
生成PDF417二维条码的应用探讨
2010-06-29 06:10张彬彬
湖南邮电职业技术学院学报 2010年2期
张彬彬
(广东纺织职业技术学院信息工程系,广东佛山 528041)
1 条形码概论
1.1 条形码技术
条形码技术是在计算机技术与信息技术基础之上发展起来的一门融编码、印刷、识别、数据采集和处理于一身的新兴技术。说起自动识别技术就必然要提到条形码,因为它在当今自动识别技术中占有重要的地位。自动识别技术的形成过程是与条形码的发明、使用和发展分不开的。
人们日常见到的印刷在商品包装上的条码是传统条码,这种普通的一维条码自本世纪70年代初期问世以来,很快得到了普及和广泛的应用。一维条码由一组规则排列的条、空和相应的字符组成。条码信息靠条和空的不同宽度和位置来传递,信息量的大小由条码的宽度和印刷的精度来决定的,条码越宽,包含的条和空越多,信息量越大;条码印刷的精度越高,单位长度内可以容纳的条和空也越多,传递的信息里也就越大。这种条码技术只能在一个方向上通过一些“条”与“空”的排列组合来存储信息,所以叫它“一维条码”。这种用条、空组成的数据编码可以供机器识读,而且很容易译成二进制数和十进制数。这些条和空可以由各种不同的组合方法,从而构成不同的图形符号,即各种符号体系,也被称码制,适用于不同场合。
1.2 二维条码的起源
要提高信息密度,一种简明的方法就是减少条码的条高,做出一个很窄很长的条码,然而这种方法并不实用,因为通常遇到的情况是在一个固定面积上印刷出所需信息。这一问题的解决可用两种方法:一是在一维条码基础上向二维条码方向发展;二是采用新的集合形体和结构设计出二维条码码制。在水平和垂直方向的二维空间存储信息的条码,称为二维条码。因为它具有高密度、大容量等特点,所以可以角它来表示数据文件 (包括汉字文件)、图片等。二维条码是各种证件及卡片等大容童、高可靠性信息实现存贮携带并自动识读的最理想的方法。
1.3 二维条码PDF417简介
目前已公布的二维条码码制有很多种,其中的PDF417层叠式条码己经成为国际通用的二维条码而且被定为我国二维条码的标准,作为低成本、高速度的便携数据文件,PDF417在管理、运输、证件识别等方面得到了广泛的应用。
PDF417码是由留美华人王寅敬博士发明的。PDF即是取英文Partable Data File三个单词的首字母的缩写,意为“便携数据文件”。因为组成条码的每一符号字符都是由4个条4个空构成,如果将组成条码的最窄条或空称为一个模块,则上述4个条4个空的总模块数一定为17,所以称为417码或PDF417码,如图1所示。

图1 PDF417二维条码Fig 1 Two-dimensional bar code
PDF417条码可表示数字、字母或二进制数据,也可表示汉字。一个PDF417条码最多容纳1850个字符或1108个字节的二进制数据,如果只表示数字则可达到容纳2710个数字。PDF417的纠错能力分为9级,级别越高,纠正能力越强。由于这种纠错功能,使得污损的条码也可以正确读出。
2 PDF417条码生成模块的设计
PDF417二维条码生成一开始是从SQL数据库来获得输入的原始数据,然后根据国家标准来进行编码。
2.1 数据库的设计
主要是先创建数据库,然后在数据库下建立必需的几个表,并设置好联接及主键等。
