
AVS编码变换量化和扫描硬件设计与实现
2011-01-27 01:07:44黄学超张卫宁
电气电子教学学报 2011年2期
黄学超,张卫宁
(山东大学信息科学与工程学院 ,山东济南 250100)
AVS编码变换量化和扫描硬件设计与实现
黄学超,张卫宁
(山东大学信息科学与工程学院 ,山东济南 250100)
本文提出了满足AVS实时高清视频编码的变换、量化、反量化、反变换和扫描的硬件设计方案。该设计方案以宏块为单位进行操作,通过采用乒乓操作和流水线技术,提供了高性能的并行数据处理能力。本文根据AVS变换和反变换的特点,设计了RAM行列存储器,实现高速并行转置,同时,提出了利用RAM实现并行扫描的方法及其结构,提供高数据吞吐速率.用FPGA验证结果表明,该设计满足高清序列1080i 30H z实时编码要求。
AVS;实时高清视频编码;RAM行列存储器;并行扫描
0 引言
AVS(Audio Video coding Standard)是我国自主制定的、具有自主知识产权的音视频信源编码标准。该标准技术方案简洁,芯片实现复杂度低,编码效率比第一代标准(M PEG-2)高 2-3倍,在和H.264标准编码效率相当的同时具有较低的编码复杂度。目前视频部分已正式成为国家标准[1-2]。
火灾自动报警系统工程的发展非常迅速,新技术、新工艺、新材料、新设备不断涌现,设备的更新换代速度快,在工程设计中必须考虑现代水利建筑智能防火方面发展的要求,要有一定的前瞻性,因此在设计阶段各项设计内容的质量控制显得尤为重要。
变换、量化、反量化、反变换和扫描是AVS编码中数据处理流程的中间部分,既将残差经过变换、量化、反量化和反变换后返回给帧内和帧间部分,又将扫描后生成的(run,level)对传送至熵编码部分,因此其实现结构的优劣直接影响到编码器的性能。
本文基于 AVS编解码标准,以实现 1080i 30H z格式视频实时高清编码为目标,设计了一种高速并行处理结构。变换和反变换处理一个8x8块的时间仅需14个时钟。本文并设计了RAM行列存储器而不是转置寄存器实现了转置,转置操作仅需8个时钟,节省了大量的寄存器和选择器资源。同时,笔者利用RAM 实现并行扫描,加快整个模块的数据吞吐速率。
1 整数DCT、扫描
1)整数变换和反变换
3.要立足于互联网的经济特点,形成相匹配的包装思路。在互联网电商日益成熟的今天,运输物流尤其是跨境电商模式在逐渐成熟。在这一背景下,探索包装设计活动的新方向,同时对大众消费者自身的兴趣与关注度进行分析,这是当前整个包装设计活动实施进程中的重要内容。要想做好商品的包装设计,企业必须从包装图案、文字使用和色彩选择、色彩搭配这三个重要角度出发,通过合理搭配和巧妙应用,从而在诠释其设计活动文化特性的基础上,实现其艺术性的诠释与观赏性的表达。
AVS采用基于88块大小的类DCT整数变换,避免了变换和反变换过程中产生的误差,使编解码端数据相匹配。AVS变换和反变换的公式如下:

式中,TT8为 T8的转置,有

为了减少变换和量化过程中取整带来的误差,H.264中将正向缩放和量化结合在一起操作,反向缩放和反量化一起操作。而在AVS-P2中,则采用带PIT(预缩放整数变换)的8x8整数余弦变换技术,把所有的缩放都放在编码端完成,极大地简化了解码器的计算量。
每个时钟依据扫描次序得到两个像素地址,分别由输入缓存RAM的双口读出两个扫描数据,32个时钟扫描完成一个子块。
...I am in no humour at present to give consequence to young ladieswhoareslighted by other men[4].
