
正则表达式在汉英对照中国文化术语抽取中应用
2010-06-05 09:43姚振军黄德根纪翔宇
大连理工大学学报 2010年2期
姚振军, 黄德根, 纪翔宇
(1.大连理工大学计算机科学与技术学院,辽宁大连 116024;2.东北财经大学国际商务外语学院,辽宁大连 116024)
0 引 言
当前对于正则表达式的研究集中于3个方面:一是应用正则表达式解决实际问题,即基于正则表达式的深度包检测算法[1],对专利信息提取[2],对Web数据提取[3],编程题自动阅卷[4]以及电子政务客户端认证[5],设计基于正则表达式的关系数据库模式生成算法和通用抽取与组装算法[6];二是通过对正则表达式语句的优化来提高匹配效率[7];三是集中于正则表达式引擎的优化,通过将NFA转化为DFA引擎来提高匹配效率[1、8].此外,还存在对于模式匹配算法及优化的研究[9、10].
本文的研究背景是设计一个基于网络的汉英对照的中国文化术语词典,在建设词典过程中,需要建立一个中国文化术语汉英对照词库.使用计算机自动完成从异构的现有的典籍英译文献中抽取汉语典籍词汇以及与之对应的英文翻译成为快速扩充词库的最好手段.这个抽取面临的问题主要有两个:其一,实现具有特定模式的文本的匹配,即在文献中快速找出汉语典籍词汇以及与之对应的英文翻译;其二,面对来源广泛的文献,每种文献的目标抽取文本的模式略有不同,要保证程序的通用性.针对这两个问题,本文选择正则表达式来实现目标文本的匹配,首先,正则表达式是用于模式匹配的专用语言;其次,针对不同的模式,正则表达式可以灵活地构造不同的专用语言来实现模式匹配.所以,正则表达式可以很好解决项目中词库建立的问题.
在使用正则表达式实现词汇抽取的过程中,本研究通过简化正则表达式规则来提高正则表达式运行效率,通过设计正则表达式生成器来降低正则表达式的使用难度.
1 正则表达式及其元字符简述
正则表达式是一个用来描述或者匹配一系列符合某个模式的字符串的单个字符串.许多文本编辑器软件(比如Unix上的编辑器ed)以及软件开发语言(比如Java语言有Jakarta-ORO正则表达式库来提供使用正则表达式的API,脚本语言JavaScript也提供函数处理正则表达式)都使用正则表达式处理文本字符串,通过正则表达式将字符串中符合某一模式的文本进行查找和替换.一个正则表达式用来描述一种模式,如M[AI]KE这个正则表达式就可以描述MIKE、MAKE这两个单词的模式.目前应用中通用的正则表达式规则中元字符部分如表1所示.

表1 通用的正则表达式部分元字符Tab.1 Part of themeta-characters o f regular exp ression
由表1可知,在通用的正则表达式规则中元字符有11个,为了处理这些元字符,正则表达式处理程序中至少要出现11个判断语句,即正则表达式中的一个字符可能要经过11次判断才能断定与待搜索文本中对应字符是否匹配,所以,现有的正则表达式软件包都非常庞大.grep中的代码长度超过500行(大约10页书的文字长度),并且在代码周围还有复杂的上下文环境[1].Java中开源的正则表达式处理包则更为庞大,比如Jakarta-ORO包就有65.7 kb.这是因为这些软件包要综合考虑灵活性、通用性、运行速度以及各种复杂的应用环境.
2 正则表达式规则简化方案
2.1 具体方案
在使用标准正则表达式过程中,如果用户希望在完成文本匹配时实现效率的提升,唯一的办法是通过先分析待检索的文本的特性,然后写出符合待检索文本模式的正则表达式字符串.这样做可以在降低一部分匹配正确率的基础上提高程序的运行效率.比如针对通用的 HTTP URL:http://hostname/path.htm l,其对应的简单正则表达式为http://[ ]*.htm l?很明显,对于一般的URL,这条正则表达式可以匹配,但是对于形如http://.../.htm l的URL,该正则表达式也可以匹配,所以如果用户可以确认预搜索的文本中不含有形如http://.../.htm l的URL,就可以使用上面这种简单的正则表达式实现对目标文本中URL的匹配.
不过上述方法对于效率的提升空间是有限的,由上章可知,通用的正则表达式的元字符有11个,有很多时间会花费在元字符的判断上,如果可以根据需要减少元字符个数,对于正则表达式效率上的提升将是巨大的.
