
基于超链接分析的网页正文提取方法
2010-09-14 13:30任翔,刘彬
泰山学院学报 2010年3期
任 翔,刘 彬
(泰山学院信息科学技术学院,山东泰安 271021)
基于超链接分析的网页正文提取方法
任 翔,刘 彬
(泰山学院信息科学技术学院,山东泰安 271021)
随着网络的迅猛发展,w eb服务已经成为研究的热点之一.本文介绍了一种文件类型网页文件的文本信息预处理技术.该方法能够解析网页文件的组成结构,并从中提取出主体文本以供处理.测试表明该方法能快速有效地得到大部分HTML网页的主体部分.
网页正文;w eb服务;超链接
0 引言
1 超链接的作用
人们在设计网页的时候,总是准备了一定的素材,这些素材是设计者希望通过网页传达给访问者的信息.但是由于孤立的网页很难被访问,设计者会增加一些内容来连接不同的页面,例如增加超链接目录或者具有搜索功能的表单等.增加的文字仅仅起向导的作用,内容通常和页面原有的内容不重叠,因而它们的加入会影响网页内容的原貌.
我们把网页设计者为了辅助网站组织而增加的文字定义为“噪声”,把原本要表达的文字素材称为“主题内容”.网页含有指向其它网页的一些超链接文字,它们通常聚集成块,且独立于主题内容,仅仅起向导的作用,这一类正是我们要去除的噪声;网页中含有的超链接文字出现在正文文字中间,具有向导和陈述的双重作用,即它们引向另一个网页的同时也是当前页面主题内容的一部分,如图1所示,姚明和休斯顿火箭这两个超链接可以说明这个网页是介绍NBA火箭队和中国球星姚明的事情的,这两个关键词可以代表网页内容.因此这种超链接是不能去除的,并且对网页描述的意义重大.

图1 超链接示例
2 网页正文提取
2.1 现有的网页正文提取方法
网页文档本身是半结构化或无结构的,其数据结构不规则或不完整,复杂程度远远高于普通的文本文档,其数据结构隐含、模式信息量大、模式变化快.
当前对网页文档的正文提取方法有很多,文献[3]的方法是对于使用同一个模板生成的网页集,找出在该网页集中多次出现的内容,作为冗余内容,而在该网页集中共同出现较少的内容块就是有效的网页正文.实验证明该方法是有效的,但该方法必须局限在基于同一个模板的网页集,而web上的网页模板不计其数,因此该方法显然不够通用.
还有一种比较流行的方法是通过对网页划分为多个块,然后根据某种算法进行取舍,找到正文所在的那个块,提取出来.现在存在多种网页划分成块的方式,如基于DOM的分割[4],基于位置的分割[5],还有V ision-based Page Segm en tation[6].在文献[7]中,作者使用Site Style Tree(SST)来描述网页的版面和内容,并定义了SST中节点的重要程度,通过节点的删剪来得到网页正文.
以上方法都是对HTML语义结构进行分析,找到网页正文所在的位置进行处理,提取出网页的正文.但这些方法对于网页结构出现非常规现象时,效果不好.比如网页的正文极短,而该网页中的广告栏含有的文字量很大,这样会把广告所在的部分当成了正文部分提取出来,造成提取的失败,并且由于加入了HTML语义分析,使得程序处理网页的速度变慢,为了达到准确率高和速度快并存的目标,本文提出了基于超链接分析的网页正文提取方法.
