
应用无监督聚类算法评估电网安全水平
2011-08-16 00:48王同文
电力系统及其自动化学报 2011年6期
王同文,管 霖
(1.安徽电力调度通信中心,合肥 230022;2.华南理工大学电力学院,广州 510640)
智能电网被认为是当今世界电力系统发展变革的新制高点,也是未来电网发展的大趋势。智能电网的自愈性强调对电网运行状态实现连续在线自我评估与预防控制,及故障后的快速自我恢复[1]。这对电网安全稳定评估提出更高要求,主要体现在供稳定评估利用的信息是电网实时信息,评估方法需满足连续在线评估的要求。因而,研究基于广域信息的电网在线稳定评估方法渐成趋势[2]。
在利用电网实时信息实现系统稳定评估方面,人工智能技术因具有学习能力强、评估速度快、提供潜在有价值信息等特点,被认为是一个有发展前景的电网稳定在线评估研究方向[3,4]。
基于人工智能技术的电网安全评估模型通过学习大量训练样本中包含的潜在数据结构信息,而后利用这些信息实现未知样本稳定水平的判别。该类型算法往往由于训练样本的局限性而导致模型的推广性差。尽管增加训练样本规模可提高算法性能,但构造足够多的计及各种运行方式的训练样本几无可能,而采取样本库逐步扩充的思路又由于大多数智能学习模型在面对增量式数据集时需对所有样本重新学习致使算法学习效率下降。
对此,提出一种基于子空间扩展的聚类算法,并基于该算法提出一种电网安全评估新思路。算法以样本为基础,构造一个最小子空间,逐步扩展该子空间,直到获取一个包含样本分布结构的最优子空间;通过这些子空间的归并获得样本聚类结果。算法所需先验知识少,聚类结果可解释性强,其自下而上的扩展策略保证算法对增量式数据挖掘具有良好的适应性。在IEEE两个测试系统上的应用结果验证所提电网安全评估思路的有效性。
1 聚类算法概述
聚类包含两个关键问题[5]:接近度的度量和类簇的分组。接近度的度量主要评估两个实体的相似程度,以决定是否属于同一簇;类簇的分组即是指划分簇的策略。样本相似度度量指标较多[5~9]。常用的有距离指标,如k均值算法;频率或密度指标,频率越高或密度越大的区域包含聚类的可能性越大;信息墒指标,认为由相近样本形成的区域与由相离样本构成的区域相比具有的信息墒更小;此外,还有诸如“cohesion”指标、留数指标等。
类簇的分组方式大体有划分型、层次型及混合型3种[5~9]。划分型即是将训练样本或样本空间划分为n个子集或子空间,分析这n个子集或子空间类簇的信息。层次型方法通过分解所给定的数据对象集来创建一个层次,包含分裂和凝聚两种方式。该类型方法的困难在于类簇划分或合并的选择,选择不适宜将导致低质量的聚类结果。混合型即是划分型与层次型的结合。为提高算法对增量式数据集的挖掘性能,算法为每一个可能需要构造最大子空间的样本构造一包含数据结构分布信息的最优子空间,依据最优子空间的连通关系获得聚类结果,可理解为广义的层次型聚类。样本相近度的度量指标则采用留数指标[9],其潜在含义是,从统计学角度看,包含训练样本越多的子空间越能反映样本集在特征空间中的分布知识。
2 基于子空间扩展的聚类算法
2.1 接近度的度量:留数指标
文献[9]提出的留数指标定义一种从统计学的角度定量衡量空间内样本密集程度,能排除随机干扰样本对结果的影响,如式(1)所示。
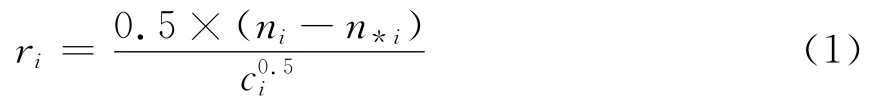
