
加性噪声环境下语音特征参数提取方法的研究
2010-10-24 05:26张昊慧
淮阴师范学院学报(自然科学版) 2010年4期
张昊慧
(1.淮阴师范学院物理与电子电气工程学院,江苏淮安 223300);2.东南大学信息科学与工程学院,江苏南京 210096)
加性噪声环境下语音特征参数提取方法的研究
张昊慧1,2
(1.淮阴师范学院物理与电子电气工程学院,江苏淮安 223300);2.东南大学信息科学与工程学院,江苏南京 210096)
提出一种具有良好抗噪性的语音特征分析方法.将语音信号的短时自相关序列进行时间方向上的平滑处理,然后利用平滑后的序列代替原语音信号进行线性预测分析,从而得到线性预测倒谱系数.实验表明,利用该特征参数的语音识别系统的识别性能优于MEL倒谱系数、LPC倒谱系数等传统的语音特征参数.
短时自相关函数;平滑处理;LPCC
0 引言
经过近半个世纪的研究,语音识别系统在安静的实验室环境下已达到很高的性能,但在实际的带有噪声的环境下,由于训练模型和识别环境的失配,系统的识别性能往往会有较大幅度的下降.为了提高语音识别系统的抗噪性,研究者提出了很多方法,除了对语音识别模型进行噪声补偿等方法外,许多学者致力于研究更具鲁棒性的语音特征.Mansou Juang[1]提出了短时修正的相干系数(SMCC,Short-timeModified Coherence Coefficient)作为语音特征参数.基于人耳的听觉特性,S.B.Davis[2]提出了Mel倒谱系数(MFCC),Y oon K im[2]利用Bark双线性变换得到了基于Bark频率规整的线性预测倒谱系数(LPCC).由于这些参数可近似人耳的听觉特性,所以在无噪环境下可取得较好的识别效果,但抗噪性能较差.
针对这种情况,本文提出一种算法,首先将语音信号的短时自相关序列进行时间方向上的平滑处理,消除加性噪声对语音信号的自相关序列的影响,然后利用平滑后的序列代替原语音信号进行线性预测分析,从而得到线性预测倒谱系数[3].实验表明,该参数在计算量增加不多的情况下既能提高识别性能,又具有较强的抗噪能力.
1 短时自相关序列
首先将观测语音信号分成帧长为M的N帧.由于混入语音的噪声可以是加性的,也可以是非加性的.但考虑到对于非加性噪声,有些可以通过一定变换转化为加性噪声,例如,乘积性噪声、卷积性噪声可以通过同态变换而成为加性噪声.因此本文仅考虑加性噪声的影响.因此,对每一帧语音信号,根据加性噪声模型得:

其中,y(n,m)是观测语音信号分析帧,x(n,m)是纯净语音信号分析帧,r(n,m)是环境加性噪声信号分析帧,M是帧长,N是帧数.在语音信号分析中,为了保证语音信号的短时平稳特性,帧长一般取为10~30ms.
假设噪声与语音信号是不相关的,且噪声是平稳随机信号.含噪语音信号的短时自相关函数为:
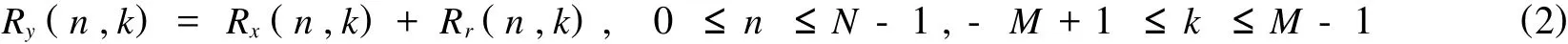
由于短时自相关函数序列是偶对称序列,为了减小数据的冗余,对于(2)式的各项,可以按照(3)式只取其偶序列.

因此,式(2)可写成:

由前面对噪声的假设知:在每一帧语音上,噪声的自相关函数是一个常数,即R′r(n,k)只与k有关而与帧数 n无关,则(4)式可写成:
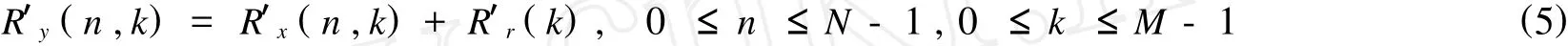
将(5)式两边分别对 n求导可得:
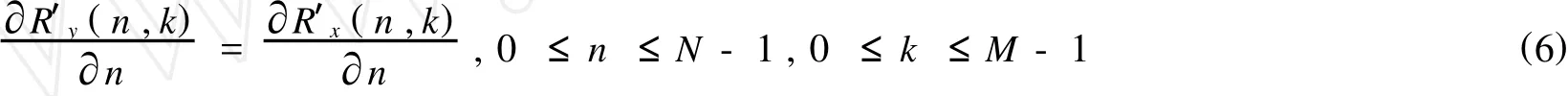
由(6)可知,当噪声与语音信号无关且是平稳的情况下,在每一帧语音内,观测语音信号的短时自相关关于 n求导与纯净语音信号的短时自相关关于n求导相等,而与噪声无关.
2 对短时自相关序列进行时间平滑处理
由于短时自相关序列是离散时间序列,直接利用其一阶差分近似(6)式的各导数项,会引起较大的噪声干扰.下面根据最小均方误差准则[2],由多项式拟合[4]的方法给出其近似公式.R′y(n+t,k)表示经过偏移 t的值,设 R′y(n+t,k),t=-L,-L+1,…,0,1,…,L可以用一个以t为自变量的二次多项式拟合,设二次多项式为g1+g2t+g3t2,则2L+1个短时自相关序列用二次多项式拟合时的总均方误差表示为:

