
基于集合卡尔曼滤波的土壤水分同化变权实验研究
2010-12-28 03:19:22王明玉赵英时
地理与地理信息科学 2010年1期
刘 茜,王明玉,赵英时
(中国科学院研究生院,北京 100049)
基于集合卡尔曼滤波的土壤水分同化变权实验研究
刘 茜,王明玉*,赵英时
(中国科学院研究生院,北京 100049)
将集合预报成员不等权重思想与集合卡尔曼滤波(En KF)同化方法相结合,利用集合成员的离散度作为权重因子,对En KF算法优化后的集合成员采用不等权重取平均值,作为同化后的预报值。首先检验了集合离散度和预报误差的相关性,证明将集合离散度作为权重因子的可靠性;利用一个水文过程模型(DHSVM)和实测数据进行了土壤水分的同化变权实验,对EnKF分析和更新后产生的土壤水分集合,分别采用算术平均和变权平均的方法,计算土壤水分预报结果并进行比较。实验表明,集合变权平均法可以进一步提高同化的预报效果。
数据同化;集合预报;权重;En KF;土壤水分
0 引言
集合卡尔曼滤波(En KF)算法目前被广泛应用于大气、海洋、陆地等数据同化研究和应用中[1-3],许多学者将 En KF与其他同化方法进行了比较研究[4,5],进一步证明了 En KF方法的有效性和优越性。En KF基于集合预报的思想发展起来,它通过一组集合预报得到预报误差协方差矩阵,即从集合预报估计状态变量与观测变量之间的协方差,利用观测资料和协方差,通过卡尔曼滤波方程更新集合预报结果。为了提高计算精度,En KF需要很大的集合数目,但是在利用En KF同化之后,只是将所有集合成员的算术平均值作为预报结果,集合中每个预报结果具有相同的权重,这并不能够完全解释集合分布中的信息。如果集合中存在与大多数成员差别非常大的成员,其将对集合平均结果有较大的影响。集合预报的结果更倾向于多数集合预报成员的值,高预报成功率往往对应于较多成员比较一致的结果[6],基于变权集合平均法的集合预报可以获得更好的预报结果[7,8]。变权集合平均法的出发点就是通过对集合成员权重的调整,加大预报结果较为一致的集合成员的权重,强调这种一致性对预报结果的影响。在En KF的集合数据同化研究中尚未运用该方法。
本文将集合预报成员不等权重的思想与 En KF同化方法相结合,在不影响 En KF算法对误差协方差矩阵计算,即不影响整个同化方法优化分析和更新的情况下,以 En KF算法更新后集合成员的离散度作为权重因子,采用不等权重的集合平均值替代简单算术平均值作为最后的预报值,以期获得更好的预报效果。
1 算法介绍
1.1 集合卡尔曼滤波(En KF)
Evensen根据 Ep stein的随机动态预报理论提出集合卡尔曼滤波(En KF)算法[9],Burgers对该算法进行了改进,提出扰动观测的 En KF算法[10],其思想和计算如下:
(1)初始化背景场。给定 N个符合高斯分布的状态变量Xi(i=1,…,N),计算每个状态变量在 k+ 1时刻的预报值 Xfi,k+i:
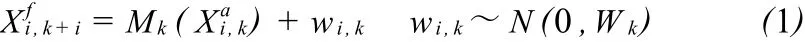
式中:Xif,k+i、Xai,k分别为第i个状态变量在k+1时刻的预报值和在 k时刻的分析值;Mk(■)表示非线性模型算子;Wk为模型误差方差矩阵;wi,k表示期望为0、方差为Wk的高斯白噪声。
(2)计算 k+1时刻的卡尔曼增益矩阵 Kk+1:
