
藏语句子相似度算法的研究
2011-06-28 06:37:06安见才让
中文信息学报 2011年4期
安见才让
(青海民族大学 计算机学院,青海 西宁 810007)
0 引言
在自然语言处理领域,尤其在中文信息处理中,句子相似度的计算是一项基础而核心的研究课题。长期以来一直是人们研究的一个热点和难点,在自然语言处理的各个领域都有着非常重要的作用。如在基于实例的机器翻译、基于语料库的汉语教学系统、文档自动文摘系统[1]、基于常见问题集(FAQ)的机器问答系统[2]、语言的对比和信息检索、信息过滤等研究中,句子相似度的计算都是其中关键的技术之一。
随着语料库语言学的兴起,基于双语语料库的汉语教学得到越来越多学者的研究。基于汉藏语料库的汉语教学系统以汉藏双语对照的实例库为主要的知识源,其基本原理是: 当输入一个待查询的藏语句子时,系统便从双语实例库中搜索得到最相似的句子,再以该句子为查询对象,找出与之相对应的汉语句子。在基于汉藏语料库的汉语教学系统和基于实例机器翻译(EBMT)中,句子相似度的衡量是一个非常关键的步骤[3],其直接影响检索的质量,最终影响检索和翻译的正确性。
如何快速从双语实例库中找出与输入句子最相似的句子,是基于汉藏语料库的汉语教学系统需解决的关键问题之一。
1 相关研究工作
按照对语句分析的深度,相似度计算方法主要有两种: 基于向量空间模型的方法和基于语义的方法。基于向量空间模型的方法把句子看成词的线性序列,计算句子相似度只利用组成句子的词的词频、词性等信息[4]。由于不加任何结构分析,该方法在计算句子之间的相似度时不能考虑句子整体结构的相似性[5]。基于语义的方法,对句子进行完全的句法与语义分析,对作比较的两个句子进行深层的句法分析,找出语义依存关系,并在依存分析结果的基础上进行相似度的计算[6],这是一种深层结构分析法。
在文献[7]中, 提出了一种英语句子相似度的计算方法,作者通过定义一个距离函数,计算从一个句子的词序列变换到另一个句子的词序列所进行插入、删除和替换单个单词项的编辑次数,以体现两个句子间距离的大小,用两个句子的最小距离作为衡量两个句子的距离,该方法适用于英语及与英语同属于一个语系的语言。
基于实例的机器翻译系统中计算句子相似度,有人提出将句子划分成几个片段,用片段的长度和匹配值计算相似度。但是,利用的句子片段越小,片段的边界越难以确定,歧义情况就越多,从而导致翻译质量的下降。为此,要建立一套相似度准则[8-9]。郭锐等人利用句子长度、汉字字形、标点符号三因素和遗传算法、动态规划算法,通过实现古今汉语自动句对齐,定义句子的相似关系[10]。也有人通过比较两个句子的词类信息串,进行最优匹配,得到一个结构相似性的值[11]。文献[12]中,作者提出了一种基于骨架依存分析的方法,该方法首先识别汉语句子的谓语中心词,其次判断两个句子的谓语中心词是否相似和它们的支配成分之间是否一一对应,如果是,则把谓语中心词之间和支配成分之间的相似度之和作为两个句子的相似度值。这种方法需要消耗大量的时间和人力。
