
基于熵值法的组合预测模型及其在高峰负荷预测中应用
2011-11-22 01:37:32赵海青
大学数学 2011年3期
赵海青
(华北电力大学数理学院,河北保定 071003)
基于熵值法的组合预测模型及其在高峰负荷预测中应用
赵海青
(华北电力大学数理学院,河北保定 071003)
组合预测可以综合利用各单一预测方法所提供的信息,是提高预测精度的有效途径.本文在指数平滑预测法及灰色预测方法的基础上建立组合预测模型,采用熵值法确定组合权系数,并对某电网高峰负荷进行了预测.实例表明,此模型具有很强的实用性和很高的预测精度.
组合预测;熵;灰色预测模型;高峰负荷
1 引 言
随着人民生活的提高和第三产业的发展,电力需求结构发生了迅速地变化.每当酷暑严寒,在高峰负荷急速攀升时,许多电网调度中心仍然处于紧张状态.2003年我国大片疆域持续酷热,使高峰期有关电网调度中心的紧张局面更加严重.美国和加拿大东部电网2003年夏天发生的大面积停电出现在高峰期,接着英国伦敦也在高峰期出现停电事故.因此有必要加强电网高峰负荷预测的研究.在电网实际预测中,当高峰期负荷急速攀升时,可能出现异常问题(如异常值、随机误差项的异方差等),容易使数据与预测模型不能高度吻合,从而直接影响预测精度.针对高峰负荷重现性较差,受温度等因素影响较敏感这一特点,预测方法也要求尽量做到稳健,而单一预测[1]方法具有较大的局限性.大量的应用研究表明,组合预测可以综合利用各单一预测方法所提供的信息,是提高预测精度的有利途径.本文建立了组合预测模型,为避免非负权数的约束,采用了熵值法[2,3]确定组合预测模型的权系数,对某电网高峰负荷进行了预测分析,能较大程度地提高预测精度.
2 组合预测及熵值法的基本思想
组合预测方法是由Bates和Granger在题为“The Combination of Forecasts”的论文中首次提出的,其基本思想是将几种预测方法所得的预测结果,选取适当的权重进行加权平均以提高预测的精度,组合预测方法建立在最大信息利用的基础上,它集结了多种单一模型所包含的信息,进行最优组合.因此,在大多数情况下,通过组合预测可以达到改善预测结果的目的.其基本思想如下:
假设有N个预测模型,每一个模型是基于各自的信息集建立起来的,即第j个模型在n时刻的信息集为Ijn∶(Ion,Jjn),其中Ion为所有模型所共享的信息集,Jjn为第j个预测模型所特有的信息集,并且假设任意两个信息集是相互独立的.因此,宇宙间的所有信息可由如下集合所表示:

如果Un是可知的,则yn的下一期预测值yn+1可由最小二乘法估计出来,其表达式为

其中,a(B),βj(B)为滞后算子多项式,zn为共享信息集的具体表达式,xjn为每个模型所特有的信息集的具体表达式.但实际上,我们往往得不到所有信息,而只是得到部分信息,如我们仅知道第j个模型的在n时刻的信息集为Ijn∶(Ion,Jjn),则在此基础上对yn+1的预测可表示为

可见第j个预测模型只是对信息集Ijn∶(Ion,Jjn)的利用,因此将已知的信息集进行有效的组合来提高预测是很自然的想法,即,如果有k个信息集已知,则组合预测可表示为
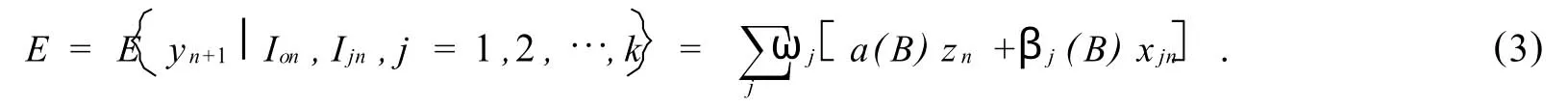
式(3)中ωj表示第j个预测模型的权数,其他符号的表示同式(1).
权数的确定成为组合预测研究的关键,也是近年来研究的热点问题.目前权数的确定方法主要有最优组合方法和非最优组合方法两类.最优组合方法根据某种准则构造目标函数,在一定的约束条件下求解目标函数,从而得出组合的加权系数;非最优组合方法根据各单项预测模型误差的变异程度来确定权数,即单项预测模型误差变异程度越大,其权数应越小,单项预测模型误差的变异程度越小,其权数应越大.这两种方法尽管得到了广泛的应用,但仍存在一定问题,如目标函数求解的复杂,非负权数的强约束使得求解的权数并非最优解等等.更为重要的是,这两种方法并没有体现出组合预测的基本思想,即将已有信息结集,达到充分利用已有信息的目的.此外,权系数是否应归一化仍存在争议.
组合预测是从信息的充分利用角度建立起来的,而信息熵能很好的度量信息量的多少,因此,将熵值法应用到组合预测权系数的确定中就很好的体现了这一思想.下面将熵值法的基本思想作一简要介绍.
熵本是热力学概念,是指不能用来做功的热能,后由申农(Shannon)引入到信息论中,在信息论中,熵是指系统不确定性程度,无序程度的度量,与信息量方向相反,即熵值越大表明系统的信息量越少,系统不确定性程度越高.熵值的计算公式为:
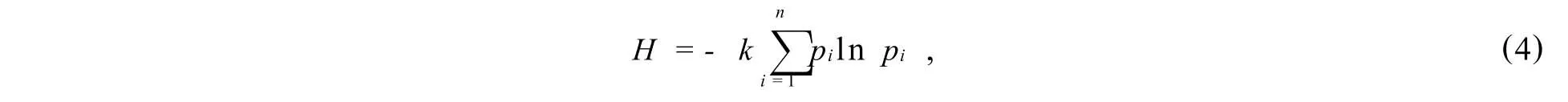

