
Web日志挖掘在个性化网站中的应用初探
2011-09-19 08:46:30肖宏飞
滁州职业技术学院学报 2011年1期
肖宏飞
(滁州职业技术学院,安徽滁州239000)
Web日志挖掘在个性化网站中的应用初探
肖宏飞
(滁州职业技术学院,安徽滁州239000)
本文分析了传统网站系统的现状及其弊端,针对这些问题提出使用web日志挖掘技术,对网站浏览者的行为进行分析,并在此基础上对浏览者访问网站的行为进行预测,从而为浏览者提供个性化的访问页面,提供访问者的检索效率,同时根据对浏览者访问记录的web日志挖掘结果,改进网站结构及功能设计。
web日志挖掘;个性化;网站改进
一、概述
随着网络信息技术的飞速发展和互联网的广泛应用,网站的数量已经数以亿计,各式各样的网站系统也层出不穷,其功能也越来越多,但大多数网站系统却不能真正完全适应浏览者的要求。其原因主要是忽视了浏览者日志这一重要信息,没有给出针对日志信息的个性化服务,降低了浏览者的访问速率。
所谓的个性化网站服务,就是一种有针对性的网站服务方式,根据用户浏览习惯来设定,依据web日志对浏览者的兴趣爱好、浏览习惯、关注资讯等相关资源,向用户提供和推荐相关信息,以满足用户的需求。从整体上说,个性化网站服务打破了传统的让用户来适应网站系统的模式,能充分利用各种网络资源优势,主动开展以满足用户个性化需求为目的的全方位的web服务。个性化网站服务是一种网络信息服务的方式,开展网站个性化服务是提供信息检索和信息资源有效使用的重要手段,突出了网站信息服务的主动性,开拓了网站信息服务的新思路。
二、w eb日志挖掘介绍
随着internet的飞速发展,大量的数据囤积在互联网上,在数据背后隐含着重要的知识。如何从互联网数据中提取有用的信息,已成为当今计算机技术研究的一个热点课题。按照挖掘对象的不同,一般将web挖掘分为3大类:web内容挖掘、web结构挖掘和web日志挖掘。
Web日志挖掘是对用户访问web时在服务器上面留下的访问日志进行挖掘,即对用户访问web站点的存取方式进行挖掘,发现用户的访问模式和兴趣爱好等信息和知识。挖掘的目的是在海量的网络数据中自动、快速地发现用户的访问模式,如访问路径、检索信息、用户聚类等。分析和探索web日志记录中的规律,可以识别网站的潜在用户,增强对用户的信息服务质量,并通过对web日志的分析改进网站结构。web日志挖掘过程如下图1所示。
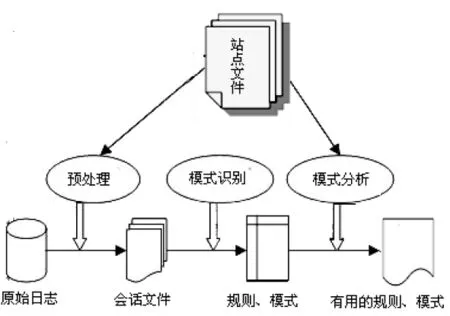
图1 w eb日志挖掘过程
三、web日志挖掘在个性化网站中的应用
下面以一个《网站动画设计》课程网站为例来说明web日志挖掘的应用。该网站主要栏目有:教学课件、实例视频、教学大纲、作品展示、素材下载、在线答疑等,访问者主要为滁州职业技术学院信息工程系08级图形图像专业学生,网站采用学号注册方式进行访问。根据学员的访问记录,在学员下次再访问该网站时,推荐学员感兴趣的知识点和相关资讯,以满足不同兴趣、不同访问目的的学员的需求,从而实现主动推荐的目的。网站结构如下图2所示。

图2 《网站动画设计》网站结构图
(一)数据收集及预处理
浏览者在访问网站时会留下很多信息,如访问IP、访问时间、离开时间、所请求URL资源、访问的HTTP状态码、客户端浏览软件等。在网站服务器上的原始的web日志中,不是所有的访问日志记录对于web日志使用数据挖掘都是有用的,进行web日志挖掘只需要对包含有用信息的日志记录进行挖掘,因此要对原始数据进行预处理。数据预处理是Web日志挖掘的重要环节,其任务是将原始日志数据转换成适合数据挖掘和模式发现所必需的格式,预处理可以直接简化数据挖掘过程,使结果更具客观性。数据预处理包括数据净化、用户识别、会话识别、路径补充四个步骤。
1、数据净化
所谓数据净化,是指将等待处理的web日志数据导入到相关的关系数据表中,删除web日志数据中不正确的值或者缺失值等信息,同时把与web日志挖掘无关的变量和数据进行清理,达到简化数据挖掘过程的目的。在本例中我们只保留了用户名、时间、浏览地址等信息。
2、用户识别
