
基于GPU的高速铁路扣件实时探测技术
2011-06-11 03:35王梦雪陶卫杨金峰吴芳赵辉王卫东任盛伟
大连交通大学学报 2011年6期
王梦雪,陶卫,杨金峰,吴芳,赵辉,王卫东,任盛伟
(1.上海交通大学 电子信息与电气工程学院,上海 200240,2.中国铁道科学研究院,北京 10081)
0 引言
扣件在铁路系统起到固定铁轨的重要作用.而现今,扣件检测主要依靠的是铁路工人的沿线排查,速度慢效率低.特别是近年来高速铁路的兴起,其封闭环境更增加了人工巡检的难度[1].目前国际上对此常用的解决方案多为视觉自动化检测技术,即在巡检车上挂载高速相机,拍摄扣件图片,对图片进行处理分析,实现自动化检测.
但是,由于传统的图像处理与模式识别存在信息量大、处理速度低的缺陷,扣件在线探测速度低一直是影响该方法实际应用的软肋.到目前为止,国内外扣件最快检测速度出现在西日本铁路公司2006年的新干线141系综合检测车上,但也只在150 km/h左右.
随着我国高速铁路事业的发展,其对扣件检测的速度要求越来越高.特别是我国近期开通的京沪高铁,其对检测速度的要求更是达到了400 km/h以上.由此可见,提高扣件在线检测速度的要求迫在眉睫.
针对这个问题,本文提出了一种基于GPU加速的扣件在线检测技术,可以准确地识别扣件缺失状况,同时将处理速度大幅度提高,满足了400 km/h高铁试验速度的在线探测要求.
1 系统组成与工作原理
该铁路扣件在线探测系统由两个探测器和一个控制系统组成.左右探测器分别监测左右两个钢轨的扣件状态,检测信号送入处理系统,进行处理、识别、判断、存储和输出.位置信号来自车轮和车体,报警信号送至车载处理中心.图1中为单个探测器的组成示意图.

图1 扣件探测系统组成原理示意图
在列车运行过程中,两台高速工业相机连续拍摄扣件所在区域的灰度图像,并对其进行图像处理和模式识别,最终得到匹配结果,实时检测了扣件缺失状况.
采用通用的模式识别算法提取扣件图像的纹理信息,通过与标准扣件模板进行局部梯度值匹配,并与设定阈值比较,从而判断扣件缺失情况,具有稳定度高,不随扣件形状的改变而失效的优点.其信息量丰富,故处理速度相对较慢,无法满足高速铁路的在线探测需求.
GPU原本应用于复杂3D图形及图像的处理运算.与CPU相比,GPU是一种高并行度、多线程、拥有强大计算能力和极高存储器带宽的多核处理器[2].现今,其最高理论浮点计算速度已经可以达到40Tflops,远远高于同期的 CPU.如今,随着计算统一设备架构(Compute Unified Device Architecture,CUDA)的出现,使得GPU的可编程性能再度得到提升.
所以本文采用了一种基于GPU与CPU协作的处理技术,即GPU负责图像算法运算,CPU则负责流处理,这样实现了扣件缺失的高速探测.
2 GPU相关研究
GPU发展到现在,已经远远不只图形渲染图形处理领域的应用.作为广义的图形处理器,大量的并行处理单元和存储控制单元使其在通用计算方面能比CPU提供更多的运算资源.
NVIDIA GPU使用了CUDA编程模型,对图形硬件和API进行封装,使得开发人员把GPU看成是一个包含了许多核许多线程的处理器,并在类似于CPU的编程环境中对GPU进行编程,实现 GPU 的通用计算[3].
本文主要以新一代的Fermi架构GF100[4]来说明CUDA的软硬件架构.从硬件架构来看,GF100包含四个图形处理团簇(GPC,Graphic Processing Core).每个GPC包含一个光栅引擎和四个SM(Streaming Multiprocessor,多线程流处理器)单元以及一些存储单元.如图2中所示.

