
遗传支持向量机及其在人民币汇率变动方向预测中的应用
2011-07-24 09:35徐成贤
统计与决策 2011年22期
徐成贤,陈 静,王 昭
(1.杭州师范大学 国际服务工程学院,杭州 310012;2.西安交通大学 a.经济与金融学院;b.理学院,西安 710049)
0 引言
在布雷顿森林体系崩溃后,随着浮动汇率制度的实施以及外汇管制的放松,汇率的变动频率越来越快,对汇率变化的预测已成为金融监管当局、投资者和金融分析专业人士普遍关心的一个焦点。汇率影响因素的多元化使得汇率变化行为更加复杂,呈现出非线性的特点,这些特点加大了汇率预测的难度。
支持向量机(Support Vector Machine,SVM)是Vapnik等人[1][2]于1995年提出的数据挖掘的一个新方法,并已成功地应用于金融时间序列的预测预报[3~5]。SVM的特点是能够同时最小化经验误差与最大化分离间隔,且训练预测模型的过程是求解一个具有唯一最优解的二次约束最优化问题,这使得该方法的复杂程度仅取决于所要求解的精度以及训练样本的数量,而与输入空间的维数无关,避免了维数灾难这一难题。多项式光滑[6]与不等权重[7]则是提高SVM求解和预测效果的两个有效措施。基于以上研究,本文拟首先给出不等权重支持向量机(USVM)及其多项式光滑处理;然后应用此不等权重支持向量机给出对美元/人民币、欧元/人民币、日元/人民币汇率变动作预测的多变量预测模型;接着将不等权重支持向量机方法应用于训练样本集的子集来确定预测模型(减少训练样本的数量),再用遗传算法对预测模型作全局优选,由此形成将两者组合的遗传不等权重支持向量机方法(GAUSVM);最后就(GAUSVM)方法的预测效果进行实证分析。
1 算法分析
1.1 不等权重支持向量机与多项式光滑
给定样本数据集T={(x(i),y(i)),i=1,2,…,l}∈X×Y其中x(i)∈X⊂Rn为输入向量,y(i)∈Y={-1,1}。支持向量机在对数据集T按y(i)的取值分类时需确定分类超平面g(x)=sign(wTΦ(x)+γ),它可通过求解下面的约束最优化问题确定
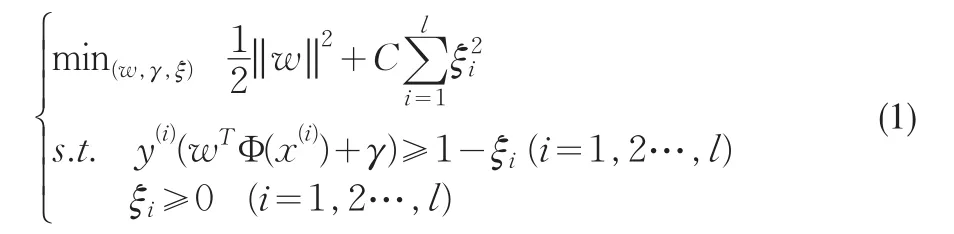

由(2)对任意的输入x∈X可确定相应的y=g(x)的值,并由此值作出预测。
问题(1)对所有数据点的误差ξi都赋予了相同的权重C。对于具有时间特征的金融时间序列,对不同时间点的误差ξi都赋予相同的权重未必是一个合适的选择。考虑到近期的数据所提供的信息对模型的影响一般要大于早期数据所提供的信息,采用递增的权重可能会更合适,由此可得用于金融时间序列预测的不等权重的支持向量机模型
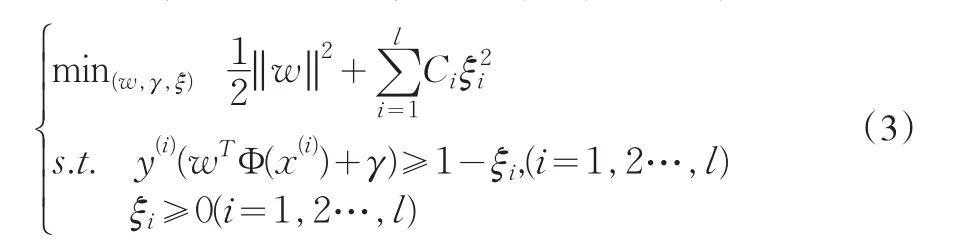
其中,Ci>0,为一单调增的权重序列。Tay和Cao在文[3]中给出了Ci的一个取法

其中a>0是控制权重递增速率的参数。
再考虑问题(3)的求解,由问题(3)的约束条件,可以得出可行的ξi可以表示为
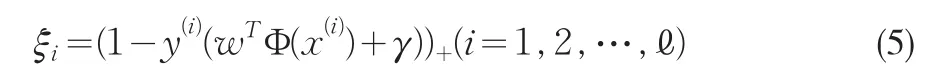
其中(α)+=max{α,0}。将(5)代入(3)的目标函数中,可将约束优化问题(3)转化成等价的无约束优化问题

