
基于Web的HSK阅卷系统设计与实现*
2011-10-18 08:10刘喆
中国教育信息化 2011年6期
刘喆
(北京语言大学 汉语水平考试中心,北京 100083)
基于Web的HSK阅卷系统设计与实现*
刘喆
(北京语言大学 汉语水平考试中心,北京 100083)
随着参加中国汉语水平考试(HSK)的人数不断增多,原有的阅卷流程和评分系统已不能适应新的要求,为了彻底解决阅卷效率不高的问题,本文进行了深入的讨论。首先分析了现有流程的主要问题,之后研究设计了核心环节并行化的阅卷方法,设计并实现了基于Web的阅卷系统,最后讨论了面向阅卷员和科研人员不同的数据管理机制。
流程优化;网络阅卷;LINQ
一、引言
中国汉语水平考试 (HSK)是为测试母语非汉语者(包括外国人、华侨和中国少数民族考生)的汉语水平而设立的国家级标准化考试,考试成绩可作为达到进入中国高等院校学习或报考研究生所要求的实际汉语水平的证明,还可作为汉语水平达到某种等级或免修相应级别汉语课程的证明,以及作为聘用机构录用人员时评价其汉语水平的依据。随着中国不断深入地参与国际社会活动,越来越多的外国人开始重视与中国的交流,学习汉语在很多国家和地区掀起了热潮。北京语言大学汉语水平考试中心负责国内外各考点的HSK考试的命题、阅卷和组织考试等工作,随着考点的不断增加,考试人数的不断增多,考试规模已经和HSK初期相比发生了巨大的变化,阅卷作为考试流程中非常重要的环节也面临着改革的机遇与挑战。
二、系统分析
1.业务背景分析
HSK阅卷作为考试必不可少的环节,在初期主要参考国外著名相关考试的模式,同时结合我国的国情和当时的技术水平设计了解决方案,这个方案完备地覆盖了考试阅卷过程的主体环节,经过几十年的积累,为HSK考生提供了优质的服务。但随着考试规模的增加,尤其是近年来我国不断加强对外的文化宣传,考生数量的爆炸式增长为阅卷带来了巨大的压力,为了保证阅卷质量和进度,除了对设备进行更新和升级以外,阅卷人员还需要付出更多的时间和精力。这不仅增加了阅卷部门的负担,还面临如下几个问题:
(1)原有阅卷流程虽然稳定可靠,但是吞吐量固定,弹性较差,面对急剧增加的考生只能通过增加阅卷时间来解决,一旦延期将直接影响成绩发放的时间,造成严重的社会影响;
(2)现在考生主要是通过互联网进行报名和成绩查询,原有的阅卷流程由于设计的时间较早,没有考虑这些因素,导致评分数据无法直接应用于网站,要进行多次转换,增加了错误出现的几率,需要额外的审查机制保证数据的准确性,影响成绩发放的进度;
