
基于证据理论的内部控制风险评估体系评价*——以我国汽车制造上市公司为例
2011-10-17 01:52朱卫东王锦
财会通讯 2011年6期
魏 巍 朱卫东 王锦
(合肥工业大学管理学院 安徽 合肥 230009)
基于证据理论的内部控制风险评估体系评价*
——以我国汽车制造上市公司为例
魏 巍 朱卫东 王锦
(合肥工业大学管理学院 安徽 合肥 230009)
作为内部控制的重要组成部分,风险评估的重要性不言而喻。对于内部控制风险评估体系的构建是否符合我国企业未来的发展方向亟待检验,汽车制造企业是我国制造业的领头羊,上市公司代表我国先进企业的发展方向,基于最近颁布的并在上市公司首先试行的《企业内部控制基本规范》,本文立足于汽车制造上市公司,建立了内部控制风险评估体系的评价模型,运用证据理论解决目前的评估方法所难以解决的评价信息的模糊性、未知备性和不确定性,完成了对于指标体系的评价,以期对汽车制造企业的发展有所贡献。
风险评估 证据理论 汽车制造 内部控制
一、引言
风险评估是内部控制系统的基础组成部分,要使控制制度发挥其应有的作用,企业必须清楚所面临的风险,并对整个企业的风险进行定性或定量的评估,然后针对风险评估的结果采取相应的控制活动。目前,在我国的企业内部控制建设过程中,除了银行等风险较大的金融行业对风险评估比较重视外,大部分企业对风险评估的作用没有形成科学的认识,对风险评估的重视度不够。然而,大多数公司舞弊案件的发生,究其根本都是对内部控制重视不强,对于风险评估方面更加松懈,最终导致悲剧的发生。汽车制造公司是我国制造业的领头羊,而上市公司代表我国先进企业的发展方向,对我国的产业发展起到至关重要的作用,鉴于上述情况,本文选取汽车制造上市公司来具体说明内部控制风险体系的构建和评价,希望能对完善汽车制造企业的内部控制系统、改进内部控制风险评估标准提供借鉴,从而实现汽车制造企业健康、稳定、良性发展。然而,由于内部控制各指标评估资源的模糊性、未知性和不确定性,需要一种有效的评估方法对其进行综合处理。目前常用的方法有层次分析法、模糊综合评判法和基于神经网络的方法等,但这些方法不能同时解决上述问题,证据推理作为一种不确定推理方法,近年来有了很大发展,国外出现了大量文献。证据理论能够很好地表示“不确定性”、“无知”等重要概念,并具有无需先验概率、推理形式简单等特点,被广泛应用于不确定性证据处理中,并取得了较好的效果。本文基于D-S证据理论将评估资源的模糊性进行了有效的处理,以期解决这一问题。
二、基于证据理论的汽车制造上市公司内部控制风险评估体系评价模型
(一)证据理论综述 D-S证据理论是建立在一个非空集合D上的,它描述了构成整个假设空间所有元素的集合(也称为样本空间),要求其中各元素互相排斥。由D的所有子集构成的幂集记为2D。下面给出与D-S证据理论有关的定义。定义1:设D为识别框架,函数M:2D→[0,1],且满足M(覫)=0M(A)=1,则称M是2D上的概率分配函数,称M(A)为A的基本概率数。定义2:设D为识别框架,M

(二)汽车制造上市公司内部控制风险评估体系评价模型 根据《企业内部控制基本规范》对上市公司构建内部控制风险评估体系的要求,结合COSO报告的精髓,通过实地调研,深入了解公司的风险评估操作规范和程序,构建了风险评估操作程序体系如(图2)所示。结合上述操作体系,综合考虑汽车生产上市公司的基本状况以及影响内部控制风险评价的要素,构建汽车生产上市公司内部控制风险评价指标体系如(表1)所示,包括总资产增长率、销售净利率、资产负债率等11个定量指标和其他21个定性指标。