式中:ci=0.5×mi×(1-mi/N),N 为样本规模;mi=0.5×(ni+n*i),ni为区域i内样本数目;而n*i为随机分布对应的样本数目,且n*=v×N,体积v为该子空间的体积。
由式(1)可知,空间i的留数ri越大,该空间内样本分布与随机样本分布差别越大,也即包含数据结构信息越多。文中定义若空间i的留数ri≥1.96则视为包含聚类信息,否则视为随机分布。
2.2 簇的划分:层次型聚类
其思路是:从一个随机样本出发,构造一个最小的超矩形空间,并逐步扩展,直到满足约束条件为止;计算该子空间的留数,根据留数大小确定是否包含聚类信息;如包含,则运用最外层样本作为下一步构造类似子空间的起点,如不包含,则选择另一个样本为起点;如此循环,直至所有样本分析完为止;最后,根据包含聚类信息的子空间连通关系,获得训练集聚类结果。
该思路包含几个关键问题:最小超矩形空间如何定义、子空间如何扩展、终止条件及下一个扩展起点如何选择等。以一二维平面数据集为例阐述以上4个问题。
如图1所示。首先随机选择样本x1作为起点,构造一个最小矩形空间,如图中粗线框所示。最小子空间是频率n为2的子空间,即除该样本外,只有一个样本落入该空间。
然后不断向外扩展该子空间,扩展速度则根据下式确定。

对于一个密集区域,在扩展初期,由于其聚集特性,留数呈增加趋势;随着扩展的继续,其稀疏特性表现越明显,故而留数呈降低趋势。据此,文中定义式(3)开始减小作为子空间扩展的终止准则。
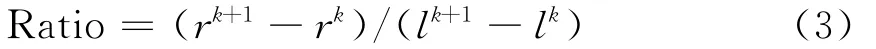
为最大程度降低计算负担,定义最大子空间及最优子空间两个概念。最大子空间即为扩展过程中的最外层超矩形空间,最优子空间定义为最大子空间的前一次扩展空间,如图1所示。
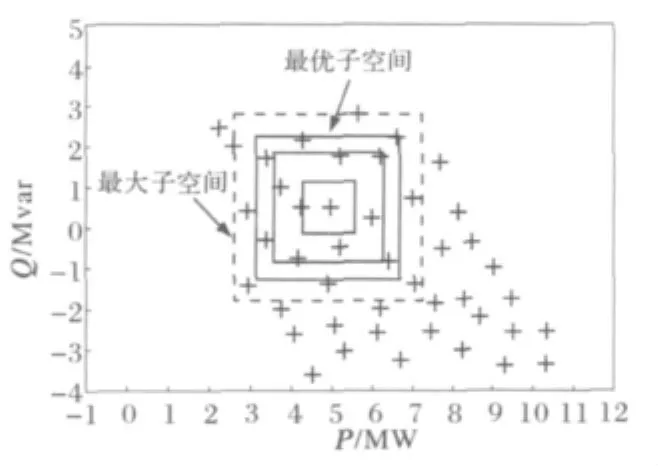
图1 最优子空间搜索示例Fig.1 Example of searching for an optimal subspace
从样本密集的角度看,最优子空间内样本分布较密集,已无对空间内其它样本构造类似子空间的必要;且介于最大子空间与最优子空间两空间之间的样本近似描述了最优子空间形状。故选择这些样本作为构造最小子空间的新起点。如图2所示x2和x3。
按上述思路,以此类推,直到所有样本分析完为止。
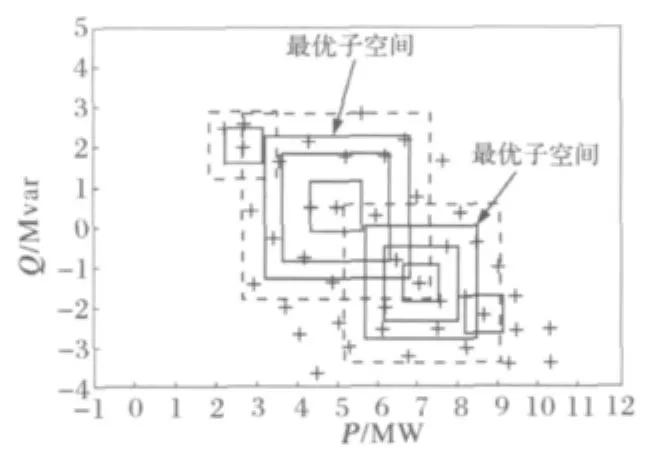
图2 空间扩展过程示例Fig.2 Example of the extension process
2.3 算法步骤
基于子空间扩展的聚类算法步骤如下:
步骤1 记训练样本集为T;
步骤2 定义当前需要扩展最大子空间的样本集D为空集,并记所有可能需要构造最大子空间的样本集为扩展集E,初始时E等于样本集T;
步骤3 从扩展集E中随机选择一个样本作为起点,构造一最小子空间,同时从扩展集E中删除该样本;
步骤4 按式(2)不断扩展该子空间,以式(3)为终止条件;
步骤5 若按步骤4获得一个最大子空间,则将最优子空间内的样本集从扩展集E中剔除,将属于E集中的位于最大子空间与最优子空间之间的样本归入D集,同时将这些样本从E集中删除,以更新扩展集E,转入步骤6;否则,标记该样本所属类别,从扩展集E中剔除该最小子空间内包含的样本,转入步骤6;
步骤6 判断D是否为空集,如是,则转入步骤7;否则,从D集中选择下一个起始样本,并转入步骤4;