本文提出的句子相似模型的算法在充分考虑句子的关键词、同义词和近义词等因素的基础上,用藏语句子关键词的词形相似度、句长相似度和连续单词序列的相似度衡量两个藏语句子的相似程度。采用的基于散列单词倒排索引的方法能够有效提高算法的查找速度。
2 句子相似模型
2.1 关键词抽取
由藏语语言学知识可知,任何句子都是由关键成分(主、谓、宾)、修饰成分(定、状、补)和语法成分(格助词、虚词)构成[13]。词语的表达能力不仅与词性相关,而且与句子结构、句子长度、词语的语法作用等因素也有关。例如谓语和修饰语对于句意表达的重要程度就是不同的。理想情况下,应该分析出词语的语法作用,据此计算出词语的权重。但是在现阶段,对句子的完全句法分析、词语语法角色的完全识别是不可能的。另一方面词语的词性与词语在句子中的语法角色是有一定对应关系的: 名词和代词一般作主语和宾语,动词一般作谓语,形容词、数词和量词一般作定语。主语、谓语和宾语对句子起主导作用,定语、状语等成分对句子起辅助作用。因此,可以将一个句子中的所有名词、代词、动词和形容词作为关键词(下文所述关键词也是此含义)看待。
2.2 有关定义和计算
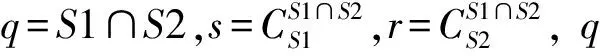
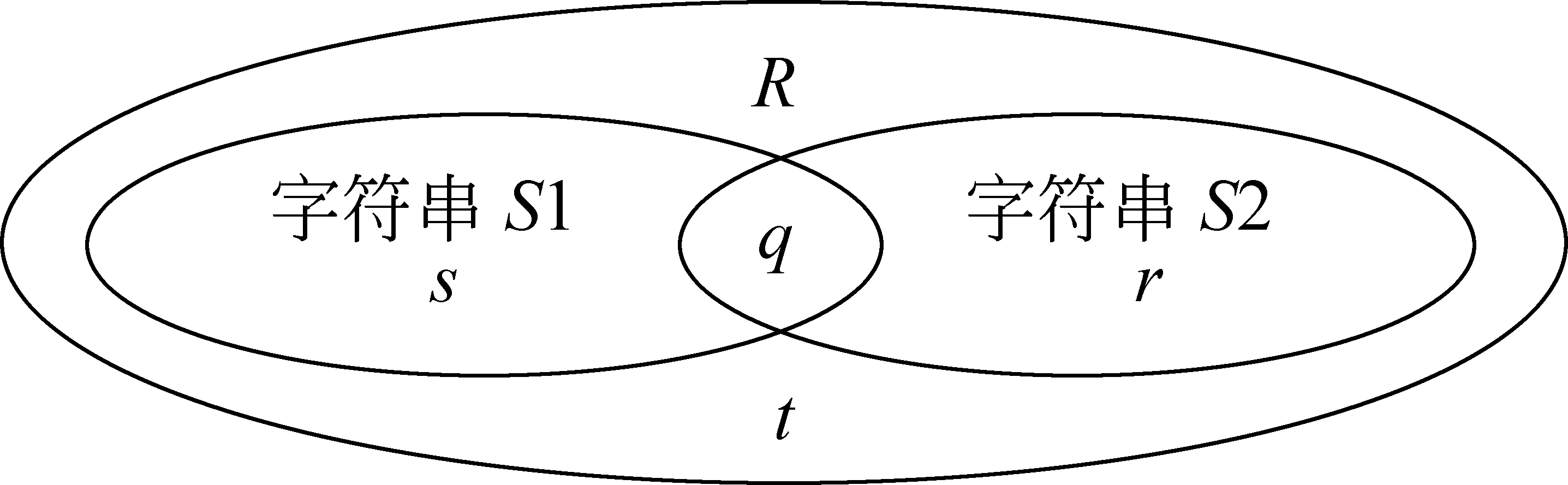
图1 字符串关系
两个字符串间的相异度=(|r|+|s|)/(|q|+|r|+|s|),相似度=|q|/(|q|+|r|+|s|)。
由此,可以得到句子的词形相似度。句子的相似度除了与关键词有关外,还与句子长度、句子中连续单词序列的距离有关,下面给出具体的定义。
定义1: 词形相似度WordSim(S1,S2)
从句子形态及词形上来标注句子的相似性,词形相似度计算如下:
WordSim(s1,s2)
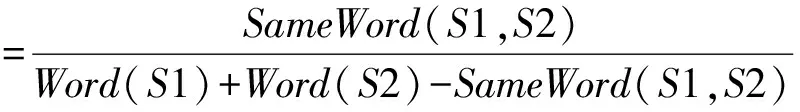
(1)
其中,SameWord(S1,S2)表示S1与S2中相同关键词个数,Word(Si)表示Si中的关键词个数,i=1,2。
由于名词和动词(除助动词)在句子中起着非常重要的作用,而且动词比名词承载着更多的信息量。所以在计算Word(Si)和SameWord(S1,S2)的时候也特意加大了相同关键词中动词和名词的重要程度。这一特性用词性权重W表示,这样,在此处计算相同关键词的个数时,若两个关键词相同并且都是动词或名词时,SameWord(S1,S2)和Word(Si)的一个动词权重计为W1,一个名词权重计为W2,其他词性权重均计为W3,即计算关键词个数时增加相应词的词性权重。
在语料库中两个相似句子长度(句子包含的单词个数)的比较实验中发现: 如果两句子的长度差变大时,相似度会降低。两个句子的长度越是接近,则两个句子越相似。所以,两个相似句子在长度上有一定的相似性。
定义2: 句长相似度LenSim(S1,S2)
(2)
其中Len(Si)表示Si中词(包括格助词和虚词)的个数,i=1,2。
定义3: 句子连续单词序列相似度
两个句子,同时出现的连续单词序列越长,其越相似。因为连续单词序列包含的上下文信息比较多,其语法、语义也比较确定,相对单词来讲,连续单词序列对自然语言的区分能力更强。