(3)原有流程并行程度不高,基本上只能线性执行,很难通过增加设备和阅卷人员来有效提高阅卷速度,更多的是依赖核心评分员的工作效率。
虽然可以通过购置新型阅卷设备来缓解这些问题,但还需要重新设计阅卷流程,开发新型阅卷系统才能与新设备无缝衔接,这样才能有效地解决目前面临的这些问题。
2.技术选择
新的阅卷流程和评分系统的设计开发应遵循两个原则:一是对历史数据和操作流程要有兼容性,出现突发问题时可以切换到原有阅卷模式;二是大幅度提高阅卷流程的吞吐能力,以适应考生的大量增长。
旧系统是基于Foxbase开发建设的,历史数据是DBF格式文件,在开通网上报名和成绩查询业务后,网站使用的是SQL Server 2000,从数据兼容性和管理员使用习惯考虑要延续使用SQL Server系列数据库来保证一致性。业务流程中主要涉及的是考生答案扫描后的文本数据的处理,结合报名数据、标准答案数据和等值数据等内容进行评分和评级,其中报名程序(包括现场报名和网上报名)是基于.NET平台开发,中心对该平台的开发已有一定的积累,且日常使用的是Windows系列操作系统,因此决定采用.NET平台进行开发。
HSK积累的大量历史数据具有非常重要的科研价值,可以为研究人员提供参考,因此要提供合理的方式分享数据。在这里要考虑两个因素,一是数据的保密性,汉语水平考试作为国家级考试对保密性的要求非常高,未授权的访问是严格禁止的,数据中包含的隐私信息一旦泄露可能会产生严重的社会影响;二是数据的分享,当次考试的数据一经公布就变成历史数据,考生可登录网站进行查询,同时也可供研究人员使用。基于以上两点,统一的管理将有效地降低成本,同时也能够以一致的模式进行分享。目前考生主要使用网上查询成绩业务,同时研究人员具有分散性和随机性,因此决定新的流程和系统将基于Web进行设计,同时考虑加入角色权限管理机制保证数据的安全使用。
3.业务流程说明
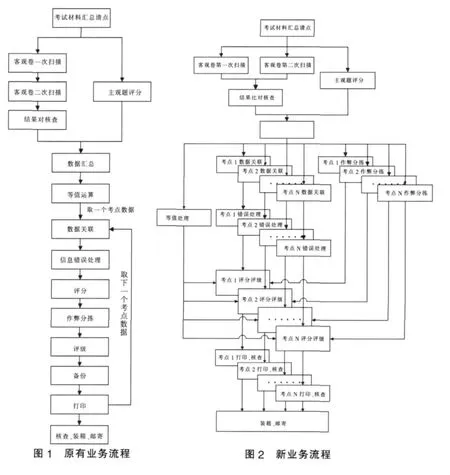
原有业务流程基本上属于线性执行,主要包括考试材料汇总、客观题数据采集、主观题评分、数据合成、数据比对纠错、作弊分析、等值计算、评分评级和成绩单证书打印、成绩发放等步骤,如图1所示;新流程在客观题数据扫描过程中通过增加扫描设备实现了并行处理,在数据关联、错误处理、作弊分拣、评分评级和打印核查等多个核心环节通过统一的数据管理和分享实现了并行处理,如图2所示。
三、系统设计与实现
1.功能需求
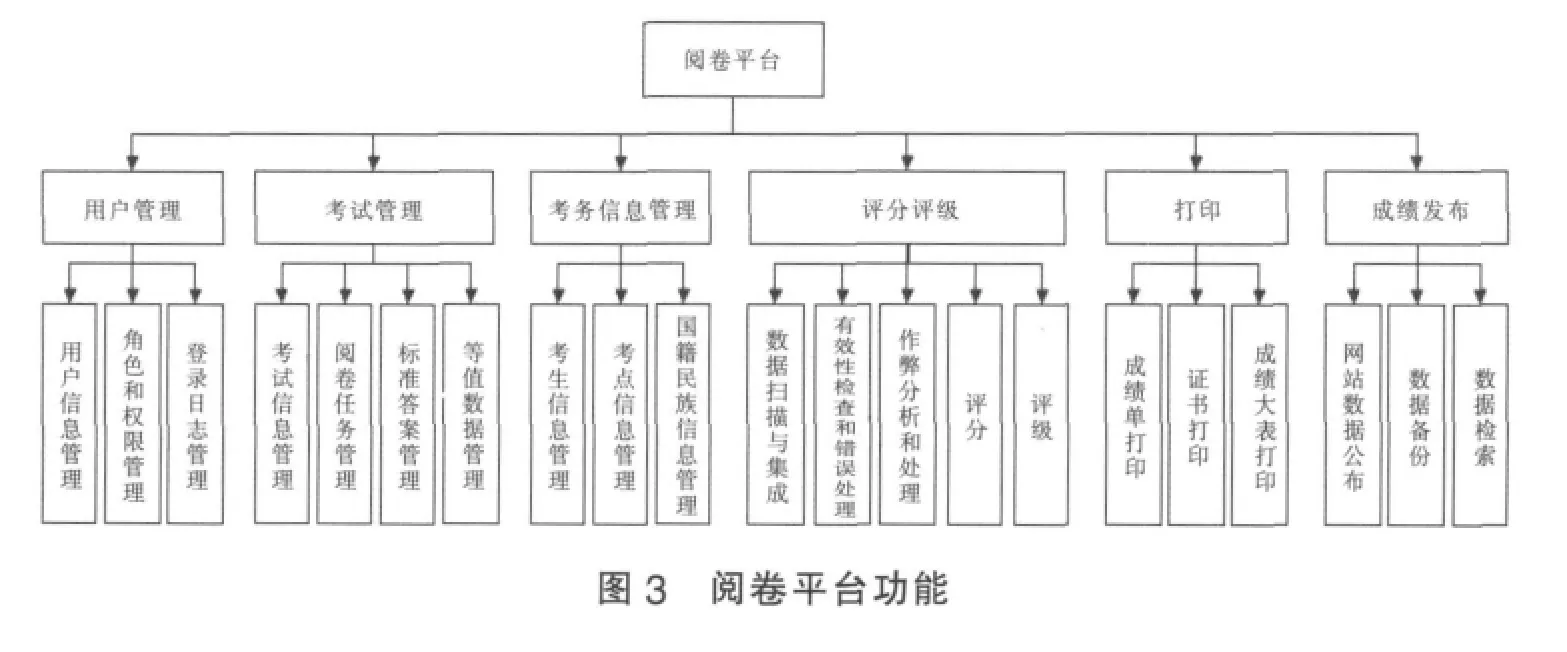
阅卷平台有以下功能要求:
