
汉藏短语抽取
2011-06-28 01:55诺明花张立强刘汇丹丁治明
中文信息学报 2011年2期
诺明花,张立强,刘汇丹,吴 健,丁治明
(1. 中国科学院 软件研究所,北京 100190;2. 中国科学院 研究生院,北京 100049)
1 引言
本文核心问题是针对特定领域汉藏多策略机器辅助翻译系统(简称MSCT_CAT)构建短语对齐词典。MSCT_CAT是基于实例的辅助翻译系统。首先把输入的汉语句子正确地分解为一些短语碎片,接着把这些短语碎片翻译成藏文的短语碎片,最后再把这些短语碎片组织成完整的句子,每个短语碎片的翻译是通过类比的原则来识别和比较已有实例与待译短语的相似之处和相差之处,从而挑选出正确的译文。
基于短语的统计机器翻译的优势在于短语能够抓住局部上下文的依赖关系。迄今为止,已经出现了多种短语对抽取方法。Marcu[1]给出了一种直接计算短语对列表和相应概率值的方法;Wu[2]用一个双语框架(Bracketing)的方法来抽取短语。这两种方法的计算复杂性太高。Zhang[3]为双语句子对建立一个互信息矩阵,从这个矩阵中抽取互信息相似的矩形区域即得到短语对,此方法并不要求词对齐,而是充分利用词对的互信息。后来Zhang[4]将短语抽取看作一个句子分割问题,在固定源短语时,寻找目标短语的最优左边界和右边界。这种方法的问题在于只能抽取连续的短语。Kaji[5]对源句子和目标句子分别进行句法分析,然后按照词对齐结果来提取源子树和目标子树就得到短语对,该方法依赖于句法分析的结果。Och[6]提出了对齐模板方法,将单词映射到词类中。该方法由于算法简单,容易实现,故而应用较广,但是利用的信息较少。有的学者也提出了一些非连续短语的抽取方法,Chiang[7]的层次短语,允许短语内部包含子短语,但是由于没有加入句法信息导致抽取的规则会带来太多的噪音信息,对时间和空间的要求较高。何彦青[8]给出了一种基于“松弛尺度”的短语抽取方法,对Och的方法进行了修改。
考虑到目前藏文在词性标注、句法层面加工处理技术不成熟,藏文短语获取方法必须摆脱对词对齐、句法分析等资源的依赖。
2 Wang提出的译文获取模型
Wang[9]提出了一种基于序列相交的短语译文获取方法。该方法将句子视为词的序列,在中日句对齐语料库中包含待译短语的所有汉语句子对应的日语句子进行序列相交,在不需要词对齐、句法分析及词典等资源的情况下,通过充分挖掘句对齐双语语料库,获得高质量的短语译文。
方法由基本模型、高频干扰词限制模块、支持度限制模块组成。基本模型从句子级对齐双语语料库中提取高质量的短语翻译对候选并对其进行排序;高频词限制模块解决译文的输出结果中的高频词干扰问题;支持度限制模块控制输出结果的个数。其中支持度限制模块是因为基本模型没有使用词典、词对齐等资源,无法判断求出的交集结果是否符合译文要求。故当求交结果的支持度很低时,往往得到的不是正确译文;当候选译文之间的支持度比较相近时,只输出一个译文,很可能漏掉正确的译文结果。因此为了提高译文结果的质量,需要一个判定模块,在基本模型中增加对候选译文的支持度的限制。

3 翻译基本模型
本文从句对齐汉藏语料中先获取所有有效汉语语块,对包含待译汉语语块的句对求交集,经过后处理得到相应的藏语译文即得到汉藏互译短语。本文获取的短语是广义上的,它是由若干个单词组成的语块。MSCT_CAT的短语对齐词典中每条记录包含汉语有效短语以及对应的藏文译文。