本文提出的解决办法,是根据待搜索文本的实际情况,选择使用元字符,建立符合特定需要的正则表达式.项目中各种不同来源的中国文化术语及其翻译的结构格式一般为“儒林外史(The Scholars)”;“儒 林外史 The Scholars” ;“(The Scholars)儒林外史”.抽象成模式为“中文词组(英文词组)”;“中文词组 英文词组”;“(英文词组)中文词组”.项目中的文本匹配中只要处理中文字符和英文字符,模式中出现的其他符号只要原样匹配,就建立了简化的正则表达式模型,如表2所示.

表2 简化方案元字符表Tab.2 The meta-characters of the simp lified regular expression
本项目的重点不是通用性,而是运行效率,所以项目选择使用自行设计正则表达式程序来处理模式匹配,这样做虽然降低了正则表达式通用性,但是与使用标准的Java正则表达式软件包相比,系统处理特定模式文本的效率更高.与标准的规则相比,这个简化版的规则将元字符的个数精简到3个.
2.2 方案程序实现
match()函数采用递进的方式在目标字符串中进行模式匹配.match中textpos的值会以步长1自加,从而遍历一遍字符串.″matchhere()==1″这句是调用matchhere函数执行匹配操作,通过返回值判断是否找到一个匹配的模式文本的.如果找到,则打印模式匹配到的文本;如果没找到 ,执行语句″if(regepos>0)textpos--;″这条语句用来控制对于目标字符串的递进操作回溯.逻辑上,如果字符串与正则表达式在除了第一个字符外的某个位置上发生不匹配,则新的匹配应在字符串中发生不匹配的位置重新开始;但是如果字符串与正则表达式在第一个字符处发生不匹配,则新的模式匹配应该从字符串中不匹配发生的下一个位置重新开始.这句代码就是实现这个逻辑,通过判断匹配不成功时正则表达式进行到的位置来控制目标字符串中匹配重新开始的位置,通过将regepos归0来表示模式匹配重新开始,将textpos增1表示从下一个位置开始新的匹配.
matchhere()是完成匹配操作的函数.第1个判断是这个递归函数的结束条件之一,如果对正则表达式的遍历完成,则说明1次模式匹配操作成功结束,找到1条匹配的模式文本,函数返回值为1.第2个判断是第2个结束条件,判断字符串是否结束,这个判断中还有一个子判断:如果字符串结束而且正则表达式遍历到最后一位则说明找到一个匹配文本,返回值为1,否则返回值为0.第3个判断是对″*″号操作,根据模型,″*″这个符号表示匹配正则表达式中前一个字符的0个或者多个出现,这个判断中会调用matchstar()函数.matchstar(c,rege,text)将字符串与c所对应的符号进行尽可能多的匹配.在matchstar()中,首先判断c是中文字符还是英文字符,然后将当前指向的字符串字符与c匹配,如果匹配,则通过递归调用matchhere()函数来对c与字符串中下一个字符匹配;如果不匹配,说明对c的尽可能多的匹配已经完成,正则表达式会递进到下一位.第4个判断是原样字符匹配,如果正则表达式中当前字符不是特殊字符,就进行原样字符匹配,然后通过递归调用matchhere()函数开始下一个位置的匹配.第5个判断是对于中文字符的匹配.第6个判断是对于英文字符的匹配.这个函数是一个递归函数,通过自调用来实现一次完整模式匹配操作,函数中通过textpos来控制目标字符串中当前指向字符的位置,regepos来控制正则表达式中当前指向字符的位置,这两个变量是全局变量,保证了模式匹配的操作在全局范围是统一的.
3 正则表达式生成器
3.1 正则表达式可读性问题的提出
比如模式″中文词组(英文词组)″,用标准正则表达式描述为″[ u4e00- u9fa5]*([A-Zaz]*)″,用项目中的正则表达式描述为″#*(@*)″.由此可见,不论是标准的正则表达式,还是项目中的,都是不可读的,一个没有使用正则表达式经验的人不知道正则表达式文本的含义,也就更谈不上使用正则表达式了.正则表达式的书写需要书写者熟悉正则表达式的语法规则,同时要具有一定的计算机知识(比如用户要知道汉字以UTF-8编码表示的范围是4e00到9fa5).虽然项目使用的正则表达式规则简单,但是″#*(@*)″这样不易理解的描述仍然让用户手足无措,如何让普通的、不具有专业知识的用户书写符合规范的正则表达式文本是正则表达式使用中的难题.
