
面向信息检索的近邻语言模型
2011-06-14 02:42韩中元齐浩亮杨沐昀
中文信息学报 2011年1期
韩中元,李 生,齐浩亮,杨沐昀
(1. 哈尔滨工业大学 计算机科学与技术学院,黑龙江 哈尔滨 150001;2. 黑龙江工程学院 计算机科学与技术系,黑龙江 哈尔滨 150050)
1 引言
在信息检索中应用文档语言模型(简称语言模型)由Ponte和Croft于1998年提出[1]。这个检索模型提出以后因其优良的性能而受到了广泛的关注,面向信息检索的语言模型对单篇文档进行建模,由于每篇文档的数据规模过小,因此对每篇文档进行语言模型建模存在较严重的数据稀疏问题。如何通过平滑技术使语言模型更好地服务于检索系统是一个关键问题。不少学者针对数据稀疏问题提出了一些改进的平滑方法或者模型。
平滑的基本思想是将模型中可见事件的概率值折扣,并将该折扣值重新分配给模型中不可见事件的元素序列,通过调整最大似然估计得到的概率分布,从而得到一个更准确、更合理的概率分布。经典平滑算法主要有Additive[2]、Jelinek-Merrer[3]、 Dirichlet[4]、Absolute Discounting[5]等,这几种方法从全局的角度对词的分布进行平滑处理,平滑项与文档无关,对所有文档一视同仁,缺乏对文档信息的进一步利用。在信息检索中,聚类有助于文档信息的利用,提出了基于聚类的检索方法[6-10]。文献[10]将与文档相关的信息引入语言模型的平滑中,词在文档中出现的分布由词在文档中的分布、词在文档所处分类上的分布以及词在整个文档集合中的分布共同决定,采用聚类方法的一个主要缺点是对于边界附近的文档,其聚类信息是否只带来正面信息具有一定的不确定性。
本文认为,经典平滑算法没有进一步利用文档的信息,聚类语言模型对处在聚类中心的文档性能有所提升,但是对处于聚类边界的文档,聚类信息未必能较好地反应该文档上词的分布。因此本文用近邻信息取代聚类语言模型中的聚类信息,以期能够更好地调整词在文档中的分布,获得性能上的提升。
本文组织如下: 第2节对语言模型的平滑技术以及聚类语言模型进行了分析,第3节介绍近邻语言模型的基本思想,第4节描述了如何去选择近邻,第5节介绍了实验环境并对实验结果进行了分析。
2 相关研究
传统的平滑算法(Additive、Jelinek-Merrer、 Dirichlet、Absolute Discounting等)对所有的文档进行相同的平滑处理,忽略了文档的因素。近期有学者对此进行了深入的研究,将文档的因素考虑到平滑之中。Kruland and lee在语料库中构建聚类,利用聚类信息进行文档的排序,将文档的因素引入平滑之中[11]。Liu and croft提出基于聚类的文档模型(CBDM,Cluster-based Document Model)将聚类信息引入到语言模型的平滑中[10],其公式为:
P(w|d)= (1-λ)PML(w|d)
+λ[(1-β)PML(w|Cluster)
+βPML(w|C)]
(1)
其中PML(w|Cluster)为w在d所在聚类上的最大似然估计,PML(w|C)为w在整个文档集上的最大似然估计。
在聚类语言模型中,平滑项由PML(w|Cluster)和PML(w|C)构成,PML(w|C)是与文档不相关的因素,从全局的角度考虑词的分布,PML(w|Cluster)通过文档所在聚类信息去评估词在文档中的分布。
聚类语言模型基于文档所在的聚类能够从一定程度上反映这篇文档特征的假设,对于处在聚类中心区域的文档来讲,这种假设具有一定合理性,但是考虑到文本聚类本身的偏差,对于处在边界区域的文档来讲,这种假设未必成立。
本文认为通过近邻信息有助于消除处于聚类边界的文档使用聚类语言模型时所带来的不确定性影响,由此提出近邻语言模型。
3 近邻语言模型
