
一种反射内存网航电软件测试环境实时通讯协议
2011-03-12 14:05:04王立泽周礼亮
哈尔滨工业大学学报 2011年3期
王立泽,刘 斌,周礼亮
(北京航空航天大学工程系统工程系,100191北京,wanglize@dse.buaa.edu.cn)
在国内外航空航天等领域,仿真测试环境多采用Hardware-In-Loop(HIL)方式和分布式结构来分散繁重的计算任务,测试实时嵌入式软件,进而验证软件可靠性[1].而如何保证分布式测试环境各节点间的实时通信则是一个难题[2].
近几年高速网络技术有Fibre Channel(FC)、Gigabit Ethernet(GigE)、反射内存网等,而反射内存网因用硬件实现通信、传输延迟确定、移植性强等优点,成为解决分布式测试环境节点间的实时通信问题的一种行之有效的方法.关于反射内存网的研究主要集中于协议设计[3-8]及理论研究[9-10]两方面.协议设计在功能实现上可分为两类:一类实现了支持一定程度异步、周期通讯模式的通讯协议,但它们都与应用绑定,不能灵活支持系统中不同种类的复杂通信,离开应用,协议需重新实现,缺乏通用性[3-6],如文献[4]为解决周期同步和通信问题进行了设计,协议建立连接后,通讯双方在约定好的位置传输某种确定的数据如同步数据,传输模式不能配置并伴随整个系统运行过程;另一类虽然实现了一定的通用性,但只支持异步通信,缺乏特殊的优先级机制,也不支持周期通讯[7-8].理论研究主要基于一定的计算模型计算实时网络的开销[9-10].通过分析,现有基于反射内存网的相关协议设计,都不能满足本文分布式测试系统的通用通信要求.
本文研究并利用反射内存网络SCRAMNet设计一种能实现周期和异步通讯的、通用性较强的实时通讯协议,并给出了较为完善的系统开销算法,以解决分布式测试环境节点间的实时通信问题.
1 测试环境通讯需求分析
在分布式测试环境中,测试环境结构分为两层:测试开发层和测试执行层[1],见图1.测试执行层存在原子事务、时钟同步、任务同步、通信等问题.原子事务的解决主要靠在各节点设置事务协调者,使之维护本地日志,并负责启动、分派、结束事务的执行,各事务协调者遵循一定协议通信[2,11],如各节点对测试开始、结束的一致响应.其它问题与原子事务类似,靠节点按即定算法周期或异步协作.节点间任何通信都要借助网络完成,通讯类型多,实时性高,且处理上有缓急之分.有的任务如仿真任务随待测系统不同而变化,因此还要求通讯有一定的配置灵活性.这就需要一个专门的实时通信层来适应节点间的通讯要求.
综合以上分析,为解决分布式测试系统的通信问题,需要基于实时网络为实时通信层设计一种通用的实时通讯协议,满足诸多任务的协作、通信.
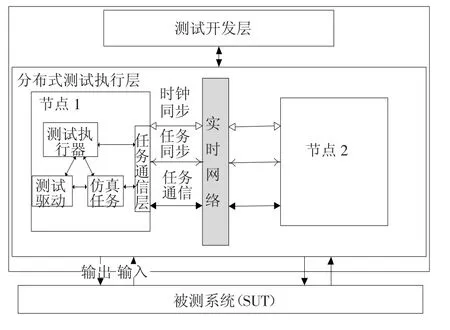
图1 分布嵌入式仿真软件测试环境结构
2 实时通讯协议的设计
2.1 网络原理
反射内存网是实时性要求较高的专用通讯网络,它的工作原理[12]是各实时节点有反射内存卡,主机内存映射到各卡的独立局部内存,局部内存映射到全局网络内存,使各卡逻辑上共用一段地址.各节点将数据写入主机内存同时也写入所有其他各卡内存.全局内存对所有节点都可见,从而实现节点间数据通讯.
2.2 设计思路
经需求分析知,分布式测试系统中既有较多周期通讯,又有灵活异步通讯需求,对异步通讯,不但强调实时性,某些类型消息还应优先处理,如测试指令消息应先于数据消息接收.本文基于SCRAMNet实现了一种支持周期和异步数据传输的协议,异步传输基于消息和优先级机制,周期传输基于数据流机制,称实现为Message-Stream Test Protocol(MSTP).
