
* 基于结构化支持向量机的中文句法分析
2011-01-11 08:21:56王文剑王亚贝
山西大学学报(自然科学版) 2011年1期
王文剑,王亚贝
(1.山西大学计算智能与中文信息处理教育部重点实验室,山西太原 030006;2.山西大学计算机与信息技术学院,山西太原 030006)
*基于结构化支持向量机的中文句法分析
王文剑1,2*,王亚贝2
(1.山西大学计算智能与中文信息处理教育部重点实验室,山西太原 030006;2.山西大学计算机与信息技术学院,山西太原 030006)
通过构造结构化函数ψ(x,y),提出一种基于结构化支持向量机(SVM-Struct)的中文句法分析方法.实验结果表明,与经典的概率上下文无关文法(PCFG)相比,文章提出的方法在中文句法分析方面是十分有效的.
支持向量机;结构化SVM;中文句法分析
0 引言
句法分析是自然语言处理中的一个重要环节,同时它也是公认的研究难题.许多自然语言处理问题,如机器翻译、信息获取、自动文摘等都要依赖句法分析的精确结果才能最终获得满意的解决.随着信息社会的到来,人们对自然语言处理的要求日益迫切,因而对句法分析的研究具有重要的实际意义.
句法分析的主要任务是给定一个输入句子,以语言的语法特征为主要知识源生成一棵短语结构树,通过树的形式指明句子各部分之间的关系.目前为止,句法分析的研究大体分为两种途径:基于规则的方法和基于统计的方法.相比传统的基于规则的方法,基于统计的分析方法具有更好的灵活性,在处理歧义等不确定性问题方面都有较好的效果[1].
概率上下文无关文法(PCFG)是把统计方法引入到上下文无关语法而形成的语法规则系统[2],然而经典的PCFG实际上是建立在一些非常理想化的独立性假设基础上,而这些假设对于实际问题往往不能满足,因此PCFG的实际应用效果并不理想.由Vapnik等人[3]提出的支持向量机(Support Vector Machine,SVM)具有完美的数学形式、直观的几何解释和良好的泛化能力,是一个通用有效的学习方法,目前已成功运用在自然语言处理的任务中,如英语词性标注、英语专名识别和文本分类等方面,并在这些领域都取得了不错的效果[4].然而中文句法分析要处理的数据具有复杂的结构,传统的支持向量机已经不适应解决此类问题.
2004年Hofmann和Joachim s等针对实际应用中大部分要处理的数据往往具有比较复杂且彼此之间存在相互依赖关系的复杂特性(如树形结构、队列结构或网状结构数据等),对传统支持向量机进行了改进,首次提出结构化支持向量机(SVM-Struct)[5],该方法通过结构化函数ψ(x,y),并结合分解、选块思想来实现对大规模复杂数据的分析.Joachim s等人之后对结构化支持向量机进行了改进,提出n-Slack Formulation等算法来提高SVM-Struct的速率[6].Thomas G.Detterich等人认为结构化支持向量机研究在未来十年都会有很好的发展及应用前景[7].
由于中文句法分析的数据集具有丰富的内部结构,同时结构化支持向量机对处理复杂结构数据的高效性,所以本文探索将结构化支持向量机学习方法应用于中文句法分析领域,仿真实验获得了较为满意的结果.
1 SVM-Struct学习方法简介
支持向量机SVM(Support Vector Machine)是新型机器学习方法,具有完备的统计学理论基础,它采用结构风险最小化原则代替传统统计学的基于大样本的风险最小化原则,具有出色的学习和推广能力.但在实际应用中,大部分要处理的数据(如树形结构、队列结构或网状结构数据等)都是比较复杂彼此之间存在相互依赖,具有特定结构化关系的,而用传统的支持向量机已经很难去处理这些问题了,因此,结构化支持向量机(SVM-Struct)根据数据内部的结构性提出结构化函数ψ(x,y)对传统的支持向量机进行了改进,能有效地处理结构化数据.
结构化数据分析问题的目的是要找到样本的输入与输出对之间的一个函数f:X→Y假定函数f的形式为:

其中F是判别函数:F(x,y;w)=〈w,ψ(x,y)〉,w是权向量,ψ(x,y)是结合输入与输出数据特性提取出来的代表着输入输出彼此之间特性合并的一个向量.一般ψ(x,y)的形式取决于具体要解决的结构化问题.
SVM-Struct通过训练得到w权向量,使:

其中定义δΨi(y)≡ψ(xi,yi)-ψ(xi,y).
班级也是一个社会的组织,班主任可以将大学生职业生涯规划整合到班级建设中,例如:开展班级面试大赛、职业理想演讲比赛、班级社会实践,优秀毕业生交流等班级建设活动,将职业生涯规划融入到学生生活中,帮助学生毕业时能尽快适应职场生活。
采用最大间隔法[8],引入松弛变量[9]的最优化问题为:
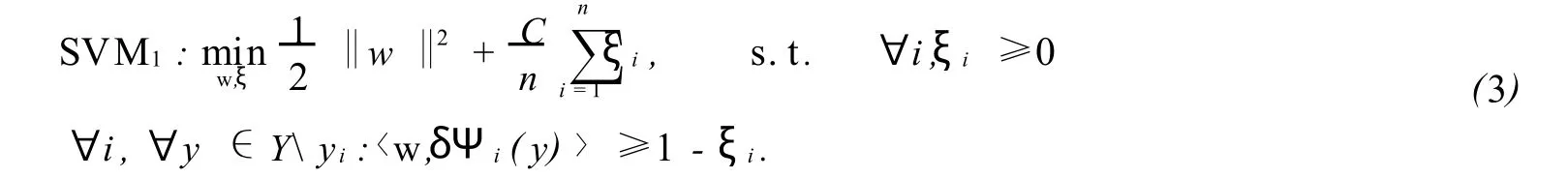
由于实际问题中|y|往往很大,以上形式不适合解决此类问题,所以在约束条件中引入了损失函数:

或者 ∀i,∀y∈Yyi:〈w,δΨi(y)〉≥Δ(yi,y)-ξ(5)
最优化问题(3)的对偶形式为:

其中αiy是拉格朗日乘子.对于软间隔,还另外有组约束条件:

在SVM-Struct方法中,其重点也是难点的是ψ(x,y)函数的构造,对于实际应用问题,ψ(x,y)构造的合适与否将直接影响SVM-Struct方法的有效性.
2 基于SVM-Struct的中文句法分析
目前中文句法分析研究中常采用两类方法,一类是浅层句法分析,也叫部分句法分析或语块分析,主要任务是语块的识别和分析.另一类是完全句法分析,通过一系列分析过程,最终得到句子的完整的语法树.本文的研究方法属于完全句法分析,它基于SVM-Struct方法,主要通过构造结构化函数ψ(x,y),对中文句法进行分析,最终得到句子的完整语法树.

其中αi(i=1…n)指所对应的语法规则出现的次数,n指所涉及的语法规则的总个数.一个句法分析示例及对应的ψ(x,y)如图1所示.

图1 (a)中文句法分析示例;(b)对应的ψ(x,y)Fig.1 (a)Illustration of Chinese parsing;(b)Correspondingψ(x,y)
一个句子样本x通过函数f(x;w)=argy∈mYa xF(x,y;w)得出与之对应的句法树y,其中F(x,y;w)=〈w,ψ(x,y)〉.本文所用到的汉语词类标注及汉语短语标注见表1[1]和表2[1].

表1 汉语词类标注Table 1 Chinese part of speech tagging

表2 汉语短语标注Table 2 Chinese phrase tagging
句法树y中的每个结点对应着语法规则gj以及权值w j.句法树y中所有结点对应的w j的总和将代表着将样本x分类为y的一个评价值.这个值可以通过函数F(x,y;w)=〈w,ψ(x,y)〉得到,其中ψ(x,y)列向量中的每个元素对应着句法树y中每个gj所出现的次数.然后通过式(1)最大化函数F,就可以得到正确的y.
基于SVM-Struct的中文句法分析算法的主要步骤如下:
Step1:输入训练样本(x1,y1),…,(xn,yn),设置参数C,ε,并选定损失函数类型,即为Δ(yi,y).
Step2:初始化工作集Si为空集,i=1,(i=1,…,n).
Step3:按式(4)计算H(y)≡(1-〈δΨi(y),w〉)Δ(yi,y),其中w≡∑j∑y′∈Sjαiy′δΨj(y′).
Step4:计算出^y=arg maxy∈Y H(y).
Step5:计算得出ξi=max{0,maxy∈Si H(y)},如果H(^y)>ξi+ε,那么Si←Si∪{^y},S= ∪i Si,在S上进行二次优化更新αs,并继续返回到Step3进行优化,否则转到Step6.
Step6:输入测试数据集根据训练得出的权值进行分类测试并输出测试结果.
3 实验结果与分析
本文实验所用数据来自北京大学计算语言学研究所公开的微型语料库中的树库样例(1434句),句长大约都在5-20个词之间.本文首先按照SVM-Struct方法重写训练句子.如句子“北京在黄河北面”的树库格式为:

由于本文重点在于验证SVM-Struct算法在中文句法分析中的可行性,所以选取了其中一部分数据作为实验数据.将50条句子作为训练数据集,并从树库中随机抽取50条句子作为测试数据集来验证结构化支持向量机在中文句法分析上的可行性以及有效性.

实验采用的评价准则主要有准确率(Accuracy)和F1[1],其定义分别为:其中,TP、TN、FP、TN指一个预测可能产生的四种结果,TP(Ture Positive)指正确的肯定;TN(Ture Negative)指正确的否定;FP(False Positive)指错误的肯定;FN(False Negative)指错误的否定.
实验首先统计训练数据集中出现的语法规则以及出现的次数,结果见表3.