例如应用实例“毕业生基本信息管理系统”是先创建“StuBaseInfo”数据库并在数据库下建立了三个表:encouragementandpunishment(奖励惩罚表)、record(成绩表)、student(学生基本信息表),它们之间通过id(学号)列名来建立联接,设置student(学生表)的id(学号)列名为主键。数据库设计如图2所示。
本文研究了基于传感器网络的自适应参数估计问题,提出了一种利用传感器节点1比特测量值的OB-RLS算法。为了降低各节点的能耗、存储资源,以及到中心处理器的通信带宽,首先将各节点采集的测量信号压缩为1比特数据,然后再发送给中心处理器。在中心处理器中,采用文中所提出的OB-RLS算法来获得对感兴趣参数的自适应估计。该算法结合了期望最大化的思想和递归最小二乘方法,相比符号滤波算法和Probit-MLE算法有较低的估计误差和较好的稳定性,且和传统RLS算法估计精度相当。论文通过MATLAB仿真实验,验证了算法的性能。
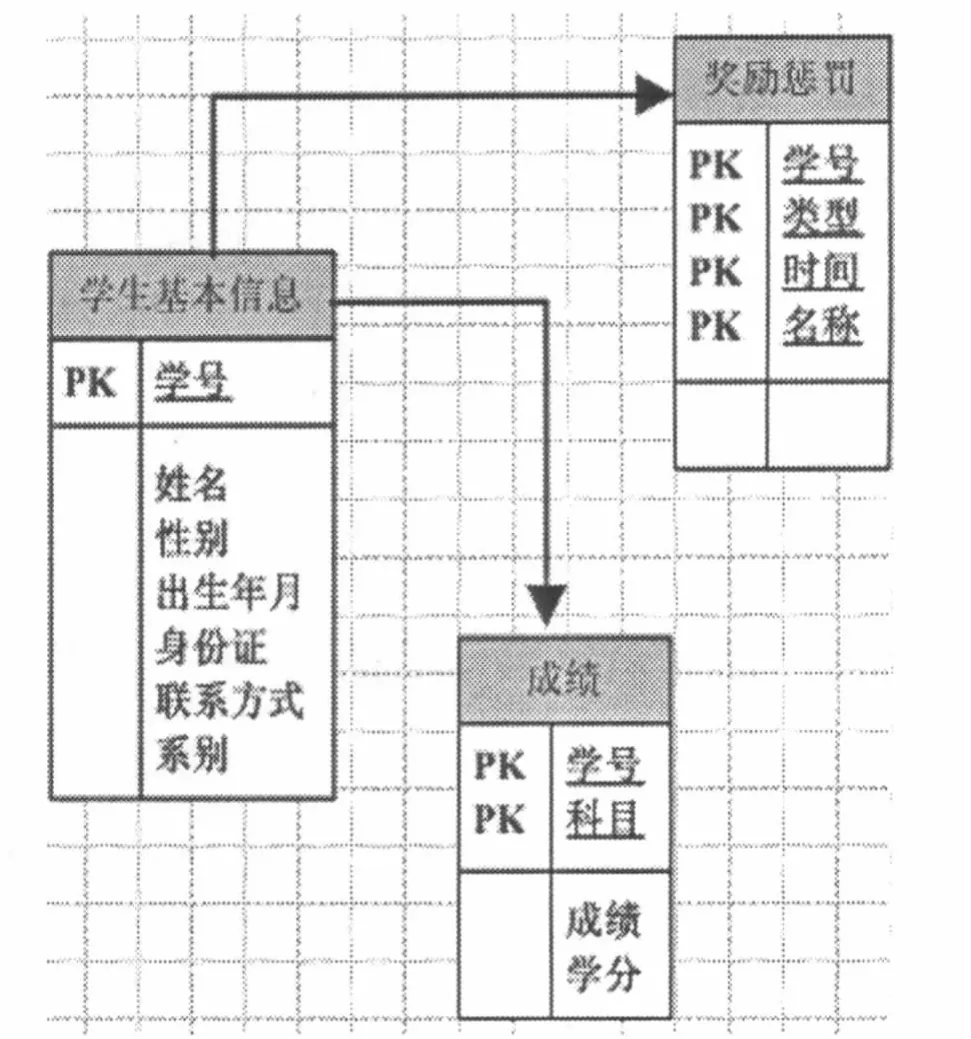
图2 数据库设计Fig 2 The design about database
还要加载数据库,步骤是进入控制面板,再双击管理工具,再双击数据源(ODBC),添加类型选MySQL ODBC 3.51 Driver,对话框中的data source name就输入stubaseinfo,descprition就输入student base information,server就输入localhost,user就输入root,password就输入安装mysql所设的密码,最后在database输入stubaseinfo,设置好后,单出“TEST”按钮进行测试连接是否成功,如果成功就可以了。
2.2 编码算法
当条码矩阵的排列定后,就可以确定左、右行指示符号字符,加上起始符、终止符,然后调用符号字符的码字集,就可以把条码符号生成出来。
1)编码算法流程。本系统的实现严格按照国家标准实现,对其中的文本模式下子模式的锁定和转换的混合型模式到标点型模式的锁定和转换做了个约定,就是如果在混合型子模式下遇到连续3个以上的标点型子模式就锁定为标点型子模式,否则(暂时)转换为标点型子模式。行高:对于已经达到推荐的最低错误纠正等级的PDF417条码符号推荐最小行高为3X。否则为4X。
2)编码细节。文本字模式间的转换与锁定:
第一,如果一段文本串开头默认锁定在ALPHA子模式。遇到单字节字符就用前导码字BYTESHIFT并且如果前面只有奇数个字符被填充的话在BYTESHIFT前加个辅助字符AL或PS。
第三,其他子模式下遇到PUNCTUATION字符后先判断是否有连续3个以上的PUNCTUATION字符,如果有则锁定到PUNCTUATION子模式,并且如果前面的模式是MIXED则用PL作前导字符,其他两种则用ML+PL作前导字符。如果没有第3个以上则不用锁定而只是加上一个PS作为前导。PUNCTUATION模式下遇到其他子模式的字符则先锁定到ALPHA子模式,加前导字符PAL,然后再按在ALPHA子模式下处理该字符。
第四,其他子模式下遇到LOWER字符都要锁定为LOWER子模式并加上前导字符LL。