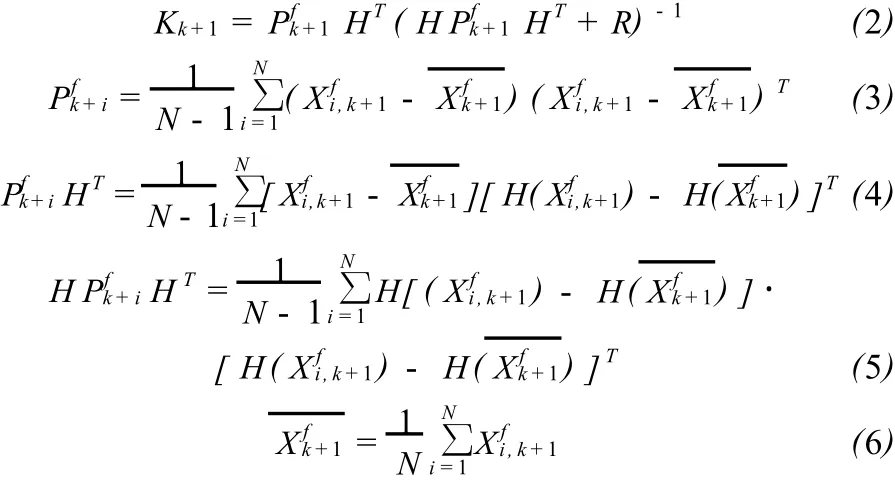

(4)进入下一时刻,返回步骤(2)。
1.2 集合变权平均法
在En KF算法优化更新后,会产生一组优化后的状态变量集合。为了提高集合预报的效果,考虑到集合成员之间的差异,选用集合成员之间离散度w作为权重因子,对集合平均值进行调整。
集合成员的离散度w可以定义为:
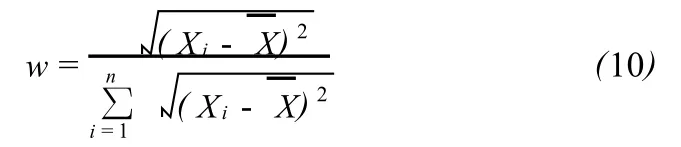
集合中每个元素的权重可以认为与其离散度成反比,离散度越大,赋权重越小。集合变权平均预报结果′可表示为:
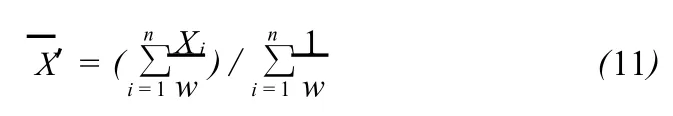
1.3 变权集合同化效果检验方法
利用En KF算法对状态变量进行更新,产生优化后的状态变量集合,对集合分别采用等权平均法和变权平均法计算预报结果;然后利用实测的土壤水分数据,采用平均误差(M B E)和均方根误差(RM SE)对预报效果进行检验。公式为:
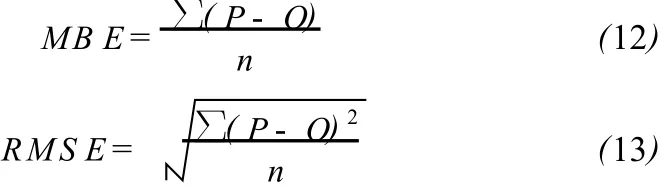
式中:P为预报值;O为实地观测值;n为观测的数量。
2 同化变权实验
为检验此方法的有效性,基于En KF算法,将实测的土壤水分数据与分布式水文土壤植被模型(DHSVM)模拟的土壤水分进行同化,对优化后的土壤水分集合分别采用等权平均和变权平均的方法,计算预报的土壤水分,在黑河流域进行了土壤水分同化变权实验。
2.1 研究区与数据
黑河流域是我国第二大内河流域,流域面积11.6万km2,年均降水量108 mm。研究区位于黑河流域中游(38°45′~39°15′N,100°00′~100°45′E),地面高程在1 000~2 000 m,年均气温6℃。研究区内的自动气象观测站记录了水文模型所需的6个气象驱动变量:气温、风速、相对湿度、短波辐射、长波辐射、降水;在每个气象站放置了 TDR仪器,用于测量10 cm、20 cm、40 cm、80 cm、120 cm、160 cm深度的土壤水分。实验在 HUAZHA IZI站点进行,此处主要为低矮稀疏灌草覆盖的荒漠,土壤以砂砾土为主。
2.2 分布式水文土壤植被模型(DHSVM)
DHSVM模型详细描述了地形和植被对水流动的影响,模型主要包括植被截留、蒸散发、积雪、融雪和径流等部分。DHSVM在流域数字高程模型(DEM)的网格尺度上对水文过程进行动态描述,以DEM的节点为中心,流域被分成若干计算网格单元,每个网格被赋予不同的土壤和植被特性。每一计算时段内,模型对流域内各网格的能量平衡方程和质量平衡方程提供联立解,各网格之间通过坡面汇流和壤中流的汇流演算发生水文联系。
非饱和土壤水运动采用两层模式进行模拟,透过植被下渗的降水以及雪盖融水都进入土壤。第一层的深度是下冠层的根系深度,上层土壤的厚度 d1等于下冠层植被根系平均深度;第二层的深度是上冠层的根系深度,下层土壤厚度 d2从 d1处伸展到上冠层植被根系的平均深度。下冠层一般只从第一层中提取水分,但上冠层能从两层中提取水分;如果土壤达到饱和状态,多余的水分将形成地面径流。土壤蒸散发的计算一般只限制在第一层。该模型的详细描述可参考文献[11,12]。
2.3 水文模型输入和同化实验