本协议的设计目的及特点主要有:
1)能够实现测试系统任务间的异步通讯传输原语,发送消息,查询消息,接收消息;
2)允许两任务间异步通讯有一定持久性,即通过合理分配内存,允许发送多条消息,接收与发送顺序一致;
3)允许异步通讯有优先级机制,使某类通信能够被优先处理;
4)能够实现任务间的周期性通讯,且不同的协议配置,传输不同的周期数据.
2.3 内存布局
内存布局解决的问题是如何为MSTP进行内存分配,使协议对用户透明.
根据反射内存网的广播特点,同一内存区不能被多个用户同时写操作,如同时写则必须实现加锁机制,而加锁会增加开销,所以,协议的核心设计思想是为每个进程开辟一块写操作区域,全局只有此进程拥有写操作权,即一块内存区有且只能有1个写操作者.设参加通讯的进程数为proc-num.
为实现上述思路,对内存进行访问控制,将其分为2个区域:数据区和控制区.为实现异步通讯,为每个进程分配各自的数据区和控制区,数据区存放消息,控制区存放各消息对应的控制信息,见图2.为实现任意两进程间的周期通讯,分配1个全局的数据区和1个通讯登记区,见图3.
异步通讯数据区由所属进程管理并执行写操作,当有异步消息发送时,发送进程申请并将消息写入数据区内存,发送后,目的进程只能读取消息.为实现优先级机制,消息数据区按页(page)分配.当优先级不同的消息共存时,高优先级消息先被取走而导致在数据区产生外部内存碎片,为每个消息分配一定数量页面可避免碎片产生.每条消息可分配多页,呈链表结构,每页头部的页指针指向下一页.布局示意见图2.
与消息数据区同属发送进程的控制区划分为3个子区域:消息描述区,已发送标记区(send),响应区(ack).每个进程最多发送某一固定数量的消息,记为msg-num.每个消息对应1个消息描述区,分别表示所属进程的从第1到第msgnum个消息的位置和属性信息,包括首页(firstpage),长度,发送序号,类型,优先级等.首页记录起始页号.长度表示消息字节数.另外,控制区还各含有proc-num-1个send标记和ack标记,每个标记有msg-num个位.每个send标记代表源进程向目的进程发送的消息序列,自左至右的位序号对应了消息序号,代表源进程是否向目的进程发送消息,同理,ack标记则代表消息是否已被目的进程接收.消息描述区、send区、ack区,同消息数据区一样,在协议初始化后,大小位置都固定不变.