3.1 基本模型
藏文词序列相交算法(简称TIA)使用的语料库为汉藏句对齐双语语料库SABC,其中包含若干个汉藏对齐的句对。汉语句子是没有像英文那样自然形成的分词标记。作为一种拼音文字,藏文中各音节之间由音节点分隔,但是词与词之间没有分隔标记[10],很难区分词的边界。为了词序列相交,本文分别使用斯坦福的中文分词开源项目和中国科学院软件研究所多语言信息处理研究室开发的藏文分词模块对汉藏单语语料进行分词,为TIA做准备。TIA的核心是通过汉藏词序列相交模型,获取1-n的汉藏互译短语对。
基本模型中,句子和短语均以词序列的形式表示。句子和短语的序列表示以及句子的序列相交定义沿用文献[9]的公式表示,表1给出汉藏双语句对词序列相交的示例。

表1 汉藏双语句对词序列相交示例表

续表
3.2 SIBPTM模型
本节介绍藏文词序列相交算法短语译文获取模型,简称SIBPTM模型。

从以上分析可以得出,两个句对SPr与SPt相交结果表示如下:
Q={Q1,Q2, …,Qk} 为句对SPr和SPt中汉语句子CSr和CSt的交集(汉语短语集合),其中包含Qi(1≤i≤k)待翻译的中文短语,T={T1,T2, …,Tg} 为SPr和SPt中藏文句子TSr和TSt的交集。T中肯定包含Qi的翻译译文,可以查找汉藏词典确定汉藏互译对(Qi,Tj)。
待翻译中文短语由多个汉语单词构成,表示为如下公式(2):
假设Qi中任意单词Qi+θ(1≤θ≤l)在词典中查到一个以上译文,这些译文保存到链结构L中,一定会存在某个Tj+ω能够满足Tj+ω∩L≠ Ф的条件。这些Tj+ω(1≤ω≤g)最终构成Qi的译文Tj。Tj可以是连续的,也可以是非连续的。
从公式(1)得知,句对的序列相交由若干个藏文公共子串CS组成。其中为每个CS构造一个树结构T的话,句对的序列相交可以组成一个森林。设定两种节点。其中有存储藏文CS的某个单词的节点,用ITN表示;还有某个藏文单词节点的同义词、时态变化或格变化的节点,用SYN表示,约定SYN在其关联的ITN的右子节点中记录;ITN的左子节点中记录同一个CS中相邻的藏文单词。因此,某个T的根节点是tag 域为1的ITN节点,T的叶子是左子节点为空的ITN节点。CS中某个单词对应节点的所有同义词、格变化或时态变化等形态变化形式构成一个列表SL。
假设,在SABC中有42个中文句子包含待翻译语块Q,其对应藏文句子取交后获取两个公共子串P1和P2。P1和P2的树结构分别用T1和T2表示,如图1。
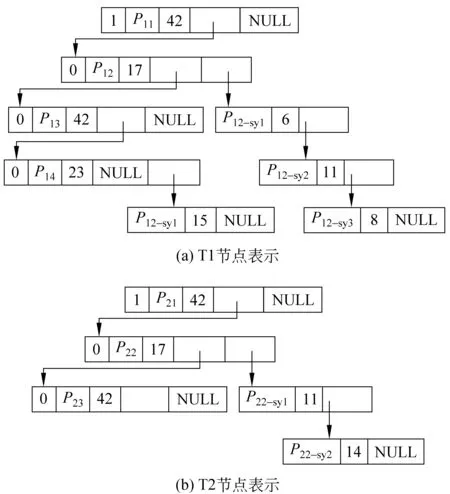
图1 译文确认过程
确认(Qi,Tj)的过程是对由T1和T2组成的森林的搜索过程。在图1中,P11出现频次等于42,被接受为译文Tj的一部分。P12节点最后一个域指向P12_sy1、P12_sy2和P12_sy3组成的链表,同时P12、P12_sy1、P12_sy2和P12_sy3出现频次的和等于42,因此词组[P12,P12_sy1,P12_sy2,P12_sy3] 被接受。P13出现频次为42,它被接受为Tj的一部分。P14和P14_sy1出现频次和为38,从而它们被丢弃。同样,P21和P23出现频次等于42,它们被接受为Tj的一部分。P22、P22_sy1、P22_sy2的频次和等于42,词组[P22,P22_sy1,P22_sy2] 被接受为Tj的一部分。Qi的最终翻译结果Tj是一个集合P={P11[P12,P12_sy1,P12_sy2,P12_sy3]P13,P21[P22,P22_sy1,P22_sy2]P23}。