对于“整体风险承受能力”子指标的选取,主要是根据财务指标所反映的企业四大能力,同时考虑到数据披露的全面性和篇幅的限制,分别选取了一个有代表性的指标来从披露的数据上反映此项能力,即增长能力(总资产增长率)、盈利能力(销售净利率)、偿债能力(资产负债率)和资产运营能力(总资产周转率),进而反映企业的财务和运营风险承受能力,另外,选取企业价值、企业信用等级和汽车销量排名来从市场价值上来反映企业的市场风险承受能力。对于“业务层面风险承受能力”子指标的选取则是根据汽车生产企业的行业状况决定的。其中,总资产增长率=本年总资产增长额/年初资产总额×100%;销售净利率=净利/销售收入×100%;资产负债比率=负债总额/资产总额*100%;总资产周转率=销售收入/平均资产总额×100%;固定资产比率=固定资产/资产总额×100%;存货周转率=主营业务成本/平均存货×100%;主营业务利润率=主营业务利润/主营业务收入×100%。
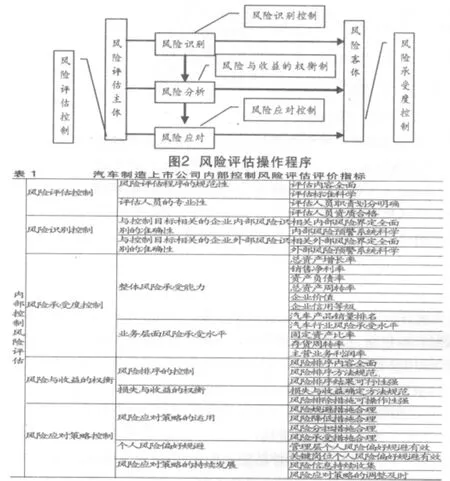
(三)基于证据理论的汽车制造上市公司内部控制风险评估体系评价模型建立 本文采用证据组合观点,用专家评价定性指标,将定性的专家意见与定量指标进行科学的融合。但专家的评判意见也是带有主观性的,也会存在偏差,并且有时会出现含糊或不确定的认知状况。所以在这类定性评价中,由于信息本身存在的不确定性以及运用信息进行判断的专家的不确定性,使得评价结果的最终确认和可信性方面受到挑战。而基于证据组合的信息融合方法正是解决此类问题的一个有效手段。基本步骤如下:
首先,确定需要处理的对象,建立多层次多属性结构模型(如表1)。本文所建模型是一个三级指标体系即多层次结构模型;体系中涉及定性指标和定量指标多个属性即混合多属性结构模型。为了实现最后指标的综合处理,必须把所有的指标形式统一,具体来讲有两种方法:一是将所有定性指标均转化为定量指标,即定性指标定量化;二是将所有的定量指标均转化为定性指标,即定量指标定性化。而前者比较适合多个评价方案的比选排序,后者比较适合单个方案的评价。况且证据理论适用于评价定性指标,解决其中存在的不确定和不完全信息,因此,应该对定量指标定性化。
第二,评估指标体系的建立。评估指标体系通常是多层次的。为便于说明,先假设评估指标体系为单层次,此时,评估指标体系可表达为指标集,记为U={Uj|j=1,2,…,t},记评语集D={θ(p)|p=1,2,…,t},D即为辨别框,本文中可令D={优(θ(1)),良(θ(2)),中(θ(3))},较差(θ(4)),很差(θ(5))。
第三,定量指标的定性化。在评价指标体系中,设同层指标中X1,X2,…,XL为定性指标,指标Y1,Y2,…,YR为定量指标,它们的权重分别为w1,w2,…,wL和v1,v2,…,vR。对于定量指标,其数值与方案的评语之间必然存在一定的联系,虽然对某个特定的数据来说,其与评语之间的关系并不明显,但评语与指标数值范围总存在一个粗略、相对较易识别的对应关系。对于定量指标,先确定所需评价指标的最大临界值Yjmax和最小临界值Yjmin,在其中插入等距离的三个点Yj1、Yj2、Yj3,(Yj1>Yj2>Yj3),再区分效益型和成本型指标,分别用(4)和(5)式进行处理。
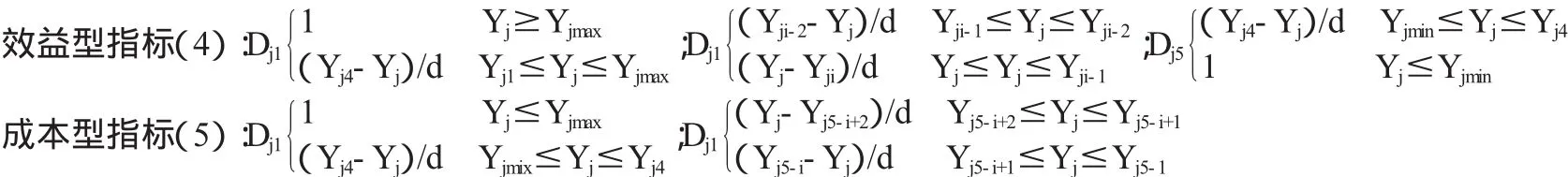
i=2,3,4;d=(Yjmax-Yjmix);其中Yj0=Yjmax;Yj5=Yjmix。Dji反映了某一指标Yj经过定性化后属于等级Di的隶属度。此时,定量指标经过上述转化已经变成定性指标,并被赋予了不同等级的标度值。结合原有的定性指标X1,X2,…,XL,形成了新的定性指标体系。
第四,权重的确定。权重集可以分为专家权重集和指标权重集。由于不同的专家的知识水平和权威性,所以不同专家对同一指标的影响程度(权重)也应该是有所不同的。设是指标U的专家权重集。(t=1,2,…,l)表示第t个专
