
POM海洋模式的并行算法
2010-09-05 04:00:00李冬刘璟韩桂军张学峰王喜冬
海洋通报 2010年3期
李冬,刘璟,韩桂军,张学峰,王喜冬
(1. 南开大学信息技术科学学院,计算机科学与技术系,天津,300071;2. 国家海洋局国家海洋信息中心,天津,300171)
POM海洋模式的并行算法
李冬1,2,刘璟1,韩桂军2,张学峰2,王喜冬2
(1. 南开大学信息技术科学学院,计算机科学与技术系,天津,300071;2. 国家海洋局国家海洋信息中心,天津,300171)
POM模式目前尚无正式发布的并行版本。通过对POM串行程序的数据流向分析,讨论了POM模式并行化所涉及的关键算法和主要技术问题;并基于消息传递接口(MPI),研发了POM模式的并行版本。测试结果表明,POM并行软件效率较高,达到了业务化要求,业已应用于国家海洋信息中心的再分析业务化系统中。
POM模式;并行算法;MPI;再分析
POM (Princeton Ocean Model) 模式[1]是美国普林斯顿大学发展的三维斜压原始方程海洋模式。国内外许多业务化数值预报和再分析系统都是以POM模式为基础开发的。
近年来,随着业务化系统的需要及计算条件的逐步提高,海洋模式的时空分辨率越来越高。我们多年的研究实践表明,采用POM模式的串行版软件,能够较好的满足潮汐和三维潮流的数值计算时效要求。但若研发再分析、数据同化和数值预报系统,无论从再分析业务化运行时间,数值预报的时效、还是从模式的深入开发调试上讲,POM模式的现有串行版软件均难以满足业务化系统的要求。
遗憾的是,POM模式目前尚无正式发布的并行版本。虽然Internet上可以下载到并行的Cousins版本[2](该版本采用TOPAZ软件开发了MP-POM(Massively Parallel-POM,并已移植到Cray T3E和SGI Origin 2000),但用户的使用情况表明,其计算结果与相应的串行版本的计算结果存在明显差异,不能满足实际应用。同时,三维海洋模式的并行化是极具挑战性的工作,技术难度大,复杂程度高。所有这些,都给使用POM模式的海洋科研工作者带来极大的不便,阻碍了其业务化系统的建设和应用。
本文将讨论POM模式并行化过程中涉及的关键算法和主要技术问题,在对POM模式串行程序进行数据流向分析的基础上,基于消息传递接口(MPI)[3],依托自主开发的基础通信模块,设计并完成了POM模式并行软件的开发。
文章第二部分对POM海洋模式进行简单介绍;第三部分详细讨论POM模式的并行算法、并行程序框架及通信软件模块;第四部分介绍并行程序的测试结果;第五部分给出结论。
2 POM海洋模式简介
POM模式的主要特点为:
(1) 垂向混合系数由二阶湍流闭合模式确定。
(2) 垂向采用σ坐标。
(3) 水平采用正交曲线网格及“Arakawa C”网格。
(4) 水平差分格式采用显格式,垂向差分格式采用隐格式。
(5) 采用自由表面及时间分裂格式;外模式(正压模)为二维,采用较短的时间步长(由CFL条件及外重力波波速决定);内模式(斜压模)为三维,采用较长的时间步长(由CFL条件及内波波速决定)。