4 汉藏短语抽取
为了不依赖于额外资源,本文提出两步抽取汉藏短语方法。汉藏短语对抽取流程如图2所示。汉语和藏文语块抽取先后分两步来进行。在面向中文信息处理的研究工作中,吕学强和张乐[12]利用Nagao的N-gram 统计算法,在大规模汉语语料中进行抽取语块的实验,他们在论文中还提出一个删除同频子串的算法(SSR),提高了语块抽取的准确率。SSR可靠并复杂度不高。在大规模语料中很实用。从汉语语块抽取的实际需求出发,本文在Nagao的串频统计方法的基础上开展基于词语的中文语块抽取并删除同频词串。提取的中文语块是连续的。具体串频统计和删除同频词串不是本文的重点,不再赘述,可以参考文献[12-13]。
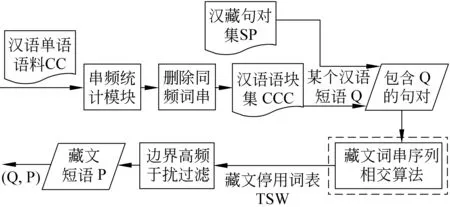
图2 汉藏短语对抽取流程
除了藏文语块抽取(虚线内部)外,汉藏短语对抽取需要做的工作有以下几点。虚线内部算法将在4.2节详细说明。首先,用脚本程序将SABC分为汉藏各自的单语语料,汉语语料和藏文语料分别标记为CC和TC。其次,用Nagao的算法计算出CC中所有2-gram 到5-gram 语块做为候选汉语连续语块。根据文献[12]中算法,通过子串归并删除同一频度的子串。最后对这些候选汉语语块进行过滤和排序后将汉语语块集CPS保存到文本文档中。另,构建TC中的藏文停用词表TSW为边界高频干扰过滤模块使用做准备。
4.1 藏文短语类型

4.2 TIA算法
藏文词串序列相交(简称TIA)算法不依赖于额外资源的前提下,对句对齐双语语料库中包含待翻译汉语语块Q的句对TSS求交集,通过后处理得到汉语语块的译文,从而构建汉藏短语词典。为了提高准确率TIA用到汉藏词典[11],并设定阈值来解决部分未登录现象。TIA重点解决1-n的短语对。
TIA算法的核心由两步组成。第一步使用第二节介绍的序列相交翻译模型,对藏文句子集中任意两句取交来为已知的Q构建公共子串森林F。在公式(2),Q由若干个词Qi(1≤i≤l) 组成。取交过程中任意Qi的译文均被保存并生成公共子串树T或森林F。并不是T或F中所有节点构成Q的译文P,节点满足以下两个条件才能组成P的候选。
1) 译文中一定包含任意Qi(1≤i≤l) 的译文;
2) 所有候选译文的支持度和等于Sn。
第二步遍历F,筛选出满足以上条件的候选单词并确认Q的译文P。P是CS的集合,P的生成过程描述如下。
输入:藏文句子集公共子串森林F
1. 初始化tn:= 0 ,用于记录森林中树的个数。
2. 初始化con:=true,用于记录一棵树中出现的候选是否连续。
3.Fornumfrom 1 to subTreeCount(F)
4. Foridfrom 1 to nodeCount(T)
5.nodeList:= RightChild(id) .