依据熵的思想,组合预测中各单项模型预测相对误差熵值的大小可以表示此单项模型的稳定程度,即相对误差熵值越大,说明误差的变异程度越小,则此单项模型的预测越稳定,因此,其在组合模型中的权数应该越大;反之,若预测相对误差熵值越小,说明此模型提供的有效预测信息量就越小,预测误差变异程度较大,此预测模型就越不稳定,其在组合模型中的权数就越小.由此可以用熵值法确定组合预测的权数,其一般性步骤如下:
(i)计算第j个预测模型在第t时刻的预测相对误差的比重pjt:

(iii)计算第j个预测模型的预测相对误差的变异程度系数Dj:

(iv)计算第j个预测模型的权系数lj:

2 实例分析
以某电网1994—2006的年度高峰负荷数据作为预测样本,对2007及2008年的高峰负荷进行预测运算并进行误差分析.该电网年高峰负荷历史数据见表1所示,预测结果及误差分析见表2所示.
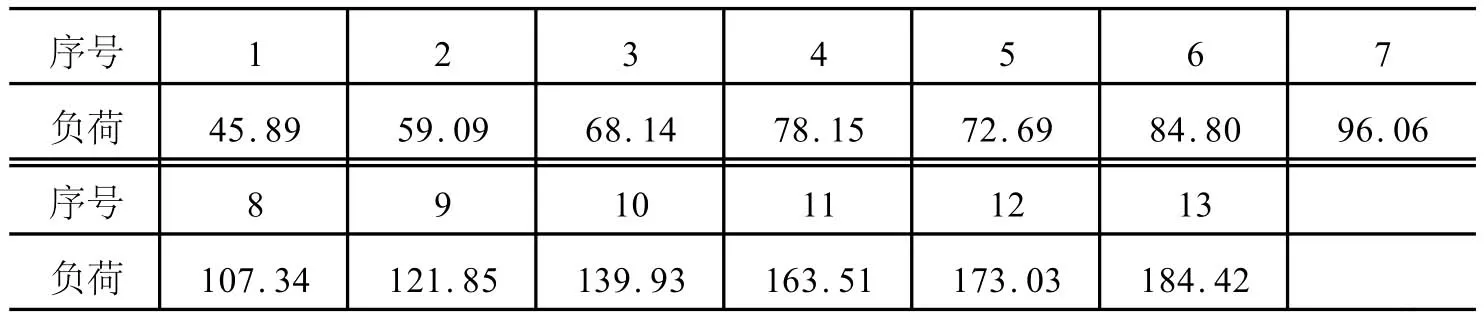
表1 某电网1994—2006的年度高峰负荷 (单位:MkW)
首先根据历史数据计算出单项模型分别为:

经计算可得2007和2008年的最大负荷值分别为213.2MkW和238.27MkW.并对1994—2006年的最大负荷值进行误差分析(见表2),原点误差较小.

表2 预测结果及误差分析
3 结 论
i)本文提供了一种稳健的高峰负荷的预测模型,给出了确定权系数熵值法,操作简便且具有较高的精度.
ii)此模型不仅适用于电力负荷预测问题,也适用于重现性较差、受温度等因素影响较敏感经济指标的预测,有较强的可移植性和可扩充性.
[1] 牛东晓.电力负荷预测技术及应用[M].北京:中国电力出版社,1998.171-196.
[2] 陈华友.熵值法及其在确定组合权系数中的应用[J].安徽大学学报(自然科学版),2003(4):1-6.
[3] 邱箢华.管理决策与应用熵学[M],北京:机械工业出版社,2001.
The Combination Forecasting Model Based on the Entropy Approach and Application in Power Peak Load Forecasting
Z HAO Hai-qing
(Department of Mathematics and Physics,North China Electric Power University,Baoding 071003,China)
Combination forecasting is an effective way to improve the accuracy of forecasting as it can utilize the information from every single forecasting method comprehensively.Based on exponential tendency forecasting method and grey forecasting method,this paper sets up acombination forecasting model,in which the coefficients of combination weights are determined by the entropy approach.The combination model is used to forecast the power peak load forecasting.It is indicated that the model presents better utility and accuracy.
combination forecasting;entropy;grey forecasting method;peak load
TM731;O221.67
B
1672-1454(2011)03-0157-04
2008-08-01
猜你喜欢
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
今日农业(2021年8期)2021-07-28 05:56:04
书香两岸(2020年3期)2020-06-29 12:33:45
统计与信息论坛(2020年5期)2020-06-03 06:57:04
证券市场周刊(2019年25期)2019-08-16 01:27:48
证券市场周刊(2019年26期)2019-07-20 10:00:48
统计与决策(2018年23期)2018-12-21 07:14:20
河南电力(2016年5期)2016-02-06 02:11:32
卫星与网络(2016年12期)2016-02-05 09:23:22
河南电力(2015年5期)2015-06-08 06:01:46
