
基于Stacking组合分类方法的中文情感分类研究
2010-06-05 03:23李寿山黄居仁
中文信息学报 2010年5期
李寿山,黄居仁
(香港理工大学 中文及双语学系,中国 香港)
1 引言
目前,人们越来越习惯于在网络上表达自己的观点和情感。网络上出现了大量的带有情感信息的文本,这些情感文本以商品评论、论坛评论、博客等形式存在。面对这些越来越多表达情感信息的文本,传统的基于主题的文本分类系统已经不能满足人们的需求,迫切需要对这些情感文本进行研究和分析。情感文本分类即是在这种氛围下产生的一种特殊的文本分类任务,该任务按照表达的情感倾向性对文本进行分类[1]。例如,判断文本对某个事物的评论是“好”还是“坏”。该任务的研究历史虽然不长,但是已经成为自然语言处理方向里面的一个研究热点。尤其是近几年在自然语言处理相关国际顶级会议上(ACL、EMNLP、SIGIR、WWW等)涌现出了大量的文章。目前,该方向的研究主要不仅仅是在英文方面,中文情感文本分类的研究也得到了迅速的发展,例如,文献[2-4]。
针对情感分类任务,目前主流的方法是基于机器学习的分类方法,该方法利用统计机器学习分类方法学习标注样本,然后用学习好的分类器测试非标注样本。这种方法在性能上比其他的基于规则的方法有着明显的优势[1]。不过,机器学习方法中存在多种不同的分类方法,选择合适的分类方法便成为情感分类研究中的一个重点问题。文献[4]首先采用机器学习方法进行英文文本(电影评论)的情感分类研究,文中给出三种不同的分类方法,分别为朴素贝叶斯(Naive Bayes,NB),最大熵(Maximum Entropy,ME)和支持向量机(Support Vector Machines, SVM)。他们的研究结果发现大部分的情况下SVM取得的分类效果最好。后续的许多研究工作都是基于SVM的分类方法进行展开的,例如,文献[5-6]。对于中文文本的情感分类研究,文献[8]采用K-近邻(KNN),感知器Winnow,NB和SVM四种分类方法对来自不同领域的评论文本进行分类,实验结果发现SVM在所有领域都取得了最好的分类效果。文献[9]也有类似的结论,不过实验结果中SVM的分类效果没有非常大的优势,而且在利用不同的特征时,SVM的效果有时候会差于其他分类方法。然而,文献[10]给出了的结论与上面的文章不是很一致,该文发现如果利用二元(Bigram)词特征或者单字特征的时候,NB的分类效果是最好的。因此,我们可以认为SVM分类是情感文本分类任务中表现比较好的分类方法,但是该方法不可能在所有领域所有特征集合下取得最好的分类效果。
本文将采用四种不同的分类方法,即朴素贝叶斯,最大熵,支持向量机和随机梯度下降线性分类方法对中文情感文本分类进行研究。本文的重点不是比较这四种方法的分类表现。我们相信不同的领域或者不同的特征可能需要不一样的分类方法才能取得最好的分类效果。因此,我们的目标是应用组合分类方法组合这四种方法,考察组合后的方法能否获得比最好分类方法更好的分类效果。
本文的其余部分如下安排:第2节详细介绍各种分类方法在情感分类上面的应用;第3节给出基于Stacking的组合分类器方法;第4节是实验结果和分析;最后一节是本文的结论和将来的一些工作。
2 统计情感文本分类方法
2.1 朴素贝叶斯(Naive Bayes,NB)
该方法的基本思想是利用特征项和分类的联合概率来估计给定文档的分类概率[11]。朴素贝叶斯假设文本是基于词的Unigram模型,即文本中词的出现依赖于文本类别,但不依赖于其他词及文本的长度,也就是说,词与词之间是独立的。文档一般采用DF向量表示法,即文档向量的分量为一个布尔值:0表示相应的单词在该文档中未出现,1表示出现。则文档d属于类c文档的概率为:
(1)
其中,
(2)
其中,P(d(t)|c)是对在c类文档中特征t出现的条件概率的拉普拉斯估计,N(d(t)|c)是c类文档中特征t出现的文档数,|dc|为c类文档所包含的文档的数目。对于情感文本分类,c∈{-1, 1},分别表示负面(贬)或者正面(褒)。
2.2 最大熵(Maximum Entropy,ME)
最大熵分类方法是基于最大熵信息理论,其基本思想是为所有已知的因素建立模型,而把所有未知的因素排除在外。也就是说,要找到一种概率分布,满足所有已知的事实,但是让未知的因素最随机化。相对于朴素贝叶斯方法,该方法最大的特点就是不需要满足特征与特征之间的条件独立。因此,该方法适合融合各种不一样的特征,而无需考虑它们之间的影响。
在最大熵模型下,预测条件概率P(c|d)的公式如下:
(3)
其中,Z(d)是归一化因子。Fi,c是特征函数,定义为:

(4)
在做情感分类的时候,我们用的特征主要是词特征是否出现在某个文档里并属于某个类别。
2.3 支持向量机(Support Vector Machines,SVM)
该方法主要是用于解决二元分类模式识别问题,它的基本思想是在向量空间中找到一个决策平面(Decision surface),这个平面能“最好”地分割两个分类中的数据点[12]。支持向量机的核心思想就是要在训练集中找到具有最大类间界限的决策平面。

2.4 随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降是一种线性分类方法[13],即f(d)=wTd。其中d是文档的向量表示。该分类方法的训练目标就是求得最佳的参数w如下:
(5)

顾名思义,随机梯度下降分类方法是利用随机梯度下降解决公式(5)中表达的优化问题,从而得到SGD的在线更新策略如下[13]:

(6)


fort=1,2, ...
从样本集合里面随机抽取样本(dt,ct);

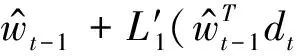
end
该分类方法适用于高维大规模的分类问题[13]。文献[14]将该算法应用于英文的情感文本分类任务中,取得了同SVM类似的分类效果。
3 组合分类方法
组合分类方法是融合多个分类器的结果从而得到一个新的融合结果,这个融合结果将取代各个基分类器的结果作为最终的分类决定[15]。组合分类器方法是模式识别以及机器学习理论研究领域里面的一个重要的研究方向。
3.1 产生基分类器
构建一个多分类器系统,首先需要产生多个基分类器用以组合。产生基分类器的方式大致有三种。第一种方式是通过训练不同的语料库产生不同的分类器;第二种方式是通过训练不同的特征集产生多个基于不同特征集的分类器。例如:在生物认证问题中,作为认证的特征可以是人脸、声音、虹膜等。这些特征中的任一特征都可以训练单个分类器,这样,一个生物认证系统可能包括多种生物特征的分类器。第三种方式是通过不同的学习方法获得不一样的分类器。很多分类方法是基于不同的机理的,如K-近邻(KNN)方法是基于记忆的方法,支持向量机方法(SVM)是基于结构风险最小理论的方法等等。因此,不同的分类方法实现的分类器实现分类的效果往往是不一样的。一种可行的方式就是将多个分类方法实现的分类器组合起来。
3.2 融合算法
获得了基分类器的分类结果后,组合分类器方法需要特别的融合方法去融合这些结果。融合方法本身就是“多分类系统”研究领域的一个基本问题之一[15]。融合方法可以分为两种,固定的融合方法(Fixed Rules)和可训练的融合方法(Trained Rules)。前者的优势在于它们不需要额外的训练语料进行训练。这种方法简单,易实现,如简单的投票规则(Voting Rule)和乘法规则[15]。可训练的融合方法的优势在于在足够的训练语料下,它们能够获得更好的分类效果。
假设有R个参加组合的分类器fk(k=1,…,R),这些分类器给样本x的分类结果为Lk(Lk=c1,…,cm)。另外,他们提供出了属于每个类别的概率信息:Pk= [p(c1|dk), …,p(cm|dk)]t,其中p(ci|dk)表示样本dk属于类别ci的概率。如果样本dk属于类别cj,在不同的融合算法中需要满足不一样的条件。下面是一种常见的固定融合算法:
乘法规则的条件[15]:

(7)
目前比较主流的一种可训练的融合方法叫做元学习的方法(Meta-learning)。元学习的融合方法是指,将基分类器输出的分类结果作为中间特征[16](又叫元特征),即:
Pmeta= [P1,P2,…,Pk,…,Pm]
(8)
然后把这些特征向量作为输入再一次学习一个分类器,该第二层的分类器叫元分类器。
3.3 基于Stacking的组合分类器方法
基于Stacking的组合分类器方法是目前比较主流的组合分类器方法[17]。该方法产生基分类器的方式即是上面提到的第三种方式。利用上面提到的四种分类方法,即NB,ME,SVM和SGD,训练得到四个基分类器。然后,使用的融合算法是可训练的元学习方法。特殊的是中间样本(元学习样本)是通过对训练样本的N-fold交叉验证(Cross validation)获得的。另外,针对元分类器的分类方法也可以有很多种选择,在后面的实验中,我们分别选取SVM和ME做相关实验。基于Stacking的组合分类器方法的系统框架结构如图1所示。

图1 基于stacking的组合分类器系统的框架结构


(9)
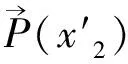
(10)
交叉验证使得获得的元学习向量数目同整个训练样本里面的样本数目是一样的。由于元分类器的向量维度非常小(为2×l),该分类器的训练和测试速度非常快。因此,元学习过程对系统的时间复杂度影响不大。
4 实验设计及分析
本实验中,我们使用了谭松波博士收集的一个的中文情感文本分类语料库*http://www.searchforum.org.cn/tansongbo/,该语料库的来源是旅馆预订领域,我们选取了2 000个样本。为了确保实验分析更加可靠,我们在卓越网站*http://www.amazon.cn/上面另外收集了来自三个领域的中文评论语料。这三个领域分别是书籍﹑DVD和运动产品。实验中的情感文本分类的任务是将评论分为正面和负面,每个领域大概有1 600个样本。实验过程中,我们选择80%的样本作为训练样本,剩余的20%样本作为测试样本。上面提到的四种分类方法中,SVM是使用标准工具light-SVM*http://svmlight.joachims.org/,NB和ME使用的是MALLET机器学习工具包*http://mallet.cs.umass.edu/。在使用这些工具的时候,所有的参数都设置为它们的默认值,例如SVM使用的是线性核函数。SGD方法是由我们自主实现的(参考文献[13])。在实现过程中,我们采用的学习速率为ηt=0.002,损失函数L(x,y)为Huber损失函数[18]。在实现基于Stacking的组合分类方法时,我们在训练样本中进行了5-fold交叉验证来得到元学习样本。然后分别使用SVM和ME作为元分类器的分类算法。为了便于比较,我们同样给出了一种固定方式的融合算法—乘法规则的融合结果。
我们采取了分类正确率来评价分类的效果,其定义如下:
(11)
在进行分类之前,首先我们采用中国科学院计算技术研究所的分词软件ICTCLAS对中文文本进行分词操作。给定分好词的文本后,我们分别选取词的Unigram和Unigram+Bigram作为特征,用以获得文本向量的表示。
表1和表2给出了四个基于不同分类算法的基分类器在四个领域里面的分类结果。表1和表2的结果分别是利用词的Unigram和Unigram+Bigram

表 1 基分类器在各个领域上面的分类结果(利用词的Unigram特征)