第五,其他子模式下遇到MIXED字符都要锁定为MIXED子模式并加前导字符ML。其他子模式下遇到ALPHA字符,如果是LOWER则看看是不是有连续3个以上,如果有则锁定到ALPHA子模式并加前导字符ML+AL,否则不用锁定到ALPHA子模式,只需加前导字符AS。如果是MIXED则锁定到ALPHA子模式下并加前导字符AL。
附上辅助字符和前导字符的值:BYTESHIFT 913,PL 25,LL 27,AL 28,ML 28,AS 27,PS 29,PAL 29。
另外,由于必须对输入的数据进行一定的格式处理,也就是用我们自定义的格式来处理为我们想要的数据流。本系统采用类似于网络链路层通信的那种解决冲突的办法来格式化数据流,也就是说,用ESC(0x1B)作为某些个特殊数据的前导符,而ESC则用ESC+ESC来表示,数据逻辑分段(项目分段)用ESC+某些标志符来标记。
标志符如下:项目开始(标头开始)ESC+0x01;项目结束(内容结束)时用ESC+0x02;项目标头结束(内容开始)ESC+0x03。项目支持列表,也就是说,内容可以多项,每一项以ESC+0x01开头和以ESC+0x02结尾。
2.3 条码生成的关键函数说明
1) GetRecord(CString studentID)连接数据库StuBaseInfo,可以用语句:db.Open(NULL,FALSE,FALSE,"ODBC;DSN=StuBaseInfo;UID=root;PWD=b");根据学号获得学生记录。
2) void code(ppdf417 p):该函数的功能由以下几个函数构成。
Void breaktext(ppdf417 p,parraylist list):分段时以数字串为分段的点,先查找长度大于13的连续数字串,然后对第一段数字串前面的字符串(如果有的话)、两个数字串之间的字符串和最后一个数字串后的字符串进行分段。然后再对合并相邻的一些段试压缩编码的效率更高。段合并的情况如下:两个文本串中间一个单字节的字节串合并为一个文本串;一个长文本串和相邻的文本串或者单字节的字节串合并为一个文本串;一个长字节串和相邻的短文本串或者另一个字节串合并为一个字节串。最后如果只有一个长度大于或等于8的文本串就将其当作一个数字串处理。
void assemble(ppdf417 p,parraylist list):按一段一段来压缩编码,根据压缩编码类型分为以下3种(前导码字见源代码)。
void textcompaction(ppdf417 p,int start,int length):文本压缩模式是最复杂的一种压缩编码方式,它有4种子模式,并且要处理文本串里夹杂的单字节。文本压缩模式最终要的是处理好怎样标识各种子模式的转换与锁定。数据压缩上,一个单字节用一个码字编码。而其他数据则两个字符压缩编码为一个码字。
void numbercompaction(ppdf417 p,int start,int length):数字压缩模式即把10进制转换为900进制以44个数字为单位进行压缩。加上前导数字1刚好45个字符压缩为15个码字。剩余的数字同样加个前导数字1再压缩。大概就是3个数字压缩为一个码字。
void bytecompaction(ppdf417 p,int start,int length):字节压缩模式即把256进制转换为900进制。以6个字节为单位压缩为5个码字。不足6个部分按一个字节一个码字编码。