这是一个凸二次优化问题,但由于w*唯一,而γ*不唯一,可对问题作进一步的修改
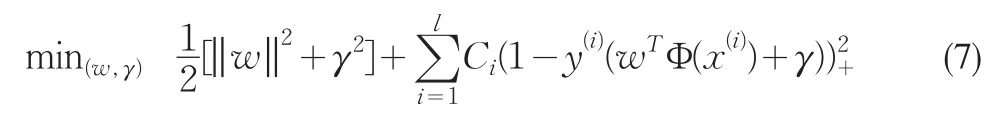
这是一个严格凸二次最优化问题,最优解(w*,γ*)唯一。但由于目标函数中(α)+=max{α,0}不可微,这是一个不可微最优化问题。我们用文[1]给出的连续可微的分段多项式来近似函数 (α)+=max{α,0}

得连续可微的无约束最优化问题

函数(8)在区间 (-1/k,1/k)外同函数 (α)+=max{α,0}取值相同,而在区间 (-1/k,1/k)内对 (α)+=max{α,0}的近似精度为

对无约束最优化问题(9)可利用BFGS这一有效的无约束优化算法求解。
1.2 遗传不等权重支持向量机算法(GACSVM)
在利用SVM确定最优分类超平面时,一个显著的特征是只有少数被称为支持向量的样本数据起决定性的作用。相对于给定的训练样本,大量的非支持向量样本数据对分类超平面的确定几乎不起作用。考虑到这一特征,我们在对给定数据集应用不等权重支持向量机确定分类超平面时,将随机选用数据集中的部分数据(子集)来确定分类超平面,并用遗传算法在这些分类超平面中搜索最优的分类超平面,称由此形成的算法为遗传不等权重支持向量机算法(GAUSVM)。这一则可以减少训练样本点的数量,降低问题(9)的复杂度,提高算法对其求解的效率,另一方面通过遗传算法对预测模型作全局优化搜索,可以确定尽可能好的预测模型。为方便对GAUSVM的叙述,首先给训练样本数据集T中的ℓ个样本数据{(x(i),y(i)),i=1,…l}按某种次序编号,遗传算法中的一个个体对应T的一个子集。设初始种群中每个个体所对应的子集包含样本数据的数量为M,每代种群的规模为N,种群最大进化次数为K,则算法GAUSVM的主要步骤如下:
步骤1随机生成N个个体形成初始种群
每个个体由随机生成的二元值向量η=(η1,…ηl)确定,其中每一分量ηi的取值或为0或为1,且所有分量之和等于M。如果ηi=1,表示对应的样本点(x(i),y(i))入选该个体对应的子集,如果ηi=0,表示对应的样本点没有入选该个体对应的子集。每个向量η对应数据集T的一个包含M个数据点的子集。对每个个体应用上节的不等权重支持向量机得到一个预测模型,应用这个预测模型于检测数据集得到这个预测模型的预测正确率,记为这个个体的适应度。
步骤2 交叉运算(均匀交叉)
从种群中随机选取两组(每组两个)个体,在每组再选择适应度高的个体作为父代进行交叉运算产生子代。交叉过程采用均匀交叉:若两父代的η在某位都为1,则子代节点在该位也为1;若两父代在某位都为0,则子代节点在该位也为0;若两父代在某位一个为0,一个为1,那么子代在该位为0或者为1的概率均为50%。
步骤3变异(固定的变异概率q,取p为小于或等于qℓ的最大整数)
步骤4进化
对子代应用不等权重支持向量机确定一个预测模型,并计算其适应度。将其加入种群,并将种群中适应度最差的一个个体删去。
步骤5 停机检验
若新产生的子代个体的适应度函数达到精度要求,或者产生子代的进化次数超过允许的最大进化次数K时,停机,选取当时种群中适应度最高的个体作为需要的最优解,产生预测模型。否则转步骤2进入新一轮的遗传①经过交叉变异进化后的每个子代个体,其所对应的子集包含的数据数量有可能不再等于预先指定的数量M。。
2 汇率预测模型构建
下面我们将应用前述的遗传不等权重支持向量机方法就美元/人民币(U/C)、欧元/人民币(E/C)、日元/人民币(J/C)汇率变动的预测作实证检验分析。一般情况下,汇率变动受两国的经济乃至世界经济发展状况的影响,考虑到数据的获取可能,我们分别选择道氏中国600指数(DJCBN600)、道氏中国88指数(DJC-88)、道氏中国海外50指数(DJCOS50)、道氏中国市场指数(DJCMT)、道氏上海指数(DJSH)、道氏深圳指数(DJSZ)、道氏美国指数(DJUS)、标准普尔500指数(SP500)、纳斯达克综合指数(NASDAQ)、法国CAC40指数(CAC)、德国DAX指数(DAX)以及日经225指数(NIKKEI)作为中国、美国、欧元区及日本经济发展状况的指标,并选取2008-12-10至2009-7-13期间这些指数连同上述3种汇率的日收盘价作为对遗传不等权重支持向量机方法进行实证分析与检测的数据。由于这些数据分属不同国家,对这些数据作预处理后,共有125组有效数据。
对于汇率变动方向预测,下面以美元/人民币汇率为例建立预测模型,对于欧元/人民币及日元/人民币汇率可用同样的方法建立预测模型。首先记美元/人民币第i日的汇率为,道琼斯中国指数第i日的指数为对其余各指数都用类似的符号表示。对汇率及各指数数据按
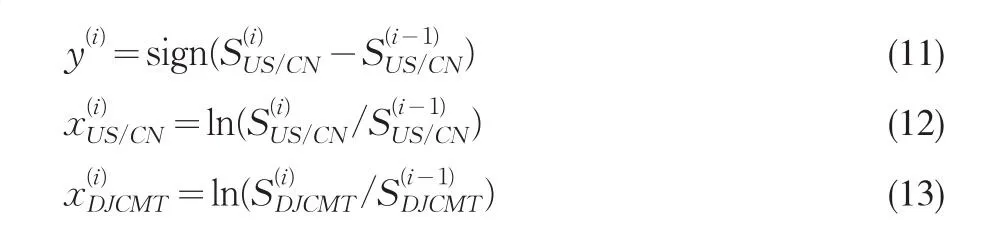
计算汇率第i日的变动方向与对数收益,及各指数第i日的对数收益。由此形成用上述遗传不等权重支持向量机方法对美元/人民币汇率变动作预测进行实证分析检测的样本集T={(x(i),y(i)),i=1,2,…,ℓ},其中 ℓ=124。

