
文本挖掘的方法及应用研究
2011-08-08 12:48张晓艳华英
电脑与电信 2011年12期
关键词:关联分析
张晓艳 华英
(苏州市职业大学计算机工程系,江苏 苏州 215104)
1.引 言
传统的数据挖掘主要针对结构化的数据,如关系的、事务的和数据仓库数据。但随着互联网应用的兴起和普及,涌现出巨量的电子信息,如电子文档、电子出版物、万维网等,其中以文本形式的信息占比最大。这些文本信息存储在文本数据库中,属于半结构化数据。文档挖掘技术可帮助用户比较非结构化的文本信息,确定文档的重要性和相关度,找出多个文档的共通模式或趋势,成为数据挖掘中的一个重要研究方向。
2.文本挖掘的处理过程
文本挖掘从数据挖掘发展而来,但面向的是半结构化或非结构化的文本数据,无确定形式并且缺乏机器可理解的语义;因此除采用数据挖掘的一些常见方法之外,还涉及到文本分析、模式识别、统计学、数据可视化、数据库、机器学习等技术的运用。
文本挖掘的处理过程主要包括对含有大量文档集合的内容进行文本预处理、特征提取、结构分析、文本摘要、文本分类、文本聚类、关联分析、质量评估、模式生成、结果输出等,如图1所示。
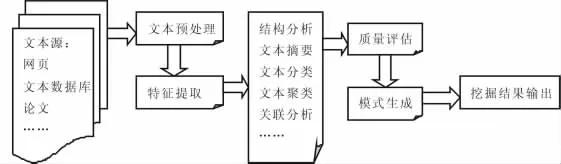
图1 文本挖掘的处理过程
文本预处理的目的是选取任务相关的文本并将其转化成文本挖掘工具可以处理的中间形式。特征提取一般会构造一个评价函数,对每个特征进行评估,按分值高低排列,预定数目分数最高的特征被选取。接着将进行一系列分析挖掘步骤,利用机器学习、数据挖掘以及模式识别等方法提取面向特定应用目标的知识或模式。在最后挖掘结果输出前,需根据已经定义好的评估指标对获取的知识或模式进行质量评估。如果不符合要求,则要返回到前面的环节重新调整和改进。
3.文本挖掘主要方法分析
从图1可以看出,整个文本挖掘处理过程中,重点集中在一系列分析挖掘步骤上,这些步骤的操作对象是提取出来的关键词、标记或语义信息,其中最主要使用的方法有:关联分析、文本分类和文本聚类。
3.1 关联分析
关联分析首先要对文本数据进行分析、词根处理、去除停用词等预处理,再调用关联挖掘算法,如Apriori算法。关联挖掘算法多使用支持度—置信度框架,最小支持度和置信度阈值可排除大量无益的规则。在文本数据库中,视每个文档为一个事务,文档中关键词的集合视作是事务中的项集。所以文本数据库中关键词关联挖掘的问题就映射为事务数据库中项的关联挖掘。关联挖掘过程有助于找出复合关联,即领域相关的术语或短语,如[西红柿,蔬菜],也可找出非复合关联,如[基金,银行,证券,投资]。这样的关联挖掘也被称为“术语级关联挖掘”,便于找出术语和关键词间的关联。具有无需人工标记文本、极大减少算法的执行时间和无意义结果的优点。
3.2 文本分类
由于存在大量的文本,自动对这些文本分类组织以便于检索和分析,是文本挖掘至关重要的任务。文本分类是一种“有教师”的机器学习方法。首先要取一组预处理的文本特征向量集作为训练集,每个训练集有个类别编号;然后选择分类方法分析训练集并导出分类模式;再检验这个分类模式以求精;最后用训练好的分类模型对其它待分类文本进行分类。常用的文本分类方法有:
(1)最邻近分类法。将全部训练文本进行简单索引,每个文本都关联到对应的类别编号。当提交一个检验文本时,把它当作查询提交,并从训练集中检索出与查询最相似的n个文档。检验文档的类别编号由它的n个最邻近的类别编号的分布决定。这种方法需要相对其它分类方法会占用更多的存储训练信息的空间和查找倒排索引所消耗的时间。
(2)特征选择分类法。向量空间模型可能会将大权重赋予某些稀有词,而不管它的类分类特征如何,这些稀有词的存在可能会导致无效的分类。此时可以使用特征选择分类法删除训练文本中与类别编号不相关或冗余的词,其目的是找出最小特征集,使得数据类的概率分布尽可能接近使用所有特征得到的原分布。使用特征选择删除非特征词后,产生的训练文本分类结果更有效。