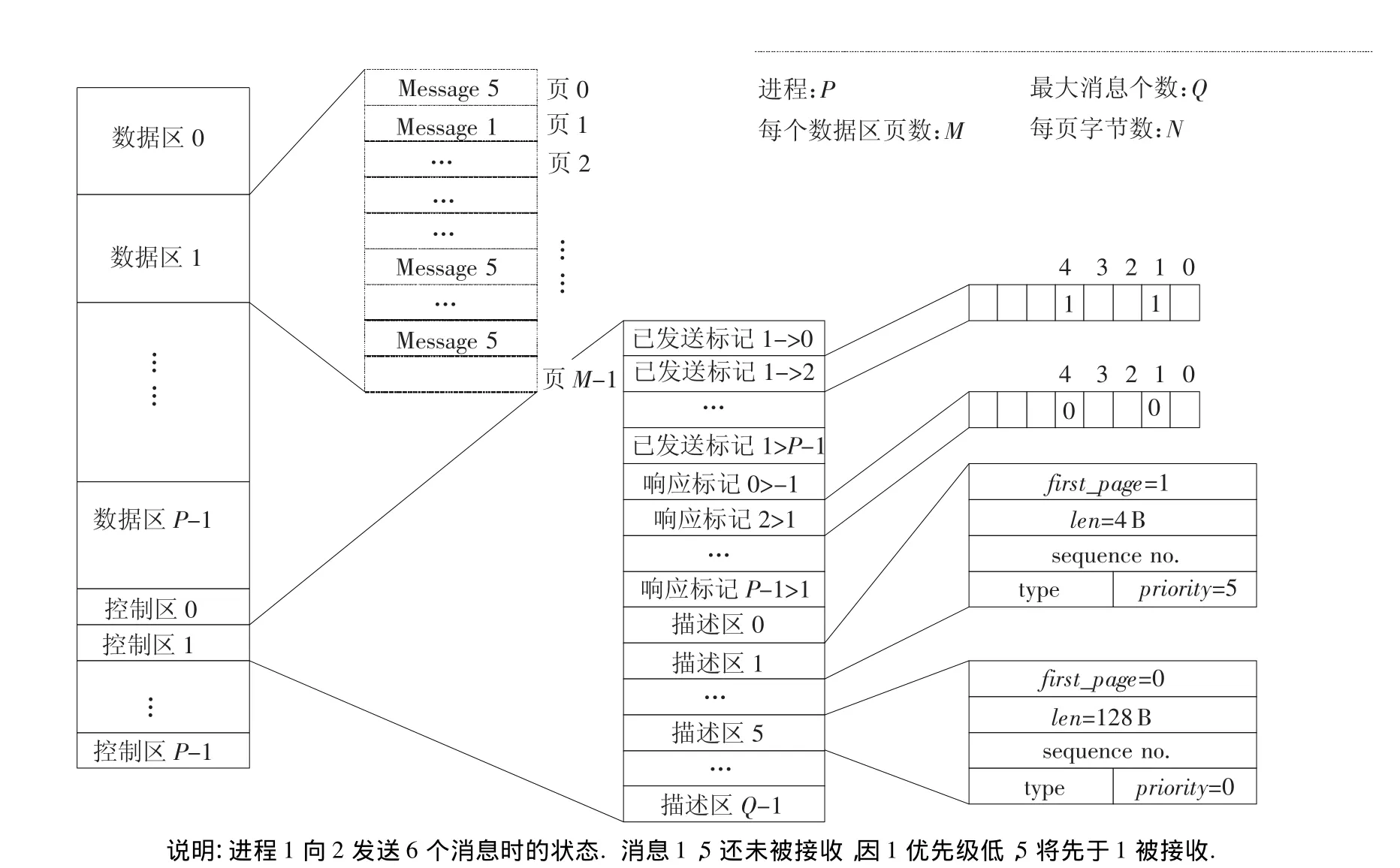
图2 MSTP异步通讯内存布局
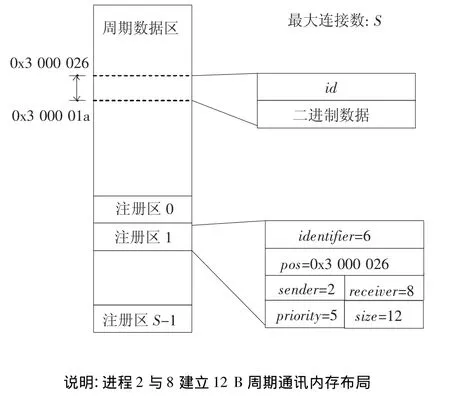
图3 MSTP周期通讯内存布局
2.4 协议描述
协议描述规定了用户如何使用MSTP及其实现的原理.对异步通信,MSTP要求明确所有参与通信的进程数量.每个进程对应1个逻辑地址,即在进程集中的编号.
API定义如下:
1)mstp-asyn-init(int proc-logic,int procnum),异步通讯初始化.参数分别为异步进程逻辑地址和异步进程数.返回指针struct mstp*,以后进程proc-logic将用此指针收发消息.初始化指针包括了进程逻辑地址,消息数据区和控制区地址及通讯状态等信息;
mstp-perd-init(),周期通讯协议初始化;
mstp-perd-regist(int id,struct reg* info),登记1个通讯区,info包括通讯标识、周期等信息.
2)mstp-asyn-send(struct mstp*,char* buf,int len,int dest,short msg-type,short priority);向dest进程发送缓冲区buf内的len字节的数据,msg-type是用户定义的消息类型.默认为最低优先级;
mstp-perd-send(int id,char* buf,int size);写数据流buf到通讯标识id.
3)mstp-asyn-inquiry(struct mstp* this,int source);查询是否有从source发送至this的消息,若有,返回进程逻辑地址,反之 -1;若source为-1,查询是否有从所有任务发送至this的消息.
单轴压缩实验在YAW-2000液压伺服试验机上进行,实验过程采用轴向位移控制方式,加载速率恒定在0.01mm/s,实验前选取20个直径和高度误差均小于±0.05%的标准煤样,分为4组,每组5个煤样。
4)mstp-asyn-recv(struct mstp* this-proc,char* buf,int max-len,int source,short&msgtype);从source接收max-len字节消息至buf.先取得高优先级的消息,同优先级消息按发送顺序取得.
mstp-perd-recv(int id,char* buf);读数据流.