void calculatecorrectioncodewords(ppdf417 p,int dest):是根据错误控制码算法:Reed-Solomon来编码的。
void fillpad(ppdf417 p,intdest): 用TEXT_MODE码字填充。
void generatepdf417image(ppdf417 p):先填充整个图像的左空白区和右空白区。然后一行一行填充,每一行先填充开始pattern、计算并填充左行指示符pattern、接着逐个填充该行码字的pattern、最后计算并填充右行指示符pattern和结束pattern。并把这一行像素点同样填充HeightOfBar行。
2.4 主要代码


[1]陈晓平.条码印制技术[M].北京:清华大学出版社,1995.
[2]中国物品编码中心.条码技术与应用[M].北京:清华大学出版社,2003.
[3]黄志建,顾向阳,戴钧陶.条形码技术及应用[M].北京:机械工业出版社,1992.
[4]齐舒创作室.VC++6.0开发技巧及实例剖析[M].北京:清华大学出版社,1999.
[5]矫云起,张承海.二维条码技术[M].北京:中国物价出版社,1996.
[6]黄以群,董湘陵.条形码技术[M].北京:国防工业出版社,1991.
[7]黄汉如.用PDF417条码管理运费抵扣发票初探[J].条码信息系统,2004,(1).
[8]宋杜生,钟燕.铁路行包无凭证提取的条码信息加密研究[J].条码信息系统,2001,(1):8-10.
[9]张铎,王耀球.条码技术与电子数据交换[M].北京:中国铁道出版社,1998.125-126.
[10]王庆有.图象传感器应用技术[M].北京:电子工业出版社,2003.247-267.
[11]潘松.EDA技术实用教程[M].北京:科学出版社,2002.24.
[12]宋万杰,罗丰,吴顺君.CPLD技术及其应用[M].西安:西安电子科技大学出版社,1999.76-77.
[13]辛春艳.VHDL硬件描叙语言[M].北京:国防工业出版社,2002.114.
[14]侯伯亨.VHDL硬件描叙语言与数字逻辑电路[M].西安:西安电子科技大学,1999.203-204.
[15]赵亮.单片机C语言编程与实例[M].北京:人民邮电出版社,2003.144-145,207-209.
[16]杨小平.Visual C++项目案例导航[M].北京:科学出版社,2002.
[17]戴扬.PDF417纠错码原理及实现[J].吉林大学学报,2004,(2).
[18]薛红.条码技术[M].北京:中国轻工业出版社,2007.
猜你喜欢
条码与信息系统(2021年1期)2021-12-05
商品与质量(2020年46期)2020-11-26
条码与信息系统(2020年5期)2020-06-07
福建基础教育研究(2020年1期)2020-05-28
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
网络安全与数据管理(2018年8期)2018-08-27
扬子江(2018年1期)2018-01-26
广东通信技术(2016年9期)2016-10-25
电测与仪表(2014年16期)2014-04-22
