
模式矩阵的FP-DMMFI并行算法在教师科研素养挖掘中的应用
2011-03-14 06:44徐儒
网络安全技术与应用 2011年7期
徐儒
长江师范学院数学与计算机学院 重庆 408000
0 引言
数据挖掘(DataMining)是为了解决“数据丰富,知识贫乏”状况应运而生的,是从海量数据中获取知识的可靠技术。将数据挖掘中的关联规则分析方法应用于教师科研素养分析,能发现影响教师素养各因子之间的相关性。通过收集、加工和处理教师的科研信息统计表,分析特定群体或个体的知识结构、年龄阶段、兴趣爱好等,从而确定出教师群体或个体的科研习惯、科研特征,科研倾向和兴趣偏好,进而对相应群体或个体的未来发展趋势做出判断,找出影响科研素养各因子之间隐藏的内在关联。
1 模式矩阵的并行频繁项集挖掘算法:FP-DMMFI
虽然FP-growth与Appriori算法相比,极大地提高了挖掘的效能,但在构造一颗新的 FP-tree时需要扫描两次数据库;当事务数据库中有新数据加入时,原来发现的频繁项集可能不再是频繁的,这时,每重新建立一次FP-tree都要同时把新旧数据扫描两次;同时,当支持度阈值发生变化时,需要重新建立FP-tree,这种情况数据的规模越大,开销就越大。针对以上存在的不足,本文提出了一种基于模式矩阵的并行频繁项集挖掘算法 - FP-DMMFI(frequent pattern array for distribution mining maximal frequent itemsets)算法。
1.1 FP-DMMFI算法
FP-DMMFI算法主要将挖掘数据映射成矩阵后通过并行处理的方式来完成频繁项集的挖掘工作。基本思路是:采取分治策略,首先将提供频繁项的数据库压缩到矩阵T中,但仍然保留项集关联信息,同时获取频繁项的支持度计数的向量ω,由矩阵T和ω生产模式矩阵P,然后并行完成频繁项集的挖掘工作。
FP-DMMFI通过一次扫描数据库将事务和项集关联信息映射成矩阵,之后无需再做扫描数据库的操作,直接通过矩阵运算就可以挖掘出频繁项集。并行FP-array模式矩阵算法的挖掘过程主要包含三个步骤,分别是构造模式矩阵、FPMax最大频繁模式挖掘和生成关联规则。
1.2 构造FP-array
定义1:向量ω表示数据库D中各项的支持度计数。ω =[ω1,ω2,…ωn]。ωi表示第i个项在D中的支持度计数。