2 AVS编码器结构
图1为AVS编码系统框图。在硬件上编码系统主要由帧内预测、帧间预测、变换量化反变换反量化扫描、环路滤波和熵编码等五部分组成。由编码框图可知,AVS编码路径非常长,若采用顺序处理方式,会降低硬件的利用率和吞吐率,而且不能满足时序要求。
为了加快处理速度,通常采用宏块级流水线处理,如图2所示。在帧内预测时,子块预测需用到同一宏块内相邻子块的重建像素,帧内预测、变换、量化、反量化、反变换和重构构成了一个编码环路。因此,将变换、量化、反量化和反变换集成到一起进行优化,采用合理的流水线成为必然。在帧间预测时,有可能同时获得多个残差块,需要连续处理。若是扫描模块处理速度不够快,则将影响整个系统的数据吞吐速率,所以,扫描模块也必须进行优化。
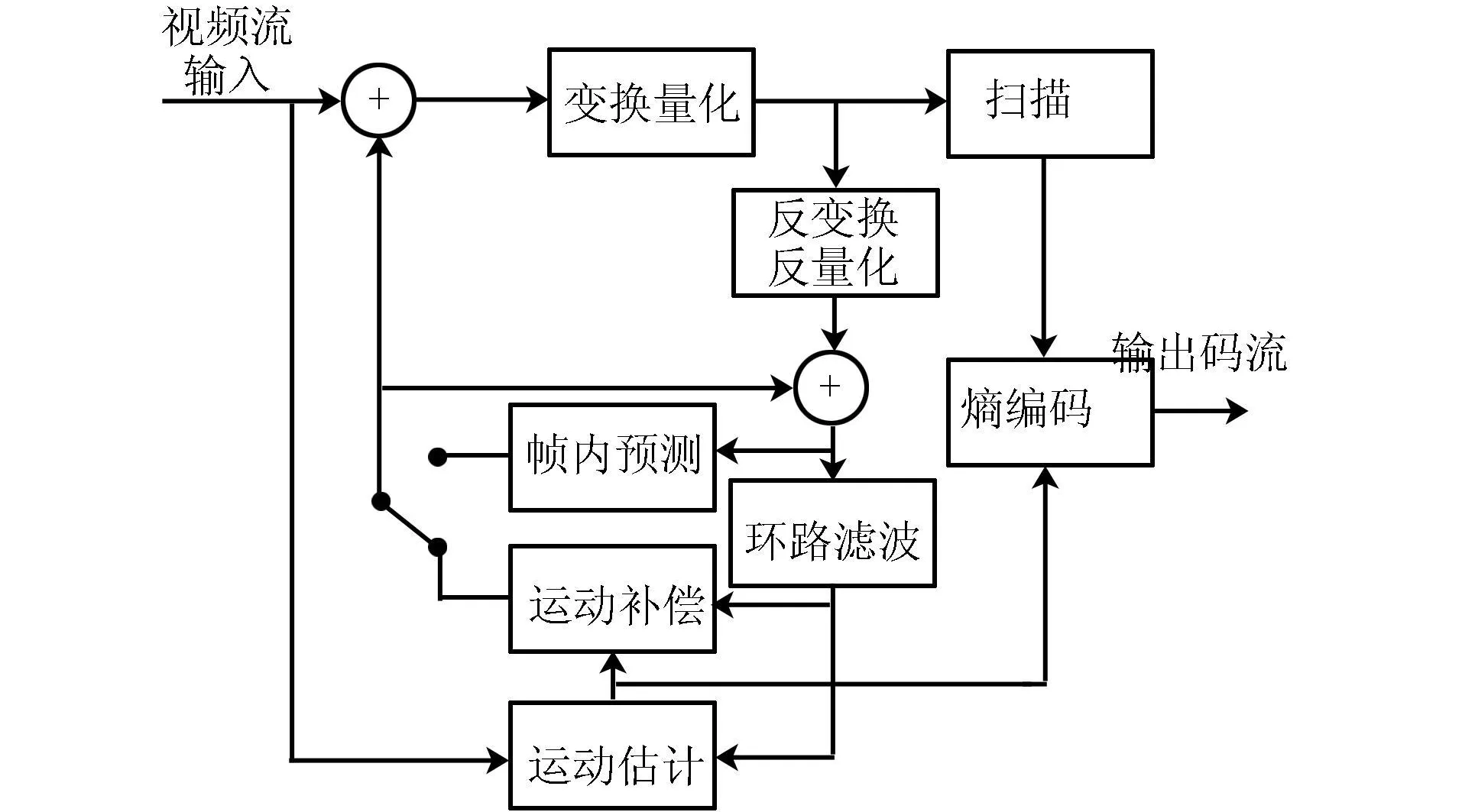
图1 AVS编码系统框图
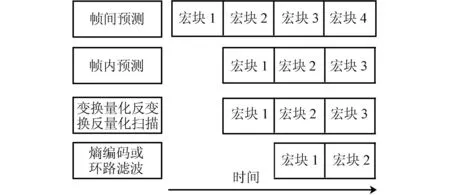
图2 AVS编码器流水线流程
3 硬件结构
本文的设计目标是支持19201088,30fps格式视频的 AVS实时高清编码,系统工作频率为100MHz。可以计算得到一个宏块的处理时间为256/(1920108830)=4085ns,即不超过408个时钟周期,否则就不能满足编码要求。
王婆什么观察力也失去了!不自觉地退缩在赵三的背后,就连那永久带着笑脸,常来王婆家搜查的日本官长,她也不认识了。临走时那人向王婆说“再见”,她直直迟疑着而不回答一声。
图3为本设计的硬件顶层结构框图。系统通过FIFO与帧内预测和帧间预测部分接口,接口宽度为144bit。控制模块依据扫描模块乒乓缓存RAM的状态产生读 FIFO命令,收到读 FIFO命令后,FIFO发送残差块数据,每个周期输出两列数据。残差数据经过变换后从查找表LUT单元得到量化和反量化参数进行量化反量化[3],量化数据保存至乒乓缓存RAM,由扫描模块控制并行扫描,扫描模块输出逆序后的(run,level)对。反量化数据经过反变换后输出,反变换模块每个时钟输出两列数据。量化反量化单元的处理周期固定为3个时钟。
业内人士估算,整个共享单车领域这几年已经烧掉了超过百亿美元,但是,也有数亿用户形成了使用共享单车的习惯。但这一切,只是棋至中局。
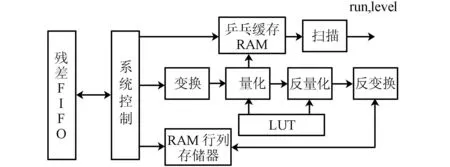
图3 硬件顶层结构框图
1)变换和反变换模块
传统的行列分解法是AVS变换和反变换最常用并行处理方法,即将变换和反变换用8次水平变换和8次垂直变换实现。在本设计中,变换和反变换模块采用改进的行列分解法每次单步运算处理两行或两列的数据。变换模块先列变换后行变换,反变换模块先行变换后列变换。