这里p为待定的滞后阶数,它将在下节实证分析时根据预测效果确定p的取值。
在实证分析时,样本集124组数据中的前100组将用作训练集,用于用遗传不等权重支持向量机等方法确定预测模型

后面余下的24组数据用作检测集,用于检测所确定模型的预测精度。考虑到人工神经网络模型在汇率预测中已被成功应用,本文选择采用BP算法的单隐层前向人工神经网络模型(ANN),一般的支持向量机方法(SVM),不等权重支持向量机方法(USVM)与遗传不等权重支持向量机算法(GAUSVM)就三种汇率变动的预测效果作比较。
3 实证结果分析
首先选择确定各模型中的参数值。对于遗传算法中的参数,种群的规模取为N=50,每个子集(个体)包含数据点的数量为M=15,固定变异概率q=10%,允许最大进化次数K=250;分段光滑多项式(2-8)中的k=10,单隐层前向人工神经网络模型(ANN)隐层内的结点数取为d=6。支持向量机模型中的映射Φ取为恒等映射,即Φ(x)=x,模型中的参数C,变权重系数公式(4)中的调节参数a,及式(14)中的滞后阶数p,则须经实证分析比较后选定。表1分别给出了对美元/人民币、欧元/人民币、日元/人民币日汇率变动进行实证比较分析后选定的这几个参数的值。
表2给出了各支持向量机方法及神经网络模型在检测集(样本外)数据及训练集(样本内)数据上对各人民币汇率未来一天变动方向的预测正确率。
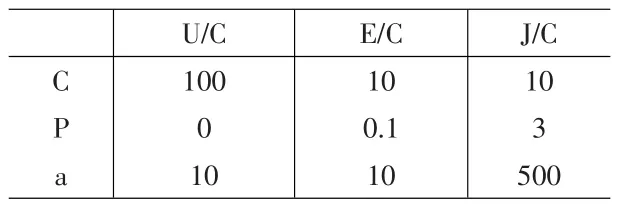
表1 预测汇率变动的各SVM模型的最优参数值
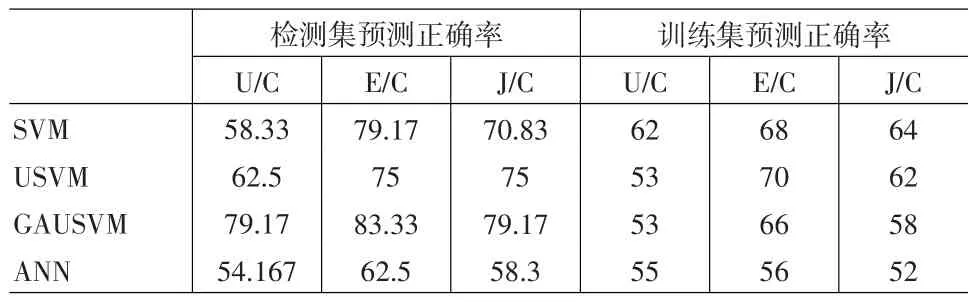
表2 各SVM模型及ANN模型对汇率变动的预测结果
表2可以得出下述结论:(1)各支持向量机方法在检测集和训练集上的预测效果均要好于ANN模型的预测效果,证实了同时实现最小化经验误差与最大化分离间隔的支持向量机方法在汇率变动预测方面的优越性;(2)USVM方法在检测集上的预测效果要优于SVM方法(仅在E/C上较SVM稍差),一定程度上证实了近期数据对未来变化的影响较早期数据大的假设;(3)GAUSVM方法在检测集上的预测效果明显优于其它两个SVM方法,这表明通过把遗传算法与USVM进行组合能够有效地提高USVM的预测效果,加强其数据挖掘功能。
表3给出了三个支持向量机方法确定的预测模型相应的支持向量个数(支持向量与非支持向量之和为训练集样本点数)。
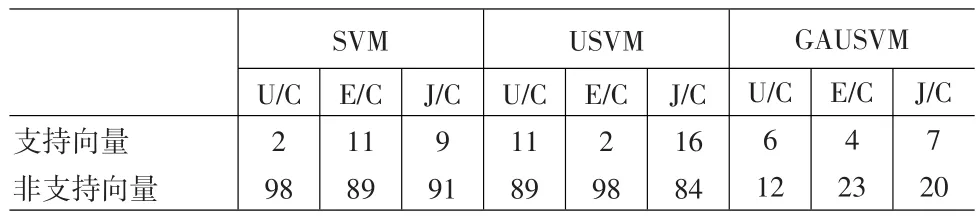
表3 汇率预测的各SVM模型的支持向量个数
从表3可以看出,SVM与USVM模型对三种汇率所确定的预测模型支持向量的分布很不均匀,而GAUSVM方法由于利用遗传算法对预测模型进行了全局优选,因而由其得出的对三种汇率预测模型支持向量的分布比较均匀和集中。这一点在表2的对检测集预测正确率的结果中有所体现。这些结果表明将遗传算法与支持向量机方法结合对预测模型选优可以有效地提高模型的预测效果。
4 结论