j家对指标Uj的相对权重。专家权重集的确定采用集值迭代法。根据掌握的专家信息,设m个专家系统对n个参评专家进行评价。m次在n个专家中选择他认为最可信的专家,计算n个专家中每人被选中的次数并进行归一化处理,即为该专家对指标Uj的相对权重,亦可看成是专家的置信度。该方法避免了检验判断一致性的问题,操作简单。设指标权重集w={wi|i=1,2,…,t},满足非负性和归一化要求;wi(i=1,2,…,t)表示指标Uj在指标集w中的权重。本文由专家打分,采用层次分析法确定指标权重。
第五,基于证据理论的计算方法。为了完成综合评估任务,还必须获得指标Xi(定性指标)关于评语子集θ(p)的隶属函数(记为μθ(p)(xj))该指标值是一个评语集,体现了评估资源中的模糊性。此时是由专家、评委直接给出U关于该指标的评估结果,表达为D={θ(p)|p=1,2,…,t}上的一个mass函数。借助以上评估资源,可以采用D-S证据理论实现对U的模糊综合评估,过程如下:
Step1:将所获得的专家、评委的关于Uj的评估结果记为Mj',Mj'也是一种评估资源,记为M(j'{θ(1}),{θ(2}),L,{θ(s}),D)=M(j'{θ(1})),M(j'{θ(2})),L,M(j'{θ(s})),M(j'D))。将所得各专家评估资源按照其对应权重进行处理并归一化,得到新的评估资源,记为M(j{θ(1}),{θ(2}),…,{θ(s}),D)=Mj({θ(1})),M(j{θ(2})),L,M(j{θ(s})),M(jD))…(6)。式中:M(jD)∈[0,1],当M(jD)≠0时,体现了评估资源的未知性。据此,可建立如下mass函数:mj({θ(1}),{θ(2}),…,{θ(s}),D)=m(j{θ(1})),m(j{θ(2})),…,m(j{θ(s})),m(jD));m(j{θ(p}))=M(j{θ(p}))·wj;m(jD)=1-m(j{θ(p}))=1-wj+M(jD)wj…(7)
Step2:基于D-S合成规则(参见式3),组合成与指标集U={Uj|j=1,2,…,t}有关的t个mass函数,记组合的结果为M*,则有M*({θ(1}),{θ(2}),…,{θ(p}),D)=M1茌M2茌…茌Ms…(8)。式(8)的意义在于:通过t个函数的正交和,综合处理评估资源中的模糊性和未知性。
Step3:根据式(1)和式(2),可知对命题P的信任区间为:[Be(lp),p(lp)]=[m*({θ(p))},m*({θ(p}))+m*(D)]…(9)。m*和[Be(lp),pl(p)]都是对评估对象U的综合评估结果,且二者是相互唯一确定的,只不过表达形式不同。若需要把评估就结果表达为评语集D={θ(p)|P=1,2,…,t}上的一个分布,则可构造一个“类概率分布函数”,记为(fP),从而使评估结果拥有概率的数学性质。对于(fP),可以按比例把分配给的其余各焦元,此时有…(10)。与m*({θ(p)})一样,f(P)也是对命题P的一种确定性度量。如果需要为评估对象U赋以一个唯一确定的评语,则可以选择满足max(f(P)|P=1,2,…,s)的那个“类概率分布函数”,对应于该函数的命题以最大概率成立。以上仅讨论了评估对象U的评估指标体系为单层次的情形。对于指标体系为多层次的对象,综合评估时先从指标体系的最下层开始,然后渐次向上,直至到达总目标。
三、案例分析
(一)评估体系建立 为了进一步说明方法的应用以及评价效果,有针对性的对BJ汽车有限公司进行了实地调研,下面仅以BJ汽车有限公司为例进行说明。依据上述方法,对某上市公司内部控制进行综合评价。首先,建立指标体系如(表1),设评语集D={θ(1),θ(2),θ(3),θ(4),θ(5)}={优,良,中,较差,很差}。其次,确定指标体系中定量指标值如(表2)所示,各项指标值是通过汽车工业协会统计网和中国汽车网以及各上市公司披露的2009年年报来获取的。