定义2:T[n][m]表示与D一一对应的映射矩阵,T[i]表示与D相对应的第i个事务,Tij表示第j个项在第i次事务中的出现与否,如出现则xij=1,否则xij=0(即xij∈{0,1},i≤n,j≤m)。
扫描数据库,获取数据库的事务数和项数。假设D中含有m个事务,所有事务共涉及n个项,则需要构造一个n行 m列的矩阵T[n][m]。此时,称ω的转置向量ω-1和矩阵T组成的矩阵为模式矩阵P。
1.3 FP-Max挖掘
P压缩写入了D中内容,对于任何频繁项目集X,其频繁项目已经映射到P矩阵里。因此,可以将求解频繁项集的问题,转换为递归发现矩阵最长频繁模式的问题。
通过模式矩阵 P,获得支持频度大于最小支持频度的模式矩阵P1,P1表示为1-项模式矩阵。对P1中行元素进行笛卡尔关系与操作,生成2-项模式矩阵P2,剪枝掉P2中支持频度小于最小支持频度的所在行,确定出模式矩阵P2。依次循环,由项模式Pn依次推出并产生矩阵Pn+1,直到Pn+1=Ф时停止,挖掘最大频繁项集模式矩阵的操作结束,则Pn即为最大频繁模式矩阵。挖掘过程为:
(1) 连接:将模式矩阵 Pn-1中的行与其余各行进行笛卡尔与操作,得到n-项矩阵T;
(2) 生成模式矩阵:计算n-项矩阵T对应的ω向量,将ω-1和n-项矩阵T组成模式矩阵Pn;
(3) 剪枝:删除模式矩阵Pn中支持度小于最小支持频度的所在行。
设计代码为:
算法:并行模式矩阵挖掘 D中最大频繁项目集算法(FP-DMMFI)
输入:事务数据库D的映射矩阵T,最小支持度阈值s
输出:事务数据库D的最大频繁项目集MFSD
方法:
(1) 将数据库D压缩到矩阵T中;
(2) MFSD=Φ;//初始化最大频繁项目集合;
(3) 获取T中各对应列的项的支持度计数ω,生产模式矩阵P;
(4) If ( P[i]中的ωi< s)then //剪枝小于最小支持度的项;
(5) Delete P[i];//删除该行记录;
(6) 更新P;
(7) If (P≠Φ) then;
(8) MFSD= P;
(9) P各项集进行笛卡尔与运算//挖掘最大频繁项集;
(10) 跳转到第(2)步;
(11) End;
(12) 输出MFSD。
2 挖掘教师科研素养中的关联
2.1 数据整理