(1)对用户进行区别管理,阅卷员和科研人员分别扮演不同角色对数据进行访问,其中阅卷员可以在指定授权的考试范围内进行相关的各种操作,而科研人员仅具有只读的访问权限,此外还要对其指定数据的访问范围,以此保证数据的安全性。
(2)阅卷平台要具有较强的扩展性,除了完成日常计划中的HSK各类考试外还要适应临时性的考试,如HSK预测考试、留学生分班考试、入学考试以及短期班的水平测试考试等。
(3)对历史数据要有效地进行管理,包括历次考试的标准答案、等值数据、考生信息、最终成绩、作弊记录等,并要保证数据安全。
(4)阅卷数据要保证能够与最终网站发布成绩的格式保持兼容,实现共享,并且提供丰富的自定义条件供科研人员提取数据进行科学研究。
(5)对阅卷的主要环节实现分布式并行化处理,大幅度增加阅卷的吞吐能力,提高效率。
具体功能如图3所示。
2.数据库设计
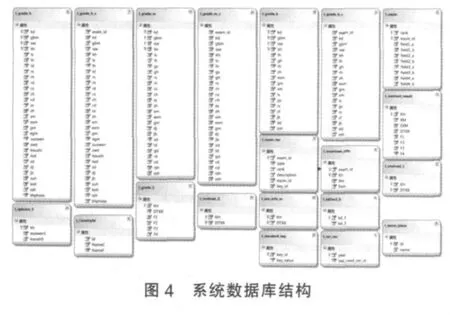
阅卷平台的数据库设计除了要满足评分的要求外还要满足科研人员诸多自定义查询的需求。传统的数据访问方式将表现层与数据访问层隔离,好处是能够降低耦合性,但是对于多重用途系统的数据呈现就带来了困难。LINQ利用基于关系数据的.NET语言集成查询,可以实现以对象形式管理关系数据,并提供了丰富的查询功能。本平台将使用LINQ作为主要的数据访问方式。如图4所示是本系统利用LINQ设计的数据库结构。
3.关键技术实现
(1)LINQ的应用
首先利用对象关系设计器(O/R设计器)创建基于数据库中对象的LINQ to SQL实体类和关联(关系),即用O/R设计器在应用程序中创建映射到数据库中对象的对象模型。同时生成一个强类型DataContext,用于在实体类与数据库之间发送和接受数据。

在建立了DataContext后,利用它将我们对数据库对象的LINQ查询转换成相应的SQL查询,然后将查询结果汇编成实体对象返回,供我们进行各种操作。例如,取得初中等考试评分表中的所有已关联记录。
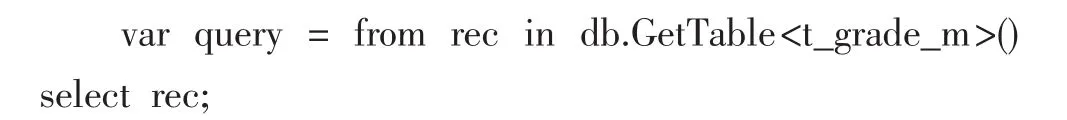
利用迭代器对逐条记录进行等值处理,得出报告分基数,并存储在相应的列中。
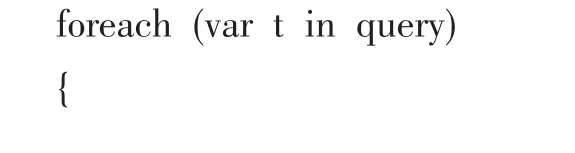

在完成所有计算后将计算结果保存到数据库中。
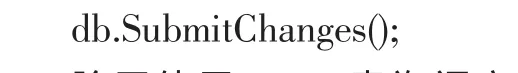
除了使用LINQ查询语言外还可以使用标准的SQL语言对LINQ查询对象执行操作。

(2)权限管理与差异性数据展现