DHSVM模型的输入数据包括DEM、土壤类型、土层厚度、植被类型、气象数据、河网/路网分布图和道路/河流分级文件,其中植被和土壤类型数据由中科院资源环境科学数据中心提供。以30 m× 30 m的DEM网格作为所有输入数据的基本网格单元,并利用反距离加权插值法对输入数据进行重采样。将DHSVM模型的输入变量作为栅格图层加入A rcGIS,并将这些栅格图层Grid格式转换成Binary格式,便于DHSVM模型读取和处理。在每个时间步长和每个单元网格上模型会自动运行。DHSVM模型运用许多刻画植被和土壤特征的参数描述地表过程,这些参数主要通过地面实测和文献[13]获得。在本研究中,土壤水分的模拟时间步长为3 h。
基于En KF算法,每隔3 d加入一次实测表层土壤水分数据(0~10 cm),与DHSVM模型模拟进行数据同化。对 En KF而言,模型误差和观测误差的准确估计十分重要,它直接影响着同化效果。然而,观测误差和模型误差随着时间不断变化,而且其影响因素非常多,所以对观测误差和模型误差的量化非常困难。假设本研究中实测土壤水分是精确的,先将DHSVM模型在同化实验之前运行一个月,在初始条件并不是很稳定的条件下,模型自动进行调整而达到平衡,同时获得模型的初始场和初始场误差方差。根据初始场误差方差对土壤水分的初始场进行扰动,产生水文模型的初始状态集合。此外,对站点观测的表层土壤水分进行扰动,增加均值为0、方差为2E-5的随机噪声,生成观测数据的集合,集合数目设为100。通常在En KF算法中,在每个时间步长,最后的状态变量取值由同化预测的集合算术平均值确定。在 En KF同化变权实验中,模型运行的每个时间步长最后的状态变量取值由同化预测的集合变权平均值确定。在进行同化实验的同时,单独运行DHSVM模型,并将其运行结果与等权平均预测、变权平均预测的同化结果相比较。
3 实验结果与分析
首先基于等权平均方法,利用 En KF算法进行同化实验,在不同的时间步长进行集合预报。为了进一步验证将集合离散度作为权重因子的可靠性,对集合离散度和预报误差进行相关分析(图1)。由图1可知,同化后的预报误差随着集合离散度的增大而增大,预报误差与集合离散度之间具有较好的线性相关性(R2=0.7843)。因此,为了提高预报精度,获得更多集合预报的有效信息,将集合离散度作为En KF集合预报的权重因子取平均值是合理的。

图1 预报误差与集合离散度的相关性Fig.1 The relationship between forecast errorsand the ensemble spread
实验采用均方根误差RM SE和平均误差MB E,对2008年5月27日(148 d)—7月10日(190 d)HUAZHA IZI站点模型单独模拟、等权平均预测、变权平均预测结果进行分析,结果如图2和表1。由表1可知,利用等权平均预报和变权平均预报,同化后表层和根区土壤水分的模拟值均方根误差和平均误差均明显降低。此外,对于表层土壤水分而言,一般等权平均和变权平均预报的模拟值的RM SE分别为0.0047和0.0045,MB E分别为-0.0018和-0.0012;对于根区土壤水分而言,等权平均预报和变权平均预报的模拟值的RM SE分别为0.0029和0.0014,M B E分别为-0.0019和-0.0014,变权平均预报的优化效果明显优于等权平均预报。研究表明,在En KF同化更新后,取集合的变权平均值,将实地观测与水文模型同化可以明显改善土壤水分的估测结果,同化使得DHSVM模型输出更接近于实测值。
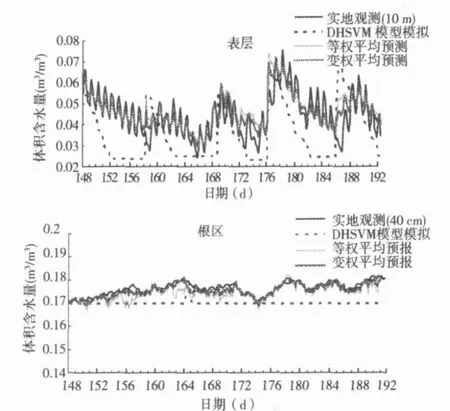