正则表达式生成器即是针对正则表达式可读性差、难以使用的问题提出的.生成器的基本思想是:首先,用户将一个待搜索文本的例子输入系统;然后,系统将这个例子的模式分析出来,转换成标准的正则表达式;最后使用上一步得到的正则表达式文本到目标字符串中去模式匹配.比如说,用户只需要输入XXX,系统会自动学习将输入的文本转换成正则表达式YYY,这样就ZZZ.这种生成器的实际应用比较简单,主要原因有两个:其一,项目使用的正则表达式规则简单,表达式元字符少且含义简单;其二,项目设计针对的目标模式相对固定,结构简单.
3.2 正则表达式生成器程序流程
图1描述了程序如何从一段作为示例的文本中自动提取模式的过程,这个图做了一定的简化,省略了对目标字符串的遍历过程.程序完全使用Java的基本包编写,不用添加任何Java扩展包.通过″if(text[i]>=0x4e00&&text[i]<=0x9fa5)″这句代码判断当前例子中指向字符是否为中文,Java中对于字符是按照UTF-8编码进行处理的,汉字在UTF-8码中的范围是16进制的4e00到9fa5.″match+=″#*″是在正则表达式中添加代表汉字的特殊字符以及″*″,加上″*″说明汉字字符可以重复出现.例如用户输入一个例子″中国(China)″,系统会将这个例子转换成系统可以识别的正则表达式″#*(@*)″;又比如用户输入的例子是″美国the USA″,系统会识别例子,抽象出对应的正则表达式″#*@*″.如此,用户就可以在不了解正则表达式规则的情况下使用正则表达式来工作.
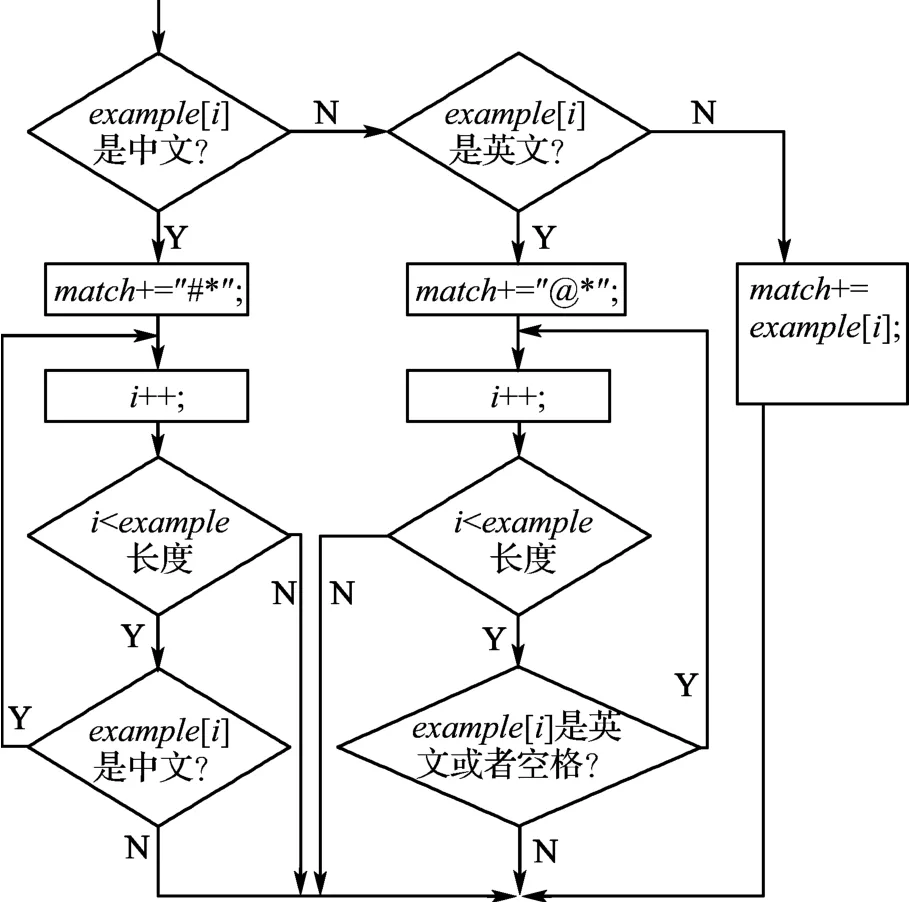
图1 正则表达式生成器流程图Fig.1 The flow chart of the generating engine of regular exp ression
4 实验结果与讨论
本项目中的实验样本选自由中华人民共和国教育部主管,高等教育出版社与施普林格(Springer)公司共同创立的“中国学术前沿期刊网”中的“文学研究前沿”(Frontiers of Literary Studies in China)部分的.pdf格式的文章.样本1:The eastw ard transition of Chinese cu lture in the Eastern Han Dynasty and the north-south difference of scholarship &literature in the Eastern Jin,Southern and Northern Dynasties,该样本中中国文化术语在文中的格式为“中文术语(英文翻译)”.运用本项目中设计的正则表达式系统进行匹配,使用的正则表达式为″#*(@*)″,匹配时间为16~32m s,正确抽取177个中英文对照的词条;使用Java自带的正则表达式进行处理,其正则表达式为″([ u4e00- u9fa5])+{2,2}([(][a-zA-z]+[)])″,时间为47 ~ 68 m s,正确抽取177个中英文对照的词条.样本2:M etal typography, stone lithography and the dissemination of M ing-Qing popular fictions in Shanghaibetween 1874 and 1911,运用本项目中设计的正则表达式系统进行匹配,使用的正则表达式为″#*(@*)″,匹配时间为 15 ~ 16 ms,正确抽取65个中英文对照的词条;使用Java自带的正则表达式进行处理,其正则表达式为″([ u4e00- u9fa5])+{2,2}([(][a-zA-z]+[)])″,时间为16~31m s,正确抽取65个中英文对照的词条.从时间上看,本研究中设计的系统可以将抽取效率提高1倍左右,正确率可以达到100%.
