
完全支持数据更新的XML压缩编码
2011-11-24 07:06刘先锋张楚才
湖南师范大学自然科学学报 2011年6期
周 舟,刘先锋,刘 萍,张楚才
(湖南师范大学数学与计算机科学学院,中国 长沙 410081)
目前,XML被认为是互联网上的数据表示和数据交换的标准,并被大家广泛接受,越来越多的网上资源以XML的格式来表示.如何对这些XML数据进行有效地管理就成为一个重要的研究内容,人们针对XML的查询要求提出了一些如Xpath和Xquery查询语言.但这些查询语言都有一个共同的不足:当XML频繁地发生诸如删除、插入等更新操作时,需要重新建立索引或重新编码,更新代价极大.因些找到一种编码占用存储空间小,支持结点无限更新而查询效率又高的XML编码方法就迫在眉睫.
本文提出了一种新的压缩编码方法,具体在于:
(1) 提出了一种新的XML 压缩编码方法,该编码方法利用了分数特点和路径编码方案的优点.
(2) 编码占用存储空间小.目前XML文档越来越大,提高存储空间的利用率十分必要.该压缩编码方案将结点名,结点值和路径分别保存在不同的表中,并将其编号,这样可以避免记录相同的结点名,结点值和路径,提高了存储空间的利用率.
(3) 支持数据无限更新.该编码利用分数的特点即在任意两个分数间可以插入无穷多个分数,支持两结点间的任意操作,而不需要二次编码,是真正意义上的支持动态更新.
(4) 查询效率高.该编码将每一个结点的路径保存在一个表中,并将其路径编号,避免了以往查询算法的结构连接,且不受路径表达式长度和中间结果的影响,从而提高了查询效率.
1 背景知识和相关工作
为了解决XML更新带来的编码重构问题,很多学者和研究人员提出了一些编码[1-5]和查询算法[6-9].
1.1 区间编码
一种常见的区间编码方案称为Zhang[1]编码,其编码规则为:XML文档树中的每一个结点被赋予一个二元组(begin,end).对树T的所有结点访问两次,一次是在遍历该结点的所有后裔结点之前访问该结点,并产生该结点的序号begin;另一次是在遍历完结点的所有后裔结点后再一次访问该结点,并产生该结点的另一个序号end.
1.2 前辍编码
LSDX[2]编码是一种前缀编码,LSDX编码采用数字表示节点的层次关系,用字母表示节点的位置信息.LSDX编码格式为nx.y,其中n是数字,表示节点的层次,x是字母,表示节点的父节点编码,y是字母,表示节点是其父节点的子节点.如果节点没有父节点,显示格式为0x,表示该节点的层次为0,编码为x.
2 FAPE方案
2.1 编码方法
在该编码方法中,XML文档树中的每个结点用一个三元组来表示〈fenzi/fenmu,PathName,PathPosition〉,其中fenzi为该结点先序遍历所得到的值,初值设为1,以后按先序遍历的顺序每访问下一个结点,其值加1;fenmu恒设为1,保持不变;PathName为该结点的路径名;PathPosition表示结点的路径序号,因为不同的路径可能有相同的路径名,为了区别,在访问时按照从左到右的顺序.如果某条路径是第一次出现,则该路径的PathPosition为1,如果某条路径第二次出现,则该路径的PathPosition为2,以此类推.对于如下lib.xml文档,其文档树及分数路径编码(FAPE)如图1所示.
lib.xml
〈library〉
〈book id=″B001″〉
〈title〉 Distribute Database Systems〈/title〉
〈author〉 Jentoner Witom〈/author〉
〈/book〉
〈magazine〉
〈title〉 Object lanauage〈/title〉
〈author〉 Neichun Hsu〈/author 〉
〈/magazine〉
〈book id=″B002″〉
〈title〉 Popular Database Systems〈/title〉
〈author〉 Alfons Kemper〈/author〉
〈/book〉
〈/library〉

图1 XML文档树及分数路径编码
举例:对于右边的book结点,其编码为〈8/1,library/book,2〉,数字8表示magazine结点为先序编码的第8个结点; library/book为该结点的路径,数字2表示该路径为第2次出现,因为在左边已经有一个book结点具有相同的路径,也为bibrary/book,所以用2进行区分.