我们以某高校统计的教师科研信息作为实例分析。数据来源于某年度所有教师的科研统计,有效时间段为:从1月1日起至12月30日止,共有3000余条数据记录,分别记录了每位教师在规定时间内,全部论文、著作、课题和获奖四个方面的科研情况和其它相关信息。如表1所示是事务数据表中的部分字段和记录。
由于本次是对教学科研人员的科研素养进行研究,因此,最能够体现科研的能力特征主要应表现在论文、著作、课题和获奖这四个方面。提取最主要反映科研的能力特征的四个特征属性值,分别对各特征属性值进行归约化操作。其中将“论文”归约为三大检索期刊(SCI、EI、ISTP)、中文核心和普通期刊三类,且仅以排名第一作者为有效;“著作”归约为专著和教材两类,作者排名以主编、副主编和前三位参编有效;“课题”归约为国家级、省市级和区县级三类,国家级课题作者排名前五位为有效,省市级课题作者排名前三位为有效,区县级作者排名第一为有效;”获奖” 归约为国家级、省市级和区县级三类,作者的有效排名与“课题”规定相一致。省略其它信息,对事务数据进行特征提取、归约整理。
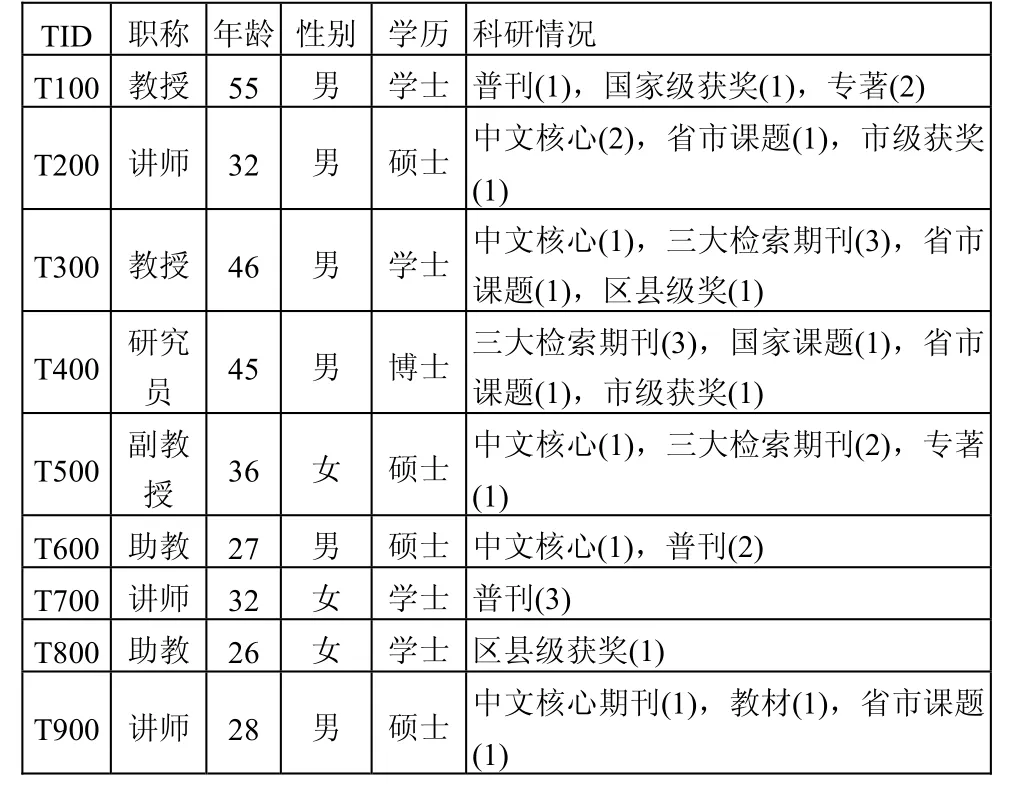
表1 事务数据表中的部分字段和记录
显然,表1中的原始数据不能够直接进行数据挖掘。为了能够真实地反映某一群体或个体的科研素养情况,便于准确的进行知识特征提取和挖掘数据关联,我们以主要影响科研素养的职称、年龄和学历三个方面(表 2所示),作为挖掘科研素养数据的判定因子,对原始数据库中的论文、著作、课题和获奖的字段信息,进行离散化操作,并按照论文、著作、课题和获奖的顺序,依次用I12,I13,…,I22分别表示。离散后的判定因子和事务数据,如表3所示。
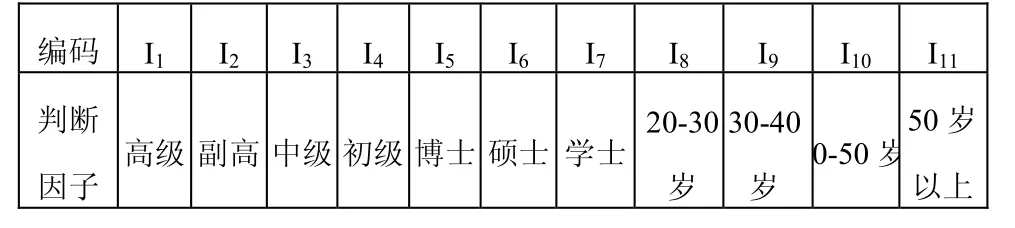
表2 影响因子的映射
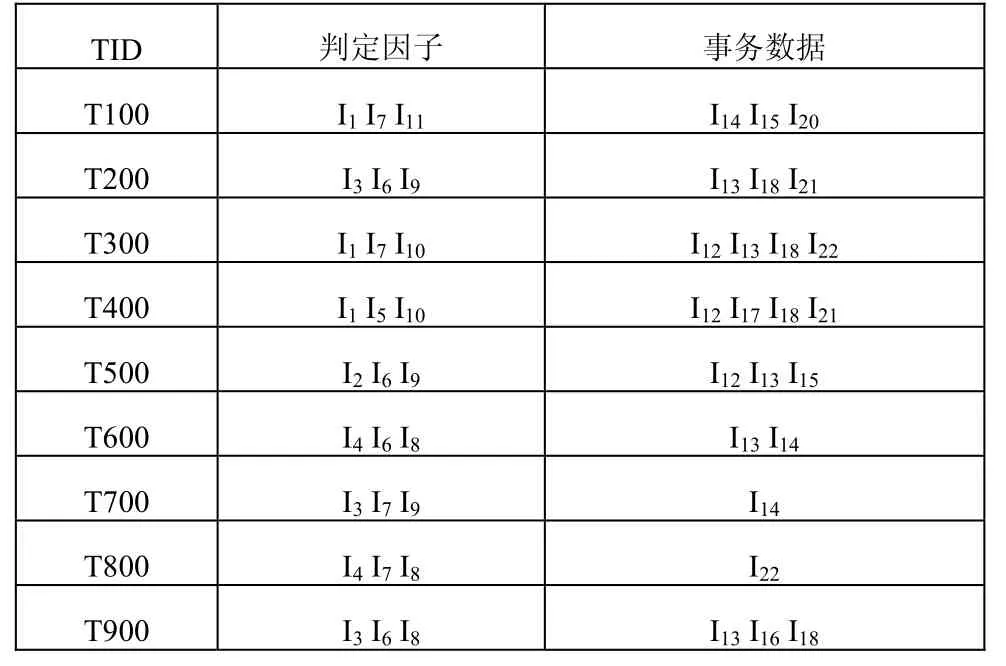
表3 离散后的数据
2.2 构造模式矩阵
将数据进行归约和离散化操作后,就可以构造模式矩阵了。由于影响科研素养的判定因子不止一个,可以对各影响因子构造不同的FP-array矩阵,进行分别判断,也可以将各影响因子统一构造FP-array矩阵综合判断,所以,我们采用统一构造FP-array矩阵的方式,并行完成频繁项集的挖掘工作。