表2 基分类器在各个领域上面的分类结果(利用词的Unigram+Bigram特征)
作为特征得到的。从表1的结果可以看出,在使用Unigram的时候,没有一种分类算法是有绝对优势的。SVM的表现相对来说比较好,它在两个领域中取得了最好的分类效果。然而,从表2的结果可以看出,NB分类方法取得了一致最好的效果。这一点同文献[10]的结论一致。比较表1和表2的结果,我们可以发现,引入词的Bigram对分类的性能提高有明显的帮助。总体来说,该实验结果同我们的观点一致,就是说不同的领域,不同的特征集合需要的最优分类算法往往也不一样。
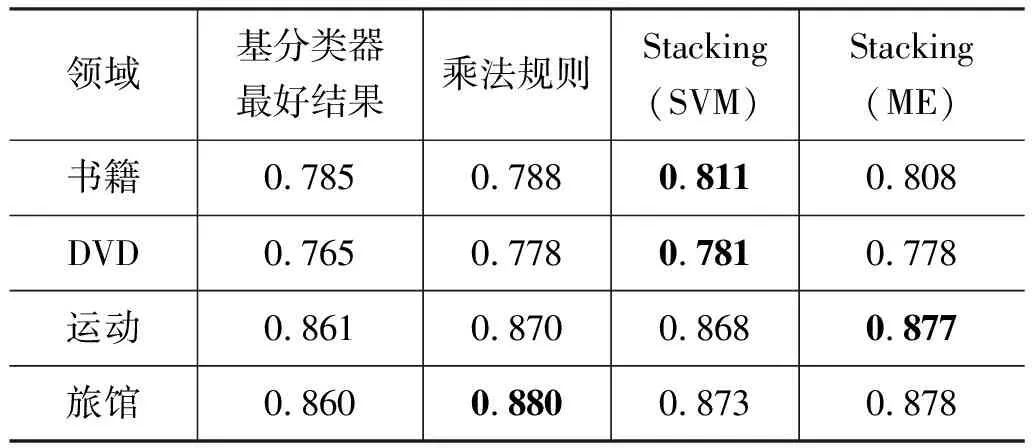
表3 不同融合算法在各个领域里面的表现(利用词的Unigram特征)

