
关联规则在高校评教系统的应用
2011-01-06 08:21:10陈井霞刘志凯
哈尔滨师范大学自然科学学报 2011年1期
白 玲,陈井霞,刘志凯
(哈尔滨商业大学广厦学院)
关联规则在高校评教系统的应用
白 玲,陈井霞,刘志凯
(哈尔滨商业大学广厦学院)
利用关联规则对高校教师进行评价,进而探索受学生欢迎的教师类型.
数据挖掘;关联规则;Apriori算法
1 数据挖掘概述
1.1 数据挖掘定义
简单地说,数据挖掘 (Data Mining,DM)是指从大量数据中提取或“挖掘”知识.广义观点是:数据挖掘是从存放在数据库、数据仓库或其他信息库的大量数据中发现有趣知识的过程.它是“数据中的知识发现”(KDD)的一个非常重要的步骤.[1]
1.2 数据挖掘流程
数据挖掘是知识发现中比较重要的步骤.数据挖掘流程如图1所示.
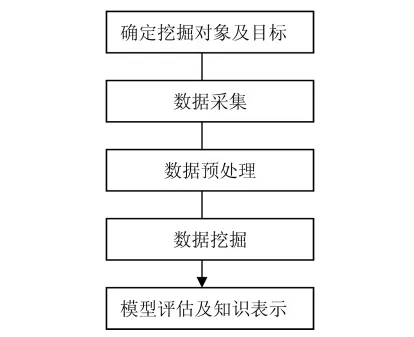
图1 数据挖掘流程
虽然挖掘的最后结果不可预测,但要探索的问题应是有预见性的.首先要选择合适的挖掘算法,然后按照不同算法进行预处理.这一步非常重要,不同的算法可能需要不同的分析数据模型.数据挖掘的过程是一个多次循环反复的过程,每一个步骤一旦与预期目标不符,都要回到前面步骤,重新调整,重新执行.[2]
2 关联规则
2.1 频繁模式
频繁模式是频繁地出现在数据集中的模式(如项集、子序列或子结构).在挖掘数据之间的关联、相关和许多其他有趣的联系时,频繁模式起着重要的作用.因此频繁模式的挖掘就成了一项重要的挖掘任务和挖掘研究关注的主题之一.[1]
2.2 关联规则挖掘过程
关联规则挖掘过程一般分两步:
第一步:找出所有的频繁项集.根据定义,这些项集的每一个出现的频繁性至少与预定义的最小值支持计数min_sup一样.
第二步:由频繁项集产生强关联规则:根据定义,这些规则必须满足最小支持度和最小置信度.
2.3 Apriori算法概述
Apriori算法是Agrawal和 R.Srikant于1994年提出的为布尔关联规则挖掘频繁项集的原创算法.
Apriori算法分析:算法使用频繁项集性质的先验知识.Apriori使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集.首先,通过扫描数据库,累积每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合.该集合记作L1.然后,L1用于找频繁2项集的集合,L2用于找L3,如此下去,直到不能再找到频繁k项集.找每个Lk需要一次数据库全扫描.[1]
3 关联规则在评教系统的应用
3.1 方案设计
算法选择:选用经典的Apriori算法.
挖掘对象:全校现任专兼职教师,79人次,100门课程.
挖掘目标:挖掘学生更喜欢哪类教师,学历高还是职称高?
数据采集:2010-2011第一学期的教师评价表
数据源类型:Excel工作表
挖掘工具:SPSS Clementine
3.2 数据采集及预处理
原始表有两个,一个是教师基本信息表,一个是学生评教表,因为有些教师信息不全,所以采用忽略元组的方式,将资料不全的教师信息删除.将两表集成后得到教师评估表.因为主要针对职称、学历、评分结果信息挖掘,其他字段对来说没有意义,所以将其余字段删除.由于Apriori算法是基于布尔型的算法,对连续数据无法使用,所以需对评分结果离散化,离散标准是:设大于等于90分为“优秀”;大于等于85分为“良好”;大于等于80分为“中等”;小于80分为“一般”四个等级.离散化后教师评估表如表1所示.

表1 离散化后的教师评估表
3.3 数据挖掘
利用Apriori算法,在Clmentine下建立的数据挖掘模型如图2所示.
图2是针对本次挖掘任务所设计的流.流中将“教师评估表.xls”作为源文件节点.添加类型节点建立库与模型间的数据传输,Apriori算法模型中共用到了6个属性字段,所以叫6字段,最后将图形节点填入流中,实现了结果多样性.
建模过程及主要参数配置如下:
(1)建立数据源节点.教师评估表.xls
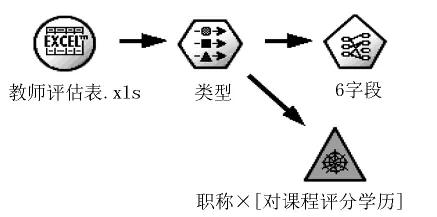
图2 Apriori关联规则数据模型
(2)建立类型节点,与数据源连接.将所有字段将方向设置为两者.