假设最小支持度阈值为 2,剪枝掉数据库中小于最小支持度阈值的事务记录,将提供频繁项的数据库压缩到矩阵T中,构造一个m行n列的FP-array矩阵M1,并保留项集关联信息。这里,我们采用了0-1矩阵的存储形式,即矩阵值为0时表示与之对应的元素为假,矩阵值为1时表示与之对应的元素为真。矩阵中的每列代表的是剪枝后存储的一条或者多条记录。从而,构造与数据库保持一致的FP-array模式矩阵P (如图1所示)。

图1 FP-array模式矩阵
2.3 挖掘最大频繁项集
通过并行求解模式矩阵 P,挖掘最大频繁项集。挖掘结果为:
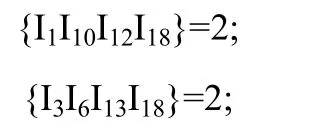
2.4 关联规则生成
根据最大频繁模式的挖掘结果,得到两条4-项频繁项集。从数据库D中挖掘出所有的频繁项集,就可以很容易地获得相应的关联规则。通过项集支持频度计算公式获得关联规则的信任度。则由最大频繁项集产生的部分关联规则如表4所示。
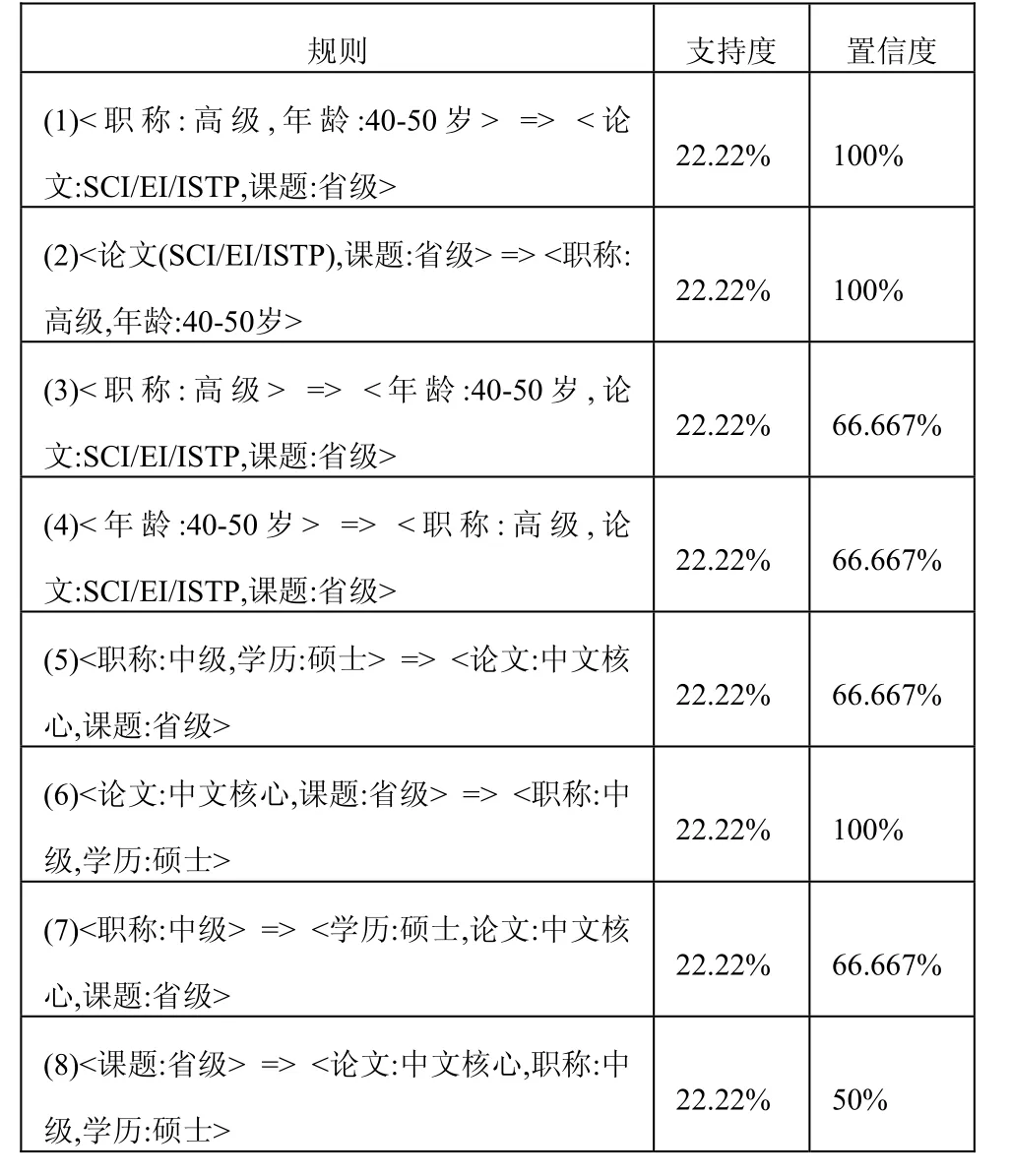
表4 关联规则
如果设最小置信度阈值为60%,则规则(1)~(7)被保留,规则(8)被删除;如果设最小置信度阈值为70%,那么仅有规则(1)、(2)和(6),由于信任度大于最小置信度阈值而被保留下来。
同理,由3-频繁项集产生的部分强关联规则有:
(9) Conf(<职称:高级,年龄:40-50 岁> => <论文:SCI/EI/ISTP>) = 100%
(10) Conf(<职称:高级,年龄:40-50岁> => <课题:省级>) = 100%
(11) Conf(<职称:中级,学历:硕士>=> <论文:中文核心>) = 100%
(12) Conf(<职称:中级,学历:硕士>=> <课题:省级>) = 100%
2.5 结果分析
从关联规则的支持度和信任度中可以看出:年龄在 40到 50岁之间、职称结构为高级的教师群体,偏好于在SCI/EI/ISTP刊源的高质量学术期刊上发表专业文章,同时申请获得省部级以上的科研项目的机率较大。高级别职称的教师群体通常作为高校各学科领域的带头人,在教学和科研方面起着领头羊的作用。经过关联规则的信任度和支持度可得,高级别职称的科研素养还是比较高。最高学历为硕士研究生、职称结构为中级的教师群体,普遍选择将文章发表在中文核心期刊要目总览的期刊上,同时也是申请省部级以上科研项目并获得审批的主要群体之一。