3 FAPE存储结构
FAPE用5个表记录了XML文档的信息,分别如下:
3.1 值索引表
记录了结点的值和结点的值编号,不同的结点值具有不同的值编号,相同的结点值具有一样的值编号,这样可以节约存储空间.表1记录了上述lib.xml文件的结点值和值编号.
3.2 结点名索引表
结点名索引表记录了结点名称和结点名编号,不同的结点名称具有不同的结点名编号,相同的结点名称具有相同的结点名编号,这样可以节约存储空间.表2记录了上述lib.xml文件的结点名称和结点名编号.
3.3 属性表
属性表记录了属性所属的结点编号,属性名和属性值.表3记录了上述lib.xml文件的结点编号,属性名和属性值.
3.4 路径索引表
路径索引表记录了结点的路径和路径的编号.路径名指从根结点到该结点的路径(该结点包括在路径名里面).不同路径名具有不同的路径编号,相同的路径名具有相同的编码.表4记录了上述lib.xml文件的路径名和路径编号.
3.5 结点信息表
结点信息表记录记录了结点编号、结点的路径序号、路径编号、结点名编号、结点值编号和该结点的分数.表5记录了上述lib.xml文件的相关信息.

表1 值索引表
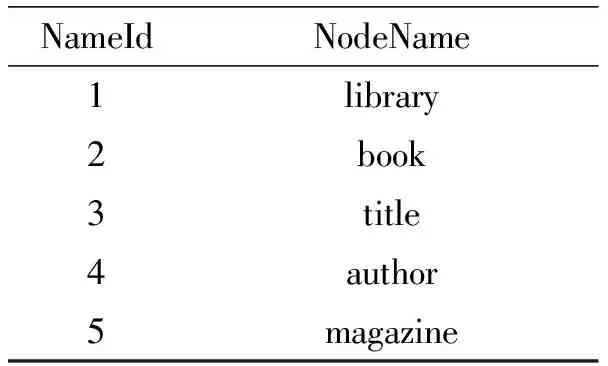
表2 结点名索引表

表3 属性表
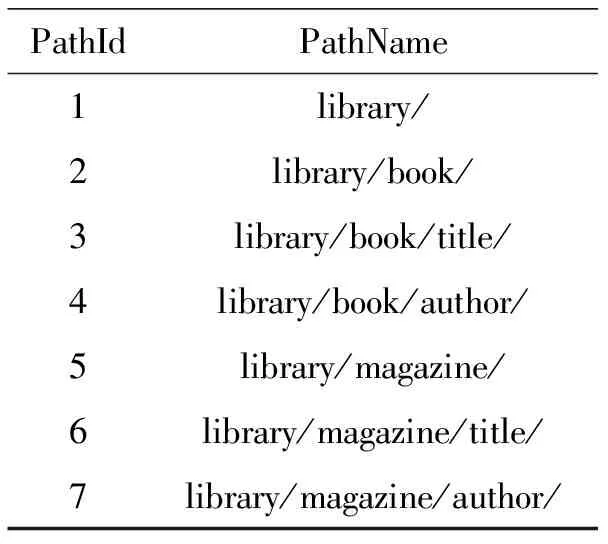
表4 路径索引表
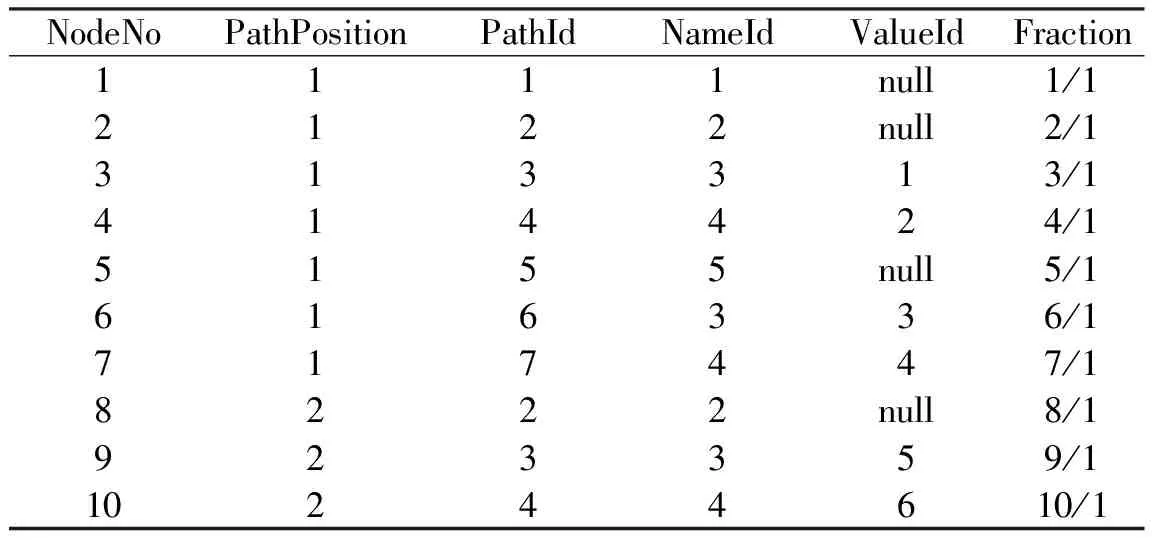
表5 结点信息表
4 编码结点关系判断
4.1 父子关系判断
设u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文档树T中的2个结点,其中node1和node2 分别为该路径名的最后一个结点名.如果n1+node1+“/”=n2,且p1=p2,则u结点是v结点的父结点,v是u结点的子结点.例如:结点u〈2/1,library/book/,1〉(n1=library/,node1=book)是结点v〈3/1,library/book/title/,1〉(n2=library/book/,node2=title)的父结点.