同时,采用本项目中的正则表达式系统,用户在使用时不用书写复杂的正则表达式,只要将一个目标文本的例子输入系统,系统就可以自动生成目标正则表达式.比如上面的应用,用户只要输入″红楼梦(A Dream of Red M ansions)″,系统就可以生成″#*(@*)″,并用生成的正则表达式在目标典籍中匹配目标文本.
5 结 语
本文提出了结合应用需求,通过简化正则表达式的规则来提高正则表达式在特定应用需求中文本匹配效率的思想,并通过程序证明了这种提高的可能性.通过精简元字符的个数,提高了正则表达式对特定数据库中的文本处理的速度,在对大数据量处理时,本文的方法就会有良好的效果.同时通过正则表达式生成器,尝试解决正则表达式应用过程中可读性差、用户使用难度大的问题.本研究下一步将提高项目中正则表达式应用系统代码效率,以及在全规则的正则表达式系统中进行符合用户需求的正则表达式生成器设计来降低用户使用难度.
[1]丁 晶,陈晓岚,吴 萍.基于正则表达式的深度包检测算法[J].计算机应用,2007,27(9):2185-2186
[2]邱清盈,郑国民,冯培恩,等.基于正则表达式的专利信息提取方法研究[J].中国机械工程,2007,18(10):2326-2329
[3]刘松业.正则表达式的W eb数据提取研究[J].电脑编程技巧与维护,2008,16(16):89-91
[4]佘石泉,周肆清.正则表达式在编程题自动阅卷中的应用[J].计算机技术与发展,2007,17(7):224-246
[5]王功明,吴华瑞,赵春江,等.正则表达式在电子政务客户端校验中的应用[J].计算机工程,2007,33(9):269-271
[6]邓绪斌,朱扬勇.ReDE:一个基于正则表达式的生物数据抽取方法[J].计算机研究与发展,2005,42(12):2184-2191
[7]葛汉强,陈和平.Java正则表达式优化[J].计算机系统应用,2008,17(9):102-104
[8]王 艳,李冬梅.基于正则表达式的协议识别方案[J].软件导刊,2009,8(2):47-49
[9]陈曙晖,苏金树,范慧萍,等.一种基于深度报文检测的FSM状态表压缩技术[J].计算机研究与发展,2008,45(8):1299-1305
[10]李伟男,鄂跃鹏,葛敬国,等.多模式匹配算法及硬件实现[J].软件学报,2006,17(12):2403-2415
猜你喜欢
无线互联科技(2020年11期)2020-12-01
电子制作(2019年13期)2020-01-14
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
山东工业技术(2015年21期)2015-07-27
高中生学习·高三版(2014年3期)2014-04-29
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
网络安全与数据管理(2011年17期)2011-07-25