步骤7 判断扩展集E是否为空集,如是,则转入步骤8;否则,转入步骤3;
步骤8 算法结束,输出聚类结果。
2.4 在人造数据集的测试
为显示基于子空间扩展的聚类算法性能和应用过程,构造2组二维数据集进行测试,图中带有圆框的样本为算法识别出代表聚类形状的边界样本。
图3显示算法准确地识别出样本数量较少的聚类。
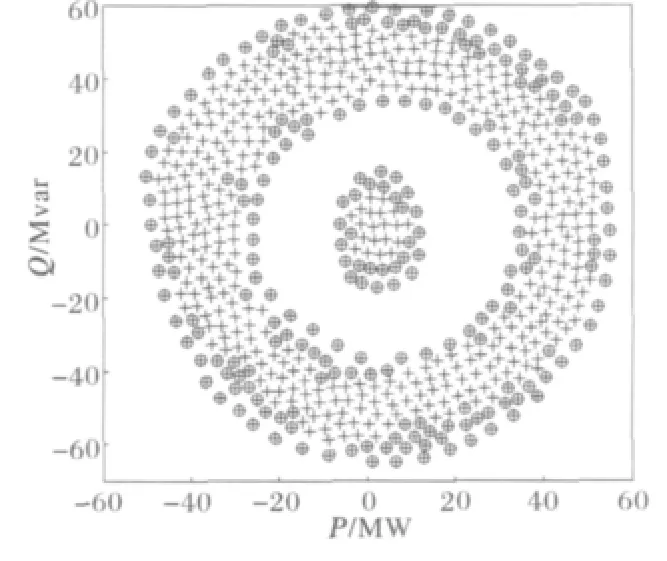
图3 聚类结果展示Fig.3 Clustering result of the test data set
对于大多数智能学习模型,处理新增样本时,需对所有样本重新学习。而文中所提算法仅需对新增样本构造最优子空间,大大提高算法学习效率。图4和图5展示了算法处理增量式数据集聚类结果,证实了算法的性能。
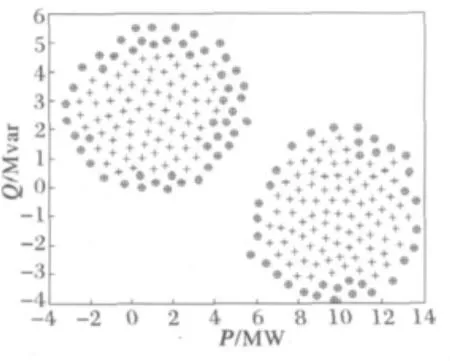
图4 聚类结果展示Fig.4 Clustering result of the test data set

图5 聚类结果展示Fig.5 Clustering result of the test data set
3 基于聚类算法的电网安全评估
3.1 评估思路
首先构造大量训练样本,通过特征裁减技术提取稳定评估关键稳态状态量,而后应用所提聚类算法挖掘训练样本中包含的聚类知识,以描述聚类边界的训练样本为参考样本,采用常规k近邻法完成未知样本稳定水平的识别。在构造训练样本时,调整负荷水平及分布,相应改变发电机出力,在每种潮流方式下,采用BPA仿真工具获得不同故障位置下CCT值。故障类型为三相瞬时性故障。
根据相关文献[9,10],选择系统稳态量构成初始输入集,这些量包括发电机的有功、无功出力();系统中支路的有功、无功潮流(、);系统 中支路的有功损耗、无功损耗(、)等状态量。由于稳态运行信息与系统规模成比例增长,须采用特征选择技术进行特征属性约减。文中采用基于遗传算法的嵌入式特征选择算法实现特征空间的有效裁减[10]。
以IEEE两个测试系统为例展示所提电网安全评估思路的应用结果。
3.2 IEEE9节点系统
测试系统结构如图6所示。训练集和测试集规模分别为300和60。
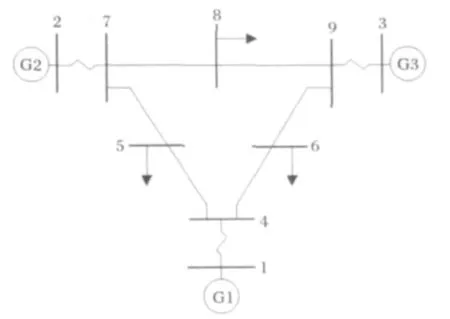
图6 IEEE9节点测试系统Fig.6 IEEE 9-bus testing system
运用文献[10]的特征选择算法,对母线7故障提取的稳定评估关键稳态特征集包括P1G、P2G、、等4个状态量。
应用所提聚类算法,对300个测试样本进行分析,共发现6个簇类,约有51.3%的训练样本被算法识别为类别边界样本。考虑电网评估需求,根据簇类间连通关系,将这6个簇类聚合归并为低、中、高稳定水平类。
以这些类别边界样本为已知类别样本,运用k阶近邻法(取k=5)对测试集进行分类,与按样本CCT分类相比,准确率约为86.7%。
3.3 IEEE39节点系统
测试系统如图7所示。测试集和训练集规模分别为500和100。
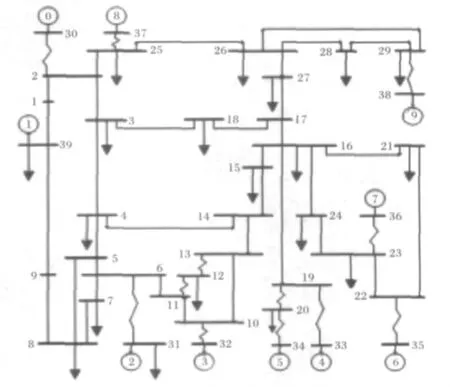
图7 IEEE新英格兰测试系统Fig.7 IEEE New-England test system
运用文献[10]的特征选择算法,对母线26故障提取的稳定评估关键稳态特征集包括、P17-27、Q2-25、等5个状态量。
