
基于DXVA的多路H.264高清视频解码器的实现
2011-06-07 05:53苏俊峰朱秀昌
电视技术 2011年18期
苏俊峰,朱秀昌
(南京邮电大学 江苏省图像处理和通信重点实验室,江苏 南京 210003)
0 引言
H.264是目前视频压缩领域编码效率较高的视频编码标准,但是其运算复杂度较高,特别是随着高清数字电视(HDTV)技术广泛应用和互联网的快速发展,使编解码器对处理器的要求越来越高[1]。HD视频中较低的解析度即为720p分辨力,采样点高达1 280×720,而顶级格式的1 080p更是达到了1 920×1 080。在高分辨力的情况下,其码率是很高的。例如,720p格式中帧率为60 bit,10 bit量化、4∶2∶0采样方式,其码率为791 Mbit/s,如果采用视频压缩技术,压缩后码率也超过12 Mbit/s,这也就意味着视频解码和后期处理对处理器具有很大的挑战。
如何在现有计算机的基础上降低视频解码对硬件的要求,进而降低CPU的使用率已成为视频解码技术的研究热点。当前主流的方法是通过利用GPU(Graphic Pro⁃cessing Unit)来分担视频解码的部分工作[2]。而利用GPU来进行视频解码的技术主要有两种方式:第一种是利用GPU内部能够并行工作的流处理单元,编写在GPU上运行的代码,典型的代表有NVIDIA的CUDA和ATI的Stream技术;第二种是间接通过GPU来加速,通过制定统一的解码接口来实现,主要是微软的DXVA(DirectX Video Acceleration)。第一种方式在解码速度上有优势,但是实现起来比较复杂,而且必须熟悉GPU的架构和数据处理流程,针对不同的GPU设备,实现的代码不相同,跨平台性能差。而第二种在速度上可能有一点逊色,但是实现起来简单,可扩展性能好,针对不同的GPU设备,只要支持DXVA都可以使用。通过以上分析,本文采用基于DXVA的H.264视频解码设计。
1 H.264标准和DXVA技术
H.264是目前视频压缩领域编码效率较高的编解码标准。其软件解码框图如图1所示。主要完成以下功能:解码器首先提取H.264码流中的NAL单元,然后对NAL单元进行熵解码、反量化和反变换,根据参考帧和运动矢量进行预测和运动补偿,然后把解码出的图像进行环路滤波,最后对滤波的图像进行显示和参考帧缓存[3-6]。

DXVA是微软为加强视频播放效果所设立的一套API(Application Programming Interface)和 DDI(Device Driver Interface)。通过DXVA可以把解码的部分工作和视频的后期处理操作从CPU转移到GPU,这样利用了GPU硬件单元的并行处理来加速视频播放的效果,从而降低了CPU的利用率[7]。
在H.264视频解码的过程中,运动补偿、反离散余弦变换和可变长编码这些操作占了解码总操作时间的80%以上[8],因此,如果能够减少这些操作的时间,那么解码的整个时间一定会减少很多,而且也会大大降低CPU的工作量。目前DXVA规范规定的硬件加速的操作也正是这些解码过程,不过DXVA是按等级来划分的。例如,对于H.264标准来说共分为6个等级,分别为DXVA2_Mo⁃deH264_A~DXVA2_ModeH264_F。因此,GPU厂商在实现这些接口的时候也只是实现了其中的一些子集,本文采用GF9500GT实现的等级是DXVA2_ModeH264_E,也就是MC,IDCT和VLC的解码操作都是在GPU上实现的。
2 高清解码器的设计和实现
要实现解码器的硬件加速功能,就是把软件解码器的部分工作转移到显卡的GPU上来完成,但是由于显存和内存之间数据总线的传输速率相对于处理器的处理速度比较慢,所以在设计解码器的过程中要尽量减少数据在内存和显存之间的传输次数,并且解码之后的数据尽量不要再传回内存,否则可能会降低解码器的性能,也就是说把视频数据的后期处理(如颜色空间转换、缩放等一些特效)也利用显卡进行。
如图2所示,DXVA硬件解码主要有3种处理架构:将解码的MC部分转移到GPU中;MC和IDCT转移到GPU中;将MC,IDCT和VLD转移到GPU中执行。图中虚线以上为CPU执行部分,虚线以下为GPU执行部分。本文按第3种架构来实现H.264视频解码器。