源进程向目的进程发送异步消息时,协议内部动作:1)按消息大小申请空闲内存区,得到1个或多个内存页,根据页号为每页的指针头赋值; 2)将数据拷贝至内存数据区;3)根据目的进程的send标记和ack标记,计算出消息缓冲区号,根据通讯状态得出消息发送序号;4)将新的send标记和消息描述信息写入控制区.发送端协议自动计算消息序号.发送端节点维护其对应控制区信息.
进程接收源进程发来的异步消息时,协议动作:1)根据源进程的send标记和ack标记,得到未接收消息列表;2)读取消息列表相应描述区信息,根据优先级和发送序号,得出应读消息号;3)将消息读出;4)置ack标记.
由于本地内存操作比读写反射内存快,所以协议内部的实现应尽可能减少反射内存读写.可利用状态信息实现.
周期通讯的关键在于通讯登记表的建立.双方经过通讯标识确立通讯关系,协议负责为通讯双方在数据区维护内存资源.在通讯配置建立时,发送方协议通过分布式互斥算法向登记区增加记录,然后通过异步消息通知目的方获取记录项.通讯过程中,为保证实时性能,协议不允许改变登记表.
2.5 协议实现
实现MSTP需确定如下参数:异步通讯进程个数proc-num,每个进程发送最大消息数msgnum,每个进程消息数据区长度data-area-len,消息数据区最小内存单元page-size,最小内存单元指针头 page-head,消息描述区 data-descsize,周期通讯连接数perd-num,登记表项大小reg-size.优先级数、消息类型、周期通讯数据区大小perd-data-size根据应用确定.确定参数后,协议实现异步消息通讯需要的实时网络内存为

实现周期通讯登记表需要的内存为
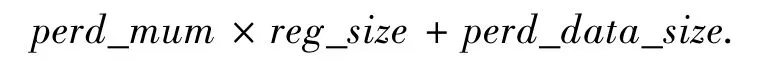
本文在测试环境中实现了MSTP:异步通讯进程数32,每进程数据区1 M,最大消息数64,最小内存单元48 B,指针头4 B,消息描述区16 B,优先级别10级,最高0级.周期通讯最大连接数300,登记表项24 B,数据区2 MB,计算得实际使用实时网络内存35 691 800 B.
协议初始化后,为异步通讯每个进程分配的指针维护了指向数据区和控制区、状态信息数据结构的指针.为避免频繁访问反射内存,状态信息将最近一次操作反射内存的数据缓存至其中,包括消息数据区内存缓存、发送标记、序号、已探测到但还未接收的消息等.发送和接收进程根据send标记和相应ack标记是否相等判断此消息号是否在已发送队列中,若相等,说明其空闲.
2.6 测试
为检验MSTP设计效果,在分布式测试环境下设计了周期和异步通讯性能测试实验.分别位于2个实时节点的多对仿真任务并发运行,对异步和周期通讯,依次对每种负载持续测试1 s以验证是否有丢包或碰撞现象.异步消息优先级为0或5.周期通讯周期为1 ms.测试负载为4 B,64 B,…,16 kB,32 kB.为每种测试负载分配1对异步、周期任务,对比发送与接收的数据以判断通讯正确性.测试设备为 Pentium4 2.8GHz PC机,OS VxWorks5.5,PCI 64 SCRAMNet,示波器.实验数据如图4所示.