设两个句子S1、S2被连续单词分成k个连续块, 则句子S1、S2的连续单词序列相似度:
其中,M=max (Len(S1),Len(S2)),Ni为第i连续块中总单词数,wi,j为第i连续单词块中第j个单词的词性权值,wm为最长句子中第m个词的词性权值。
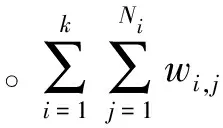
定义4: 在句子S1和S2中计算相同词和连续单词序列单词个数的方法:
给定两个句子S1、S2,构造连续单词序列矩阵simmatrix(m,n)。
其中,m,n分别是句子S1和S2的句长,boolij的取值:
在比较句子S1的第i个单词与句子S2的第j个单词时,如果第i个单词与第j个单词不相同,则在同义词和近义词知识库中寻找第j个单词的同义词或近义词是否与第i个单词相同。

从矩阵可以发现: 连续单词序列有1个,相邻词的个数为5,其中,动词有1个(值为5的元素),名词有2个(值为3的元素),所以,
在计算连续单词序列中的单词个数时,如果当前的两个句子中没有连续单词序列,但句子中两个相邻的词是名词或形容词且两词之间含有藏语语法成分时,可以考虑将两个词的前后顺序交换后,看是否有连续的单词序列。
3 算法描述
句子相似算法分为粗选算法和精选算法。粗选算法是从海量双语实例库中找出与输入句子比较相似的候选句子集合,做为精选算法的基础。
3.1 基于倒排索引和长度的多策略粗选算法
粗选算法的目标是从海量双语实例库中筛选出一定数量的句子作为候选集合,集合中包含了与输入句子基本相似的句子。
快速检索是粗选算法的关键技术之一。为了提高检索速度,粗选算法应该计算简单,不能过多考虑上下文。在此,提出一种简单的计算方法: 如果两个句子的长度相似度大于阈值k,则两个句子趋于相似。
为了进一步提高检索速度,对语料库中的句子建立散列单词倒排索引。首先建立语料库中句子的各词散列表,然后将每个单词所出现的多个句子编号SID构建一个单链表,其中SID是句子编号,如图2所示。

图2 散列单词倒排索引
粗选算法的具体过程是:
(1) 对输入的藏文句子进行分词和词性标注,获得单词链表;
(2) 从散列单词倒排索引中获得单词链表中各单词的句子编号链表,并获得相应的候选句子集合p1;
(3) 用句长相似度对集合p1的候选句子进行计算,选择句长相似的P个句子作为新的候选句子集合p2;
(4) 对集合p2按句长的相似度作降序处理。
最后对获得相似度取值最大的P个句子作为粗选集合。
3.2 基于词形相似度和连续单词序列相似度的多策略精选算法
经过粗选之后,获得粗选集合的句子数量已经缩小到P个(如200)。因此可以对这些数量较少的句子进行更复杂的计算,来精确地找出与输入句子最为相似的句子。提出一种基于词形相似度和连续单词序列相似度的方法。
记两个作比较的句子为S1和S2,S1与S2的相似度记为Sim(S1,S2),则:
其中:λ1+λ2=1,且λ1>λ2>0,λ1和λ2是经验值。
该算法中的关键词抽取部分涉及分词与词性标注(其他算法大部分仅涉及分词),在计算相似度时还需要借助藏语同义词和近义词知识词库,对同义词或近义词进行替换,以提高相似度。