平台的使用者分为阅卷员和科研人员,两者对数据的关注点不同,阅卷员关注的是当次考试指定类型的评分数据,而科研人员关注的是历史数据中蕴含的趋势性信息,因而从访问权限和数据展示方面就要进行差异化的处理。
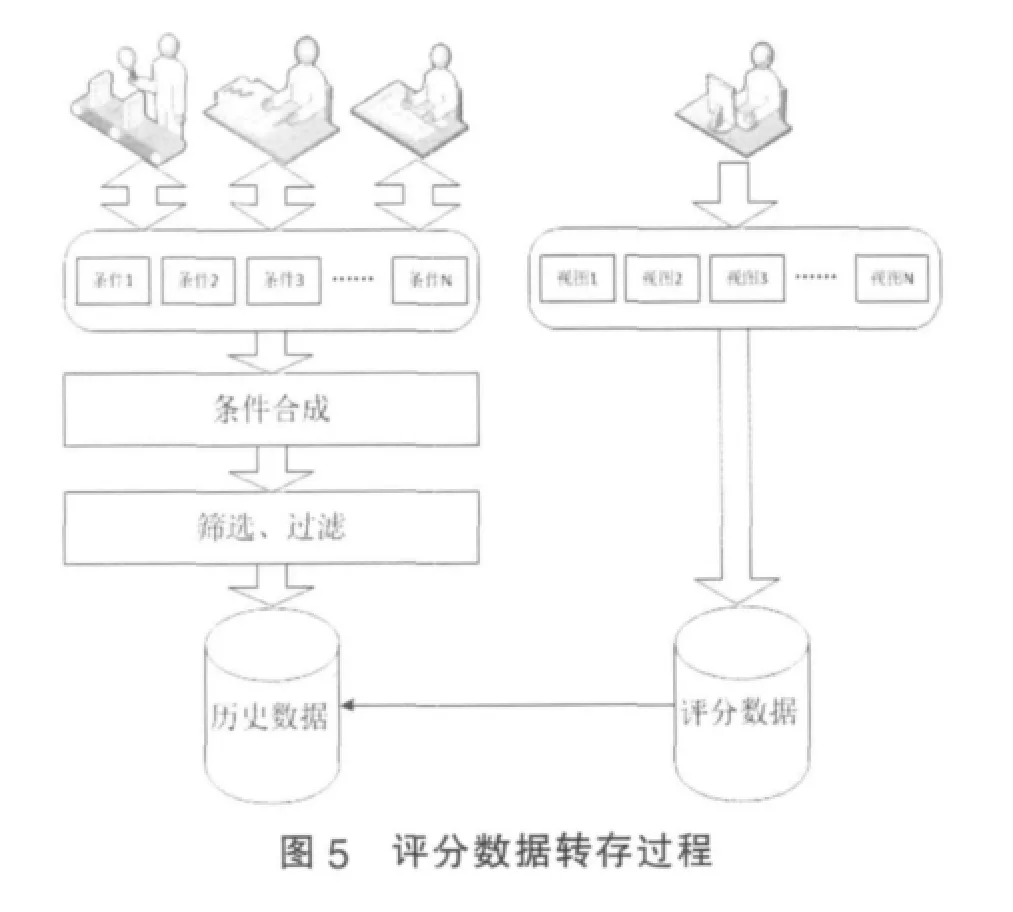
为了提高访问的效率,将数据库分成两部分,一部分是历史库,即已经发布的考生成绩、已使用过的试卷标准答案和等值数据、往次的考生信息数据等,另一部分是还未公布的考试数据的评分库,主要是阅卷过程中需要使用的考生信息、标准答案、等值数据、考生答卷数据和评分计算数据等,数据公布后将转存到历史库中,如图5所示。
①预编译查询
对阅卷员显示的信息比较固定,按照阅卷流程显示相应的各种信息即可,因此可将所有要展示的数据设计成视图,提高访问效率。复杂的层次结构将会降低系统的性能,在进行数据库操作的时候存在着性能方面的开销,尤其是将LINQ查询语句转换为数据库使用的SQL时,转换的过程需要通过反射得到映射的元数据,再将查询语句解析成表达式树,并根据表达式树生成SQL字符串。
若某个查询语句需要多次执行,那么利用预编译查询技术只需要分析一次该查询结构,随后就可以多次使用。这里使用CompiledQuery.Compile方法定义一个将要被重复使用的查询,并在DataContext中定义一个静态域保存该查询,再使用另一个非静态的方法对其进行封装。CompiledQuery.Compile方法将返回一个泛型的函数,而不是一般查询所返回的值或简单类型。下例代码给出了一个返回指定考点的评分信息的预编译查询,除了传入名为kd的考点代码外,查询的其他部分将被预编译。

因为KDInfo为静态域,所以在该应用程序域(AppDomain)中只需要一次性地求值,随后便可以多次使用,从而省去了每次求值所带来的额外性能开销。在任何时候若需要得到指定考点的评分信息,我们就可以直接调用GetKDInfo方法。LINQ框架无需每次都重新映射数据库和对象之间的关系,也无需重复地将查询语句解析成表达式树。
②条件合成和过滤
科研人员要对数据进行分析和比较,所以会提出各种限制条件,这些条件具有很大的随机性,无法提前预估出来,因此在对科研人员的数据展示方面要结合数据访问限制和条件需求进行设计。