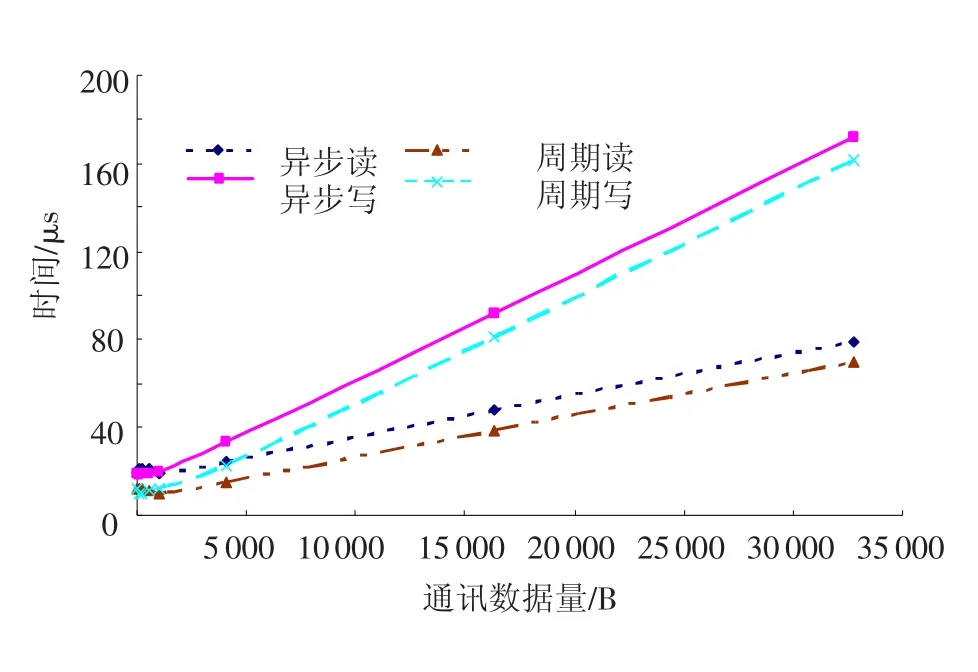
图4 MSTP测试数据
根据实验作以下分析:1)MSTP的异步和周期模式在并发运行、不同数据量、多次测试情况下,无丢包现象,均正常工作,且未知所携带的数据含义,与应用分离;2)文献[4]未给出性能测试数据,但应用系统的周期和异步协议工作在25~40 Hz间;文献[8]使用异步协议实现仿真应用的周期和异步数据传输,测得3节点网络系统的性能约为300 μs/800 B,320 μs/1600 B;文献[5]实现用周期和异步方式传输HLA联邦成员,性能在70 μs~30 ms之间.而本文提出的MSTP,在具备通用性的前提下,从图4实验数据可看出也具有强实时特性,满足大多数应用的实时性要求; 3)异步通讯中优先级高的消息总是先于低的被接收;4)传输延迟大小受数据包大小影响很大,因此要获得强实时性,需尽可能减小每次通讯的数据量.
实验结论:MSTP通用性设计可行,较已有设计有更广适用范围,且实时性强,可靠性高,能够基于其解决分布式测试环境的各种协议实现问题.
3 理论分析
文献[10]采用估算法设计了1个专用于反射内存网络的根据各节点的访问次数开销计算系统总开销的计算模型,本文进一步完善文献[10]中关键量的算法,得到更为精确的系统总开销算式.
文献[10]假设节点i各进程内存区大小未知,且各进程读/写内存次数比率同为β(i),所以在计算总开销时采用估算法,设i所有进程每次读写操作时访问i的全部内存区S(i).而在本文及实际应用中[3-6],文献[10]的假设会带来网络访问开销的增加和效率的降低,相反,节点i的各进程j一般不共享使用S(i),而是使用各自内存s(j),内存相互独立、大小不同,且读 /写次数比率不同,记为β(j),以提高网络内存访问效率.因而该估算法会因缺乏准确性而带来误差,本文综合以上因素,给出更为符合实际的计算模型改进算法.计算原理及关键量的改进算法如下.
规定一个时间段Tlcm,在Tlcm内所有访问反射内存的进程必须至少执行1次,且假定有R个节点,节点i上有j个进程,各进程执行时间τ(j)已知.这样,

式中:c(i)为i节点的内存区访问开销;N(i,j)为平均每个进程j对单位数据的访问次数;S(i)为节点i各进程内进程内存和.各节点内存访问开销和为系统总开销.
根据节点i上各进程的执行时间τ(j)等量,求得i的平均单元数据访问时间Δ(i):
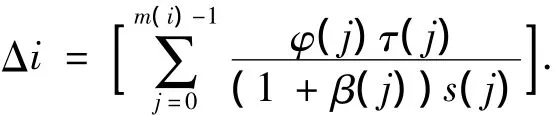
其中φ(j)为进程j在Tlcm内执行次数;τ(j)为j执行时间;s(j)为j内存数量;β(j)为j读/写次数比率.
加入节点i各进程j执行时间权重,计算j在Tlcm间单元数据访问次数N(i,j)为

节点i的单元数据访问次数总开销C(i)为各进程j对单元数据访问开销的平均值,即
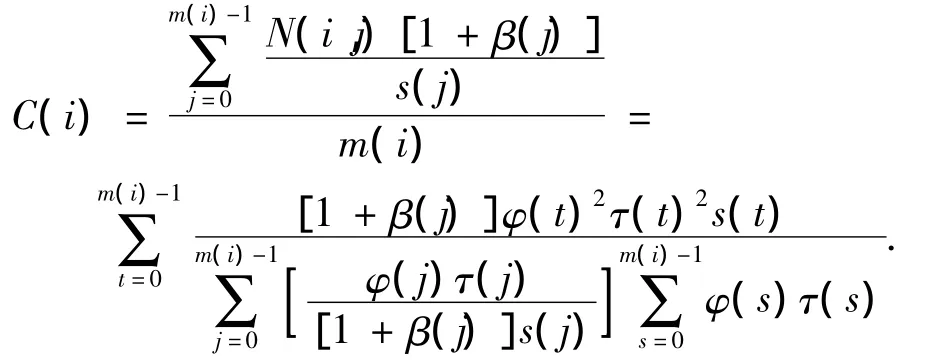
求得C(i)后,将C(i)组成矩阵C,各节点i进程数组成K,各节点进程实际内存分配组成X,则系统总开销 =[KC]TX.