图2 实地观测、DHSVM模型模拟、等权平均预报和变权平均预报同化结果比较Fig.2 Comparisons of field measurement,DHSVM simulation and assim ilation results

表1 土壤水分模拟和同化结果的误差统计Table 1 The soilmoisture errors statistic of simulation and assim ilation results
4 结论
本文提出将集合预报成员不等权重思想与 En-KF相结合的方法,以En KF算法更新后集合成员的离散度作为权重因子,对集合成员权重进行调整,以集合变权平均值作为最后的预报值。研究利用水文过程模型(DHSVM)和实测数据进行土壤水分同化实验,将等权平均和变权平均的预报结果进行比较,结论如下:1)基于En KF算法,将实测数据与水文过程模型(DHSVM)进行同化,利用等权平均法和变权平均法,均可以明显改进单独水文模型模拟的土壤水分结果;2)对于En KF优化后的集合预报结果,集合的离散度和 En KF预报误差具有较好的相关性,随着集合离散度的增加,预报误差也增加,集合离散度可以在一定程度上反映预报的效果;3)利用集合的离散度作为权重因子,将En KF滤波与变权重方法相结合,将不同权重的集合平均值替代原算术平均,可进一步提高集合的平均效果和 En KF的同化效果。本方法对集合数据同化方法具有一定的借鉴作用。
[1] 张学峰,黄大吉,章本照,等.集合数据同化方法的发展与应用概述[J].海洋学研究,2007,25(3):89-96.
[2] ALLEN J I,EKNES M,EVENSEN G.An ensemble Kalman filter with a complex marine ecosystem model:Hindcasting phytoplankton in the Cretan Sea[J].Annals Geophysicae,2002,20: 1-13.
[3] DONG Y N,GU Y Q,OL IVER D S.Sequential assimilation of 4D seismic data for reservoir description using the ensemble Kalman filter[J].Journal of Petroleum Science and Engineering,2006,53(1):83-99.
[4] WALKER J P,W ILLGOOSE G R,KALMA J D.One-dimensional soilmoisture p rofile retrieval by assimilation of near-surface observations:A comparison of retrieval algorithms[J].Advances in Water Resources,2001,24(6):631-650.
[5] HAN X J,L I X.An evaluation of the nonlinear/non-Gaussian filters for the sequential data assimilation[J].Remote Sensing of Environment,2008,112(4):1434-1449.