听了陈诚的一番话,胡琏这位只有三十六岁的年轻将军内心很复杂。作为黄埔四期的高材生,他在抗战中屡立战功,从旅长到副师长,一直到现在成为肩扛将星的师长,多少次出生入死,他早已将生死置之度外。此时,他不想多说什么,作为军人,他只有服从命令,忠于职守,即使付出鲜血和生命,只要能够取得胜利,那就是死得其所!想到这儿,他眼含热泪,双脚一并,向陈诚敬了一个标准的军礼,大声说:“请总司令放心,胡琏决心与石牌共存亡,不成功便成仁。”
2.2 网页预处理
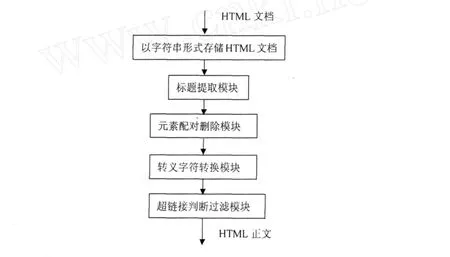
在使用超链接判断之前,先要对网页进行预处理,去掉一些与正文无关的元素,分析如下:
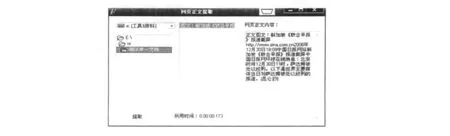
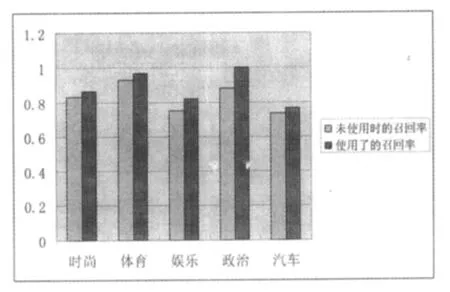
首先是网页正文存放的位置,它是包含在之间,作为某个HTML元素的内容出现的,比如元素的内容.因此我们只需要对有内容的元素进行分析,而那些没有内容只有标签的元素可以删掉.例如注释标签, 对于有内容的HTML元素,例如style和scrip t等元素不包含正文.style元素主要是用来改善网页的显示效果的,它的内容主要是设计网页显示的属性,和网页正文无关;scrip t元素是脚本程序,用来设计动态网页,它的内容也和网页正文无关.因此要将这两个元素删除. 由于style元素,scrip t元素是必须有结束标签的,所以很容易定位这些元素所对应的子字符串在网页文档总字符串s中的位置和长度,但考虑到很多网页的不规范性,为提高程序的容错性能,采用了一种标签配对的方法,将这些要删除的元素各部分补齐,然后再进行匹配删除. 标签配对的方法如下:由于在style元素、scrip t元素的内容中,除了存在注释标签外,不会出现其他的标签,因此从开始标签向后查找,在除注释标签之外的其他标签之前插入结束标签即可完成标签配对. 虽然HTML协议允许出现元素的交叉,即 2.3 基于超链接分析的网页正文提取 利用超链接可以判断网页的正文,我们采用的具体启发式规则如下: ①一篇有主题网页中的正文通常是用成段的文字来描述,中间通常不会加入大量的超链接,而非正文信息通常是伴随着大量超链接出现的. ②正文中的两个超链接之间的文字个数不会太少,而两个广告超链接或导航超链接之间的中文文字个数很少,有时没有,有时只有几个.因此在这里我们对两个超链接之间的中文文字个数设置了一个阈值用来判断是否为正文超链接,通过实验证明,15个字数的区分度较为合适. 本文基于以上的启发式规则,提出了一种超链接判断正文过滤法的新算法.该算法主要思想是通过判断网页中出现的超链接的性质,来判断超链接前后的文字是否是网页正文. 在经过网页预处理后,这时只剩下超链接标签还没有删除,开始对 超链接判断正文过滤法的具体算法如算法1所示: 算法1 超链接判断正文过滤算法 程序流程图如图2所示: 图2 程序模块流程图 超链接判断正文过滤法的程序实现是采用的D elphi7设计的,开发的硬件平台为:pen tium 4 2.4G的CPU,512M内存.为了验证这个新算法的正确性,从各大网站下载了1万张网页进行了实验,并随机抽取了1000张网页的处理结果进行验证,只有少数几个网页没有抽取出正文,经分析发现是由于该网页是一个网站的首页,全部是链接构成的,没有正文部分,故认为程序是正确的.该程序在执行效率上也是很好的,对一个1000字左右的网页抽取正文,平均时间为17毫秒.并且本算法克服了分块算法容易出现的错误,即找错网页正文所在的块.如链接地址为h ttp://new s.sina.com.cn/w/p/2006-12-30/ 180811925138.sh tm l的网页,它的正文部分只有一句话,而与正文无关的广告却占了很大篇幅,这样就会造成网页正文提取的失败,而本算法可以顺利提取出该网页的正文部分.如图3所示: 图3 网页正文提取实例 经过一些有代表性的网站(见表1)测试,我们认为,该方法能有效得到大部分HTML网页的正文部分. 表1 经过测试的网站 为了验证本算法的效果,采用聚类实验来检验.在聚类实验中,准备五类网页,分别为:时尚类、体育类、娱乐类、政治类、汽车类,每类网页数为30.本文做了两组实验,在第一组实验中,没有使用网页正文提取而直接对网页提取特征描述,然后采用遗传算法与k-m eans结合的聚类方法聚类,记录聚类的实验数据.在第二组实验中,先调用本文中的算法来得到网页测试集的正文,然后得到网页的特征描述,最后采用的与第一组相同的聚类方法聚类,记录聚类的实验数据.在这里,本文使用网页的召回率和精确率来描述聚类的结果. 两组实验的数据结果对比如图4、图5所示: 图4 召回率对比 图5 精确率对比 通过图4、图5所做的对比可知,在使用了本算法的第二组数据中,聚类的召回率和精确率都有了改进,特别是精确率有了明显的提高. 网页文档是网上应用最多的文件格式,处理好网页文档对处理网上的信息内容有很大的意义.本文提出了一种网页文档提取正文的方法,该方法通过分析网页中出现的超链接,得到网页的正文.测试表明该方法能有效地得到大部分网页的主体部分.