表3 训练数据集中出现的语法规则及频次Table 3 Grammatical rules and frequencies in training dataset
实验中,设置惩罚参数C=1.0及参数ε=0.01,并选用两种损失函数的SVM-Struct算法即SVM1和SVM(其中SVM1采用0——1损失;SVM采用F1损失,F1的定义式见式(11),其中Δ(yi,y)=(1-F1(yi,y)).与传统的概率上下文无关文法PCFG进行比较.三种方法训练和测试的结果见表4.

表4 采用三种方法进行句法分析的实验结果Table 4 Experiment results by three Chinese parsing approaches
从实验结果可以看出,选用SVM-Struct算法进行的句法分析无论从准确率Accuracy还是F1测量值都要优于PCFG分析方法,尽管运行时间比PCFG方法稍慢但也是在我们可以接受范围内的,由此可以得出,在中文句法分析问题中SVM-Struct能够有效地利用传统SVM高泛化性能的优势.另外SVM1在准确率Accuracy上较高于SVMΔs1,但从F1测量值来看,SVMΔs1要优于其他两种算法.因此,在结构化支持向量机中,损失函数将会影响F1测量值.在实际问题中,我们可以根据特定的处理对象来选择合适的损失函数及SVM的核函数与参数,从而进一步得到更为优秀的学习模型.
4 结论及展望
本文基于SVM-Struct,通过分析结构化输入数据与输出数据的特征对应关系,构造结构化函数ψ(x,y),将结构化支持向量机算法应用在自然语言处理中的中文句法分析.本文通过选用不同的损失函数对数据进行测试,实验结果表明结构化支持向量机算法在中文句法分析中的可行性及有效性.尽管SVM-Struct对结构化数据具有较好的学习性能及应用性,但本文基于SVM-Struct的中文句法分析的研究是初步的,另外由于目前中文树库资源还非常稀少,因此我们的实验结果可能存在一定片面性.今后如何通过增大实验数据以及增加评价指标使其中文句法分析更深入还有待于进一步研究.
[1] Christopher D.Manning,Hinrich Schutze,Foundations of Statistical Natural Language Processing[M].Cambridge,M IT Press,1999.
[2] 林颖,史晓东,郭峰.一种基于概率上下文无关文法的汉语句法分析[J].中文信息学报,2006,20(2):1-7:32.
[3] Vapnik V.Statictical Learning Theory[M].New York:Wiley,1998:11-23.
[4] 李珩,朱靖波,姚天顺.基于SVM的中文组块分析[J].中文信息学报,2004,18(2):1-7.
[5] Tsochantaridis I,Hofmann T,Joachim s T,et al.Support Vector Machine Learning for Interdependent and Structured Output Spaces[C]//Proceedings of the twenty-fist International Conference on Machine Learning,2004:104-112.
[6] Joachims T,Thomas Finley,Chun-Nam John Yu.Cutting-Plane Training of Structural SVMs[J].Machine Learning,2009,77(1):27-59.
[7] Dietterich G H,Domingos P,Getoor L.Structured Machine Learning:the next ten years[J].Machine Learning,2008,73(1):3-23.
[8] Tsochantaridis I,Joachim s T,Hofmann T,et al.Large Margin Methods for Structured and Interdependent Output Variables[J].Journal of Machine Learning Research,2005,9:1453-1484.
[9] Crammer K,Singer Y.On the Algorithmic Implementation of Multi-Class Kernel-Based Vector Machines[J].Journal of Machine Learning Research,2001,2:265-292.
[10] 冯志伟.基于短语结构语法的自动句法分析方法[J].当代语言学,2000,2(2):84-98.
Chinese Parsing Based on Structural Support Vector Machine
WANG Wen-jian1,2,WANG Ya-bei2
(1.Key Laboratory of Computational Intelligence and Chinese Information Processing of Ministry of Education,Taiyuan030006,China;
2.School of Computer and Information Technology,Shanxi University,Taiyuan030006,China)
A structural support vector machine(SVM-Struct)approach for Chinese parsing was introduced by constructing structural functionψ(x,y).Comparing with the traditional probabilistic context free grammar(PCFG),the experiment results demonstrate that the proposed SVM-Struct approach is effective for Chinese parsing.
support vector machine;SVM-Struct;Chinese parsing
TP181
A
0253-2395(2011)01-0066-05*
2010-07-28;
2010-10-18
国家自然科学基金(60975035);教育部博士点基金(20091401110003);教育部科学技术研究重点项目(208021);山西省自然科学基金(2009011017-2);山西省回国留学人员科研资助项目(2008-14)
王文剑(1968-),女,山西太原人,博士,教授,博士生导师,主要从事机器学习、计算智能等的研究.E-mail:w jwang@sxu.edu.cn
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
河北理科教学研究(2021年4期)2021-04-19 13:34:44
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
计算机教育(2020年5期)2020-07-24 08:53:00
时代英语·高一(2019年1期)2019-03-13 10:29:48
时代英语·高三(2019年1期)2019-03-13 10:29:26
时代英语·高三(2018年1期)2018-02-23 19:33:53
新高考(英语进阶)(2017年10期)2017-12-23 09:15:06
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