(6) 模式包含完整的热力学过程。
3 POM模式并行算法及软件设计
3.1 算法及程序框架
由于POM模式的差分格式,水平方向采用显格式,z方向采用隐格式,因此,在水平方向各格点的计算仅与相邻格点的前面时刻的数据相关。设计POM模式并行化的关键是如何有效地进行重叠区数据的更新。
重叠区数据的更新需要通过与周围相邻进程的通信完成,但若完全依靠通信机制来实现,通信开销太大,严重影响程序的并行效率。我们在对POM模式串行程序进行数据流分析的基础上,将相邻进程通信和本进程的冗余计算相结合来实现重叠区数据的更新,并采用MPI提供的派生数据类型将多变量数据打包在一起更新,极大地降低了通信的开销。简单起见,以一维情形为例,简要说明并行程序的设计思路。假设有如下简单的串行代码:
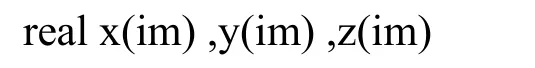
……(此处省略部分代码)
由于计算y(i)时要用到x(i-1)值,计算z(i)时用到y(i+1)和y(i-1),因此改写成并行程序时,每个进程要进行两次重叠区的更新操作(在计算数组y、z之前各进行一次)。
而通过数据流相关分析可知(图1),事实上,每个进程在计算数组y之前,只要更新自己重叠区中的x数组的3个元素(在图中以圆圈标记),之后计算数组y和z的工作就完全在本进程完成,而无需与其它进程通信。与完全通过通信机制进行重叠区的更新相比,这虽然略微增加了本地的冗余计算(计算y时有冗余),但却减少了一次重叠区更新操作。而通过通信进行的重叠区更新具有很大的通信开销(算法见3.2.2),在实际程序中,当大量这样的更新操作被减少时,并行程序的效率会得到显著提高。
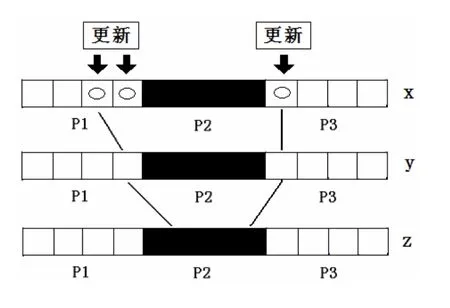
图1 本地冗余计算与进程通信结合实现重叠区更新示意图Fig. 1 Halo regions updated by the combination of processes communicating and local computing
我们将这样的一段代码称之为一个“并行区域”,即通信主要集中于此代码段的入口,而在代码段内部主要是本地计算,几乎不进行(或仅有少量)进程之间的通信。采用本地冗余计算与进程通信相结合的方式进行重叠区的更新,其带来的另一个优点是:由于各变量均于“并行区域”的入口处进行重叠区的更新,因此,可以通过派生数据类型将这些变量打包一并更新,再次显著地减少了并行程序的通信次数,极大地提高了并行效率。
我们在对POM模式串行程序进行数据流向分析的基础上,采用本地冗余计算与通信结合更新重叠区的方式,基于MPI开发了POM并行程序,基本流程见图2。
其中,在内(斜压)、外(正压)模式之间建立了3个“并行区域”,在这些区域中,仅有少量的进程通信,大部分通信集中于它们的入口,通过采用派生数据类型,将需要消息传输的变量一起更新,显著减少了通信次数,提高了并行效率。
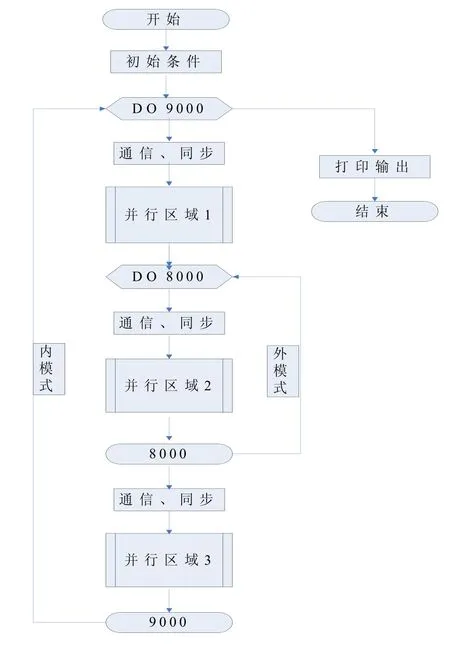