本文中对HTML文件正文提取的方法不仅可以用于提取出HTML文件的主体文本,还可以用于网页的特征提取以及网页的分类、推荐等web服务领域,具有较强的推广应用价值. [1]Tkach D.Technology TextM in ing:Turn ing Inform ation into Know ledge[R].America:AW hite Paper from IBM,1998. [2]Baizilay R,ElhadadM.U sing LexicalChains for Text Summ arization[C].M adrid,Spain:Proceeding of the ACL’97/EACL’97W orkshop on Intelligent Scalable Text Summarization,1997. [3]Sh ianHuaL in,JanM ingHo.D iscovering inform ative contentblocks from W eb documents[C].Edmonton:SIGKDD,2002. [4]Chen J.,Zhou B.,Shi J.,Zhang H.-J.,Q iu F.Function Based ObjectModel TowardsW ebsite Adap tation[C].Hong kong:Procrrdingsof the 10 thW orldW ideW eb conference,2001. [5]KovaceivicM.,D iligentiM.,Gori,M.,M ilutinovic V..Recognition of Common A reas in aW eb Page U sing V isual Information[C]. M aebashi TERRSAA:A possible app lication in a page classification.Proceedings of 2002 IEEE International Conference on Data M ining( ICDMp02),2002. [6]Yu S.,CaiD.,W en J.-R.,M aW.-Y..Imp roving Pseudo Relevance Feedback inW eb Inform ation retrievalUsingW eb Page Segmentation[C].Budapest:Proceedingsof twelfthW orldW ideW eb Conference(WWW 2003),2003. [7]Lan Yi,B ing L iu,XiaoliL i.Elim inatingNoisy Inform ation inW eb Pages forDataM ing[C].W ashington:Proceed ingsof the nin th ACM SIGKDD international conference on Know ledge discovery and datam ining,2003. Research on M a in Tex t Ex traction for Ch ineseW eb Pages Based onW eb Hyper link REN X iang,L IU B in W ith the inc rease of In ternet,w eb service has been the focusof research.The paperp roposes a Chineseweb pagesp rep rocessingm ethod.Them ethod can parsew eb pages,and extract them ain part from theweb pages.The experim ent show s that them ethod is feasib le to parsew eb pages. m ain textofweb pages;web service;hyperlink TP391 A 1672-2590(2010)03-0044-05 2010-03-28 任 翔(1983-),男,山东泰安人,泰山学院信息科学技术学院教师.
,
等就被删除.
3 实验数据及结果


4 结束语
(Schoolof Info rm ation Science and Techno logy,Taishan University,Tai’an,271021,China)
猜你喜欢
传媒论坛(2022年9期)2022-02-17
科学养鱼(2021年6期)2021-11-30
成都信息工程大学学报(2021年6期)2021-02-12
车迷(2018年11期)2018-08-30
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
海峡姐妹(2018年3期)2018-05-09
电子制作(2017年2期)2017-05-17
公民与法治(2016年10期)2016-05-17