一般,残差经过变换量化后会产生很多零系数,为了更有效的去除编码冗余,在熵编码之前要进行Zig-Zag扫描和游程编码。AVS规定了两种扫描模式,帧扫描模式和场扫描模式,其选择决定于当前图像的编码方式[2]。根据两种扫描模式可以得到扫描次序和像素点坐标的对应关系。
与传统方法相比,本设计将变换和反变换的时间缩短一半,而仅仅增加了一个一维变换模块和一维反变换模块。而一维变换和一维反变换模块,可以只用加法和移位实现,因此,只增加了很少的硬件开销。变换、反变换的结构框图如图4所示。本设计中,单步变换或反变换为3级流水结构。
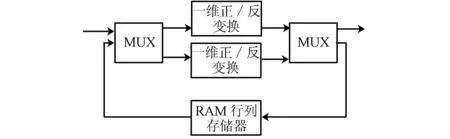
图4 变换或反变换结构框图
PFD最常见的症状是POP、SUI,对女性正常生活影响最大。POP是盆底支持组织(肌肉和筋膜)松弛导致盆腔组织器官移位而出现的盆腔功能异常,子宫脱垂发生率较高,其次是阴道前壁膨出、阴道后壁膨出。我国中老年妇女POP患病率为30%,美国老年女性POP患病率为50%[10]。71%POP患者伴有SUI,59%SUI患者伴有POP[11]。PFD病因尚不十分清楚,流行病学研究[12]显示,年龄、雌激素水平下降、妊娠和阴道分娩、便秘、肥胖、盆腔手术史等是PFD的主要致病因素,其中年龄、经阴道分娩、多产是PFD独立危险因素,肥胖、便秘、雌激素分泌减少、慢性咳嗽是非独立危险因素。
全国有200多种常用药材已开展人工种植[21]。规范中药材的种植,建立健全的中药材种植质量控制标准可确保从源头控制质量。尽可能固定药材基原、产地、种植条件、采收期等影响药材质量的各种因素,可在一定程度上保证中药材质量均一稳定[22]。
变换反变换单元都需对中间结果进行转置,该转置要能存储一个块的数据,且能按照两行或两列的方式并行输入输出数据。若采用文献[4]结构实现,将耗费大量的寄存器。若采用文献[5]所用的RAM实现,仅反变换就需要40个时钟,变换和反变换需要80个时钟,一个宏块就需要480个时钟周期,不满足编码要求。
本文设计了 RAM行列存储器实现转置,该存储器不仅能按照两行或两列的方式并行输入输出数据,且能同时进行两次转置操作,实现乒乓转置。该转置存储器由8个大小为832bit的RAM 组成,每个RAM都由XilinxISE10.1 03综合工具IPCORE Generators生成为双端口RAM,写宽度为32,深度为8,读宽度为128,深度为2。其结构如图5所示。
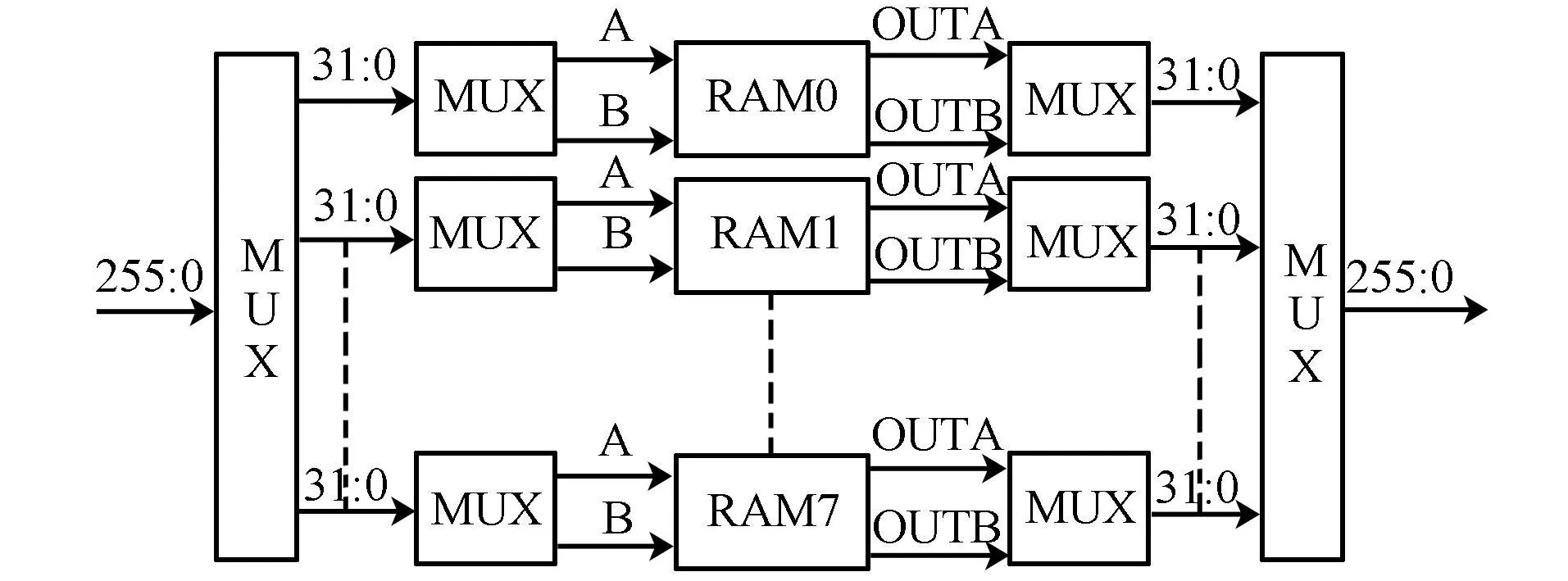
图5 RAM行列存储器
变换模块转置时,每块RAM的A端口输入数据,每个时钟输入两个像素值,按时钟分别写入0,1,2,3单元,共输入一列数据。输出时第一个时钟输出0,1块0单元数据,第二个时钟输出2,3块0单元数据,直到第四个时钟输出6,7块0地址数据。反变换模块转置时,B端口输入数据,写入4,5,6,7单元,输出时输出地址为1。转置操作共需要8个时钟,88像素块完成变换或反变换只需14个时钟。