4.2 祖先/后裔关系判断
设u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文档树T中的2个结点,其中node1和node2 分别为该路径名的最后一个结点名.如果n1+node1+“/”是n2的前辍,且p1=p2,则u结点是v结点的祖先结点,v是u结点的后裔结点.
4.3 兄弟关系判断
设u〈f1,n1+node1+“/”,p1〉,v〈f2,n2+node2+“/”,p2〉是XML文档树T中的2个结点,其中node1和node2 分别为该路径名的最后一个结点名.如果n1=n2且p1=p2,则u结点与v结点是兄弟结点;如果n1=n2且p1=p2,f1 设u〈f1,n1+node1+“/”,p1〉,则n1中“/”符号的个数即为该结点所在的层次. 数据结点的更新包括新增、删除和修改.节点的删除和修改不会影响到原有的编码数据,但新增节点会对已经编码的数据造成影响.下面分析一下结点的插入情况, 在介绍结点的插入之前,先介绍一个重要的定理[3]: 下面讨论新增结点的插入,分4种情况: (d)新插入节点无兄弟(同时无左兄弟和右兄弟),在结点A下面插入结点B(结点名设为price),如图5所示:设A结点的编码为〈4/1,library/book/author/,1〉,则B结点的编码为〈5/1, library/book/author/price/,1〉. 图2 有右兄弟但无左兄弟 图3有左兄弟但无右兄弟 图4 既有左兄弟也有右兄弟 图5 即无左兄弟也无右兄弟 实现了FAPE方案,实验中的算法用JAVA编程语言来实现.软件环境是Windows XP+MyEclipse7.0+JDK 6.0,硬件环境是:Pentium(R)4 cpu 3.00 GHZ,内存:512 MB DDR1,硬盘:80 G. 实验中的数据集采用Xmark[10]生成的数据,XMark来源于一个针对XML的基准测试项目. 第一个实验用来检测FAPE对文档编码所花的时间.用Xmark数据集作为测试数据.Xmark数据集选择参数分别为0.018和0.27,分别生成大小约为2 MB和30 MB的XML文档.用FAPE,zhang编码,LSDX编码对文档编码进行编码,所占用的存储空间如表6所示. 表6 存储空间的比较 从实验结果可以看出,相同大小的的XML文档,LSDX所占用的空间最多,原因在于,当结点个数增加时,其结点包括其父亲结点的编码,长度呈非线性增加.Zhang编码所占用的存储空间比较小,随着结点个数的增加,其编码长度呈线性增加.FAPE所占用的存储空间最小,原因在于其分别通过值索引表,结点名索引表和路径索引表避免了记录重复的结点值,结点名和结点路径,最后只记录其相应编号即可. 第2个实验用来检测FAPE查询的效益,依旧采用Xmark作为测试数据集,选择参数为0.27,生成了30M左右的文件,其结点个数为1 022 976.针对不同的查询条件选择了6个查询实例,如表7所示.使用的编码为FAPE,XISS[5],B+TREE[6],DUIX[7]实验结果如表8所示. 表7 6个查询实例 表8 查询处理的性能 从实验可以看出,FAPE在查询时效率最高,关键在于其保存了结点的路径,完全避免了结构连接,查询效率不受查询路径表达式长度和中间结果集大小的影响,从而使查询较快.XISS在查询时所花的时间较长,关键在于其使用了结构连接.B+TREE相对XISS有所改进,但其查询效率受中间结果集的影响较大.DUIX相对XISS和B+TREE都有所改进,但在一定程度上仍受中间结果集的影响. 从上面几个实验可以看出,不管在空间性能,还是在数据查询的效率方面,FAPE相对其他的编码都具有优势,且支持结点的无限更新. 本文提出的编码方案还有很多待完善的地方,如在实际应用中,XML文档中的节点值往往具有多种类型,如日期、文本等,本文没有考虑不同的数据类型,把他们全当成字符型数据来处理,在后续工作中,将会研究不同数据类型的查询和存储情况. 