
一种基于模糊聚类的矢量量化码书生成算法
2011-05-10 09:30:20于凤萍韩笑青
天津大学学报(自然科学与工程技术版) 2011年2期
张 涛,于凤萍,张 海,韩笑青
(天津大学电子信息工程学院,天津 300072)
量化是模拟信号转化为数字信号的必要环节,也是现代语音和音频编码中的一项关键技术.而在量化技术中,又可分为标量量化和矢量量化[1]两大类.由于矢量量化能够有效地利用矢量中各个分量间的关联性降低数据中的冗余度,因此,被广泛应用于要求高质量、高编码效率的数字语音频编码领域.
在矢量量化中,码书的设计至关重要,码书的质量对整个语音频编解码系统的编码效率和恢复信号的质量有着决定性的作用.LBG算法 1980年由Linde等[2]提出,是经典的码书设计算法之一,其本身是一种迭代算法.近些年来,以成对最近邻(pariwise nearest neighbor,PNN)算法和渐进构造聚类(progressive constructive clustering,PCC)算法为代表的一些非迭代的码书生成算法也得到了迅猛的发展.此外,各种基于数学的方法,比如基于神经网络的码书设计方法[3]、基于主分量分析的码书设计方法[4]和模拟退火码书设计算法[5]等也得到了很大的发展.但是由于LBG算法简单实用,而且基于LBG算法的稍许改进也能有效提升矢量量化的性能,因此,很多学者致力于 LBG算法的改进与优化[6-7],通过提升初始码书的性能而提高最终码书的质量,改进后的算法失真度降低,恢复数据的效果更好.
需指出的是,对于基于初始码书生成矢量量化码书的算法,初始码书选取是生成码书性能好坏的关键,不合理的初始码书更有可能使生成的码书陷入局部最优,且会导致迭代次数增大而降低码书生成速度.文献[8]中详细分析了 LBG算法对初始码书的敏感度;文献[9]采用模糊聚类的算法优化了初始码书的设计,并在图像编码领域取得了令人满意的结果.
笔者以非迭代算法的基本思想为基础,采用模糊聚类对典型的非迭代算法 PCC进行改进.为了获得更具典型性的码书,根据矢量空间的密度有效地使初始码本的矢量在矢量空间中散开,并在稠密区域占据更多的码矢,以更精确地划分胞腔.与传统的 LBG算法相结合能够减少迭代次数,加快收敛速度,并使最后生成的码书更接近全局最优.
1 经典的矢量量化码书生成算法
1.1 LBG算法
最经典的矢量量化码书设计方法是 LBG算法,它是对 Lloyd-Max标量量化的多维推广.LBG算法基于最近邻域准则和质心条件2条优化准则.对于1个训练序列,首先生成 1个初始码书,按照最近邻域准则把训练序列按码书中的元素分组,找出每组的质心,得到新的码书,将其作为新的初始码书;重复上述过程,直到平均失真度小于预定的阈值为止.
最常用的初始码书生成方法是随机法,也称为训练矢量集随机抽取法.该方法的主要缺点有:①训练矢量集随机抽取法可能会选取到非典型的矢量作为码矢,根据最近邻域准则该胞腔只有很少矢量,而每次迭代中这些非典型矢量或非典型矢量的质心又都被保留下来;②会造成空间的胞腔分配不均,有些分得过细,有些分得太粗.这样都会导致码书中的部分码矢无法得到充分利用,从而影响码书性能以及整个LBG算法的收敛速度.
文献[10]介绍了一种基于迭代思想生成初始码书的方法——分裂法.首先计算整个训练序列的形心Y,并把它作为码书的第一个码字 Y0.然后选择扰动矢量 Delta,以{Y0-Delta,Y0+Delta}为初始码书,利用LBG算法,设计仅有2个码字的码书,并以新分裂形成的2个码字分别进行扰动,经再次分裂形成4个码字.迭代进行,直到得到所需大小的码书为止.分裂法可以得到比随机法性能更好的初始码书,但是分裂法的计算量是呈指数式增长的,而且,关于如何选取最佳的扰动矢量目前尚没有确切的理论依据,因此,无法稳定地生成高性能的初始码书.
1.2 非迭代码书生成算法
近年来,又出现了一些非迭代的码书生成算法.典型的非迭代算法有PNN算法和PCC算法.PNN算法[11]是一种删除算法,它不断地把最相近的2个腔胞合并起来,直到得到所需数目的腔胞;PCC算法[12]的特点在于仅对训练序列进行1次扫描,渐进地生成码字.该算法首先以训练序列中第 1个矢量作为码书,将每个输入矢量映射到1个最近相邻的码字中,若其失真距离大于预先设置的阈值,并且码书中的码字还不够,则该矢量被确定为新的码字,否则与该矢量最近相邻的码字将被合并到最近的聚类中,计算合并后聚类的形心,将其作为调整后的码字,重复上述操作,直至扫描完整个训练序列.
只使用 LBG算法,或仅仅使用非迭代算法生成的码书质量都不理想.虽然 LBG算法具有坚实的理论基础,且实施过程简便实用,但是该算法对初始码书非常敏感,虽然能够收敛,但容易陷入局部最优,从而导致码书有“优”、“劣”之分;而非迭代算法尽管能够保证较快的收敛速度,但是其关键的阈值的选取方法又是一个因没有理论指导而很难解决的问题.改进算法的思想在第2.1节中描述.
2 基于模糊聚类的码书生成算法
2.1 算法的基本思想
文献[12]中通过自适应调整保护区阈值的上下限,对PCC算法进行改进.新的码书生成算法基于传统的 LBG算法,通过优化码书来提高码书质量.优化的码书生成算法基于模糊聚类的思想将迭代算法(LBG算法)与非迭代算法(PCC算法)相结合以提高矢量量化的性能.
从迭代算法的角度来看,新算法通过训练矢量和聚类矢量之间距离门限的迭代使得初始码书的码字在矢量空间中按照概率密度很好地散开,并进一步利用 LBG算法迭代生成最终的码书,新算法的距离门限逐级迭代也有助于防止此后的LBG算法陷入局部最优,使得设计出的码书更加接近全局最优.
从非迭代算法的角度来看,新算法是对 PCC算法的改进,通过对循环逐级递减的方式调整距离门限,不仅提高迭代的收敛速度,而且可以防止新聚类生成得太快,从而更可能得到更多有代表性的码字.
另外,为了使生成的码字在矢量空间中尽可能地分散开,以占据概率密度较大的区域,从而保证获得的码字更具代表性,最后选取码字时,新算法采用了择优选取的方法:当聚类矢量集中的矢量数量大于原定的码书尺寸时,按照胞腔中矢量个数从大到小的顺序进行排序,选择所需个数最大的那些腔胞作为码字;当聚类矢量集中的矢量数量小于原定的码书尺寸时,则先将矢量集中的矢量全部选作码字,然后再调整门限,进行下一次 PCC迭代,生成新的码字,直至码字的数量达到要求为止.
2.2 优化的矢量量化码书生成算法
图1为优化的初始码书生成算法的主要步骤,其中 delta为空间划分距离门限;siz_book为待设计的码书大小;siz_count为当前生成的矢量量化码字个数计数器;siz_plus为码字增量计数器.