另外,系数矩阵A、X、内存限制矩阵b组成限制条件AX≤b.各矩阵表示如下.


可从统计角度将改进后的系统总访问开销的算式用于判断各节点上各任务的内存分配合理与否的量化评估.可使用MATLAB“LINPROG”等工具对其进行分析,以最小化总访问开销[10].关于计算模型的说明及非关键量的计算参见文献[10].
4 结论
本文设计了一种基于反射内存网的支持异步、周期性数据通讯的实时传输协议MSTP,解决分布式测试环境的复杂通讯问题,较已有设计通用性强.并基于理论计算模型,给出了计算系统开销的更为完善的算法.实验表明本STP能够满足分布式测试平台实时通信、时钟同步、任务同步等需要.体现了较好的通用性、可配置性和集成性,对基于反射内存网的应用协议设计人员具有重要的参考价值.下一步将基于MSTP设计分布式测试平台的相应算法开展工作.
[1]刘斌,高小鹏,陆民燕,等.嵌入式软件可靠性仿真测试系统研究[J].北京航空航天大学学报,2000,26 (4):490-493.
[2]ANDREW S T.分布式系统原理与泛型[M].杨剑锋,译.北京:清华大学出版社,2004:9.
[3]HAVLICSEK S H,ZANA L.Improving real-time communication between host and motion system in a HWIL simulation[C]//Procedings of SPIE.Pittsburgh PA: Acutronic USA,2004:33-43.
[4]TAKAHASHI H.Synchronized data distribution and acquisition system using reflective memory for J-PARC 3GeV RCS[C]//Processings of the 11th European Particle Accelerator Conference.Genoa:[s.n.],2008: TUPPO13.
[5]李海,吴嗣亮.基于HLA和反射内存网的半实物卫星对抗仿真系统[J].系统仿真学报,2008,18(6): 1520-1523.
[6]蒲源,王仕成.多网络半实物实时仿真平台研究[J].系统仿真学报,2008,20(10):2572-2574.
[7]JACUNSKI M G,MOORTHY V.Low latency messagepassing for reflective memory networks[C]//In Proceedings of CANPC.Orlando:[s.n.],1999:211-224.
[8]LAWTON J V,BROSNAN J J.Building a high performance message-passing system for memory chaninel clusters[J].Digital Technical Journal,1996,8(2):96-116.
[9]STOCKINGER H,STOCKINGER K.Towards a cost model for distributed and replicated data stores[C]//In Proceeding of Ninth Euromicro Workshop on Parallel and Distributed Processing.Italy:[s.n.],2001:461-467.
[10]RYOU M S.Optimization of data accesses in reflective memory systems[C]//TENCON 2006,IEEE Region 10 Conference.HongKong:[s.n.],2006:1-4.
[11]ABRAHAM S.操作系统概念[M].第六版.郑扣根,译.北京:高等教育出版社,2005:4.
[12]SCRAMNet G T.A new technology for shared-memory communication in high-throughput networks[EB/OL].[2009].http://www.cwcembedded.com/documents/ contentdocuments/White-Paper-SCRAMNet-GT.pdf.
猜你喜欢
科技创新导报(2021年23期)2021-01-15 00:46:10
中国外汇(2019年20期)2019-11-25 09:54:58
科技视界(2019年10期)2019-09-02 03:22:27
当代陕西(2019年13期)2019-08-20 03:54:22
数字技术与应用(2018年5期)2018-09-26 11:34:32
中国纤检(2015年4期)2015-03-13 18:25:35
民主与科学(2014年3期)2014-02-28 11:23:03
测绘科学与工程(2014年5期)2014-02-27 07:06:14
教育与职业(2014年7期)2014-01-21 02:35:04
计算机与网络(2013年1期)2013-06-05 05:31:50