3)扫描模块
方勋梅没有主动出击,程晓也懒得理她,只是每天,方勋梅刚刚钻出尼桑车,他的凯迪拉克也悄然驶入厂区;每天下班后,方勋梅的车刚一驶上公路,程晓的凯迪拉克就如一尾快鱼从她身边穿过,在暮色中倏地无影无踪。
传统的Zig-Zag扫描处理方法,扫描模块每个时钟扫描一个数据,扫描一个块需要64个时钟,在加上存储所需的4个时钟,处理一个宏块至少需要408个时钟。而编码一个宏块最多要408个时钟,显然不满足编码要求。又因I帧宏块内子块间隔时间不均匀,亮度子块的时间间隔一般较长,与上文所提的编码环路周期有关,色度子块和帧间子块间隔一般较小。这样很难保证子块的流水处理,系统难以满实时处理要求。本文通过并行扫描和乒乓操作技术,大大减少扫描所需的时钟,其结构如图6所示。

图6 扫描模块结构框图
当有输入缓存RAM处于空状态时,扫描控制向系统发出请求数据信号,系统发送残差块,经变换量化后存入输入缓存,输入缓存是大小为896bit的双口RAM,写宽度为 96,深度为8,读宽度为12,深度为64。控制模块判断有输出缓存为空时,便可开始扫描。
2)RAM行列存储器
2)扫描
由于AVS编码是从高频系数开始,与扫描的顺序相反,所以输出缓存需要逆序输出(run,level)对。并行扫描有可能同时获得两个(run,level)对,所以输出缓存由双口RAM组成,大小为6518bit。扫描结束后,输出缓存开始从当前地址读取数据,一直读到零地址数据(存储0),即EOB码,输出一个子块最多需要65个时钟(所有量化系数都不为零时)。由于乒乓扫描操作,扫描模块处理一个宏块最多需要390个时钟。
4 结果分析与仿真综合结果
1)结果分析
1996年我国开始启动超级稻研究。近20年来,我国水稻单产有了大幅度提高。双季超级稻总产优势明显高于一季超级稻,双季超级稻开始进入了推广阶段。随后,袁隆平开始大胆设想“种三产四”的杂交水稻工程,即用“3亩(1亩≈667 m2)地生产出4亩地的粮食”[2]。在南方地区大力推广双季超级稻种植,大幅度提高单产,满足了我国日益增长的粮食需求。
文献[4]和[5]在反变换模块的设计上都采用传统的行列分解法。在转置操作的实现上,文献[4]采用64个寄存器实现,文献[5]采用 RAM 实现,两种设计反变换所需时间分别为24和40个时钟。
本设计中,设计了RAM行列存储器存储变换和反变换的中间结果并在在8个时钟内实现了转置,将变换、量化、反量化、反变换合成到同一流水线。变换和反变换都仅需14个时钟,一个子块完成变换、量化、反量化和反变换只需30个时钟,大大减少了帧内预测时编码环路所用时间,给帧内预测预留了充足的时钟。同时,系统根据扫描模块输入和缓存的状态,发送数据请求信号,根据输出缓存状态,进行扫描。而扫描模块扫描子块最少需要32个时钟,输出子块(run,level)最多需要65个时钟。因此,系统处理一个宏块的时间取决于扫描模块,最高为390个时钟(所有量化系数不为零时),满足编码要求。