图1 优化的矢量量化码书生成算法流程Fig.1 Flow chart of a novel algorithm of vector quantizetion codebook
本算法的计算过程是一个迭代的过程.

(2) PCC迭代,即先把第1个矢量放入码书作为第 1个码字,随后遍历所有矢量,凡是距码书中每个矢量距离都大于门限delta的就作为新的码字写入码书,反之进行聚类;
(3) 如果当前码字siz_count加上此次循环带来的码字增量siz_plus超出设计所需的码书大小siz_book,则将聚类矢量按照胞腔内矢量的个数由大到小排序,取前siz_book-siz_count个聚类矢量作为新码字写入码书,生成所需码字个数的码书,并尽可能地占据矢量空间密集的区域,算法结束;否则,如果当前码字siz_count加上此次循环带来的码字增量siz_plus小于所需的码书大小siz_book,即尚未生成所需个数的码字,那么将 siz_plus个聚类矢量作为新码字写入码书,siz_count+=siz_plus.调整距离门限delta,转步骤(2).
3 新的码书生成算法在移动语音频编码中的应用
近几年,3G无线网络迅速发展,手机、PDA等移动通信设备普及率越来越高,移动语音频业务的种类、数量均日益增多.因此以 ITU的移动语音频编码标准 AMR WB+[13]为参考,中国国家音视频编码标准(Audio Video Coding Standard,AVS)工作组从2005年开始制定相应的语音频编码标准,被称为AVS-M音频,即AVS第10部分[14].
在AMR WB+和AVS-M语音频编码标准中都采用了一种基于交错分组和帧内预测的线谱频率系数矢量量化技术,其中用了 5个矢量量化码书:cb_lsf_1_3_5[1,024][3],cb_lsf_7_9_11[512][3],cb_lsf_13_15_2[512][3],cb_lsf_4_6_8[512][3],cb_lsf_10_12_14_16[512][3].
用本训练方法,对每16个线谱频率(linear spectrum frequency,LSF)构成一个矢量进行矢量量化.训练序列选用25,min、单声道、16,kHz采样频率的测试序列,共产生131-072个LSF矢量的训练集.
3.1 算法效率分析
新的初始码书生成算法与采用均匀抽取初始码书生成算法的LBG迭代次数和信噪比对比结果如表1、图2和图3所示.可见在码书大小为512和1,024的情况下,本算法相比均匀抽取初始码书生成算法信噪比分别提高2,dB和4,dB,而迭代次数分别降低为5/17和2/3.