图2 GPC架构
软件上,CUDA对底层硬件的封装,使其对外显示出线程的三层组织结构,如图3所示.具体如何组织网格(grid)由启动kernel函数时提供的配置参数决定[5].执行配置的第一个参数指定网格的维度,第二个参数指定块的维度,如 kernel Function<<<dimGrid,dimBlock> > > (…),dimGrid表示一个Grid中的Block数量,而dim-Block则表示一个Block中的thread数量.

图3 kernel组织结构
而GPU理论性能的描述主要从以下几个方面描述:
(1)CGMA(Compute to Global Memory Access),是在CUDA程序的某一区域内每次访问全局存储器时,执行浮点操作运算的次数.
(2)Speedup(加速比),此项指标是指对于同一算法的实现,GPU与CPU的耗时比值.记CPU耗时为ts,GPU耗时为tp,则
3 扣件探测算法在GPU上的实现
3.1 算法实现步骤
实际算法在GPU上进行并行计算主要有以下步骤:
(1)将主机端内存中的图像数据和模板纹理通过PCI-E总线传输到设备端全局存储器,并绑定到GPU的纹理存储器中.
(2)对输入图像数据进行边缘提取,抽样滤波以及模板匹配等处理,将匹配结果存入全局存储器中以便送回给主机端.
(3)将匹配结果传出给主机端,方便进行显示,分析.
具体算法流程及存储器设计如图4所示.此算法利用GPU的高吞吐量,采用一次向GPU压入N幅图像,降低了平均每幅图像的传输延时;通过充分利用shared memory的块内快存储特性,减少了程序对global memory的读写次数,对提高CUDA kernel的性能有很大意义;使用了texture memory对图像进行梯度的计算,同样提高了算法稳定性和快速性.
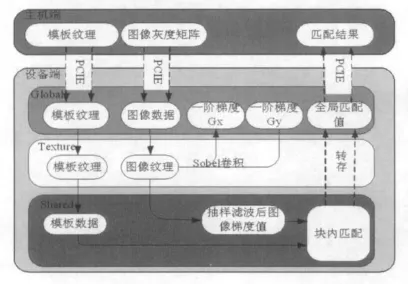
图4 算法流程图
3.2 GPU程序的优化
影响CUDA kernel函数性能的因素主要有以下三个:CPU-GPU之间的数据传输延时;全局存储器的访存频率(CGMA值);kernel函数的结构组成(分支、循环).下面会分别对这三点进行详细分析,并针对本文的算法进行优化处理.
下面是一组未经过优化的实验数据,如图5所示.50表示一次传入GPU的图像数为50幅,1表示一次传入一幅.图像分辨率分别为160 dpi×120 dpi,320 dpi× 240 dpi.

图5 多幅图一次传入性能比较
从图中可以很明显的看出,一次压入50帧比一次压入1帧的平均每帧传输延时减少了50~100倍,这是由于多次传输会浪费GPU大量warp线程,而一次传输会大大减少这种浪费.鉴于这个原因,本文采用大吞吐量设计,考虑GPU一次处理多帧图像,降低每帧的平均延时.
其次,CGMA同样对CUDA程序性能影响很大.CGMA能综合反映出许多对执行效能有影响的因素如I/O效能,内存架构,cache的一致性.例如,NVIDIA公司生产的GTX470支持全局存储器的访问带宽为135.9 GB/s,则对于单精度浮点数的加载速度不会超过33.975Gflops(135.9/4).如果CGMA比值为1.0,即执行一次单精度浮点运算即加载一次全局存储器数据,则每秒钟可执行的浮点操作也不会超过33.975Gflops,这相对于GTX470理论最高单精度浮点处理速度1.633Tflops来说,实在是相形见绌,限制了硬件良好性能的充分发挥.所以提高CGMA比值,是提高kernel函数性能的关键.
本文针对提高CGMA使用了两种方法:第一,选择将图像数据和模板纹理数据均绑定到纹理存储器,从而减少对global memory的读写.纹理存储器(texture memory)是由GPU用于纹理渲染的图形专用单元发展而来,有着无需考虑图像访问越界等独特的特性,从底层的存储机制来说,纹理存储器是一种SP访问全局存储器的不严格机制,以缓冲来自全局存储器的数据.一旦将全局存储器中的某一区域与纹理存储器绑定,那么只有当缓冲失败的情况,才会访问全局存储器,大大减少了访问global memory的次数,提高了CGMA比值.第二,将分块技术与数据预取技术相结合.即充分利用块(block)内共享存储器(shared memory)(快读写,速度接近寄存器),在使用当前数据元素时预取下一个数据元素,将其从其他存储器(如 global memory)加载到共享存储器[6].
