
关于中国社会总体和谐度的调查分析
2011-09-05 02:47李春林屈驳韵
统计与决策 2011年13期
李春林,屈驳韵,万 平
(河北经贸大学 数学与统计学学院,石家庄 050061)
0 引言
《荀子·王制》有云:“和则一,一则多力,多力则强,强则胜物”,这其实是指一个多元兼容、统一一致、关系和谐的社会群体,定能够产生可战胜一切困难的强大力量!为研究当代中国社会和谐状况及其因素,我们在全国范围内进行了关于《当代中国影响人际关系和谐因素》的问卷调查,并收回有效问卷2972份。因为问卷样本数量巨大,知识丰富,为避免传统的单变量频数分析、对比分析或双变量列联表分析等在分析过程中造成的知识浪费,本文尝试采用数据挖掘的相关方法对所得数据从不同层面,不同视角进行深层次挖掘,力求获得更多有价值的知识。本文系属此次调查研究的部分成果,着重利用数据挖掘中多运用于市场调查和社会调查中的CHAID(卡方自动交互检测)算法,进行中国社会特定和谐满意度下的人群细分。
1 细分变量确定及数据描述
1.1 细分变量的确定
在查阅特定问题下人群特点细分的诸多研究中,发现常用的细分变量主要是性别、年龄、学历、收入水平、职业、个人所在地等。但随着社会经济的发展,思想文化水平的提高,人们看待问题的观点和侧重点也越来越复杂,仅仅利用这几类变量对中国社会和谐满意程度进行人群细分很难看出问题的本质。因此本文细分变量的确定借鉴了《CHAID分析在抽油烟机产品市场细分中的应用》[1](苏胜强,2006)的思想,将细分变量分为广度细分变量和深度细分变量,其中广度细分变量就是诸多研究中常用的有关被访者的基本信息,通过广度细分变量我国社会特定满意度下的人群可以直接形象的得到描述。而深度细分变量是被访者对影响当代社会总体和谐程度的经济、文化、政治、法律等深层次问题的认识状况。
1.2 数据的基本信息
根据调查问卷的情况采用3分Likert评测法,测试影响中国社会和谐诸因素发展状况,并将其作为深度细分变量,变量及其数据情况如表1。
2 CHAID算法的思想和步骤
2.1 CHAID算法的基本思想
CHAID的全称是Chi-squared Automatic InteractionDetector(卡方自动交互检测)。在1980年,由Kass等人提出,它的理论构想主要来源于决策树模型,根据反应变量在解释变量上的分布来划分人群,适用于分类和序次等级数据的分析,是一种以目标最优为依据,具有目标选择、变量筛选和聚类功能的分析方法[2]。它的基本分析思路是χ2自动交叉检验[3],首先选定分类的反应变量,然后用解释变量与反应变量进行交叉分类,产生一系列二维分类表。分别计算二维分类表的χ2值或似然估计统计量,以最大统计量的二维表作为最佳初始分类表,并继续使用分类指标对目标变量进行分类,重复上述过程直到满足分类条件为止[4]。
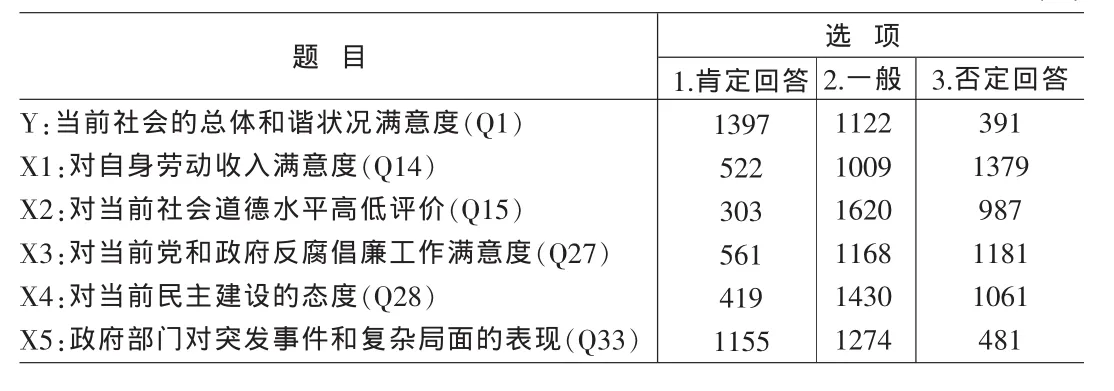
表1 影响中国社会和谐的因素及其数据情况表 (人)
2.2 CHAID算法的求解过程
本文以深度细分变量对中国社会和谐满意度进行人群特点挖掘为例来说明CHAID算法的求解过程。
(1)首先分别建立反应变量Y与5个细分变量Xj(j=1,2,3,4,5)之间的二维列联表。如反应变量Y(即Q1)与细分变量X4(即Q28)的二维列联表见表2:

表2 Y和分别与X4的列联表
通过式(1)和式(2)计算 Pearson_χ2统计量和似然比 χ2统计量(L2)。在CHAID算法中反应变量既可以为分类型或等级分类型,也可以是离散型或连续型,而解释变量要求为分类型或等级分类型。因此,当反应变量为分类型变量时,CHAID算法按式(1)计算反应变量与各解释变量所形成的二维列联表的Pearson-χ2统计量;当反应变量为等级分类变量或离散型变量时,CHAID算法按式(2)计算各二维列联表的L2;当反应变量为连续型时,则用F检验。
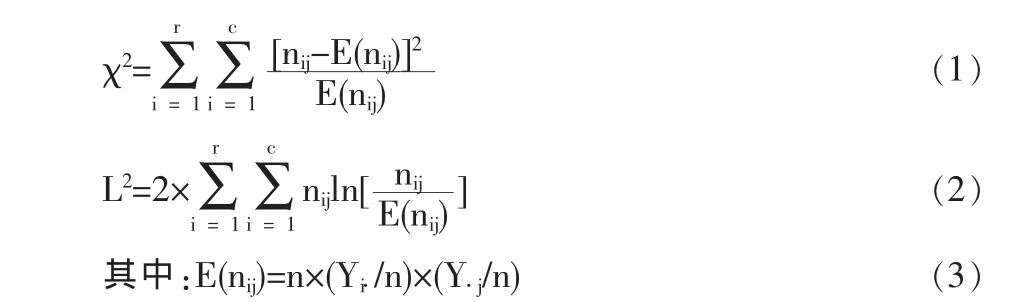
因为本文反应变量Y是3 Likert等级分类型,因此计算的是似然比χ2统计量,即L2。Y与深度细分解释变量Xj之间的二维列联表结果见表3:

表3 第一步细分的各列联表似然比χ2统计量(L2)
由表3可知,反应变量Y与各细分变量所构成的L2二维列联表的中,与X4所构成的列联表的L2最大,为416.667,因此将此列联表作为最佳初始分类表对反应变量Y进行细分。因为X4为3个类别,故列联表2可以拆分成3个2×4二维列联表,并计算各表的L2。当所有的L2≥(n)时,则按细分变量原有的类别细分反应变量,即将Y在按X4的三个类别进行细分;当其中某个L2≤(n)时,则将细分变量的这两个类别合并成一个新的类别来细分反应变量。当所有的L2≤(n)时,则不对反应变量进行细分。Y和X4的二维列联表拆分列联表及其如表4。
(2)第一步确定反应变量Y由细分变量X4分成三个类别,第二步细分将在这三个类别条件下构造反应变量Y与其他细分变量Xj(j=1,2,3,5)之间的二维列联表,并计算相应的L2,第二层细分的各列联表及其L2如表5。
由表5可知,在细分变量X4=1的条件下,Y与细分变量X3所构成的二维列联表的似然比χ2统计量最大为76.262,(如*标识)。因此在细分变量X4=1的条件下再对Y进行细分时,将以X3为细分变量进行下一层的细分。同理,在细分变量X4=2和X4=3的条件下,反应变量Y和细分变量X2之间的似然比χ2均为相应组最大,分别为73.188和93.885,因此将由细分变量X2进行下一层细分。接着,在此基础上进行与第一步同样方法的拆分,直到CHAID算法满足停止拆分的条件为止。

表4 Y和X4的二维列联表拆分列联表及其L2

表5 第二层细分的各列联表及其L2
CHAID算法停止拆分的条件有两个,第一个为第一步过程中的似然比χ2统计显著性检验;另一个是人为自定义的,本文中因为样本数量较大,CHAID决策树庞大,将决策树停止生长的条件定为父节点上最小样本为50个,子节点上的最小样本为30个。
3 细分结果分析
本文借助统计软件SPSS的Clementine数据挖掘模块中的CHAID决策树节点来实现CHAID算法的人群细分过程。在细分过程中,随着决策树的生长,分类维数的增加,对样本特征的描述越来越精确,决策树中度量这一性质的指标是索引,并且需大于1。
3.1 中国社会总体和谐满意度的广度细分人群特点
(1)对我国社会总体和谐程度满意的人群特点。包括河北省在内的中部各省的学历为中小学的公务员、商业一般收入、商业高收入及教师等知识分子中,中国社会总体和谐满意度为62.805%,高出全国平均水平14.798个百分点,尤其是河北省的这些属性的人群中满意度达77.78%,高出全国平均水平29.773个百分点,索引为1.62,这意味着当我们挖掘对中国社会总体和谐满意度高的人群属性时,锁定河北省中小学学历的公务员、商业一般收入、商业高收入及教师等知识分子,命中率与在所有人中随机抽查相比将提高1.62倍;中国军人、农民和工人的中国社会总体和谐满意度为57.886%,尤其是京津地区的这些人群,满意度达75%,高出全国平均水平23个百分点,且索引值为1.56,这意味着在挖掘对中国社会总体和谐满意度高的人群属性时,锁定京津地区的军人、农民和工人,命中率是在所有人中随机抽查的1.56倍。
(2)对我国社会总体和谐程度不满意的人群特点。仅从决策树模型的第一层来看,在校学生、待业、失业和自由职业者的中国社会和谐满意度仅为37.402%,低于全国平均水平达10.6个百分点。这些人群中,对中国社会和谐程度不满意的人比重为15.88%,高出全国平均水平2.443个百分点。尤其京津、中部地区及河北的青年大中专或中小学学历的在校学生、自由职业者、待业、失业人员中,有28.442%的人对中国社会总体和谐程度不满意,高出全国平均水平15个百分点,其索引值为2.12,而西部和东部沿海地区的这些人群中,不满意率为18.75%,索引值为1.39;另外还可以看到,京津和西部地区的本科或研究生学历的在校学生及自由职业者、待业、失业人员中,对中国社会不满意率为18.42%,高出全国平均水平4.98个百分点,且索引值为1.37。