中级别职称的教师群体作为学校的中坚力量和第二人才梯队,有66.667%的老师具有硕士学位、发表过中文核心期刊论文和主持过省部级课题,由此可以看出,中级职称的科研素养情况处于中等偏上水平的。值得一提的是,通过对教师科研素养的数据挖掘,初级职称和副高级职称这两个职称系列,由于没有特别明显的科研成果,表现出科研素养不高的情况。值得我们思考和反省。
3 小结
通过对高校教师科研现状的分析,归约出了主要影响科研素养的判定因子,并用模式矩阵算法,挖掘其隐藏信息和内在关联。挖掘过程中,在分析Apriori和FP-tree算法的基础上,提出了并行挖掘最大频繁项集的FP-DMMFI算法。算法整个过程只需完整的扫描一次数据库,将所有信息压缩映射到矩阵中,对矩阵进行并行处理,就能够完成频繁项集的挖掘工作。FP-DMMFI算法应用于教师科学素养的数据挖掘中,挖掘结果能够很好的为决策者提供决策参考。
[1]宋余庆,朱玉全.基于FP—tree的最大频繁项目集挖掘及更新算法[J].软件学报.2003.
[2]秦亮曦,苏永秀,刘永彬等.基于压缩 FP-树和数组技术的频繁模式挖掘算法[J].计算机研究与发展.2008.
[3]刘鹏,孙莉,赵洁等.数据挖掘技术在高校人力资源管理中的应用研究[J].计算机工程与应用.2008.
[4]Han J Kamber.范明,孟小峰.数据挖掘:概念与技术[M].北京:机械工业出版社.2001.
[5]邓丰义,刘震宇.基于模式矩阵的FP-growth改进算法[J].厦门大学学报.2005.
[6]朱明.数据挖掘[M].中国科学技术大学出版社.2002.
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
今日农业(2020年17期)2020-12-15
当代陕西(2019年15期)2019-09-02
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
大连理工大学学报(2017年5期)2017-09-20
读者(2017年5期)2017-02-15
公民与法治(2016年4期)2016-05-17
草地(2014年1期)2014-12-09
中国卫生(2014年1期)2014-11-12