另外,指令混合也是CUDA优化技术的一种.其旨在kernel函数中减少循环和递归的使用,通过减少对有限的指令带宽的占用来提高GPU的指令执行速度.但是由于本算法固有的循环维度比较大的特性,此项技术的可行性不高,所以本文只对源程序的一个10×10的小循环做了循环展开,不过运算速度却大大提高.实验结果会在4.1节中给出具体分析.
4 GPU加速性能实验研究
本文中采用了七彩虹 iGame GTX470-GD5 CH版显卡,其GPU为NVIDIA公司的GTX470型号,核心频率为607MHz,显存1280MB;CPU采用Intel Core2 Duo 2.7GHz,内存 2GB.编程环境为Windows下 Visual Stdio 2008(VC++9.0).
实验中,为了得到统计性能更好的数据,我们对每次的实验数据量都进行了20次平均.
4.1 指令混合优化实验
指令混合前后GPU耗时实验数据如表1所示.从表1中可以看出,块的大小在性能中起着主要作用.在块大小比较小的时候,循环展开对性能的提升基本没有作用.这是由于,当块大小比较小时,全局存储器的带宽处于饱和,性能瓶颈会出现在存储器的读写上,循环展开对此将失去优化意义.而当块大小足够大时,此时指令混合和数据预取技术就显得尤为关键,本例中,仅仅一个10×10的循环展开就让性能提高了20%~40%,可见此项技术的优化潜力还是很大的.
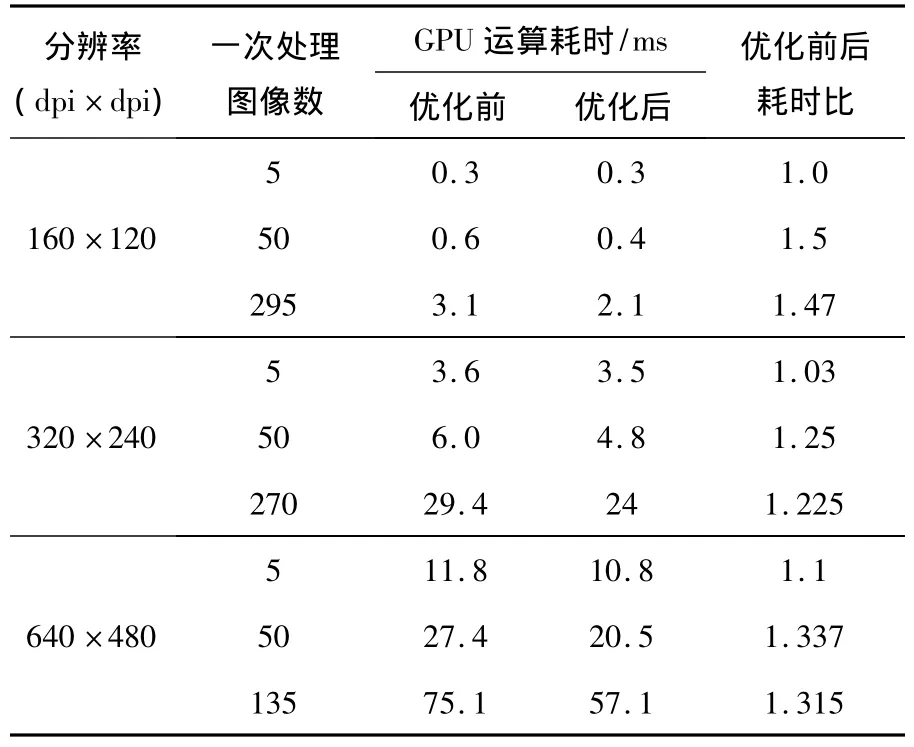
表1 优化前后耗时对比
4.2 GPU加速性能实验
本实验对不同分辨率下(160 dpi×120 dpi,320 dpi×240 dpi,640 dpi×480 dpi)的N幅图同时处理,分别得到CPU耗时和GPU耗时,测时分辨率为0.1 ms.如表2所示.其中GPU运算耗时是指算法在GPU端的计算时间,不包括前期的数据准备以及数据传输时间;而总耗时是二者均有的总时间.