因此从广度细分变量来看,中国社会总体和谐满意度高的人群主要为中小学学历的低学历人群,还有中国的军人、农民和工人对社会和谐程度满意度很高;而不满意度高的人群主要是在校学生,尤其像北京、天津等地区的学生不满意度均很高,另外西部地区的高学历者不满意度也值得关注。
3.2 中国社会总体和谐满意度的深度细分人群特点
由CHAID决策树模型(图略)可以看到,第一层细分变量为我国当前民主建设情况(X4),这说明人民在评价我国社会总体和谐程度时,首先关注的因素是我国民主建设状况。X4将反应变量细分为三个部份,对我国当前民主建设满意的人群中,社会和谐满意度达67.78%,高出全国平均水平19.77个百分点,不满意度仅为3.58%,低于全国平均水平近10个百分点;而对我国当前民主建设不满意的人群中,社会和谐满意度仅为27.99%,低于全国平均水平20个百分点,不满意度达27.427%,高出全国平均水平近14个百分点。
第二层细分变量为当前党和政府反腐倡廉工作满意度(X3)和当前社会道德水平高低(X2)。在对我国当前民主建设持满意态度的人群内部,人民更关注党和政府反腐倡廉工作力度,对当前党和政府反腐倡廉工作满意的人群中社会和谐满意度达84.72%,而对党和政府反腐倡廉工作不满意的人群中和谐满意度仅37.5%。在对我国当前民主建设一般满意或不满意的两个人群内部,人们更关注道德水平的高低。这两个人群中认为当前道德水平高的人群中社会总体和谐满意度分别为81.84%和66.01%,而认为当前道德水平低的人群中社会总体和谐满意度仅分别为44.44%和20%。
由决策树模型可以看到,树的终端叶节点主要是细分变量自身劳动收入水平满意度(X1)和政府在应对突发事件与复杂局面时的表现 (X5),这说明当人们对我国当前民主建设、反腐倡廉、道德水平等方面的满意程度一定时,会更关注自身收入水平和政府部门应对突发事件和复杂局面的能力。
因此,从深度细分变量可以看出,在构建社会主义和谐社会过程中,人们当前更关注我国民主建设、反腐倡廉和社会道德水平这三个方面。
4 结论
本文利用SPSS统计软件中Clementine数据挖掘模块对2910份调查问卷从广度和深度两个方面对特定社会和谐程度人群进行挖掘细分,挖掘出了令人满意的结果。尤其是发现农民的社会和谐满意度较高,说明当前我国的各项惠农政策产生了实效,让农民感觉社会更加和谐,生活更加幸福;同时发现我国高学历的在校学生对社会和谐满意度较低,这说明随着我国社会经济的不断发展,高学历者面临的竞争越来越激烈,尤其是就业压力越来越大等原因,使高学历者自身社会价值的实现越来越难,因此对社会和谐满意度偏低;另外,通过深度细分变量挖掘出了我国当前民主建设满意度、反腐倡廉工作、社会道德水平高低等问题是人们评价我国社会和谐与否的关键方面。
[1]苏胜强.CHAID分析在抽油烟机产品市场细分中的应用[J].商业研究,2006.
[2]王广州.AID和CHAID在多变量市场细分中的应用[J].研究市场与人口分析,1999.
[3]Chaturvedi A,Green P E,et al.SPSS for Windows,CHAID6.0[J].Journal of Marketing Research,1995,32(2).
[4]范晓清.决策树技术在手机市场细分中的应用[J].浙江统计,2004.
[5]宋家典.和谐社会的哲学底蕴[D].湘潭大学硕士学位论文,2007.
猜你喜欢
华人时刊(2020年23期)2020-04-13
成都信息工程大学学报(2019年3期)2019-09-25
中国财政年鉴(2019年0期)2019-08-31
电子制作(2018年16期)2018-09-26
中国财政年鉴(2017年0期)2017-07-04
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国财政年鉴(2016年0期)2016-06-05
专用汽车(2016年9期)2016-03-01
中国财政年鉴(2015年00期)2015-09-14
专用汽车(2015年2期)2015-03-01