图2 POM并行程序的基本流程图Fig. 2 Flow chart of parallel POM
3.2 通信模块的设计和开发
正确、高效地实现不同进程之间的通信,是并行程序设计要解决的关键问题之一。我们对MPI标准库函数进行了封装,开发了一系列高层的基础通信模块,并依托这些基础通信模块进行POM模式的并行开发工作。
这些基础通信模块包括:区域划分及进程的虚拟拓扑结构模块、数据重叠区更新模块、派生数据类型模块、数据合并及分解模块、I/O接口模块等。
3.2.1 区域划分及进程的虚拟拓扑结构模块根据对POM数值模式的差分格式(水平方向采用显格式,z方向采用隐格式)及其串行程序的数据流向分析,POM并行软件将计算海区按经纬度划分成多个子海区分配给不同的进程。
进行区域划分以后,设计进程的虚拟拓扑结构,对进程进行编号,建立数据和任务与进程之间的映射;同时,为了各进程之间通信的方便,建立进程之间的联系,即每个进程除了记录自己的信息之外,还要记录其周围相邻进程的基本信息。图3是采用16个进程时的进程虚拟拓扑结构示意图,图中的数字表示进程的编号,每个进程只负责自己所管辖海区的计算任务。图中的海区即为基于POM的中国海及邻近海域预报模式的计算区域。
3.2.2 数据重叠区更新模块 基于区域划分的海洋模式并行算法,由于数值计算格式的需要,每个进程在计算过程中不可避免地要用到其周围相邻进程的数据,因此,通常需要在每个进程所负责的计算区域周围建立重叠区(Overlap Areas或Fake Zones、Halo Regions)。本地进程重叠区数据的更新由其周围相邻进程发送,本机接收。对重叠区数据进行正确的更新是保证并行程序结果正确性的关键,重叠区数据更新效率的好坏也直接影响并行程序最终的并行效率。图4为POM模式并行计算软件采用的重叠区更新算法的流程示意图:
(1)非阻塞接收相邻的北部进程发来的数据,以更新本进程的重叠区1;非阻塞接收相邻的南部进程发来的数据,以更新本进程的重叠区2。
(2)阻塞发送本进程计算区域中的北部数据至相邻的北部进程的重叠区2;阻塞发送本进程计算区域中的南部数据至相邻的南部进程的重叠区1。
(3)等待本进程重叠区1和重叠区2数据接收的完成(这是必须的,否则,可能会导致东南、东北、西南、西北四个角处的重叠区数据的错误更新)。但这里并不需要进程之间的同步操作。
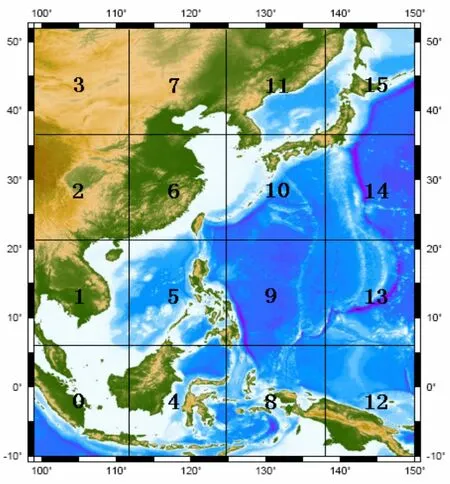
图3 进程虚拟拓扑结构示意图Fig. 3 Virtual topologies of processes
(4)非阻塞接收相邻的西部进程发来的数据,以更新本进程的重叠区3;非阻塞接收相邻的东部进程发来的数据,以更新本进程的重叠区4。
(5)阻塞发送本进程计算区域中的西部数据至相邻的西部进程的重叠区4;阻塞发送本进程计算区域中的东部数据至相邻的东部进程的重叠区3。
(6)等待本进程重叠区3和重叠区4数据接收的完成。
所有的进程同时执行这6个步骤,最后的结果是每个进程的重叠区数据都得到了正确、有效的更新。