6. If (nodeList==null && Freq(id)==Sn)
7. then节点id添加到{Pi} 中。
8. Else if ( Freq(nodeList)==Sn)
9. then 节点id的左子节点组合添加到{Pi} 中。
10. Else
11. 抛弃当前节点id,con:=false。
12. End for
13. 公共子串树的个数tn自动加1。
14. End for
15. If (tn==1 )
16. then (Q,P) 标记为 A 。
17. If (tn> 1 )
18. then (Q,P) 标记为 B。
19. If (i==1 )
20. then P 被标记为 C。
21. If (i> 1 )
22. then P 被标记为D。
输出:连续性和对应关系被标记的汉藏互译对(Q,P)
伪代码中,函数subTreeCount(F)表示组成森林的树的个数;nodeCount(T)表示一个树中节点个数;RightChild(id)表示节点id的右子节点,null值表示没有右子节点;Freq(id)表示节点id出现频率,如果其参数是节点列表,计算出列表中所有节点出现频率之和;Sn表示包含待译语块Q的句对个数;con用于记录一棵树中出现的候选是否连续, 值等于false表示一棵树中出现的候选译文中只有部分满足频率条件而构成不连续译文P,值等于true表示一棵树中出现的候选译文是连续;{Pi}表示候选译文集合。用A,B,C,D分别将P标记为1-1,1-n,连续或非连续等不同短语类型。
公共子串树和森林结构可以充分体现藏文语料中时态变化和格变化等形态变化引起的一对多的互译短语;同时能够正确找出非连续的藏文短语。译文生成过程中标识了所有藏文短语类型。因此,TIA抽取的短语既能满足藏文短语的连续性,又能满足短语对应关系。
5 实验
实验数据是汉藏法律法规和公文报告等特定领域语料。收集到的原始语料通过篇章对齐和句子对齐后,再抽取单语语料,最终形成短语对抽取模块可以处理的五份汉藏单语语料。通过分析发现, 语料
1和语料4中低频短语对(在语料中出现次数很少)较频繁,语料5在五组语料中句对数最多。实验的准确率(P)定义为:
其中,N为算法从语料库中抽取出的所有藏文短语的个数,Nr为其中正确短语的个数。
5.1 TIA与Moses结果比较
Giza++是用于从句子对齐双语语料中训练词语对齐,但工作组在特定领域已收集的句子对齐汉藏语料规模还无法达到较大的规模,Giza++双向词对齐结果合并后很不理想。因此本文提出摆脱词对齐结果的短语抽取方案SIBPTM模型。
Moses是一个基于短语的统计机器翻译系统,从训练到解码完全开放源代码。Moses在解码之前可以生成双语短语表和重排序表,但其在本实验设计中使用的汉藏句对齐五份实验语料上性能和短语准确率没有TIA算法运行效果好。就性能而言,搭建Moses前需要安装Giza、Srilm等额外工具之外生成短语表之前需要生成目标语语言模型,这些工作较费时间;TIA只需要句子对齐汉藏语料作为输入,计算出来的即为汉藏短语。就准确率而言,请参见图3。图中横坐标表示语料序号,纵坐标表示准确率。
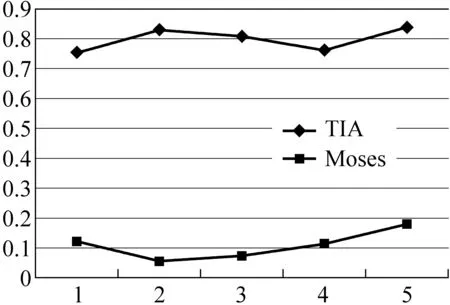
图3 TIA和Moses准确率比较图
图3结果表明,为实验准备的五份汉藏语料上TIA算法生成汉藏短语对准确率明显高于Moses生成的短语表准确率。Moses要用到基于统计的语言模型,工作组收集语料初步阶段的汉藏法律法规和公文领域对齐语料规模无法达到Moses及相关统计机器翻译开源工具对语料规模的要求。目前的语料规模下,MSCT_CAT抽取短语互译对再生成待译句子的译文过程中,Moses生成的短语表还不可取。