与IEEE9节点测试系统类似,算法共识别出10个簇类,约有60.6%的训练样本被识别为边界样本。根据簇类间的连通关系将这10个簇类归并为3大类,以60.6%的训练样本为已知类别样本,对测试集的分类正确率为91%。
4 算法应用讨论
在IEEE两个测试系统的应用结果验证所提基于无监督聚类算法的电网安全评估新思路的有效性。进一步分析可知,依据类别边界样本,可方便地从中获取丰富的预防控制所需信息。
从算例分析看,针对指定位置故障,所提电网安全评估思路只需监测少数几个从EMS系统获取的稳态运行变量即可粗略实现稳定水平评估。此外,计及到聚类算法特点,可方便地将日常运行方式数据补充进样本库供算法学习,以提高算法性能。对于一个实际系统而言,只需针对若干稳定薄弱点设计类似评估模型,即可有效地掌握全系统的稳定水平。然而,考虑到电网拓扑结构变化较频繁,而文中分析并未涉及这一问题,因此实现算法在线应用仍需更进一步研究。
从测试结果看,文中所提电网安全评估思路的推广能力一般。一方面是因测试集规模较小,与有导师的学习算法相比,无监督聚类算法在样本规模较小时很难挖掘出足够多的知识。二是因CCT值的连续性,在簇类归并过程中,低、中、高稳定水平类中的簇类具有一定的重叠性,按连通紧密程度的族类合并过程影响了后续稳定水平识别的准确率。今后将在这两方面开展研究,以提高算法性能。
5 结论
1)提出一种基于无监督聚类算法的电网安全评估新思路,在IEEE两个测试系统的应用结果证实了思路的有效性。
2)提出的基于子空间扩展的无监督聚类学习算法具有可解释性强、适合处理增量式数据集、所需先验知识少、对数据形状适应性强等特点。
[1]姚建国,赖业宁(Yao Jianguo,Lai Yening).智能电网的本质动因和技术需求(The essential cause and technical requirements of the smart grid)[J].电力系统自动化(Automation of Electric Power Systems),2010,34(2):1-4,28.
[2]卢芳,于继来(Lu Fang,Yu Jilai).基于广域相量测量的暂态稳定快速评估方法(WAMS based power system transient stability assessment)[J].电力系统自动化(Automation of Electric Power Systems),2010,34(8):24-28.
[3]王同文,管霖,张尧(Wang Tongwen,Guan Lin,Zhang Yao).人工智能技术在电网稳定评估中的应用综述(A survey on application of artificial intelligence technology in power system stability assessment)[J].电网技术(Power System Technology),2009,33(12):60-65.
[4]汤必强,陈允平,邓长虹(Tang Biqiang,Chen Yunping,Deng Changhong).基于遗传算法优化的复合神经网络在稳定评估中的应用研究(Application of compound neural network based genetic algorithm optimizing for power system transient stability assessment)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2004,16(1):6-10,18.