另外,重叠区更新模块还包括:沿经度方向进行重叠区更新的模块及沿纬度方向进行重叠区更新的模块。

图4 重叠区更新算法流程示意图Fig. 4 Updating algorithms for hallo regions
3.2.3 派生数据类型模块 POM并行程序中经常要发送和接收内存中非连续分布的数据。如图5所示,假如进程要更新右侧重叠区切块中的海温数据(存放于数组T(i, j, k)中),由于Fortran语言是列优先的,因此,数组T(i, j, k)重叠区中同一层中不同行(如图中标记为1和2的区域)的元素在内存中地址是不连续的,不同层(如图中标记为1、3或2、4的区域)的数据其地址就更不连续。此外,进行重叠区更新时,通常需要更新多个数组变量,如海温、盐度、流速、水位、水深等,不同的变量在内存中当然也不是连续分布的,如果对这些变量分别发送和接收,则会使通信次数显著增加,降低并行效率。
为此,POM并行程序定义了一系列MPI派生数据类型,用以描述程序中经常进行通信的非连续数据在内存中的分布。通过使用这些派生数据类型,可以方便地对数据进行抽取,合并和通信,并且可以将多个不同数据类型的变量一起发送和接收,提高程序的并行效率。此外,在并行I/O中,也经常要利用派生数据类型进行文件的读写。
3.2.4 数据合并及分解模块 设计POM模式并行程序时,需将计算区域进行划分,把数据和计算任务分配给不同的进程。然而,在模式开发及程序的调试过程中,开发者经常需要了解区域数据与全局数据之间的关系;同时,模式的输出也要求对各进程的数据进行合并。因此,设计了数据的合并和分解模块,主要包括如下功能:
(1) 将各进程上的局部数组数据合并为整个计算区域的整体数组数据。这通过对局部数组定义派生数据类型,并利用集合通信中的收集调用来实现。
(2) 将整个计算区域的整体数组数据分解为各个进程上的局部数组数据。这通过对局部数组定义派生数据类型,并利用集合通信中的散发调用来实现。
(3) 点在整个计算区域中的全局坐标转换为其在相应进程中的局地坐标,并返回此进程号及其所管辖区域的起始点坐标。
(4) 点在进程中的局地位置坐标转换为其在整个计算区域中的全局坐标。
3.2.5 并行I/O模块 通过使用自定义派生数据类型、定义文件视图并使用聚合I/O函数实现了POM模式的并行I/O接口模块。
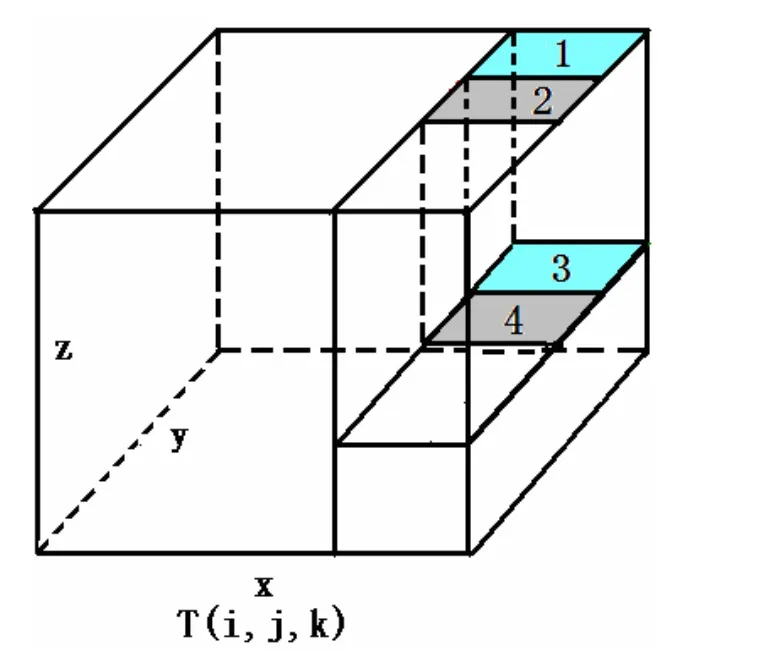
图5 派生数据类型示意图Fig. 5 Derived data type
4 测试结果
我们对中国海及邻近海域的POMgcs模式(POM模式的变种,与POM的区别在于其垂向采用 及z坐标的混合坐标,但并行方案与POM模式完全相同)并行软件在国家海洋信息中心的高性能机群系统上进行了测试。模式的水平网格分辨率为285×307,垂向35层,模式积分时间为3天。表1为性能测试结果;图6为加速比曲线,其中,虚线代表线性(理想)加速比,实线代表实际加速比。