4 实验结果与分析
4.1 实验设计和结果
因为没有可用于藏文句子相似度测试的标准测试语料,我们选用九年义务教育六年制和三年制小学及初级中学18本《汉语》教科书(藏族地区使用)的翻译内容作为实验语料。语料含有8 006个语句,从中手工获取166个藏语句子构成标准集, 把标准集中的句子依据相似程度分为8类,每类有19~21个句子,这样就保证了在标准集中每个句子都有17~21个相似句子,其余的7 840个语句作为噪音句子构成噪音集。另外,我们建设了一个藏语同义词和近义词知识库,其中含有652个词条,用于计算藏文句子相似度时,可以对同义词或近义词进行替换。
衡量指标选用了准确率P、查全率R和平均调和值F三个指标:
实验结果如表1。方法1代表词形相似度算法,方法2代表本文提出的相似度算法公式(4),其中选取参数λ1=0.81、λ2=0.19。
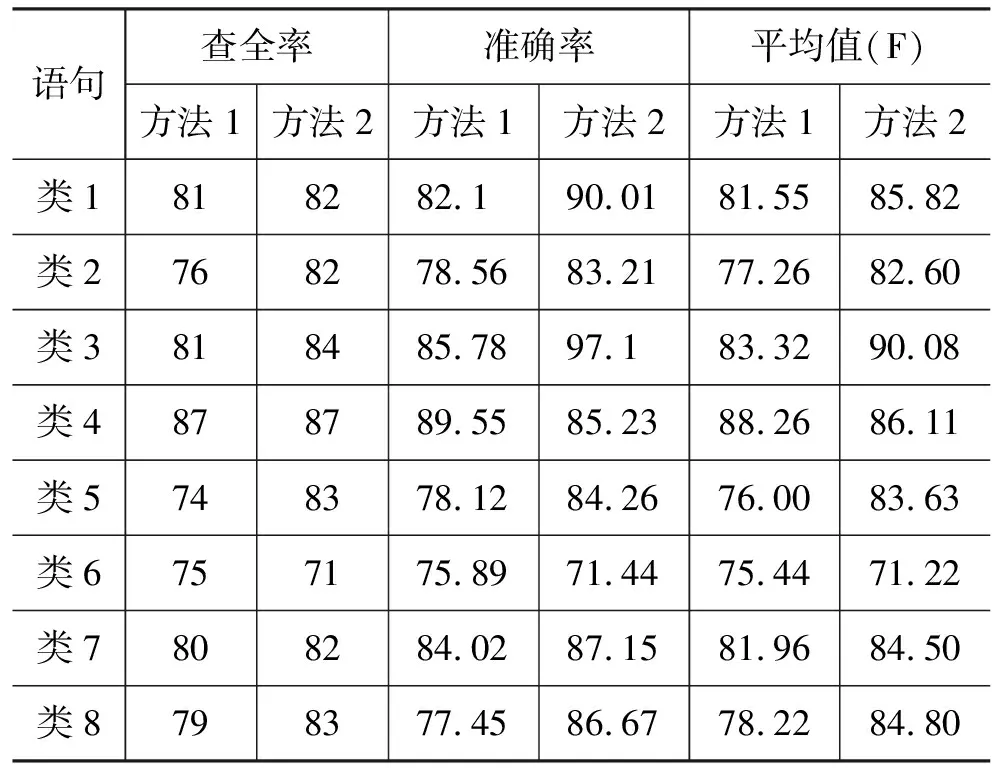
表1 实验结果
4.2 实验结果分析
1) 从计算的结果可以看出,采用方法2所得查全率比方法2的查全率高,虽然区别不大,但准确率明显提高。由于方法2中采用了连续单词序列相似度因素,使方法2对自然语言的区分能力增强。
2) 方法1和方法2的时间复杂度: 设句子S1、S2的句长分别为m、n,语料库中的句子总数为s,同义词和近义词词库中词条总数为w,散列倒排索引中的一个单链表的长为k,则方法1和方法2的时间耗费如公式(8)和(9):
T(s)=s×m×n
(8)
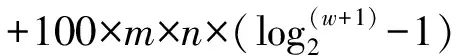
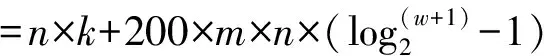
(9)
其中,100为方法2中经粗选算法计算后所得集合元素之总和。
公式(8)中的m、n和公式(9)中的m、n、w分别对T(s)和T(s)的影响比较小,作用相对稳定。T(s)是语料库中句子总数s的函数,T(k)是单链表长度k的函数,k<
通过对方法1和方法2算法的时间耗费分析可得,方法2在计算速度上应该有所提高,但受到实验样本数的限制,实验过程中没有得到体现。
在实验过程中也发现一些有待解决的问题: 同义词、近义词的词库不够充足,没有考虑藏语动词形态还原等一系列问题。
5 结论和下一步工作
采用基于句长相似度的算法和基于散列单词倒排索引的粗选方法,快速从语料库中筛选出了候选句子集合,多策略精选算法采用基于词形相似度的算法和基于连续单词序列相似度的算法衡量两个藏语句子的相似程度,能够有效地从候选句子集合中找出与输入句子最相似的句子。
下一步工作是继续扩大语料库的规模,并引入藏语动词形态学、句法结构知识和语义知识,将其融入到本算法中。
[1] 张奇,黄萱菁,吴立德.一种新的句子相似度度量及其在文本自动摘要中的应用[J].中文信息学报,2005,19(2):93-99.
[2] 张亮,冯冲,陈肇雄.基于语句相似度计算的FAQ自动回复系统设计与实现[J].小型微型计算机系统,2006,27(4):720-723.