表2 BJ汽车公司内部控制风险评估体系定量指标获取值

表3 下各子指标的专家权重评分结果

表4 专家对的评估资源
(二)定量指标定性化 依据公式(3)和(4)对定量指标定性化。由于各指标的转化方法相同,下面仅以“总资产增长率”指标来说明。由于所选取的示例指标是效益型指标,因此采用公式(3)进行转化。首先确定所有汽车生产上市公司总资产增长率指标的最大值和最小值作为该指标的最优临界值和最差临界值,分别为0.2719和-0.4067,结合BJ汽车有限公司该指标值,共同代入公式,计算得到BJ汽车有限公司在该指标上的隶属度分配。H(U311)=H1,H2,H3,H4,H5}={0,0.7468,0.2532,0,0}。同理,可以得到其他定量指标经过转化后的定性指标隶属度分配值。
(三)权重确定 由层次分析法求得一级指标权重和二级指标权重,收集专家评估资源并针对各三级指标确定专家权重集。为了方便说明,现以“风险与收益的权衡”即U4的评估为例进行说明其中,一级指标权重为w={w1,w2,w3,w4,w5}={0.3,0.2,0.2,0.2,0.1},二级指标中第四项指标权重为w4={w41,w42}={0.6,0.4}。
Step1*:由专家给出各指标的权重:w41={w411,w412,w413}={0.4,0.4,0.6};w42={w421,w422}={0.4,0.6},由于二者评价方法相同,下面以U41为例来介绍评价过程。根据掌握的专家资料,由十个专家系统针对各指标对五个专家进行评分,如(表3)。对于U411,其评分结果进行归一化处理后得到w*411={0.2,0.5,0.1,0.1,0.1},即第二个专家对指标U411的置信度最高占50%,然后由五名专家分别以D上的mass函数给出各指标的评估资源,例如专家给出的U411的评估资源如(表4)所示。将五名专家的评估资源与各自的权重相乘再对应相加的结果进行归一化处理后,即得出指标U411的评估资源,即U411({θ(1)},{θ(2)},L,{θ(s)}),同理,可得指标U412和U413的评估资源分别为:M412({θ(1)},{θ(2)},L,{θ(s)},D)=(0.3,0.48,0.2,0,0,0.02);M413({θ(1)},{θ(2)},L,{θ(s)},D)=(0.3,0.4,0.2,0.1,0,0)。
Step2*:根据权重集w1,按式(7)对M411至M413进行处理,得到D上的3个新的mass函数,即:m11({θ(1)},{θ(2)},…,{θ(s)},D)=(0.04,0.094,0.04,0.018,0,0.808);m12({θ(1)},{θ(2)},…,{θ(s)},D)=(0.06,0.096,0.04,0,0,0.804);m13({θ(1)},{θ(2)},…,{θ(s)},D)=(0.09,0.12,0.06,0.03,0,0.7)
Step3*:根据式(8)得到M41=M411茌M412茌M413;计算如下:根据式(3)可得0.06+0.04×0.804+0.06×0.808)],(0.094×0.096+0.094×0.804+0.096×0.808),(0.04×0.04+0.04×0.804+0.04×0.808),(0.018×0.804),0,(0.808×0.804)]=(0.0851,0.1663,0.0677,0.0148,0,0.6661)其中×0.094+0.06×0.04+0.06×0.018+0.094×0.04+0.096×0.04+0.096×0.02+0.04×0.018)=0.9752。将所得的M411茌M412继续与 M413求直和得到M41,同理求出M42,最后得出:M4*=m41茌m42=(0.2118,0.2729,0.1166,0.0247,0,0.3740)。此时,若为针对“风险与收益的权衡”即U4的单层次评估,即可按照以下步骤完成评估内容。