5.2 TIA抽取的藏文短语连续性验证
在实验中,对五组汉语语料用Nagao的N-gram 统计算法和删除同频子串的算法(SSR)后处理停用词,再人工筛选得到语法意义较明确的汉语语块。藏文语料先用TIA进行短语抽取,再采用计算机辅助人工的方法判断互译对正确与否,表2列出TIA抽取的连续短语和非连续短语统计结果。表2中D表示Discontinuous,C表示Continuous。
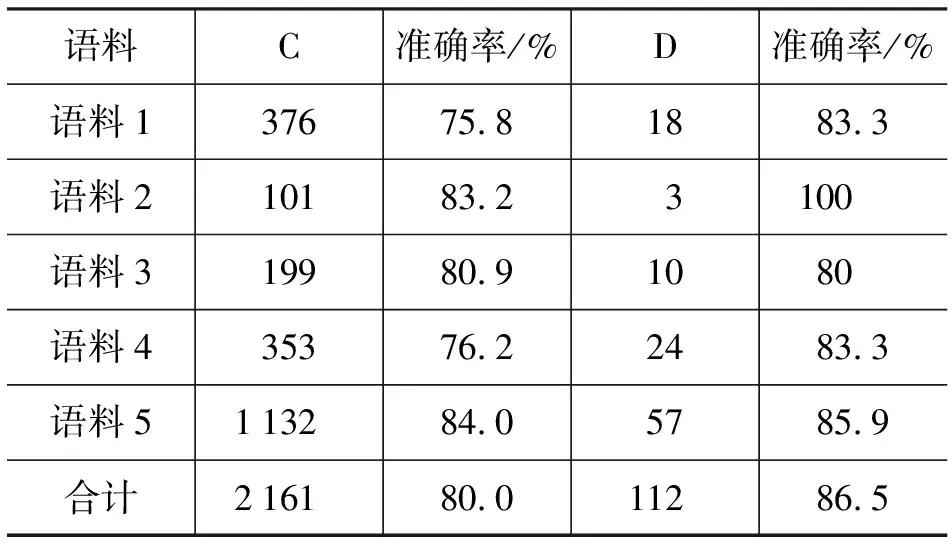
表2 TIA抽取结果的连续性统计表
5.3 TIA抽取的藏文短语对应关系验证
为了证明TIA算法抽取1-n短语对的有效性,对TIA抽取到的结果分析其汉藏对应关系。表3显示对应关系分布情况。该方法获得的短语译文准确率均值达到81%。
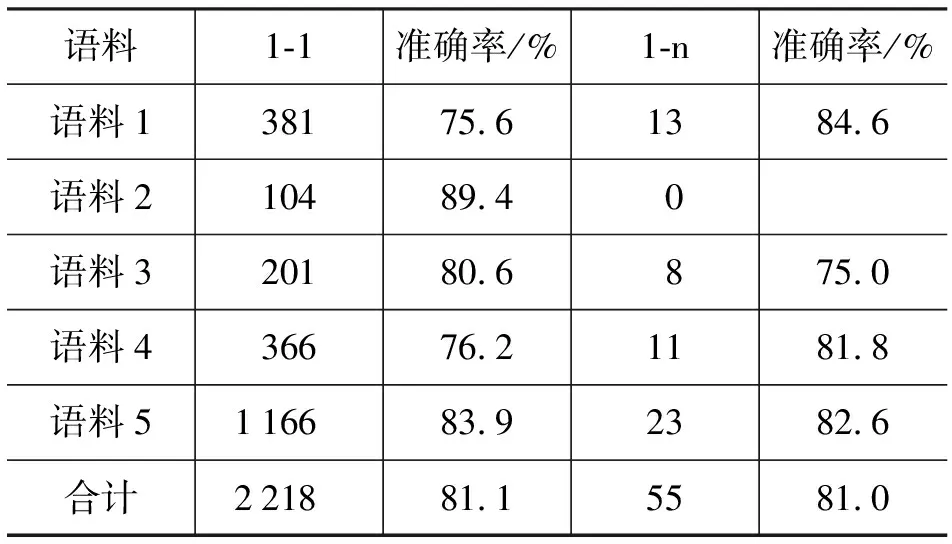
表3 TIA抽取结果的对应关系统计表
显而易见,语料中非连续短语对和1-n的短语对不可以忽略不计。TIA可以抽取连续和非连续的短语对。同时能够有效地抽取1-1和1-n汉藏短语对。从实验结果分析,由于数据稀疏问题,语料1和语料4两组准确率在同组试验中低于其他语料。低频短语在序列相交过程中很容易带着额外的与译文无关内容,这些干扰信息导致这两组的准确率降低。设定频率限度可以提高准确率,损失召回率。在每组实验结果中,语料5的准确率最佳,这表明可以通过扩大领域对齐语料规模提高覆盖率,较高的覆盖率能提高准确率。
6 结束语
目前汉藏双语语料资源不足,语料处理技术正处于起步阶段。这种前提下,文章提出两步抽取汉藏语块的方法。第一步利用Nagao的N-gram 统计算法和吕学强的SRR抽取有效汉语语块。第二步计算包含待译汉语语块的汉藏句对公共子串的思想出发,尝试藏文词串序列相交算法获取译文。其结果能满足多策略汉藏辅助翻译系统的短语实例建设需求。然而,目前收集的汉藏对齐语料中存在数据稀疏问题。N-gram、SSR以及TIA都是依赖于统计的,对于数据稀疏问题无济于事。提高语料覆盖率有利于扩建汉藏短语词典。序列相交模型将汉藏词典作为辅助资源进行短语对获取,由于召回率不高而导致未登陆现象。另外,双语语料中形态变化现象比较复杂,进一步分析和解决有助于提高准确率并解决未登录现象。下一步工作中提高准确率的同时提高召回率,使得抽取的短语融入生成模型中为汉藏辅助翻译工作发挥作用。
[1] Daniel Marcu,William Wong. A Phrase-based,Joint Probability Model for Statistical Machine Translation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Philadelphia,PA,USA. July 2002: 133-139.
[2] Dekai wu. Stochastic inversion transduction grammars and bilingual parsing of parallel corpora[J]. Computational Linguistics, 1997, 23(3):377-404.
[3] Ying Zhang,Stephan Vogel,Alex Waibel. Integrated phrase segmentation and alignment algorithm for statistical machine translation[C]//Proceeding of International Conference on Natural Language Processing and Knowledge Engineering. Beijing,2003: 567-573.