假设有一查询“南方 干旱”,现在有两篇文档,文档1《我校隆重庆祝九十华诞》是一篇关于哈尔滨工业大学校庆的报道(文中没有出现南方和干旱两个词),文档2《云南743万亩农田缺水917万人饮水困难》报道了云南省当时的旱情(但文中没有出现南方和干旱两个词)。在传统平滑算法的语言模型中,这两篇文档对于该查询的得分由全局信息计算,得分相同。而事实上,文档2与该查询的相关度较高,而文档1与该查询毫不相干,这暴露了传统平滑算法的不足。若是采用聚类的方法,文档1一般情况下不会被分配到旱情报道的聚类中,文档2有可能处于旱情报道聚类中,也有可能处于与云南相关新闻的聚类中,若是后者,文档1与文档2得分仍可能相同,也无法区分文档1、文档2与查询的关系,这主要是由于文档并不总是处于聚类中心附近,有可能带来较大的偏差。通过近邻信息有助于这一问题的解决。
本文认为文档的近邻文档能够从一定程度上反映这篇文档特征,例如与文档2接近的文档主要是涉及旱情的文档,其中出现“南方”或“干旱”的概率较高,将近邻信息引入语言模型,能够更真实地描述文档2与文档1的差异。由此,本文提出近邻语言模型,公式为:
PJM(w|d)= (1-λ-β)P(w|d)+βPML(w|Nd)
+λPML(w|C)
(2)
其中PML(w|C)为w在整个文档集上的最大似然估计,PML(w|Nd)为单词w在d的近邻Nd中的最大似然估计。
在这个模型中,由PML(w|C)从全局角度进行词分布的调整,由近邻PML(w|Nd)从考虑文档自身因素的近邻角度进行词分布调整。
4 近邻的选择
构建近邻信息主要涉及两个问题: 如何计算两篇文档之间的距离?构建近邻的数据来源是什么?
KL距离(Kullback-Leibler divergence)是常用的描述两个分布差异关系的一种测度。本文通过计算一篇文档与其他文档之间的KL距离来选择其近邻文档。其KL距离公式为:
(3)
本文对构建近邻的数据来源进行了实验。分别实验了从待检索文档构建近邻信息,从同一领域构建近邻信息,从较大数据集中选择部分文档构建近邻信息,选择的方法是使用与待检索文档集分布KL距离最接近的N篇文档。
5 实验环境及结果
5.1 实验环境
TREC(Text REtrieval Conference),文本检索会议是文本检索领域最权威的评测会议之一,由美国国防部和美国国家技术标准局(NIST)联合主办。本文采用TREC_1、TREC_2的数据作为实验数据。其中TREC数据DOE部分(美国能源署文件)有两个文件夹,第一个文件夹,记为DOE1,第二个文件夹记为DOE2。WSJ(《华尔街日报》)按年份划分,记为WSJ90(90年)、WSJ91(91年)、WSJ92(92年)。实验分为8组,其中以DOE1作为待检索文档的实验有4组,近邻选择的数据来源分别选取了DOE1自身文档集、与带检索文档相同来源的文档集DOE1+DOE2、在DOE1+DOE2中选择与DOE1规模相当的100 000篇文档、整个TREC12文档集中选择与DOE1规模相当的100 000篇文档。WSJ90实验同为4组,近邻选取策略与DOE实验策略相同。其具体实验数据如下表所示:
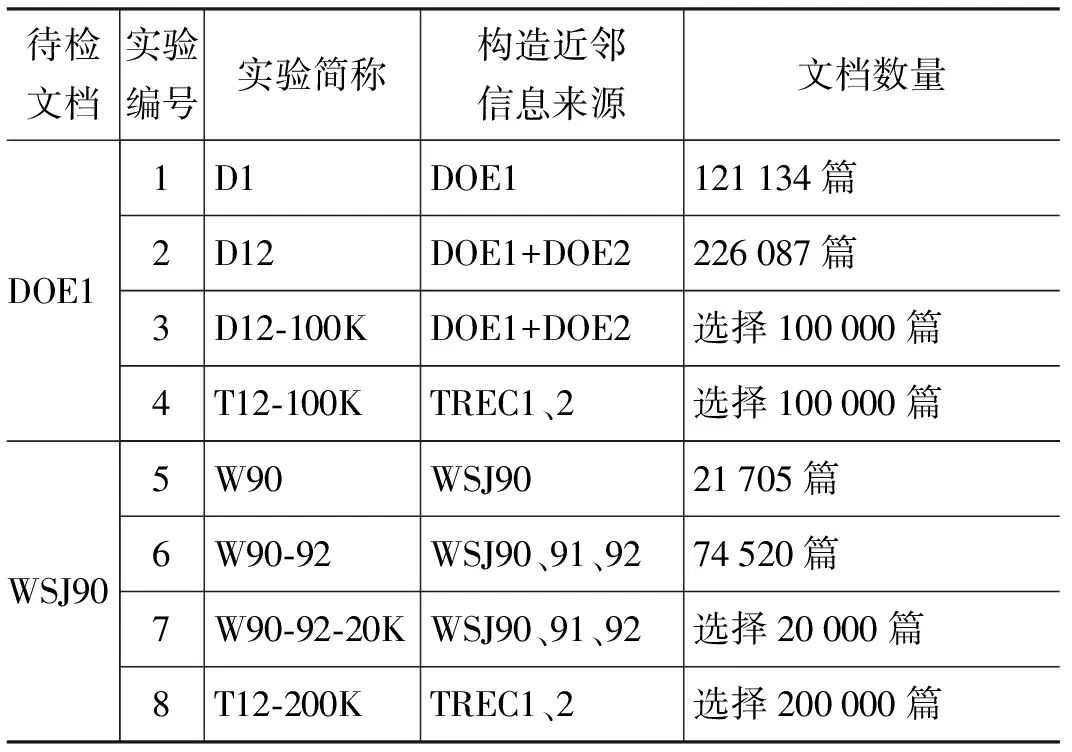
表1 实验数据说明
本文采用常用的采用Jelinek-Mercer平滑方法的语言模型作为对比试验,如公式(4)所示:
PJM(w|d)=(1-λ)P(w|d)+λPML(w|C)
(4)
其中PML(w|C)为w在整个文档集上的最大似然估计。根据经验,λ取0.2。
其他实验使用的公式(2),λ,β取值在[0,1]之间,以0.01作为步长,且λ+β≤1;近邻文档数量取值[0,200]之间,以10作为步长;近邻数量在实验中选择10,20,30,40…200篇。
参数确定采用leave one out方法,即一个查询的参数由其他查询作为训练时所得的参数所确定。
5.2 评价指标
本文选用信息检索系统中常用的评价指标平均精确率(MAP,Mean Average Precision)来检验索引策略对检索系统性能的影响。
