
基于Logistic回归的胃癌诊断研究
2011-02-07 02:04欧阳露莎刘敏思
中南民族大学学报(自然科学版) 2011年2期
欧阳露莎,刘 寅,刘敏思
(1中南民族大学数学与统计学学院,武汉430074;2华中师范大学数学与统计学学院,武汉430079)
目前,国内外对胃癌的研究主要集中在胃癌癌前病变以及综合防治上[1,2],同时也有一些专家学者利用Logistic回归的模型对进展期胃癌淋巴结转移规律作了研究和预测[3,4],还进行了饮食习惯、家族病史等因素对致癌影响的 Logistic回归的分析[5,6].
在医学普查中,对于胃癌的鉴定主要是依据水试验(x1),蓝色反应(x2),血清铜蓝蛋白含量(x3),吲哚乙酸(x4),中性硫化物(x5)这5项生化指标进行综合分析,依据多元回归计算公式:
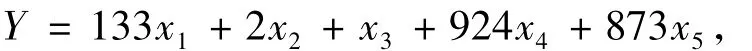
来诊断和鉴别良性胃病与胃癌.通常,在普查中,以Y<850为阳性界限,在临床上Y<1000为阳性界限[7].
由于对胃癌进行医学鉴定的成本较高,昂贵的医疗诊断费用和治疗费用让人们望而止步,耽误了最佳治疗时间.本文试图通过Logistic回归的方法建立5项生化指标与是否患胃癌之间的联系,以期更多的人,特别是家庭经济条件较差的人群,能够及时发现病情并采取积极治疗.
1 Logistic回归模型
1.1 Logistic概率公式
本文选取是否患胃癌作为因变量y,当第i个病人患胃癌时,yi=1,否则yi=0.设有m个影响因素与因变量y有关,记为X=(x1,x2,…,xm),则在m个影响因素条件下,胃癌发生的概率为:
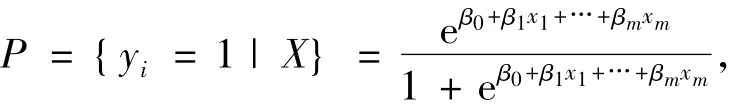
式中xi(i=1,2,…,m)为胃癌的影响因素,可以是连续变量,也可以是分类变量或虚拟变量,β0为常数项,βi(i=1,2,…,m) 为回归系数.
1.2 自变量的选取
本文试图从病人的化验结果的角度来分析其患胃癌的可能性,初步选取了5个候选自变量,分别为:水试验(x1),蓝色反应(x2),血清铜蓝蛋白含量(x3),吲哚乙酸(x4),中性硫化物(x5).
自变量的筛选工作通常从检查每个自变量与因变量之间的二元关系着手.当模型中自变量较多时,将会给工作人员带来较大的工作量.通常,人们采用前进法、后退法或逐步回归法来进行自变量的筛选.由于逐步回归法结合了前进法和后退法2个过程,因此,本文中主要采用逐步回归法进行拟合研究.给定一个显著性水平α,如果自变量的Wald统计量的显著性概率p值小于显著性水平α,表明该自变量与因变量显著相关,选取该自变量;否则,表明该自变量与因变量显著不相关,应剔除该自变量.
2 Logistic回归模型检验
回归系数的显著性检验、Logistic回归模型的拟合优度检验以及预测准确度检验通常用于Logistic回归模型检验.由于在自变量选取过程中,已经采用回归系数的显著性检验对自变量进行筛选,因此,下面只分析Logistic回归模型的拟合优度检验和预测准确度检验.
2.1 Logistic回归模型的拟合优度检验
Pearson χ2统 计 量、Deviance 统 计 量 和Hosmer-Lemeshow统计量是常用的3种拟合优度检验统计量.由于建立的模型中涉及连续型自变量,Pearsonχ2统计量和Deviance统计量不再适合用来检验模型的拟合优度.故此处我们采用Hosmer-Lemeshow 统计量来检验[8].
Hosmer-Lemeshow统计量是一种类似于Pearsonχ2统计量,区别在于对数据进行重新分组后计算实际与期望发生频率,其计算公式为:
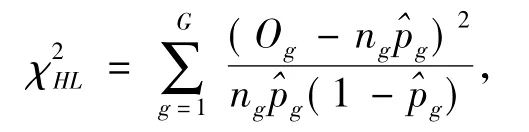
式中,G为分组数,且G≤10;Og为第g组事件的实际数;ng为第g组事件的样本数;^pg为第g组的预测事件概率;ng^pg为第g组事件的预测数.
在H0成立的条件下,χ2HL统计量渐进服从自由度为G-2的χ2分布.当模型拟合数据较好时,χ2HL检验的概率p值应大于显著性水平α;否则,模型拟合数据较差.
2.2 Logistic回归模型预测准确度检验
通过序次相关指标来评价Logistic回归模型的预测准确度,常见的评价指标有Somers'D、Gamma、Tau-a和c,其计算公式分别为[9]:
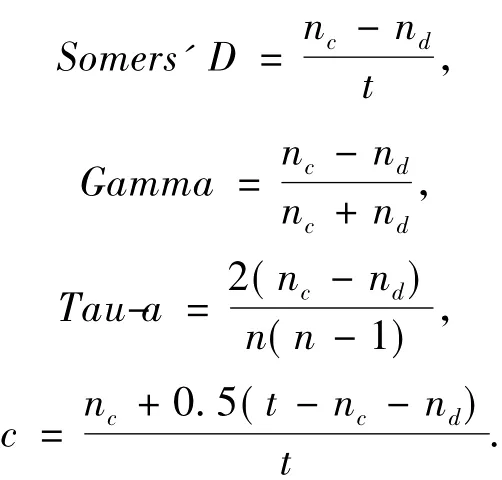
式中,n为样本总数;nc为和谐对的数量,nd为不和谐对的数量;t为观测数据对的总数.