[4] Ying Zhang,Stephan Vogel. Competitive Grouping in Integrated Phrase Segmentation and Alignment Model[C]//Proceeding of ACL Workshop On Building and Using Parallel Texts. Ann Arbor,2005:159-162.
[5] H Kaji,Y Kida,Y Morimoto. Learning Translation Templates from Bilingual Texts[C]//Proceedings of the 14thInternational Conference on Computational Linguistics. Nantes France,1992:672-678.
[6] Franz Josef Och,Hermann Ney. The alignment template approach to statistical machine translation[J]. Computational Linguistics,2004,30(4): 417-449.
[7] David Chiang. A Hierarchical Phrase-Based Model for Statistical Machine Translation[C]//Proceedings of the 43thAnnual Meeting of the Association for Computational Linguistics. Arbor,2005: 263-270.
[8] 何彦青,周玉,宗成庆,等. 基于“松弛尺度”的短语翻译对抽取方法[J]. 中文信息学报,2007,21(5):91-95.
[9] 王辰,宋国龙,吴宏林,等. 基于序列相交的短语译文获取[J]. 中文信息学报,2009,23(1):39-43.
[10] 周季文,傅同和. 藏汉互译教程[J]. 北京,民族出版社,1999.
[11] 张怡荪. 藏汉大辞典[J]. 北京,民族出版社,1993.
[12] Xueqiang Lv, Le Zhang, and Junfeng Hu. Statistical Substring Reduction in Linear Time[C]//Proceedings of IJCNLP-2004,2004:320-327.
[13] Nagao,Makoto,Shinsuke Mori. A new method of N-gram statistics for large number of n and automatic extraction of words and phrases from large text data of Japanese[C]//COLING-94,1994: 611-615.
猜你喜欢
广东教育·综合(2021年11期)2021-12-02
西藏研究(2021年1期)2021-06-09
牡丹江教育学院学报(2021年1期)2021-03-23
布达拉(2020年3期)2020-04-13
师道·教研(2020年3期)2020-04-02
中学生英语·教师版(2019年6期)2019-08-01
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
民族大家庭(2016年3期)2016-03-20
中国边疆民族研究(2013年0期)2013-02-13