表4 不同融合算法的识别结果比较(利用词的Unigram+Bigram特征)
表3和表4给出了组合分类方法在四个领域里面的分类结果。表1和表2的结果分别是利用词的Unigram和Unigram+Bigram作为特征得到的。为了便于比较Stacking组合方法和其他方法,我们还给出了基分类器中获得的最好分类结果和乘法规则融合算法的结果。从表 3和表 4的结果可以看出,乘法融合算法基本能够保证组合后的结果接近或者超过最好基分类器的结果(在DVD领域使用Unigram+Bigram特征时有0.6%的性能损失)。然而,基于Stacking的组合方法能够很好地提高分类效果,比最好的基分类器的性能都有所提高。这一点对实际应用非常重要,因为我们可以不必去面对每个领域选择合适的分类算法,而是利用组合的方法去组合不同的分类方法。这样组合的结果还可以超过最好的基分类器的结果。一般情况下, ME分类方法作为元学习的时候,组合分类的结果表现比较稳定。
组合分类方法比最佳分类方法结果平均提高了一个百分点左右,虽然这样的提高并不算非常显著,但是在实际应用中,几乎不可能有一种分类方法能够在不同的领域或者不同的特征集上都能取得最佳的效果(例如表1中显示,ME方法在书籍领域取得最佳效果而在旅馆领域,SGD方法表现最好)。更重要的是,最差的分类方法比组合分类方法相差的正确率都超过了两个百分点,尤其在书籍领域,组合分类方法(0.811)比最差的分类方法(0.775)提高了3.6%。因此,我们认为,为了保证系统分类效果达到最佳表现,组合分类方法是值得使用的。但是由于组合系统需要进行多个分类器的分类,系统在于测试阶段的时间复杂度要比使用单一分类方法要高。不过这种时间复杂度方面的提高是相对于分类器数目线性变化的,在实际应用中是可以接受的。
5 结论
在情感文本分类任务中,选择合适的分类方法直接影响系统的分类性能。为了避免不同的领域选择不同合适的分类方法,本文提出利用基于Stacking的组合分类方法组合四种不同性质的分类方法,分别为NB﹑ME﹑SVM和SGD。在实验中,我们利用四个不同领域的中文情感文本分类语料测试了该组合分类方法。实验结果表明该方法能够获得比固定融合算法(乘法规则)更好的分类结果,而且能够获得比基分类器最好结果更佳的分类效果。
在下一步的研究工作中,我们将参考这些研究比较成熟的结果,利用情感文本更丰富的特征信息产生多样的分类器及如何实现动态的分类器选择方法等问题。例如,不同词性的特征对于整篇文章的情感分类的贡献不一样,我们可以组合不同词性特征产生的分类器,考察组合后的分类效果。另外,我们将重点分析情感(Sentiment)文本中感情(Emotion)表达的份额,并利用已有的感情分类语料构建一个独立于领域的情感分类器,用以融合到我们的系统中。
[1] B. Pang, L. Lee, and S. Vaithyanathan. Thumbs up? Sentiment classification using machine learning techniques [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP-02).2002.
[2] 徐军, 丁宇新, 王晓龙. 使用机器学习方法进行新闻的情感自动分类[J]. 中文信息学报,2007,21(6): 95-100.
[3] 朱嫣岚, 闵锦, 周雅倩, 黄萱菁, 吴立德. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报,2006,20(1): 14-20.
[4] 徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制[J]. 中文信息学报,2007,21(1): 96-100.
[5] B. Pang and L. Lee. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts [C]//Proceedings of the 42nd Meeting of the Association for Computational Linguistics (ACL-04). 2004.
[6] E. Riloff, S. Patwardhan, and J. Wiebe. Feature subsumption for opinion analysis [C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP-06). 2006.
[7] H. Cui, V. Mittal, and M. Datar. Comparative experiments on sentiment classification for online product reviews [C]//Proceedings of AAAI-06, the 21st National Conference on Artificial Intelligence. 2006.
[8] 唐慧丰,谭松波,程学旗. 基于监督学习的中文情感分类技术比较研究[J]. 中文信息学报,2007,21(6): 88-94.
[9] S. Tan and J. Zhang. An empirical study of sentiment analysis for Chinese documents [J]. Expert Systems with Applications. 2008,34(4): 2622-2629.
[10] J. Li and M. Sun. Experimental study on sentiment classification of Chinese review using machine learning techniques [C]//Processing of International Conference on Natural Language Processing and Knowledge Engineering, (NLP-KE-07), 2007.
[11] M. Sahami. Learning limited dependence Bayesian classifiers [C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD-96), 1996:335-338.
[12] V. Vapnik. The Nature of Statistical Learning Theory [M]. Springer, Berlin, 2005.
[13] T. Zhang. Solving large scale linear prediction problems using stochastic gradient descent algorithms [C]//Proceedings of International Conference on Machine Learning (ICML-04). 2004.
[14] J. Blitzer, M. Dredze, and F. Pereira. Biographies, Bollywood, Boom-boxes and Blenders: Domain adaptation for sentiment classification [C]//Proceedings of Annual Meeting on Association for Computational Linguistics (ACL-07). 2007.
[15] J. Kittler, M. Hatef, R.P.W. Duin, and J. Matas. On combining classifiers [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20:226-239.
[16] R. Vilalta and Y. Drissi. A perspective view and survey of meta-learning [J]. Artificial Intelligence Review, 2002, 18(2): 77-95.
[17] Saso Dzeroski and Bernard Zenko: Is combining classifiers with stacking better than selecting the best one? [J].Machine Learning. 2004, 54(3): 255-273.
[18] Rie Ando and Tong Zhang. A framework for learning predictive structures from multiple tasks and unlabeled data [J]. Journal of Machine Learning Research, 2005,6:1817-1853.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