(3)建立Apriori模型,与类型连接.将后项、前项设置为全选;最低支持度设为10%,最低置信度设为60%,最大前项数设为2.
(4)建立网络图形,与类型连接.将可显示的最大链接数设为15.其他默认即可.
3.4 模型评估与图形表示
(1)模型评估:执行关联规则模型得到挖掘结果1,见表1.
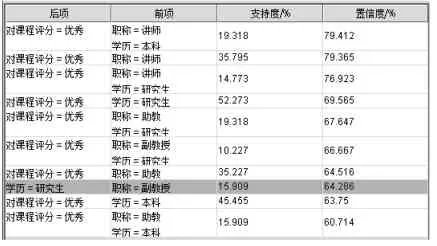
表1 数据挖掘结果1
(2)图形表示:挖掘结果2(DAG布局),如图3所示.
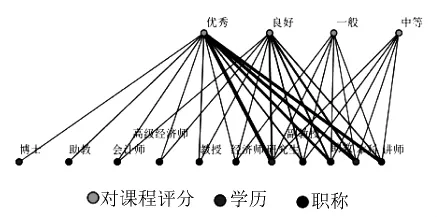
图3 数据挖掘结果2(DAG布局)
3.5 结果分析
(1)由表1分析可知:
①职称为讲师、学历是本科的教师,课程评分是优秀.
②职称是讲师的教师,课程评分是优秀.
③职称为讲师、学历是研究生的教师,课程评分是优秀.
④学历是研究生的教师,课程评分是优秀.
⑤职称是助教、学历是研究生的教师,课程评分是优秀.
⑥职称是助教、学历是本科的教师,课程评分是优秀.
规则中,没有挖掘出评分为良好、中等、一般的情况,说明有些统计结果还是偏高,有部分学生填写不够认真导致.
(2)由图4分析可知:
图中将学历、职称划分为一组,对应评分结果产生连线.线条较密集(粗)的有以下几根:
①研究生和优秀
②助教和优秀
③本科和优秀
④讲师和优秀
这与生成规则得出的结论完全相符.
(3)误差原因分析:
①由于本次参与测试的原始数据只有79名教师,100门课程,共176条记录,规模不是很大.
②部分教师的资料不是实时更新的,这对挖掘结果都有一定的影响.
③在对原始数据进行离散化处理时,可能也产生了误差.
4 结论
从结果前项中看到,职称基本上是讲师和助教、学历基本上是本科和研究生,这说明象学校这样的有十年校龄的民办高校中,大部分骨干教师都是本科起点的讲师和研究生起点的助教为主.
而从后项评分结果都是优秀中能够看出,教师的教学效果得到了大部分学生的认可.这说明学生喜欢的并不全是职称高,学识深的有多年教学经验的老教师.而年轻的肯干的青年教师,缩短了和学生之间的差距和代沟,更受到学生的欢迎.
这个结论说明,学校现任助教和讲师的教学水平得到了学生的认可,可能与以下因素有关:
(1)教师队伍比较年轻,在和学生沟通方面没有障碍.
(2)虽然看到的职称是助教和讲师,但其实这些老师在此岗位已经工作多年,积累了很多教学经验,已经接近评定下一职称的年限,工作能力比较强.
[1]Han Jiawei,Micheline Kamber.范明,孟小峰,译.数据挖掘概念与技术:原第二版.北京:机械工业出版社,2008.
[2]刘宇阳.数据挖掘技术在高校学生成绩分析中的应用[J].交通科技与经济,2008,47(3):65 -67.
[3]陈辉,向伟忠,单健.关联规则挖掘在教师教学评价系统中的应用[J].南华大学学报:自然科学版,2005,19(1):104-107,118.
The Application of Association Rules in University Teaching Assessment System
Bai Ling,Chen Jingxia,Liu Zhikai
(Harbin University of Commerce)
The teachers in the universities are evaluated by using association rules,further the types of teachers welcomed by students are explored.
Data mining;Association rules;Apriori algorithm
2010-11-01
(责任编辑:黄永辉)
猜你喜欢
公民与法治(2022年4期)2022-08-03 08:20:42
疯狂英语·新悦读(2020年1期)2020-02-20 13:23:08
公民与法治(2016年4期)2016-05-17 04:09:24
东西南北(2015年9期)2015-09-10 07:22:44
草地(2014年1期)2014-12-09 03:17:25
中国卫生(2014年1期)2014-11-12 13:16:30
卷宗(2014年5期)2014-07-15 07:47:08
教育与职业(2014年7期)2014-04-17 18:46:57
计算机工程(2014年6期)2014-02-28 01:26:12
教育与职业(2014年31期)2014-01-19 01:48:12