[3] 王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2005,19(1):21-29.
[4] 周法国,杨炳儒.句子相似度计算新方法及在问答系统中的应用[J].计算机工程与应用,2008,44(1): 165-178.
[5] 吕学强,任飞亮,黄志丹,等.句子相似模型和最相似句子查找算法[J].东北大学学报(自然科学版),2003,24(6): 531-534.
[6] 蔡东风,白宇,于水,等.一种基于语境的词语相似度计算方法 [J].中文信息学报,2010,24(3): 24-28.
[7] Federica Mandreoli, Riccardo Martoglia, and Paolo Tiberio. Searching Similar(Sub) Sentences for Example-Based Machine Translation[C]//Atti del Decimo ConvegnoNazionale su Sistemi Evoluti per Basi di Dati(SEBD 2002),Isolad Elba,Italy,2002.
[8] 侯宏旭,刘群,那顺乌日图.基于实例的汉蒙机器翻译[J].中文信息学报,2007,21(4): 65-72.
[9] 冯志伟.基于语料库的机器翻译系统[J]. 术语标准化与信息技术,2010,1:28-35.
[10] 郭锐,宋继华,廖敏.基于自动句对齐的相似古文句子检索[J].中文信息学报,2008,22(2): 87-91.
[11] 王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2005,19(1): 21-29.
[12] 穗志方,俞士汶.基于骨架依存树的语句相似度计算模型[C]//中文信息处理国际会议论文集(ICCIP 98).北京:清华大学出版社,1998,458-465.
[13] 格桑居冕.实用藏文文法[M].四川民族出版社,1987.
猜你喜欢
疯狂英语·初中天地(2021年10期)2021-12-21 06:15:44
小学生学习指导(低年级)(2021年5期)2021-07-21 02:00:54
韩国语教学与研究(2020年4期)2020-05-17 00:48:38
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
小天使·一年级语数英综合(2019年6期)2019-06-27 06:36:15
山东青年(2018年7期)2018-11-06 06:13:12
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
小星星·阅读100分(低年级)(2015年11期)2015-11-12 08:25:54
语言与翻译(2015年4期)2015-07-18 11:07:45
作文评点报·低幼版(2014年46期)2014-11-25 23:44:06