Step4*:根据式(9),可由M1*得到U1关于各个“评语命题”的信任区间。如该企业在U1方面的评语为“优”的信任区间为(0.2118,0.5858),“良”的信任区间为(0.2729,0.6469)。根据式(10),可由M1*得到U1在模糊评语集{优,良,中,较差,很差}上的概率分布(0.3383,0.4359,0.1863,0.0395,0),显然,企业在评语方面为“良”以最大概率成立。这与实际情况相符。本文为针对“内部控制风险评估”U的综合评价,应仿照上述步骤获得其他二级指标的评估资源,从Step2*开始继续以上步骤,此处不再赘述。
四、结论
本文汽车制造业的特点,建立了汽车制造上市公司内部控制风险评估体系评价模型,对内部控制风险评估体系进行了综合评价,从以上评价过程来看,该种评价方式不仅能够将评估资源的不完备性和模糊性予以分散化,使评价结果更加可靠,还能在评价过程中得到各一级指标、二级指标的评价结果,从而为评估对象的改善和提升提供了参考依据,希望能使企业的发展有所收益。
[1]丁勇、梁昌勇、蒋翠清:《基于证据理论的企业知识链绩效评价研究》,《科技管理研究》2007年第9期。
[2]鞠彦兵、冯允成、姚李刚:《基于证据理论的软件开发风险评估方法》,《系统工程理论方法应用》2003年第3期。
[3]辛金国、赖丽娜、郑明娜:《浙江省家族企业内部控制模糊综合评价探索》,《杭州电子科技大学学报》2006年第6期。
[4]林丽芬:《证据理论及其在评估中的应用》,《福建农林大学学报》2007年第5期。
[5]王艳廷、金浩、高素英:《基于证据理论的企业管理水平综合评估方法》,《河北工业大学学报》2007年第2期。
[6]Zhigang Li,Lingling Li,Huijuan Zhang and et al.A Fuzzy Case-based Reasoning Method and Its Applications in Product Design.In:Proceedings of Sixth World Congress on Intelligent Control and Automation Congress,2006.
(编辑 虹 云)
魏 巍(1984-),女,河北唐山人,合肥工业大学管理学院硕士研究生朱卫东(1962-),男,浙江仙居人,合肥工业大学管理学院教授王 锦(1985-),男,辽宁沈阳人,合肥工业大学管理学院硕士研究生
*本文系2009-2010年安徽省自然科学基金项目“基于证据理论的不完全信息下商业银行操作风险与控制方法研究”(项目编号:090416242)的阶段性成果
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
世界科学技术-中医药现代化(2020年2期)2020-07-25
中成药(2018年12期)2018-12-29
中成药(2017年6期)2017-06-13
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
医学研究杂志(2015年4期)2015-06-10
中国检察官(2015年14期)2015-02-27
中国检察官(2015年12期)2015-02-27
植物营养与肥料学报(2011年4期)2011-10-26