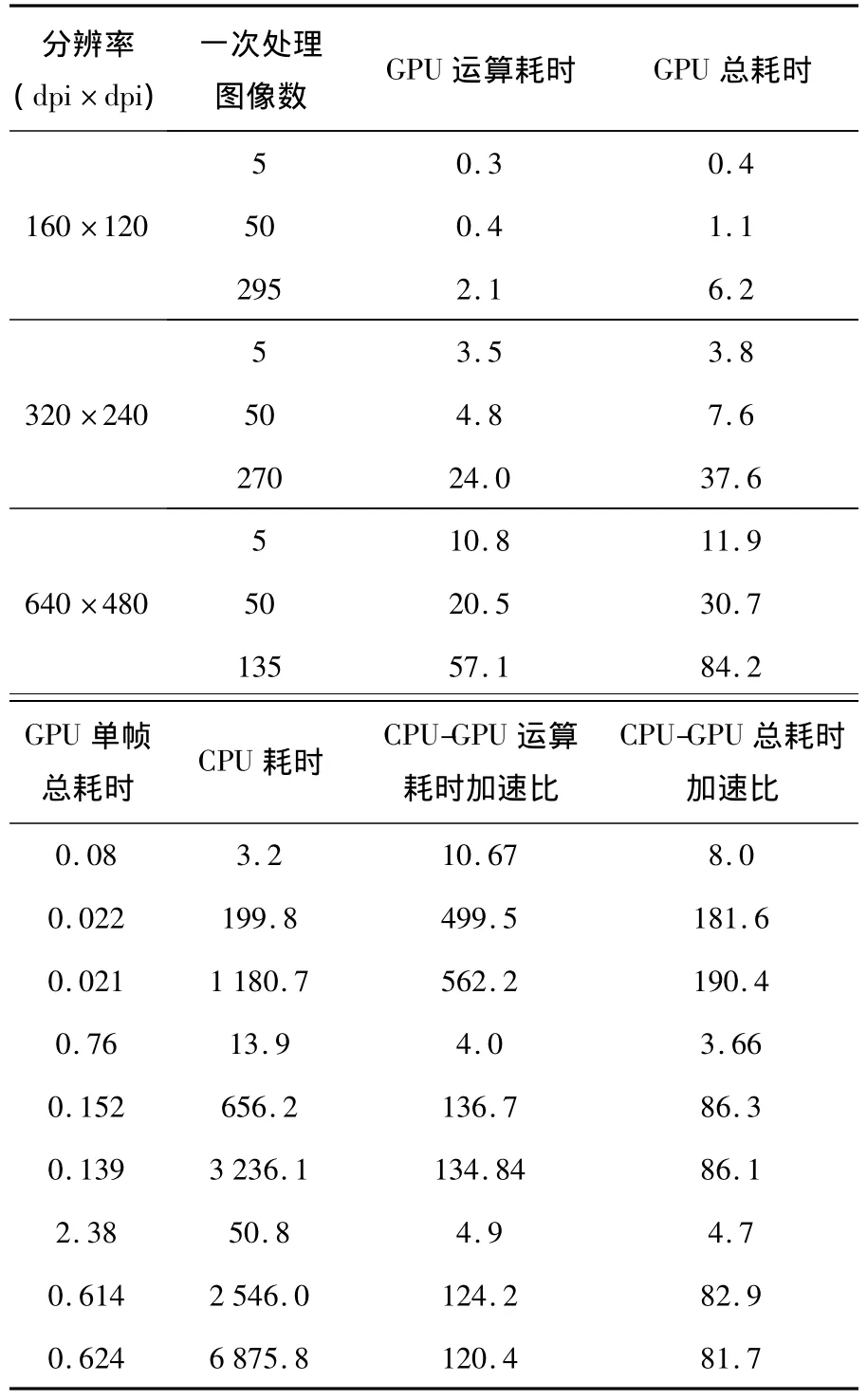
表2 耗时测试结果 ms
从表中可以明显的看出,不论是否计入传输时间,获得的加速比都是很大的.特别是在不计入传输时间以及设备端的初始化等工作时间的情况下,加速比可高达500左右.需要说明是,本文CPU中的算法是经过优化处理的,所以得到的加速比的可信度是比较高的.