平均精确率AP(Average Precision): 单个主题的AP是每篇相关文档检索出后的准确率的平均值。主题集合的MAP是每个主题的AP的平均值。MAP是反映系统在全部相关文档上性能的单值指标。AP定义如公式(5)所示:
(5)
其中:rij为查询Qi第j个相关文档的位次;|Ri|为查询Qi的相关文档数;n为测试的查询数。
5.3 实验结果
本文测试了近邻数量对性能的影响,实验结果如图1和图2所示。图中以每十篇近邻数量递进,每个线对应一组实验统计值,由实验简称+后缀标示,其中后缀MAX代表该实验取得的最高MAP值,后缀AVG代表该实验所有参数组合所取得MAP的平均值。
从图1可以看出,对于DOE短文档,其近邻的数量在大于30篇之后,对近邻语言模型可能达到的最高MAP值影响不大,但是从平均性能上,更多的近邻数量有助于性能的提升,但提升空间有限。从图2可以看出,对于WSJ相对较长的文档,过多的近邻数量对性能并没有带来积极作用。综合来讲无论是从最高性能还是平均性能上考虑,取相对较少的近邻数量(20~30篇近邻)较为合理。
使用leave-one-out方法进行参数训练后的实验结果如表2、表3所示。

图1 在DOE实验中近邻数量与MAP的关系

图2 在WSJ实验中近邻数量与MAP的关系
表2DOE的实验结果

评估指标语言模型实验简称D1 实验编号(1)提升幅度/%D12 (2)提升幅度/%D12-100K(3)提升幅度/%T12-100k(4)提升幅度/%MAP0.12160.125230.13208.60.12734.70.12926.3

表3 WSJ90的实验结果
对比实验1、2和5、6可以看出,增加相同领域文档规模,性能有所提升。对比实验3、4和实验7、8可以看出,从更大规模上挑选近邻选择来源,有助于检索性能的进一步提升。对比实验1、3和5、7,利用相同领域的文档作为近邻选择来源与自动选定的近邻选择来源性能相近。
6 结论及未来工作
本文认为利用文档的近邻信息能够更合理地反映词在文档中的分布,有助于数据稀疏问题的解决,因此将文档的近邻信息加入语言模型的平滑算法中,提出近邻语言模型,并对选择近邻的文档来源问题进行了分析,并在TREC数据集上测试了近邻语言模型在不同近邻选择集合上的性能。实验表明,将近邻信息加入到语言模型中有助于改善检索性能。
近邻语言模型的计算量较大,一篇文档要通过逐个计算与近邻数据来源中每一篇文档的距离来找到它的近邻,这限制了该模型的应用前景。计算量主要由选择近邻数据来源的规模所决定,因此减少选择近邻数据来源的规模可以有效地降低计算量,例如可以考虑利用返回结果的前N篇文档来作为近邻选择的数据来源,从而大幅度降低计算量,此外也可以离线建立并存储近邻关系以提高检索速度。本文初步验证了近邻语言模型的有效性,未来将在如何选择近邻的数据来源、如何更有效地利用近邻信息、如何降低计算复杂度等方面进行进一步的研究。
[1] Ponte J M, Croft W B. A Language Modeling Approach to Information Retrieval[C]//Proceedings of the 21th annual international ACM SIGIR conference on Research and development in information retrieval, Melbourne, Australia: ACM, 1998: 275-281.
[2] G.J.Lidstone.Note on the general case of the Bayes-Laplace formula for inductive or a posteriori probabilities[J].Transactions of the Faculty of Actuaries,1920,(8):182-192.