这4个指标的值越接近于1,表示预测概率与因变量之间的关联程度越高,说明模型的预测能力越强.
3 实证分析
本文以140例病人患胃癌情况[10]作为研究对象,使用Logistic模型来探讨胃癌诊断的主要鉴定因素.
3.1 模型的建立
此处分别考虑全模型和以逐步回归法分别得到的拟合模型:
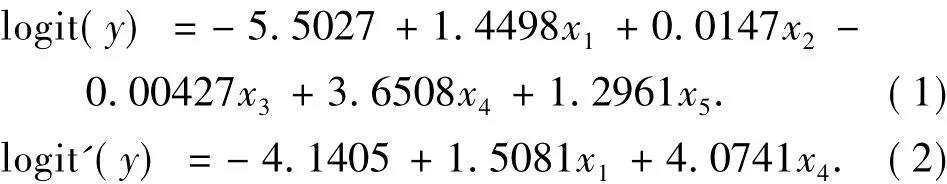
令H0:β2=β3=β5=0,通过检验回归系数子集,我们得到χ2检验统计量的p值为0.1214,大于0.05,说明采用混合逐步回归法建立的模型与考虑所有的自变量建立的模型没有显著差别,即采用混合逐步回归法建立的模型可以较好地估计病人是否患有胃癌.因此,我们采用由混合逐步回归的方法建立的模型,即式(2).在这个模型中,仅包含x1和x4两项,因此,我们在医学普查和临床上对胃癌的鉴定只需进行水试验和检测吲哚乙酸这2项生化指标即可对胃癌进行诊断,有效地降低了化验成本.
3.2 模型检验
3.2.1 拟合优度检验
表1分别给出了Deviance统计量、Pearsonχ2统计量和Hosmer-Lemeshow统计量拟合优度检验的结果.

表1 拟合优度检验Tab.1 Goodness-of-fit tests
由于此模型中含有连续自变量,因此采用Hosmer-Lemeshow统计量拟合优度检验更为合适.因为Hosmer-Lemeshow统计量检验的p值为0.0816,大于0.05的显著性水平,故χ2检验不显著,因此可以断定模型拟合数据较好.
3.2.2 预测准确度检验
表2是序次相关指标的准确度检验结果.

表2 序次相关指标的准确度Tab.2 Efficiency of the rank correlation index
从表2可以看出,本研究共有4324个数据对,其中96.1%为和谐对,有3.6%为不和谐对,0.4%为结.除了Tau-a指标外,其余3个指标值都大于0.92,表明预测概率与因变量之间的关联程度较高,说明建立的Logistic模型的预测能力较好.
4 结语
本文利用逐步回归的方法对胃癌诊断中的5项生化指标进行筛选,建立了是否患胃癌与水试验和吲哚乙酸2项生化指标之间的Logistic回归模型,从而为医学诊断有效地降低了试验成本,同时也为患者及时诊断和治疗带来了福音.
[1]张荫昌.胃癌癌前病变研究的30年进展[J].中国肿瘤,2001,10(7):406-407.
[2]袁 媛,张 联.胃癌高发现场高危人群综合防治研究[J].中国肿瘤,2001,10(3):139-142.
[3]王 浩,周岩冰,陈士远.进展期胃癌淋巴结转移规律的Logistic回归分析[J].青岛大学医学院学报,2008,44(5):414-418.
[4]陈俊强,詹文华,何裕隆,等.胃癌淋巴结转移预测的Logistic回归分析[J].中华胃肠外科杂志,2005,8(5):436-439.
[5]You W C,BlotW J,Chang Y S,et al.Diet and high risk of stomach cancer in shandong,China[J].Cancer Research,1998,48:3518-3523.
[6]Palli D,Galli M,Caporaso N E,et al.Family history and risk of stomach cancer in Italy[J].Cancer Epidemiology Biomarkers & Prevention,1994,3:15-18.
[7]刘光汉.临床常用医疗数据手册[M].西安:陕西科学技术出版社,1998:320-321.
[8]Hosmer DW,Stanley L.Applied Logistic regression[M].New York:John Wiley and Sons,1989:89-150.
[9]王济川,郭志刚.Logistic回归模型——方法与应用[M].北京:高等教育出版社,2001:58-87.
[10]董大钧.SAS统计分析应用[M].北京:电子工业出版社,2008:321-332.
猜你喜欢
中国药房(2022年7期)2022-04-14
湖南林业科技(2021年3期)2021-12-02
——拟合优度检验与SAS实现
四川精神卫生(2021年5期)2021-11-04
统计与决策(2018年14期)2018-08-22
江苏农业科学(2017年10期)2017-07-21
江苏农业科学(2017年10期)2017-07-21
文理导航(2017年20期)2017-07-10
指挥控制与仿真(2017年3期)2017-06-22
卷宗(2017年6期)2017-06-06
科技与管理(2014年4期)2014-12-31