(3)贝叶斯分类法。这是一种统计学分类方法,因为文本分类可以看作是计算文本在特定类中的统计分布。贝叶斯分类器首先通过对每个类x计算文本y的生成的文本分布P(x|y)来训练模型,然后测试哪个类最可能产生检验文本。贝叶斯分类可以预测类成员关系的可能性,适用于处理高维的数据集,准确率和速度均较高。
3.3 文本聚类
文本聚类是一种“无教师”的机器学习方法。依据著名的聚类假设:同类的文本相似度较大,不同类的文本相似度较小。它从给定的文本本身出发,根据文档特征词向量,将相关者聚为一类。与分类不同,聚类由于不需要训练过程,也不需要预先对文本标注类别,聚类要划分的类是未知的,因此灵活性和自动化处理能力更强一些。常用的文本聚类方法有:
1.光谱聚类法。先将原始数据运行维度归约(光谱嵌入),然后对维度归约后的文本空间运用k均值或k中心聚类算法。光谱聚类法因与微分几何学联系密切,便于发现文本空间中的流行结构,而具有处理高度非线性数据的能力。这种方法也有缺点,对嵌入的学习要使用到所有的数据点,如果数据集很大,那会消耗大量的时间,因此并不太适用于大型数据集。
2.混合模型聚类方法。分为两个步骤:①基于文本数据和附加的先验知识估计模型参数;②基于估计的模型参数推断聚类。这种方法通常涉及多项式支模型,能同时聚类词和文本。概率潜在语义分析和潜在狄利克雷分配是经常使用到的模型。混合模型聚类方法的优势是,可以对簇进行设计,更有利于文本的比较分析。
4.文本挖掘的常见应用
(1)信息检索。信息检索关注的是基于大量文本的文档信息的组织和检索。信息检索包括联机图书馆目录系统、联机文档管理系统和Web搜索引擎等。信息检索的典型问题是根据用户查询,在文本集合时定位相关文档。信息检索系统的一般流程为:对文本集合建立倒排索引、分析用户查询请求、匹配文档与查询请求、对查询结果进行排序以及用户相关度回馈。
(2)自定义组织联机文档。对于联机文档,可以自行制定组织方案,利用文本分类对这些文档进行自动编目。方便用户不仅能够浏览文档,并且还可以通过限制搜索范围提高查找效率。
(3)改进搜索引擎的检索结果。利用文本聚类方法,把搜索引擎的检索结果分为若干簇,加以标注,改善用户查看检索结果的方式,帮助用户从无关联的线性文档列表转为查看有规律的分类结果。
(4)提升商务电子化的管理效率。实施电子商务的企业可通过对客户访问信息、商品访问情况和销售记录情况等的文本挖掘,了解客户的兴趣与需求,跟踪产品的市场反映,收集客户的信誉度,帮助企业提升管理效率。
5.结束语
文本挖掘作为数据挖掘的研究分支,在对半结构化和非结构化数据提取有效规律和规则方面有着明显的优势。在处理不同数据集时,应根据数据集的维度和组织情况选择最适用的挖掘分类方法。随着文本挖掘研究的深入,其应用领域还将不断拓展。
[1]阮忠,邓春燕.Web文本挖掘的方法及其应用研究[J].农业网络信息.2008,(9):27-29.
[2]程显毅,朱倩著.文本挖掘原理[M].北京:科学出版社,2010.
[3]Bing Liu著,俞勇,薛贵荣,韩定一译.Web数据挖掘[M].北京:清华大学出版社,2009.
[4]白翎雁,才书训.Web文本挖掘及相关技术研究[J].沈阳工程学院学报(自然科学版).2008,4(3):260-261.
[5]谢冬,刘宏申.文本挖掘中若干关键问题的研究[J].电脑知识与技术.2009,5(18):4773-4774.
猜你喜欢
网络空间安全(2017年1期)2017-03-10
江苏农业科学(2017年1期)2017-02-27
档案管理(2017年2期)2017-02-25
江苏农业科学(2016年8期)2017-02-15
江苏农业科学(2016年8期)2017-02-15
计算机应用(2016年12期)2017-01-13
软件导刊(2016年11期)2016-12-22
科技视界(2016年15期)2016-06-30
电脑知识与技术(2016年4期)2016-04-11