最小均方误差准则就是对式(7)两边分别对 g1,g2.g3求导,并令其等于零,可得:

其中,0≤n≤N-1,
由以上分析可知:
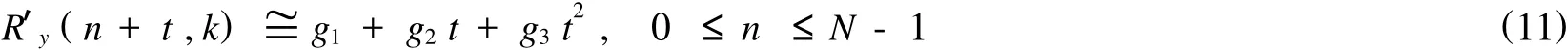
在 t=0时刻的导数为:

根据数字信号处理的原理,由式(12)可求得该变换的转移函数为:

当L=1,2时,式(13)表示的转移函数的幅度响应如图1所示.由图可知,式(13)是一个带通滤波器,L对应通带的个数.根据对噪声的假设,噪声信号的短时自相关函数是直流分量,因此可以通过式(13)得到有效地抑制.同理,当噪声信号的自相关函数序列是一个慢变信号时,也可以通过式(13)得到有效地抑制.综上可知,对短时自相关函数按照式(13)进行滤波处理,既对高频部分进行了平滑处理,又可以有效地消除平稳噪声和慢噪声对语言信号的影响.
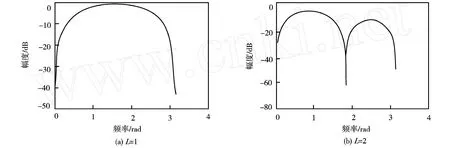
图1 滤波器的幅度响应
3 识别实验和结果
实验是在一个连续隐马尔可夫模型(CHMM)的非特定人汉语数字语音识别系统上完成的.特征参数的阶数、识别系统的状态数和混合密度数分别取12,10和1.语音库为10个男性和10个女性话者0~9的发音,每个数字重复10次,共2000个语音数据,其中一半作为训练集(纯净语音),另一半语音数据按不同信噪比和噪声进行叠加得到含噪语音数据作为测试集.其中噪声采用Noisex-92噪声数据包的白噪声、工厂噪声(慢变噪声)和汽车噪声(平稳噪声).所使用的语音模型均是用纯净的语音训练而成.
语音信号经16 kHz/8bit采样,窗长为32 ms(512点),窗移16ms的汉明窗后,取L=1分别计算采用本算法的LPCC、MFCC和传统的LPCC系数,作为特征参数,在不同信噪比下的识别效果如表1.

表1 本文算法的LPCC、MFCC和传统的LPCC的比较
在无噪环境下,本文算法的LPCC与MFCC具有相当的识别率,且优于传统的LPCC特征参数.在噪声环境下,LPCC与MFCC受噪声的影响比较大,而本文算法的LPCC具有更好的噪声鲁棒性.
4 结束语
提高系统的噪声鲁棒性一直是语音识别领域的研究热点,由于噪声的复杂多变,没有通用的方法,任何参数都有其局限性.本文提出的对语音信号的短时自相关序列进行时间方向上的平滑处理再利用线性预测倒谱系数不仅具有较高的识别率,而且对于平稳随机噪声和慢变噪声具有良好的噪声鲁棒性.
[1] 拉宾纳L R.语音识别的基本原理[M].北京:清华大学出版社,2002.
[2] 赵力.语音信号处理[M].北京:机械工业出版社,2003.
[3] 沈红丽.一种改进的基于倒谱特征的带噪语言端点检测方法[J].通信技术,2009 28(2):156-158.
[4] 董胡,钱盛友.基于小波变换的语音增强方法研究[J].计算机工程与应用,2007,43(31):58-60.
A Study of Speech Features Extraction under Noisy Conditions
(1.School of Physics and Electronic Electrical Engineering,Huaiyin Normal University,Huaian Jiangshu 223300,China)(2.School of Information Science and Engineering,Southeast University,Nanjing 210096,China)
ZHANG Hao-hui1,2
A good anti-noise characteristics of speech analysis is introduced.The idea is to filter the short-time Autocorrelation Sequence of speech.Then frequency warped LPC algorithm is applied to the Sequence instead of the original speech.The recognition experiment shows the feature is more effective than MEL Cepstrum and LPC cepstrum coefficients.
short-time autocorrelation sequence;smoothing;LPCC
TN912
A
1671-6876(2010)04-0318-04
2009-12-28
张昊慧(1979-),女,辽宁锦州人,淮阴师范学院助教,东南大学硕士研究生,研究方向为语音信号处理.
[责任编辑:蒋海龙]
猜你喜欢
阜阳师范大学学报(自然科学版)(2022年1期)2022-04-02
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
系统管理学报(2018年3期)2018-08-13
系统管理学报(2018年2期)2018-08-13
制造技术与机床(2017年11期)2017-12-18
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