用户识别,是将浏览者和访问页面相关联的过程。从web日志数据信息中找出每个浏览者的访问信息,避免web日志挖掘的重复性。目前,由于本地缓存、代理服务器和防火墙的存在,使得识别用户的过程变得复杂。由于学院内部采用统一代理IP上网,所以所有学员的IP地址都是一样的,由于网站采用学号注册登录,因此识别学员信息非常简单。通过表1我们可以直观的得出有三个学员在访问。访问路径分别是首页-视频-习题-首页-资源,首页-在线答疑-首页-资源和首页-习题-首页-资源。如下表1所示。

表1 原始日志信息(截取部分信息)
3、会话识别
会话识别是指同一个浏览者在一段时间内连续请求访问的页面进行分析所得到的用户会话。例如,时间跨度超过了规定的界限,则认为是新的会话开始。会话识别的目的是将用户的访问序列分成单个的访问序列,以便为web数据挖掘打下基础。通过表1我们可以可将会话分为首页-视频-习题、首页-在线答疑、首页-习题-首页-资源和首页-资源四个会话。
4、补充路径
补充路径,指通过web日志数据推断出读取缓存网页的情况。由于客户端缓存和代理服务器缓存,使得服务器的日志通常会遗漏一些重要的页面请求。用户浏览页面时很可能使用浏览器的前进和后退按钮,或者使用一个曾经点击过的链接,导致当前请求的页面与上一次请求的页面直接没有超级链接。此时应该根据用户访问路径的前后页进行推断,检查引用web日志确定当前请求来自哪一个页面,并将遗漏的页面补充在路径里。通过表1的分析我们可以得出,资源页面和习题页面不能相互直接达到,而是通过了首页作为中转,形成完整的用户会话。
(二)模式识别
模式识别,是对预处理后的web日志数据用数据挖掘算法来分析处理数据,也就是对用户的每一次访问序列集合进行语义分组,分割成多个逻辑单元,为每个用户建立有意义的数据聚集,然后把处理结果转化为适合web日志挖掘所需的形式。
(三)模式分析与应用
模式分析的目的在于使用各种数据挖掘技术,发掘出隐藏在数据背后的规律和通用的模式。通过对原始数据做分析,找出用户的浏览规律,为网站的规划和网站结构的调整提供具体理论依据。通过对图2和表1的分析,我们可以看到,学员在访问视频页面的同时,大部分会同时访问习题页面,这样我们就可以在学员下次打开视频页面的时候,同时推荐相应的习题资源,以便更好的为学员的学习开展针对性的教学。
四、结束语
现在web日志挖掘已经成为网络研究、数据挖掘、个性化推荐等领域的热点问题。研究web日志挖掘对于优化web站点、个性化学习、信息检索等领域,都有着十分重要的意义。本文简要的介绍了web日志挖掘对于个性化网站建设中的应用。如何将这些技术深入、完善,并尽快运用到网络中,还需要进一步的研究。
[1]王丽娜.Web日志挖掘技术研究.光盘技术[J].2008,(4).
[2]高哲,魏海平,王福威,赵晓碧.基于Web日志挖掘的Web文档聚类[J].计算机工程与设计,2008,(9).
[3]Richard J.Roiger,Michael W.Geatz.数据挖掘教程[M].北京:清华大学出版社,2003.
[4]李珊,袁方.基于Web日志挖掘的页面兴趣度方法的改进[J].计算机时代,2007,(3).
TP393.18
A
1671-5993(2011)01-0065-02
2010-03-08
肖宏飞(1983-),男,安徽蚌埠人,合肥工业大学在读研究生,滁州职业技术学院教师。
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
华人时刊(2021年13期)2021-11-27 09:19:02
魅力中国(2020年19期)2020-12-08 03:46:15
心声歌刊(2020年4期)2020-09-07 06:37:14
河北农机(2020年7期)2020-01-08 05:22:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
大众文艺(2014年5期)2014-03-12 02:09:59
电子设计工程(2014年19期)2014-02-27 12:00:42
合作经济与科技(2011年15期)2011-08-15 00:50:50
电脑爱好者(2011年11期)2011-06-22 08:20:18