2.1 DXVA解码器使用的缓冲区
解码器如果要使用硬件解码单元,必须要给硬件单元传送一定的配置参数,DXVA同样也不例外,每个参数都是以对应的缓冲区来传送的,所以,如果要传送参数必须首先向DXVA申请缓冲区,然后填充对应类型的缓冲区。本文解码器需要传送4个解码参数,即4个缓冲区:图片参数缓冲区、条带控制命令缓冲区、码流缓冲区和量化值缓冲区。
1)图片参数。在DXVA解码器解码当前帧时需要一个对当前帧描述的参数,对于H.264标准用DX⁃VA_PicParams_H264结构体描述。图片级别中每个图片的信息会不一样,所以每解码一帧图片之前,此结构体都要被传送。以下是DXVA_PicParams_H264结构体的定义:

例如参数中的wFrameWidthInMbsMinus1对应于H.264标准中的同名参数。本文在传送该参数前需要先调用IdirectXVideoDecoder::GetBuffer()来获得图像参数的缓冲区,该函数共有3个参数,分别为缓冲区类型,指向缓冲区的指针地址和缓冲区的大小,对于图片参数来说,缓冲区类型为DXVA2_PictureParametersBufferType,而这个缓冲区类型是枚举类型。得到此缓冲区之后即可以进行配置图片参数。
2)条带控制参数。条带控制参数是对当前码流的描述,用DXVA_Slice_H264_Short结构体来描述,其定义为:

其中,BSNALunitDataLocation表示传送码流的NA⁃LU单元中编码数据的起始字节数,wBadSliceChopping表示传送的码流是否包含起始码,SliceBytesInBuffer表示传送码流总的字节数,此数值不是用户实际传送的码流字节数,而是用户传送的码流按照128 byte对齐的数值,不足的部分用零填充,对齐的主要作用是在内存和显存之间能够高效快速地传送数据。
3)量化矩阵缓冲区和码流缓冲区。量化矩阵缓冲区是解码器进行反量化时所用矩阵的缓冲区,其定义为:

该缓冲区数据结构包括两种反量化矩阵,即4×4和8×8反量化矩阵。码流缓冲区是一块分配的显存地址,把解码的码流通过该缓冲区传送给GPU。
4)存放视频数据的缓冲区。码流在GPU中解码后的数据一般是YUV格式的,解码后的数据存放在叫“表面”(Surface)的硬件缓冲区,即存放视频数据的显存。存放数据的方式取决于表面的类型(视频数据的存放格式)以及显卡所支持的类型,对于DXVA解码来说,微软推荐的视频数据类型是NV12,所以大多数显卡都支持这种视频数据的存放格式。
NV12格式中每个视频数据采样点的每个分量用1 byte表示,存放的方式是一帧数据中所有的Y分量存储在第一个区域内,后面是UV数据的打包形式,即每个像素的UV分量交替存储。而数据在表面中存储也是按行存储的,即表面每行视频数据的字节数是和分辨力有关的,但每行的实际长度和分辨力不一定一样,这主要取决于显卡驱动程序。可以通过调用显卡驱动的API函数来获取表面中每行的实际长度。图3是NV12类型的表面示意图,其中视频的分辨力是1 280×720,驱动程序是NVIDIA 266.58版本。由图3可知,表面的实际长度是2 048,而不是1 280。

2.2 视频数据的后期处理
如前所述,视频解码后的数据是存储在显存中的,而且数据的格式和显示器能够显示的格式是不相同的,要显示解码后的视频图像必须对数据进行后期处理,例如反交织、图像缩放和颜色空间转换等操作。如果这些操作用软件的方式通过CPU进行处理,那么解码后的视频数据就必须从显存再传回内存中,数据处理过之后再传回显存进行显示,由于总线数据传送速度的限制,这样会大大降低解码器的性能,甚至会使解码器的解码速度达不到播放的要求。
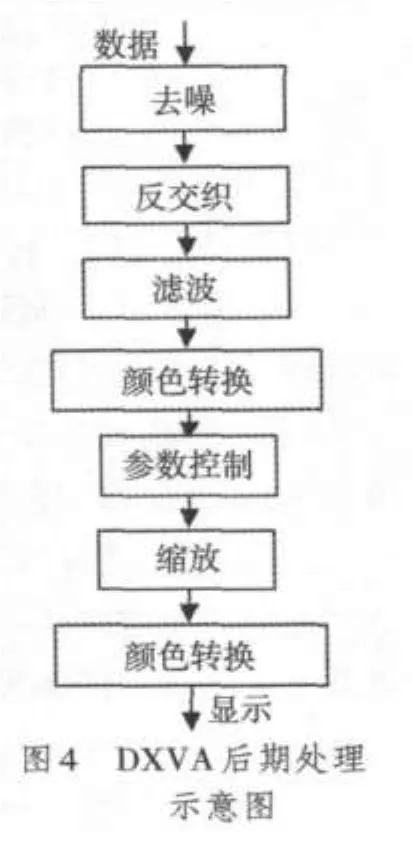
现在的主流显卡一般都集成了视频的后期处理功能,这样就能够使解码后的数据不用再传回内存而在显卡内就可以进行处理,而且基于硬件的处理操作速度会比软件更快,这样也就进一步提高了解码器的性能。DXVA规范中关于后期处理的操作是DXVA Video Process⁃ing,该操作可以完成视频数据的后期处理,包括反交织、视频流混合、图像缩放、颜色空间转换和图像滤波等。其示意图如图4所示。
2.3 多路解码器的设计与实现
本文在设计解码器的过程中把大量的算术运算转移到GPU上,利用其硬件单元来解码,但是对于码流的头部解析包含大量的逻辑运算,如果也转移到GPU上进行,对解码器的性能有很大的损耗。所以在系统设计时把码流的头部解析通过软件来进行。
在整个程序的设计过程中,主要定义了代表显卡设备的数据结构和代表解码器的数据结构。因为驱动程序允许多个对象共享一个硬件设备,所以多个解码器可以关联一个显卡设备。显卡数据结构的定义为:

其中,Hwnd是程序创建的一个用来显示的窗口句柄,pD3D9和pD3DD9分别表示显卡对象和显卡设备,pD3Dmanager是一个显卡设备的管理器,主要是用来管理多个解码器共享显卡设备的,PCI_Vendor代表显卡的制造厂商,DecoderCnt是表示和显卡关联的解码器个数。解码器定义的数据结构如下:

pD3Dmanager是解码器关联的显卡设备,pDX⁃VADecoder是所创建的解码器,pD3D9 Surface是解码后的数据存放的表面,DxvaPicParams,DxvaSliceShort和Dx⁃vaQmatrix是提到的解码硬件单元用到的数据缓冲区结构,sps和pps是H.264标准中所表示的条带控制参数和图像控制参数。在设计中,本文定义了设备的创建和解码接口,这样方便其他的程序或客户使用,在整个系统中,主要定义了5个接口函数:
1)HRESULT InitD3D Manager(D3DManager*pMan⁃ager)。函数的主要功能是初始化显卡并创建一个显卡设备,检测显卡的类型等。
2)HRESULT Create Dxva Decoder(DXVADecoderH264*pDecoder)。函数的功能是根据所关联的D3Dmanager创建一个硬件解码器对象,并使所关联的D3Dmanager数据结构中的解码器的计数加1。
3)HRESULT Dxva Decode Frame(DXVA DecoderH264*pDecoder,NALU_t*pH264NALU,RECT*pRect)。函数是解码器的解码接口,主要有3个参数,第1个是代表解码器,pH264NALU是H.264码流中的一个NALU单元,pRect是代表该解码器解码后的数据在显示窗口的显示区域。
4)HRESULT Destroy Dxva Decoder(DXVADecoderH264*pDecoder)。函数的功能是释放解码设备并使所关联的D3Dmanager数据结构中的解码器计数减1。
5)HRESULT DestroyD3D Manager(D3DManager*pManager)。函数的功能是释放显卡设备并销毁所创建的显示窗口,该函数在销毁之前会检测其关联的解码个数是否为0,如果不为0,则该函数什么也不执行并立即返回,所以在任何时候调用都能够确保安全。
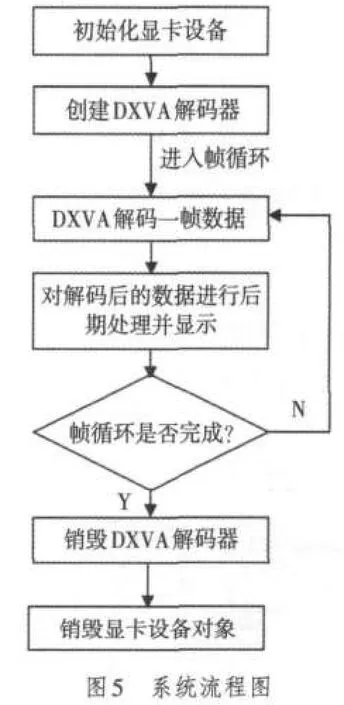
整个系统的流程如图5所示,其中解码器在解码一帧数据时的内部解码流程如图6所示。其中在解码器内部加一个阻塞锁是为了防止多个解码器同时使用一个硬件解码单元,因此本文设计的系统可以开启多个解码线程进行多路解码。

