
Hadoop云计算平台在视频转码上的应用
2011-08-08 12:48:18张浩孙淑霞
电脑与电信 2011年12期
张浩 孙淑霞
(成都理工大学信息科学与技术学院, 四川 成都 610059)
1.引言
随着网络技术的发展,网络可提供的服务越来越多。视频业务作为一种典型的网络服务,具有极大的发展潜力和市场规模。与其它业务比较而言,视频业务有自身特点:视频处理过程对计算能力要求高;视频的编码、解码、实时视频处理等技术,涉及到大量的空域频域的变换,在时效性较强的视频业务中,对计算能力构成很大挑战。Hadoop是一个开源的云计算框架,它是一个适合处理海量数据的并行编程系统,可以根据输入数据分布等信息自动创建多个并行子任务,并将子任务调度到合适的集群节点上并行执行。所以此模型能够很好地适用于多个视频文件同时转码。MapReduce是Hadoop系统的一个核心模块,它使得程序员不必关心节点失效、任务失效及任务之间的数据等问题,而只需按照MapReduce编程规范定义好map函数、reduce函数以及一些数据格式信息,即可完成分布式数据处理问题。
2.Hadoop介绍
谈到Hadoop不得不提到云计算,云计算是网格计算、分布式计算、并行计算、效应计算、网络存储、虚拟化、负载均衡等传统计算机技术和网络技术发展融合的产物。云计算的基本思想是通过构建大规模的基于集群系统的数据中心,将集群中的资源以虚拟化的形式向用户提供资源池。总之,云计算是在分布式计算的技术基础上的更高层次的“集中式”计算处理模式,Hadoop是由Apache开源组织的一个分布式计算框架,可以在大量廉价的硬件设备组成的集群上运行应用程序,为应用程序提供了一组稳定可靠的接口,旨在构建一个有高可靠性和良好扩展性的分布式系统,它是现在实现云计算的主要可选方式之一。Hadoop主要包括Hadoop分布式文件系统和计算模型MapReduce两个部分。
2.1 HDFS分布式文件系统
HDFS有着高容错性(fault-tolerent)的特点,设计用来部署在低廉的(low-cost)硬件上。它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS采用Master/Slave架构,一个HDFS集群由一个NameNode节点和一组DataNode节点组成;NameNode管理文件系统的元数据,而DataNode存储了实际的数据。
2.2 MapReduce分布式并行计算模型
MapReduce是由Google提出的云计算核心计算模型,提供了比多线程编程更上一层的接口,屏蔽了许多细节性问题,降低了开发者的入门门槛,提高了开发分布式程序的效率。MapReduce是一个用于大数据量计算的编程模型,同时也是一种高效的任务调度模型。在MapReduce计算模型中,需要用户提供两个关键函数,map函数和reduce函数,即映射和规约两个主要过程。MapReduce框架运行于HDFS文件系上面,这两个函数对一组键值对(key/value)进行操作,得出另一组键值对:(input)
3.基于Hadoop的视频转码系统
3.1 系统说明