2)仿真综合结果
本设计使用Verilog HDL硬件描述语言进行实现。Modelsim 6.2i进行仿真,并采用 Xilinx-ISE10.103综合工具,选择XC5VFX100t-1FF1136器件。综合占用资源如表1所示,综合布局布线后的结果表明该结构最高工作频率高于150MH z。

表1 硬件综合结果
利用ChipScope下载验证,与AVS参考软件RM 52G生成的测试向量进行对比,下载验证结果正确,该结构完全满足高清编码需要。
下载验证结果表明,该结构可以满足AVS实时高清编码需要。
[1] Iain E.G.Richardson著,欧阳合,韩军译.H.264和MPEG-4视频压缩[M].长沙:国防科技大学出版社,2004
[2] 中国音视频标准工作组.信息技术先进音视频编码第二部分:视频(Information technology-Advance coding of audio and video-part2:video(报批稿),2005
[3] Sheng Bin,Gao W en,W u Di.A n Im plem ented VLSI A rchitectu re of Inverse Quantizer for AVS HDTV V ideo Decoder[C].The 6th IEEE International Conference On ASIC(ASICON),Oct 24-27,2005(1):306-309
[4] 赵策,刘佩林.AVS游程解码、反扫描、反量化和反变换优化设计[J].哈尔滨:信息技术,2007(2):54-57
[5] 黄友文,陈咏恩.AVS反扫描、反量化和反变换的一种优化设计[J].北京:计算机工程与应用,2008,44(19):93-95
Hardware Design and Implem entation of Transform Quantization and Scan in AVSCoding
HUANG Xue-chao,ZHANGWei-ning
(Co llegeo f In formation Science and Engineer ing,Shan Dong University,Jinan 250100,China)