[6] TOTH Z,ZHU Y J,MARCHOK T.The use of ensemble to identify forecasts with small and large uncertainty[J].Weather Forecasting,2001,16(8):463-477.
[7] HOU TEKAM ER P L.Methods fo r ensemble p rediction[J]. Monthly Weather Review,1995,123:2181-2196.
[8] 段明铿,王盘兴.一种新的集合预报权重平均方法[J].应用气象学报,2006,17(4):488-493.
[9] EVERNSEN G.Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte-Carlo methods to fo recast erro r statistics[J].Journal of Geophysical Research,1994,99 (C5):10143-10162.
[10] BERGERSG,LEEUWEN PJ,EVENSEN G.Analysis scheme in the ensemble Kalman filter[J].Monthly Weather Review, 1998,129:2884-2903.
[11] W IGMOSTA M S,VA IL L,LETTENMA IER D P.A distributed hydrology-vegetation model for complex terrain[J].Water Resource Research,1994,30(6):1665-1679.
[12] W IGMOSTA M S,N IJSSEN B,STORCK P,et al.The Distributed Hydrology Soil Vegetation Model,in Mathematical Models of Small Watershed Hydrology and Applications[M]. Water Resource Publications Littleton CO.,2002.7-42.
[13] 康丽莉,王守荣,顾骏强.分布式水文模型DHSVM对兰江流域径流变化的模拟试验[J].热带气象学报,2008,24(2):176 -182.
A Weighted Average Soil M oisture Assim ilation Experiment Based on Ensemble Kalman Filter
L IU Qian,WANGM ing-yu,ZHAO Ying-shi
(Graduate University of Chinese Academ y of Sciences,Beijing 100049,China)
The arithmetic average of the ensemblemembers is usually taken as the final assimilation result of Ensemble Kalman Filter(EnKF).In this study,theweighted averageof the forecasting ensembleswas used as the assimilated resultof EnKF.The dispersion of the ensemblememberswas considered as the weighting facto r.After the EnKF has analyzed and updated each ensemblemember,the weighted average of the ensemblemembers was adop ted as the final fo recasting results.Since the relationship between the dispersion of ensemblemembers and the forecast errors was significant,taking the dispersion of the ensemble members as the weighting factor was reasonable.Thisapp roach wasexamined based on a soilmoisture assimilation experiment, w hich assimilated the in situ measurements of the surface soil moisture w ith a distributed hydrologic soil vegetation model (DHSVM)using EnKF.The resultsof the weighted averagewere compared w ith the resultsof arithmetic average based on En-KF.This study indicates that the assimilation can be imp roved significantly using the weighted average of ensemble members.
data assimilation;ensemble fo recasting;weight;EnKF;soilmoisture
P208
A
1672-0504(2010)01-0094-04
2009-10-09;
2009-12-10
国家973项目“陆表生态环境要素主被动遥感协同反演理论与方法”(2007CB714407);中国科学院百人计划择优支持项目“流域尺度复杂地质介质地下水污染与水资源安全”
刘茜(1983-),女,博士研究生,主要从事遥感与水文模型的同化研究。*通讯作者E-mail:mwang@gucas.ac.cn
猜你喜欢
电气电子教学学报(2023年5期)2023-11-13 08:43:16
电子产品世界(2023年12期)2023-03-20 10:16:37
湖南大学学报·自然科学版(2021年1期)2021-02-21 08:39:40
系统管理学报(2018年2期)2018-08-13 01:04:28
重庆文理学院学报(社会科学版)(2017年5期)2017-10-23 01:30:23
高原山地气象研究(2016年2期)2016-11-10 06:06:27
西南交通大学学报(2016年3期)2016-06-15 20:29:35
电测与仪表(2016年3期)2016-04-12 00:27:46
安徽师范大学学报(自然科学版)(2015年3期)2015-04-25 02:40:12
塔里木大学学报(2014年3期)2014-03-11 18:47:27