参考文献: [1] ZHANG C, NAUGHTON J, DEWITT D,etal. On supporting containment queries inrelational database management systems: proceedings of the 2001 ACM SIGMOD international conference on management of data, Santa Barbara, CA, USA, Newcastle, May 21-24, 2001[C]. New York: NY,2001. [2] MAGGIE DUONG, ZHANG Y C. LSDX:a new labelling scheme for dynamically updating XML data:ADC′05 proceedings of the 16th Australian database confereace. Australian Newcastle, January, 2005[C]. Australian: Australian Computer Society, 2005. [3] 孙勇义,高 军,王腾蛟,等.一种更新友好的基于分数的XML编码方法[J].计算机科学,2008,35(10A):165-169. [4] 曹耀钦,宋建社,赵 霜,等.基于O-D的XML编码及对信息查询与更新的支持[J].计算机工程,2007,33(5):53-58. [5] 曾 捷,谢 宁,王 晖.放大转发中继网络中一种改进的分布式空时编码[J].湖南师范大学自然科学学报,2011,34(3):20-23. [6] LI C Q, LING T W, HU M. Efficient processing of updates in dynamic XML data: proceedings of the 22nd international conference on data engineering (ICDE’06), USA,April 3-7, 2006 [C]. USA:[s.n.],2006. [7] CHIEN S Y, VAGENA ZOGRAFOULA, ZHANG D H,etal. Efficient structural joins on indexed XML documents:proceedings of the 28th VLDB conference, Hong Kong, China, 2002[C].Hong Kong: VLDB Endowment, 2002. [8] 刘先锋,朱清华,陈凤英. 一种有效支持数据更新的XML索引研究[J].计算机工程与应用,2009,45(20):140-143. [9] 邹为伟,宋余庆,耿 飙,等.基于Schema的XML索引方法研究[J].计算机工程,2011,37(6):74-76. [10] 于亚新,王国仁,张海宁,等.有效支持XML结构化连接的索引——CATI[J].计算机研究与发展,2007,44(1):111-118. [11] SCHMIDT A, WAAS F, KERSTEN M,etal. XMark: a benchmark for XML data management:proceedings of the 28th VLDB conference, Hong Kong, China, 2002[C]. Hong Kong: VLDB Endowment, 2002.4.4 结点所在层次判断
5 数据更新
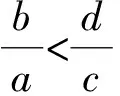
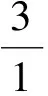
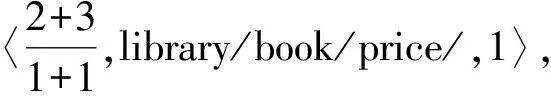
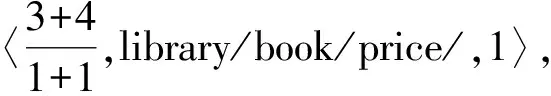
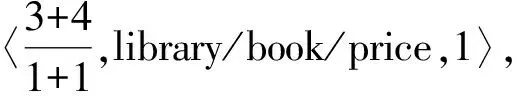

6 实验环境
6.1 测试数据
6.2 空间性能分析

6.3 数据的查询效率


7 结论及展望
猜你喜欢
客联(2022年3期)2022-05-31
智能计算机与应用(2021年6期)2021-12-17
中国新闻周刊(2021年26期)2021-07-27
综艺报(2020年21期)2020-11-30
电脑爱好者(2019年17期)2019-10-30
数学物理学报(2018年1期)2018-03-26
信息安全研究(2016年4期)2016-12-01
电子设计工程(2014年12期)2014-02-27