[5]朱玉全,杨鹤标,孙蕾.数据挖掘技术[M].南京:东南大学出版社,2006.
[6]Jing Liping,Ng Michael K,Huang Joshua Zhexue.An entropy weighting k-means algorithm for subspace clustering of high-dimensional sparse data[J].IEEE Trans on Knowledge and Data Engineering,2007,19(8):1026-1041.
[7]Yip Andy M,Ding Chris,Chan Tony F.Dynamic cluster formation using level set methods[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2006,28(6):877-889.
[8]Lin Cheng-Ru,Chen Ming-Syan.Combining partitional and hierarchical algorithms for robust and efficient data clustering with cohesion self-merging[J].IEEE Trans on Knowledge and Data Engineering,2005,17(2):145-159.
[9]王同文,管霖,张尧(Wang Tongwen,Guan Lin,Zhang Yao).基于留数分析的模式发现算法的改进及其应用(Modified pattern discovery algorithm based on residual analysis and its application)[J].华南理工大学学报:自然科学版(Journal of South China University of Technology:Natural Science Edition),2009,37(7):100-105.
[10]管霖,王同文,唐宗顺(Guan Lin,Wang Tongwen,Tang Zongshun).电网安全监测的智能化关键特征识别及稳定分区算法(Intelligent algorithm for kernel feature identification and stability-based system division in power grid security monitoring)[J].电力系统自动化(Automation of Electric Power Systems),2006,30(21):22-27.
猜你喜欢
数学大王·趣味逻辑(2021年11期)2021-12-03
科技创新与应用(2020年6期)2020-02-29
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
河南电力(2016年5期)2016-02-06
河南电力(2015年5期)2015-06-08
河南电力(2015年5期)2015-06-08