本文在对一般支持向量机方法进行不等权重和多项式光滑改进的基础上,将不等权重支持向量机与遗传算法结合,给出了对预测模型进行选优的遗传不等权重支持向量机(GAUSVM)方法,并将该方法应用于三种人民币汇率变动预测的实证分析和比较。将遗传不等权重支持向量机方法与一般支持向量机方法(SVM)、不等权重支持向量机方法(USVM)及遗传算法(ANN)对三种汇率变动的预测效果比较表明,有下述主要结论:(1)支持向量机方法在检测集和训练集上的预测效果均要好于ANN模型的预测效果。(2)由于GAUSVM方法利用遗传算法对预测模型进行了全局优选,因而由其得出的对三种汇率预测模型的支持向量的分布比较均匀和集中。(3)USVM方法在检测集上的预测效果要优于SVM方法(仅在E/C上较SVM稍差),一定程度上证实了近期数据对未来变化的影响较早期数据大的假设。(4)GAUSVM方法在检测集上的预测效果明显优于其它两个SVM方法,这表明通过利用遗传算法对预测模型选优能够有效地提高USVM的预测效果,加强其数据挖掘的功能。
[1] Vapnik V N.Statistical Learning Theory[M].New York:Wiley,1998.
[2] Vapnik V N,An Overview of Statistical Learning Theory[J].IEEE Transactions of Neural Networks,1990,(10).
[3] Cao L J,Support Vector Machines Experts for Time Series Forecasting[J].Neurocomputing,2003,(51).
[4] Huang W,Nakamori Y,Wang S Y.Forecasting Stock Market Movement Direction with Support Vector Machine[J].Computers and Operations Research,2005,(32).
[5] Schebesch K B,Stecking R.Support Vector Machines for Classifying and Describing Credit Applicants:Detecting Typical and Critical Regions[J].Journal of the Operational Research Society,2005,(56).
[6] 袁玉波,严杰,徐成贤.多项式光滑的支撑向量机[J].计算机学报,2005,(1).
[7] Tay F E H,Cao L J.Descending Support Vector Machines for Financial Time Series Forecasting[J].Neural Prosessing Letter,2002,(15).
[8] 邓乃杨,田英杰,数据挖掘中的新方法--支持向量机[M].北京:科学出版社,2004.
猜你喜欢
当代陕西(2020年17期)2020-10-28
中国外汇(2019年17期)2019-11-16
中国外汇(2019年13期)2019-10-10
中国外汇(2019年11期)2019-08-27
中国外汇(2019年21期)2019-05-21
人大建设(2018年5期)2018-08-16
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