3 解码器性能评测
由于显卡驱动程序对硬件解码单元最大的解码路数的限制,其限制最高同时执行4路解码,所以测试时开启4个解码线程同时解码分辨力为1 280×720的高清视频。评测的环境是双核CPU 2.5 GHz,内存DDR2 2 Gbyte,显卡GF9500GT,并在Visual Studio 2008环境下调试编译,计时采用C语言库的clock()函数,精确到毫秒级。解码器同时解码4路高清视频的显示效果如图7所示。

本文主要测试解码器的解码速度和CPU的占用率这两个指标。测试时,操作系统为Win7,CPU为奔腾双核E5200 2.5 GHz,显卡为中低端显卡NVIDIA GeForce 9500T。在测试解码速度时,采用固定码率的码流,码率的大小和蓝光DVD的码率大小相接近,达18 Mbit/s。解码速度指标用每秒能够解码的帧数来衡量。测试结果如表1和表2所示。

表1 DXVA与软解码1路720p视频的CPU占用率对比
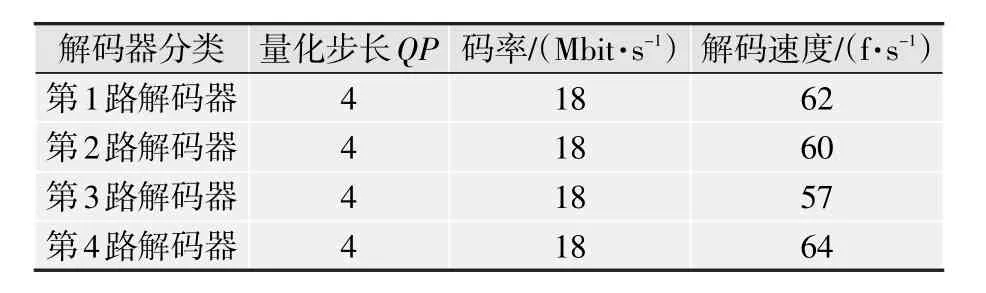
表2 4路720p视频解码的速度
由表1和表2中可以看出,当在播放高清视频时打开DXVA功能时可以大大降低CPU的占用率,解码速度提升4倍左右。完全可以胜任同时解码4路720p的视频,此时CPU的占用率约为40%,仅和CPU解码一路视频时的CPU占用率相当。当把显卡更换为当前市面上主流的中端显卡GT440时,多路解码器可以同时开启12路高清解码,是GF9500解码能力的3倍,而且画面流畅。
4 小结
随着高清时代的到来,用户对于视频的清晰度有了更高的要求,而高的清晰度意味着对解码器的解码速度也提出了更高的要求。本文设计的基于GPU解码器利用DXVA接口和GPU实现了多路高清视频H.264解码,大大提高了解码速度,在实际应用中获得了很好的解码效果。
[1]孙立,王健,郭春辉,等.基于CUDA的H.264去方块滤波的设计和实现[J].电视技术,2010,34(5):44-46.
[2]DirectX video acceleration specification for H.264/AVC decoding[EB/OL].[2010-12-10].http://download.microsoft.com/download/5/f/c/5fc4ec5c-bd8c-4624-8034-319c1bab7671/DXVA_H264.pdf.
[3]毕厚杰.新一代视频压缩编码标准[M].2版.北京:人民邮电出版社,2009.
[4]H.264/MPEG-4 Part 10 white paper[EB/OL].[2010-12-10].http://www.vcodex.com.
[5]Joint Video Team(JVT)of ISO/IEC MPEG and ITU-T VCEG.H.264 ISO/IEC 14496-10 AVC,Document JVT-G050[EB/OL].[2010-12-10].http://wftp3.itu.int/av-arch/jvt-site/2005_07_Poznan/JVT-P050.doc.
[6]朱秀昌,刘峰,胡栋.数字图像处理与图像通信[M].2版.北京:北京邮电大学出版社,2008.
[7]张帆,史彩成.Windows驱动开发技术详解[M].北京:电子工业出版社,2008.
[8]李本斋,吴从中,陈家银.H.264运动估计硬件加速器的设计[J].电视技术,2010,34(S1):79-81.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
视听(2021年8期)2021-08-12
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
沈阳工业大学学报(2018年1期)2018-01-08
项目管理技术(2015年3期)2015-04-23
时代人物(2014年10期)2015-01-28
电子技术与软件工程(2014年20期)2014-11-19
电视技术(2014年19期)2014-03-11