A hardware architecture of transform,quantization,inverse quantization,inverse transform and scan for AVS real-time HD video coding is p roposed.The design operates on macroblock leveland p rovides high parallelization,in w hich ping-pong technique and pipelining technique are used.According to the specialty of transform and inverse transform,a row-line RAM m emorizer which can realize fast parallel transpose is designed.A parallel scan method using RAM and its hardware architectureare proposed to provide high data throughput.The FPGA verification show s that the design supports 1080i 30Hz real-time HD video coding.
AVS;real-time high definition video coding;row-line RAM memorizer;parallel scan
TN 919.81
A
1008-0686(2011)02-0034-04
2010-08-08;
2010-11-08
黄学超(1985-),男,硕士研究生,研究方向为数字视频处理,E-mail:hxc.421@126.com
张卫宁(1953-),女,教授,主要从事数字信号处理与分析,嵌入式应用系统设计技术等研究工作,E-mail:zw ning@sdu.edu.cn
猜你喜欢
电脑知识与技术(2024年12期)2024-06-16 05:03:12
电脑知识与技术(2024年10期)2024-06-01 05:59:06
现代计算机(2021年36期)2021-03-14 00:50:40
汽车维修技师(2019年7期)2020-01-16 04:33:04
计算机应用(2018年12期)2019-01-07 12:16:36
汽车维修技师(2018年11期)2018-05-11 02:38:32
中学生数理化·高一版(2017年1期)2017-04-25 13:22:35
电子设计工程(2015年24期)2015-08-26 06:39:42
新高考·高一物理(2014年4期)2014-09-17 06:52:02
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