分析表2,可以得到如下两个结论:
(1)在数据量比较小时,如图像只有一幅的情况下,加速比较小;相反,在数据量比较大的情况下,加速比会大大提高.这也正体现了GPU设计的初衷,即提高吞吐量,而并不是与CPU拼单一速度.
(2)Kernel函数的性能优化技术的有机结合对性能的提高有重要意义.从图中可以看出,当数据量为160×120×50时,加速比一度提升至600左右.这与kernel函数中的线程粒度与数据预取的合理平衡有很大关系.数据量的合理性使得每个SM上运行的线程数量大大提高,这对于整个算法的吞吐量有很大的提升.
(3)数据大到一定数量时,GPU平均每帧的处理时间会出现波动,甚至下降.这是由CUDA底层指令执行流所决定的.GPU中指令是以warp为单位发射的,而每个warp中有32个thread,当数据量变化时,thread数量也会随之变化,多出一个thread可能就会多一轮warp.所以出现波动是正常可预测的,这也表明,在实际GPU编程中,需要注意thread数量,最好为32的整数倍,这样可以充分利用硬件资源,减少SM的空载浪费.
另外,本实验还有一点需要说明:由于本实验block的维度设计与图像宽度和图像数有关,当数据量增加时,block的维度也会随之增加,当数据量增加到一定程度时,会出现超过CUDA目前计算能力的block最大允许维度(65536),例如,数据量为320 dpi×240 dpi×275 dpi时,程序无法运行.这也很好的说明了,对kernel采用多种技术时,互相之间会相互影响,从而限制了彼此能优化的最大程度.
5 结论
本文围绕高速铁路扣件在线检测的速度难点进行了研究,提出了采用GPU对其中改进的模板匹配算法进行加速的实时检测技术,并对其的CUDA实现进行了深入分析以及实验验证.通过对本算法的GPU加速,可以获得实时的扣件缺失情况.在不低于200帧/s的高速采样频率下,实现了扣件实时在线检测,达到了平均每幅图优于0.02 ms的处理速度.在160 dpi×120 dpi图像分辨率下,一次处理50帧时,GPU的处理速度,相对于CPU计算,从3.996 ms/帧的处理速度提高到了0.022 ms/帧,加速比高达154.由此可见,GPU强大的计算能力及应用前景,GPU的加速技术不仅对于扣件检测有应用意义,更是为整个高速图像处理领域提供了重要的参考.
[1]钱广春,陶卫.基于相关直线法德高速运动目标快速探测方法[J].大连交通大学学报,2011,32(2):79-82.
[2]吴恩华.基于图形处理器(GPU)的通用计算[J].计算机辅助设计与图形学学报,2004,16(5):601-612.
[3]柳彬,王开志,刘兴钊,等.利用CUDA实现的基于GPU的SAR成像算法[J].信息技术,2009(11):62-65.
[4]NIVDIA's Next Generation CUDA Compute Architecture:Fermi,Whitepaper[M].NVIDIA CORPORATION,2009.
[5]NIVIA CUDA Programming Guide Version 2.0[M].NVIDIA CORPORATION,2008.
[6]JOAO LUIZ DIHL COMBA,DIETRICH CARLOS A,PAGOT CHRISTIAN A.Computation on GPUs:From a programmable pipeline to an efficient stream processor[J].Revist a de Inform tica Tericae Aplicada,2003,X(2):41-70.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
铁道建筑技术(2020年11期)2020-05-22
电子制作(2019年13期)2020-01-14
西南交通大学学报(2018年5期)2018-11-08
西安建筑科技大学学报(自然科学版)(2016年5期)2016-11-10
城市轨道交通研究(2015年3期)2015-02-27
环球时报(2014-06-18)2014-06-18