通过上面关于云计算和Hadoop相关知识的介绍,结合大批量、多用户视频转码对计算资源的需求,实现基于Hadoop云计算平台的视频转码。本项目视频处理类的实现是基于音视频转换软件ffmpeg,通过MapReduce中map函数封装ffmpeg转码功能,当大量视频转码任务提交到集群时,系统自动把任务随机分配到集群节点上,利用集群系统计算能力和已有视频转码开源软件实现多视频同时在线转码。关于视频转码相关技术如码率转换、空间分辨率转换、时间分辨率转换、语法转换、容错视频转码等都交给已有的转码软件来实现。关于Hadoop集群的搭建可以通过网络、书籍找到大量相关资料,关于具体map函数、reduce函数以及key、value对的划分等细节问题这里也不做详细解释,只给出了视频转码的开发框架。
在本设计中,使用Java提供的Runtime类进行本地转码功能代码的调用。这样做的好处是:不论本地视频处理功能是由什么编程语言实现的,只要最终的形式是可执行文件,都可以被MapReduce框架调用。Runtime类可以取得Java虚拟机的运行时环境,这个类有一个非常有用的方法exec(String cmdArray[])用于调用本地可执行文件。此方法的参数是要被调用的可执行文件的命令行字符串数组。该字符串数组的值取决于视频处理功能的具体实现。
3.2 Hadoop架构实现
Hadoop系统包括分布式文件系统HDFS、并行计算框架MapReduce、作业队列管理模块。HDFS用于存储本地上传的视频文件,MapReduce框架用于完成视频转码功能,作业队列管理模块用于接收本地提交的任务信息,分析任务,将任务分割给云节点的计算单元,最后将视频转码后的信息写入数据库。
视频转码框架如图1所示:
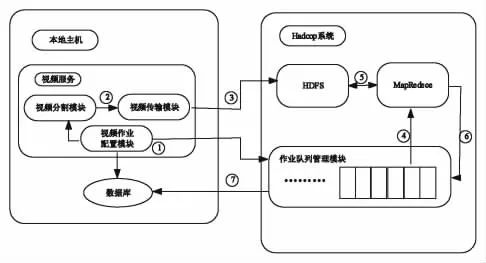
图1 视频转码系统整体架构
Hadoop系统中的视频作业控制模块主要由5个模块组成。各个模块的功能如下:
(1)子作业流创建模块:一个视频处理作业可以划分为多个MapReduce子作业,根据视频开发用户提供的信息生成一系列的MapReduce作业流,包括视频作业子作业的个数和各个子作业之间的依赖关系。
(2)视频作业信息模块:此模块用于维护一个视频作业完成状态信息和各个子作业的完成进度信息以及各个子作业的文件输出位置等信息。子作业提交模块根据此模块和子作业创建模块提供的信息决定哪个时间提交子作业流中的一个MapReduce子作业。
(3)子作业提交模块:此模块对视频作业信息模块中的子作业信息进行监控,一旦满足作业提交的要求,从子作业流创建模块中取出一个子作业,提交到Hadoop中执行。
(4)子作业监控模块:此模块负责向Hadoop系统获取各个子作业完成的状态信息,并负责更新视频作业信息的完成状态。
(5)作业清理模块:此模块用于一个视频作业完成后,清理完成视频作业的过程中HDFS上的临时文件,并将视频作业的完成状态存入数据库中。

图2 视频处理流程图
视频处理流程如图2所示流程详细过程如下:
(1)用户将需要处理的视频上传到HDFS上;
(2)将视频的处理信息和所要用到的处理函数传递到视频处理框架中;
(3)子作业创建模块创建一个子作业流和一个视频作业信息模块;
(4)子作业提交模块根据各个子作业流的依赖关系和各个子作业的完成状态向Hadoop系统提交MapReduce子作业;