表1 算法迭代次数Tab.1 Iteration times of algorithm

图2 码书为512时新旧初始码书方法对比Fig.2 Comparison between new and old methods when codesize is 512
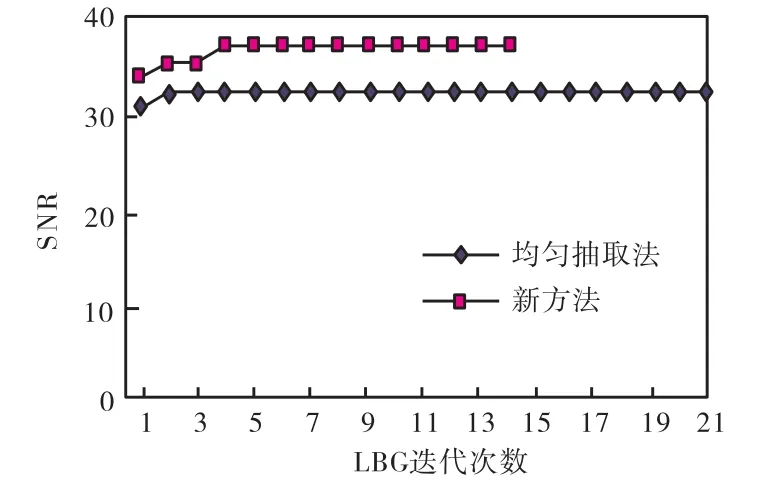
图3 码书为1 024时新旧初始码书方法对比Fig.3 Comparison between new and old methods when codesize is 1 024
采用新算法训练得到的码书与标准中的原有码书对比的主客观实验结果如下所述.
3.2 客观测试结果
目前所用的客观评价方法可以分为时域客观评价和频域客观评价.时域客观评价常见的方法如信噪比,很难与人感知到的声音质量相匹配,因此在语音和音频客观质量评价中普遍采用频域评价方法,如谱失真[15]测度.此外,ITU-T P.862建议书提供的以客观方法评价语音主观质量的方法,被称为感知质量评价(perceptual evaluation of speech quality,PESQ)[16],普遍用于编解码或系统评估、选择和优化.
在12,kb/s码率下,对AVS音频组规定的双声道16,kHz采样的20个语音频测试序列的客观测试的结果如下.
3.2.1谱失真
表 2为谱失真测试结果.新码本平均谱失真减小 0.122,2~4,dB减少 3.49%,大于 4,dB的概率几乎为零,可见谱失真有较大改善.

表2 新算法训练的码本与AVS-M码本及AMR WB+谱失真比较Tab.2 Comparison of spectrum distortion among codebooks of new algorithm,AVS-M and AMR WB+
3.2.2ITU的PESQ语音质量评测结果
图4为PESQ测试结果,平均PESQ有0.028,75的提升.

图4 PESQ语音质量评测结果Fig.4 PESQ result
3.3 主观测试结果
主观评价是在一组测试者对原始语音和处理后语音进行对比测试的基础上,根据某种预先约定的尺度来对失真语音划分质量等级.主观评价符合人类听音时对语音质量的感觉,因而得到了广泛应用.
对在 24,kb/s码率下对 AVS音频组规定的双声道 16,kHz采样的 20个语音频测试序列,按照 AVS音频组制定的语音频编码标准主观测试规范[17],随机选取 10名正常听音者的主观测试结果如图 5所示.采用新码本编解码后语音频的主观质量比原码本的CMOS分值平均高0.005.