[3] S.M.Katz.. Estimation of probabilities from sparse data for the language model component of a speech recognizer[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1987:400-401.
[4] MACKAY, D. AND PETO, L. A Hierarchical Dirichlet Language Model[J]. Natural Language Engineering, 1995,(1):289-308.
[5] NEY H., ESSEN U.,KNESER, R. On structuring probabilistic dependencies in stochastic language modeling[J]. Computer, Speech and Language, 1994,(8):1-38.
[6] Croft, W. B. A model of cluster searching based on classification[J]. Information Systems,1980,(5):189-195.
[7] Jardine, N. and van Rijsbergen, C.J. The use of hierarchical clustering in information retrieval. Information[J]. Storage and Retrieval,1971,(7):217-240.
[8] CJ Van Rijsbergen, WB Croft. Document clustering: An evaluation of some experiments with the Cranfield 1400 collection[J]. Information Processing & Management,1975,(11):171-182.
[9] Voorhees, E. M. The effectivenss and efficiency of agglomerative hierarchic clustering in document retrieval[D].The Department of Computing Science, Cornell University. 1985.
[10] Xiaoyong Liu, W. Bruce Croft. Cluster-based retrieval using language models[C]//Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval, Sheffield, United Kingdom: ACM,2004:186-193.
[11] Oren Kurland, Lillian Lee.Corpus structure, language models, and ad hoc information retrieval[C]//Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval, Sheffield, United Kingdom: ACM, 2004: 194-201.
猜你喜欢
客联(2022年3期)2022-05-31
学苑创造·A版(2022年5期)2022-05-19
中国新闻周刊(2021年26期)2021-07-27
汉字汉语研究(2019年2期)2019-08-27
流行色(2018年11期)2018-03-23
电脑爱好者(2017年7期)2017-05-06
专利代理(2016年1期)2016-05-17
对联(2011年10期)2011-09-18
质量与标准化(2010年5期)2010-05-03