条件合成主要是将用户选择的条件作为参数带到查询中,并且根据用户的要求提供默认和自定义的排序方式,利用LINQ的“延迟查询执行”可以将条件汇总作为一个过程,而不是对各个条件逐一进行查询而渐进得出的结果。延迟查询执行的一个优势在于节省了资源,主要在于直到我们需要迭代访问查询结果的时候,该查询所要操作的数据源才会被访问。比如在处理第一个元素后就不访问其他元素时,后续的元素就不会被加载到内存中,而在传统模式下,即使程序并不需要全体元素,它们也会被加载到内存中。另一个好处是可以将查询的定义和使用分开,这有利于我们将条件收集和数据查询两个过程进行分离,并且还可以多次复用已定义好的查询,提高了数据访问的效率。
条件合成通过参数化构造为过滤功能提供了基础,避免了一些常见问题。首先是SQL注入攻击,即在SQL语句中插入一段恶意代码,而使用参数化的条件合成即可避免这种威胁。其次是我们可以充分利用SQL Server的查询计划缓存。若仅修改某个查询条件的参数,SQL Server即可适当地对该查询作出执行计划并将其缓存起来,以后对于同样的查询请求,数据库即可直接使用缓存中的执行计划,而不需对表达式重新进行分析求值。
四、结束语
由于系统采用了Web模式,避免了单机模式的分散式维护,提高了阅卷并行化水平,极大地增加了阅卷的吞吐能力,还为科研人员提供了方便的数据检索功能。实践证明,本系统具有良好的社会效益和经济效益。但由于对系统流程修改较大,还存在如并行优化不足、流程衔接不够紧凑等问题,相信随着对业务研究的不断深入和技术的发展,这些问题都能得到解决。
[1](法)Fabrice Marguerie,(美)Steve Eichert,(美)Jim Wooley著,陈黎夫译.LINQ实战[M].北京:人民邮电出版社,2009.
[2](美)Andrew Troelsen著,朱晔等译.C#与.NET 3.5高级程序设计(第4版)[M].北京:人民邮电出版社,2009.
(编辑:金冉)
TP311.52
B
1673-8454(2011)11-0031-04
*本课题为北京语言大学青年自主科研支持计划资助项目(中央高校基本科研业务费专项资金资助)(10JBG15)。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
金桥(2022年6期)2022-06-20
今日农业(2022年3期)2022-06-05
今日农业(2021年19期)2021-11-27
今日农业(2021年10期)2021-07-28
金桥(2020年11期)2020-12-14
园林科技(2020年2期)2020-02-17
劳动保护(2018年5期)2018-06-05
课堂内外(高中版)(2017年9期)2018-02-24
华人时刊(2017年17期)2017-11-09