(5)Hadoop框架执行MapReduce子作业,将各个子作业的结果写入到HDFS中;
(6)子作业监控模块从Hadoop系统中获取各个子作业的完成状态并更新视频作业信息模块;
(7)整个视频作业完成后,作业清理模块负责清理HDFS上中间子作业输出的临时文件并更新视频作业信息模块。
4.实验及结果分析
集群使用两个节点作为转码工作节点,测试数据大小为700M,分布式文件系统块大小为64M。测试结果如表1所示。
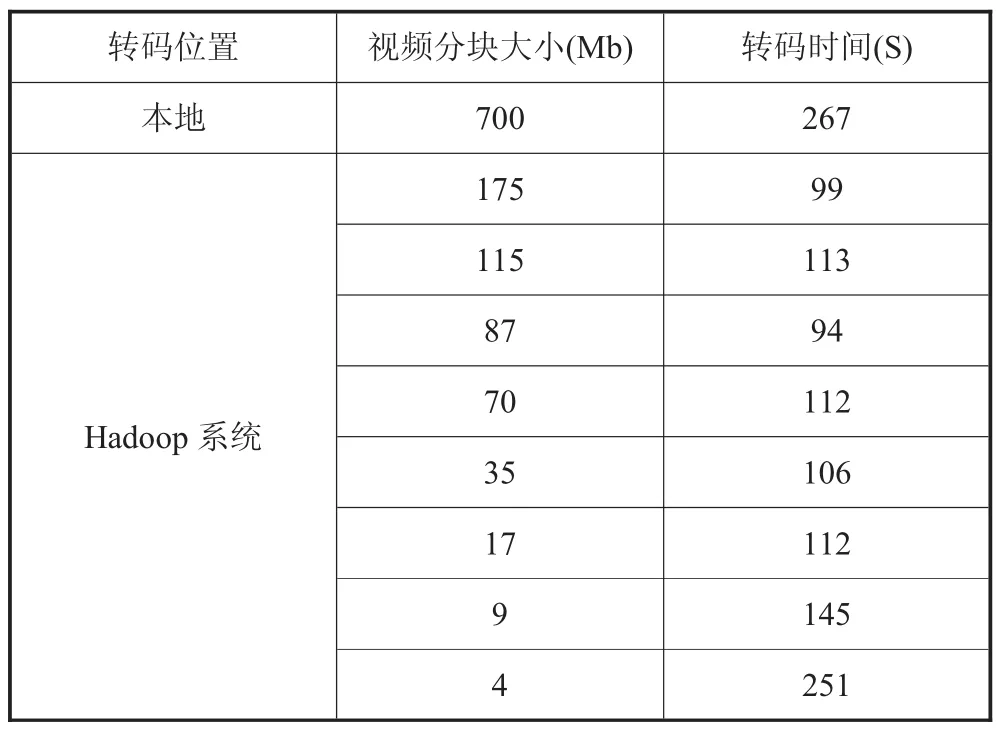
表1 集群转码性能
从表1可以看出:
(1)集群转码的时间平均时间约为单机转码所用时间的1/2,这个结果与期望的结果一致。这说明了将视频转码移植到Hadoop平台上可以提高转码效率。
(2)当视频文件分片远远小于文件系统分片的大小的时候,集群的转码性能会恶化。这表明Hadoop系统适合处理大数据量的应用。
5.结束语
本文主要论述了在Hadoop平台上视频转码的设计与实现。随着视频数据量的急剧增长,传统的集中式视频转码系统存在存储能力和数据处理能力不足、存储能力和处理能力不可扩展的缺点。Hadoop系统的并行任务分配、任务本地化、可扩展性和高容错性使得Hadoop系统在数据密集型任务处理方面有着优秀的表现。视频处理任务是一种数据密集型任务,将视频转码任务移植到Hadoop系统中可以充分利用现有的计算资源,使得视频转码效率得到提高。
[1]Chuck Lan.Hadoop INACTION[M],Manning Publications,2011.
[2]Hadoop 官 方 文 档 .http://Hadoop.apache.org/common/docs/toturial.htm[EB/OL].
[3]K.Breitman,M.Endler,R.Pereira,M.Azambuja.."When TV Dies,Will It Go to the Cloud?".IEEEComputer Society,2010:81~83.
[4]FFMpeg.http://ffmpeg.org[EB/OL],2011.
[5]Koetter R.Converting video formats with FFmpeg.Linux Journal archive,2006.
猜你喜欢
广东通信技术(2023年11期)2023-12-10 12:28:38
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
缔客世界(2020年1期)2020-12-12 18:18:28
数学物理学报(2020年3期)2020-07-27 01:19:46
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
传播力研究(2018年7期)2018-05-10 09:42:47
中国交通信息化(2017年3期)2017-06-08 06:09:28
法大研究生(2017年1期)2017-04-10 08:55:06
知识就是力量(2017年2期)2017-01-21 18:29:36