测试结果表明,在并行效果方面,当进程数目不超过48个,POMgcs并行程序的并行效率基本在70%以上;当进程数目不超过20个时,POMgcs并行程序可以保持线性加速比,特别当进程数目在10个以内时出现了超线性加速比现象,这可能是由于高速缓存(cache)的影响,操作系统开销的均摊等原因造成的。当使用的进程数目超过50个后,虽然并行程序仍然保持加速,但不再保持线性加速比,这与测试问题的规模有关。
在结果准确性方面,并行软件的计算结果与串行程序计算结果完全一致。
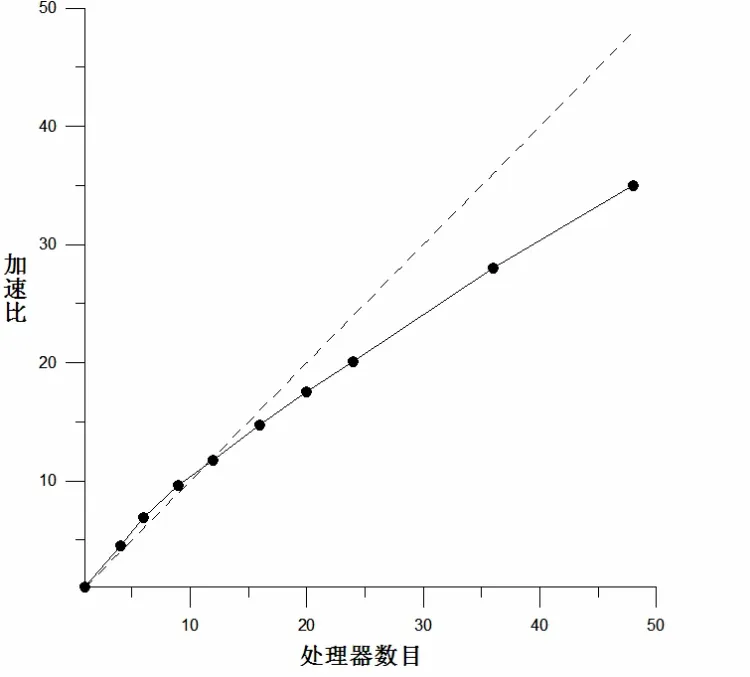
图6 并行程序加速比Fig. 6 Speedup of parallel POM
5 结 语
对POM模式串行程序进行数据流向分析的基础上,采用本地冗余计算与通信结合更新重叠区的方式,基于MPI开发了POM并行程序。经测试,并行软件效率较高,达到了业务化应用要求。目前,国家海洋信息中心已经发布了中国海及邻近海域的23年海洋再分析产品,这在中国海洋界尚数首次,其中POM海洋模式的并行软件的研制成功为保证模式的高效运行起了重要的作用。
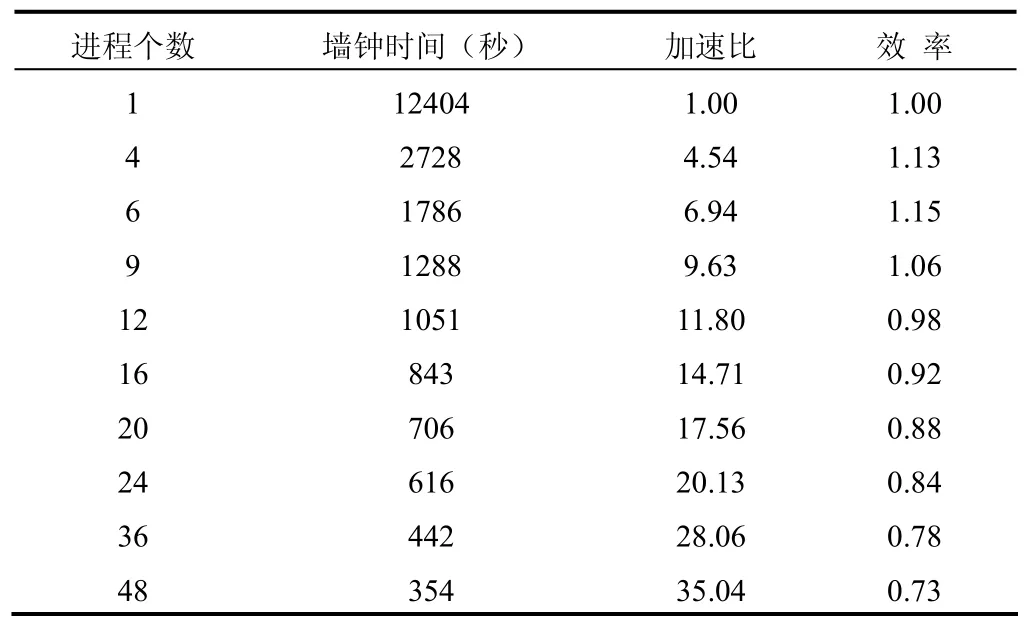
表1 性能测试结果Tab. 1 Results of performance
目前POM模式串行程序,对陆地点和水点做同样的计算,只是将陆地点的计算结果扣除。这其实做了许多冗余计算,使得由此改写的并行程序中许多进程的计算亦有冗余,甚至有的进程的工作完全是冗余的。我们进一步的工作,将只考虑水点的计算,但要设计更好的区域划分算法,以保证进程的负载平衡。
参考文献:
[1] Blumberg A F, Mellor G L. A description of a three-dimensional coastal ocean model [G]. Three dimensional coastal ocean models,N. S. Heaps, Editor, American Geophysical Union, Washington D C,1987: 1-16.
[2] Cousins S, Xue H. Running the Princeton Ocean Model on a Beowulf Cluster [R]. Terrain-Following Coordinates User’s Workshop, Boulder, Colorado, 2001: August 20-22.
[3] MPI: A Message-Passing Interface Standard [S]. Message Passing Interface Forum, 2003.
[4] 张林波, 迟学斌. 并行计算导论 [M]. 清华大学出版社, 2006:268-279.
Parallel algorithms for Princeton Ocean Model
LI Dong1,2, LIU Jing1, HAN Gui-jun2, ZHANG Xue-feng2, WANG Xi-dong2