图5 编解码后音频的主观质量比较Fig.5 Comparison of objective quality between new and old Fig.5 methods
4 结 语
本文提出了一种基于模糊聚类的新的矢量量化码书生成算法,通过逐级调整门限以减少迭代次数,降低新聚类生成的速度,从而得到更好的更具典型性的码书.此外,通过对胞腔中矢量按从大到小的顺序择优选取,使得设计出的码书性能更好,更加接近全局最优.
本算法应用于数字语音频编码的实验结果表明,该算法在保证语音频编码质量(信噪比)的前提下能够有效提高码书生成速度(迭代次数);在给定编码码率的情况下,语音频编码主客观质量与现有相关语音频编码标准相比均有一定的提高.本算法可以广泛应用于数字图像和数字音视频编码中的矢量量化.
[1]Vasuki A,Vanathi P T. A review of vector quantization techniques [J]. IEEE Potentials,2006,25(4):39-47.
[2]Linde Y,Buzo A,Gray R. An algorithm for vector quantizer design[J].IEEE Transactions on Communications,1980,28(1):84-95.
[3]Krishnamarthy A,Ahalt S,Melton E,et al. Neural networks for vector quantization of speech and images[J].Neural Networks,1990,3(3):277-290.
[4]Chang C,Lin D,Chen T. An improved VQ codebook search algorithm using principal component analysis[J].Journal of Visual Communication and Image Representation,1997,8(1):27-37.
[5]Fabian V. Simulated annealing simulated[J].Computers Math Application,1997,33(1/2):81-94.
[6]Franti P,Kaukoranta T,Shen D-F. Fast and memory efficient implementation of the exact PNN[J].IEEE Transactions on Image Processing,2000,9(5):773-777.
[7]吴婷婷,曾毓敏,李 平. 利用PNN算法改进初始码书的GLA 算法[J]. 数据采集与处理,2007,22(2):242-244.
Wu Tingting,Zeng Yumin,Li Ping. GLA algorithm for ameliorated original codebook using PNN algorithm[J].Journal of Data Acquisition and Processing,2007,22(2):242-244(in Chinese).
[8]王茂芝,徐文皙. LBG算法对初始码书敏感的实验性能分析[J]. 物探化探计算技术,2004,26(4):374-378.
Wang Maozhi,Xu Wenxi. Experiment performance analysis on sensitivity to initial codebook of LBG[J].Computing Techniques for Geophysical and Geochemical Exploration,2004,26(4):374-378(in Chinese).
[9]张 涛,于凤萍,要 强,等. 高效的模糊聚类初始码书生成算法[J]. 红外与激光工程,2010,39(1):179-183.
Zhang Tao,Yu Fengping,Yao Qiang,et al. Novel and efficient generation algorithm of initial codebook based on the fuzzy clustering theory[J]. Infrared and Laser Engineering,2010,39(1):179-183(in Chinese).
[10]George L,Al-Abudi B. Fast multi-level image vector quantization[C]//Proceedings of IEEE International Conference on Signal Processing and Communications.Dubai,United Arab Emirates, 2007:121-124.
[11]韩俊萍,程培岩. 模糊聚类法实现初始码书的优化[J].科技情报开发与经济,2006,16(11):157-158,161.
Han Junping,Cheng Peiyan. Realize the optimization of the initial codebook by using the fuzzy clustering method[J].Sci-Tech Information Development and Economy,2006,16(11):157-158,161(in Chinese).
[12]张 一,成礼智. 结合改进的PCC算法与LBG算法的高效码书设计[J]. 系统工程与电子技术,2006,28(3):470-473.
Zhang Yi,Cheng Lizhi. Efficient algorithm for codebook design based on improved PCC algorithm and improved LBG algorithm[J].System Engineering and Electronics,2006,28(3):470-473(in Chinese).
[13]3GPP. TS 26. 290 Extended Adaptive Multi-Rate-Wideband(AMR-WB+),Codec;Transcoding Functions(Release 6)[S]. France:3GPP,2006.
[14]AVS. AVS-P10 Mobile Speech and Audio Coding Standard[S]. China:AVS,2009.
[15]Norden F,Eriksson T. A speech spectrum distortion measure with interframe memory[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing. Salt Lake,USA,2001:717-720.
[16]International Telecommunication Union. ITU-T P. 826 An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Coder[S]. USA:ITU,2007.
[17]AVS. AVS音频内部主管听力测试参考规范[S]. 中国:AVS,2005.
AVS. Reference Rules for AVS Audio Objective Quality Evaluation[S]. China:AVS,2005(in Chinese).
猜你喜欢
汽车实用技术(2022年4期)2022-03-07 06:02:26
中国西部(2021年4期)2021-11-04 08:57:32
中学生数理化·高一版(2021年11期)2021-09-05 12:21:24
华东师范大学学报(自然科学版)(2020年1期)2020-03-16 03:14:55
扬子江诗刊(2018年1期)2018-11-13 12:23:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
现代防御技术(2016年1期)2016-06-01 12:13:28
新高考·高一物理(2016年1期)2016-03-05 22:47:39
湖湘论坛(2015年3期)2015-12-01 04:20:17