(1. Department of Computer Science and Technology, College of Information Technical Science, Nankai University, Tianjin 300071, China;2. National Marine Data and Information Service, SOA, Tianjin 300171, China)
There is no officially published edition of parallel POM (Princeton Ocean Model) at the present time. This paper intends to investigate the key algorithms and major techniques in parallelizing the serial code of POM based on data-flow analysis. The parallel edition of POM has been developed using MPI (message passing interface) and its high performance is verified by our experiments. And now, it has been successfully applied to the reanalysis system in NMDIS (National Marine Data and Information Service)
POM; parallel algorithm; MPI; reanalysis
P717;P731.2
A
1001-6932(2010)03-0329-06
2009-11-19;
2009-12-21
国家重点基础研究发展计划课题(2007CB816001)、国家自然科学基金项目(40776016、40906015和40906016)
李冬(1974-),男,博士研究生,副研究员,主要从事海洋数据同化、并行计算及科学数据可视化研究。电子邮箱:lidong2003@gmail.com
猜你喜欢
电脑报(2022年13期)2022-04-12 00:32:38
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
电脑报(2020年24期)2020-07-15 06:12:41
数码世界(2020年5期)2020-06-23 00:14:36
中国外汇(2019年20期)2019-11-25 09:54:58
初中生之友·中旬刊(2015年4期)2015-06-10 09:01:13
民主与科学(2014年3期)2014-02-28 11:23:03
教育与职业(2014年7期)2014-01-21 02:35:04
计算机与网络(2013年1期)2013-06-05 05:31:50
考试周刊(2012年88期)2012-04-29 04:36:47
