
基于正交变换的氧化铝浓度预测
2010-05-29 09:00林景栋
武汉工程大学学报 2010年9期
林景栋,李 岭,张 鹏
(重庆大学自动化学院,重庆 400044)
0 引 言
基于电解槽属于非线性、时变、大滞后系统[1],采用槽电阻跟踪法[2]常出现对氧化铝浓度跟踪丢失的问题,通常下料后氧化铝浓度应该在增加,但是在实践中发现,氧化铝浓度时常保持不变或无缘无故减小,这样违背了槽电阻规律.
为了解决这个问题,研究采取对氧化铝浓度进行预测的方法:首先准确判定当前时刻氧化铝浓度,然后选取影响氧化铝浓度变化的主要因素,根据这些参数的特点,采用经典的预测算法对其进行预测,得到下一时刻浓度值.为了使预测算法具有准确性,并具有自调整功能,笔者对当前预测值,和实际值作比较,通过修改预测算法权系数,使预测值逼近于实际值.
1 氧化铝初始浓度预测
当前氧化铝浓度的判定尤为重要,因为它是检测预测值准确与否的重要因素,只有对当前浓度做出准确判断,才能与预测值对比得到修改算法准确性的权系数.为此,笔者给出了一种可实现对当前氧化铝浓度的判定方法:根据瞬时电压历史数据绘制出曲线,从当前时刻向前寻找10个波峰,计算该波峰段累计斜率乘以对应的加权NB(加料时间间隔),最后筛选出最大值的点作为浓度最低点;再从那个时刻根据规则推理到当前,得出当前浓度.当判定出浓度最低的初始点以后,每隔10 min,计算该段时间内槽电压的变化率乘以对应NB的加权平均,最后得出一个N值,直接参与推理.若10 min有升降阳极的动作,则需要去掉动极1 min和动极后2 min内的数据.
初始浓度判定算子:
①从当前点Now向前搜索5 d内报告浓度过低(CMD=30)的点Pk(1≤k≤10).
②扫描每一个Pk前后7 min的范围,得到每一个Pk在此范围内的瞬时电压的最大值点对应的时刻TV.在TV前后10 min的范围内,检查是否存在槽动作,不存在这些槽动作的点TV形成一个新的点集M(k)(1≤k≤10).
③扫描这个新的点集M(k).
向前取10 min T1=T-10;
向后也取10 min T2=T+10;
扫描T1:方向从T1时刻到T
计算每13个点的累计斜率Ki(1≤i≤4)
设第十三个点的电压对应的加料间隔为NBi
Y1=Abs(sum(K1*NB1+K2*NB2+K2*NB3+…+Kn*NBn)).
扫描T2:方向从T时刻到T2
计算每13个点的累计斜率Ki(1≤i≤4)
设第十三个点的电压对应的加料间隔为NBi Y2=Abs((sum(K1*NB1+K2*NB2+K2*NB3+…+Kn*NBn)).
Z(j)=Y1+Y2.(1≤j≤10)
若Zk>4 000,则
计算系数K=Zk/10,st=M(k).TV;
若没有找到初态点,则
继续向前搜索5 d低浓度点,转第①步
根据以上算法可以实现当前时刻氧化铝浓度的判定,对于检验预测得到下一时刻浓度值,调整权系数是必不可少的.在研究中选取槽电压、电解槽状态和出铝量作为浓度预测的输入变量,建立氧化铝浓度预测模型.
2 线性回归预测法
针对影响氧化铝变量的特点,可以采用一种多输入单输出的预测算法,在这里笔者采用经典的线性回归预测法[3-4],其原理是解一个线性方程组,求解一组系数,使所有输入输出量尽量逼近此组系数构成的方程.
在对程序进行静态分析时为了构造和逼近程序的不动点理论,Patrick Cousot和Radhia Cousot在1977年提出了基于格的抽象解释理论[8]用于对程序的语义进行可靠近似。程序具体的对象域上的计算称为程序的操作语义或者指称语义,描述了对象域上的计算过程[9]。对程序的抽象解释过程可以描述为通过对待分析程序在抽象域上的计算,使得抽象域上的计算结果尽可能地逼近程序在具体域上的计算结果过程。通过程序在抽象域上的计算结果来获取真实程序计算结果的某些信息。抽象解释实际上是通过损失一部分的计算结果的精确程度来取得较高的计算速度。是在计算结果的精度损失和计算时间效率之间的一种平衡。
设样本点容量为n,因变量为y,K个自变量分别为X1,X2...,XK,则总体线性回归模型方程可表示为:
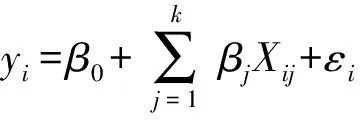
(i=1,2,3,…,n) (j=1,2,3,…,n)
因变向量y=(y1,y2...yn)T;自变量矩阵:
相关系数β=(β0,β1,…,βk)T
令
(1)
则相关系数β的最小二乘估计值应为
(2)
3 基于正交变换的氧化铝浓度预测
影响氧化铝浓度因素是高度藕合的,并且各种生产因素对它的影响不是线性的,因此经典的线形多元回归在氧化铝浓度预测的时候就会出现相对较大的偏差,这就限制了经典方法的直接使用.所以将经典的线性方程进行正交变换,用近似于线性方程的一个矩阵求解其特征值、特征向量得到推算出氧化铝浓度预测值.
按照第1节中的论述,采用一些对氧化铝浓度影响较大的因素去预测氧化铝浓度.令输入为槽状态、出铝量以及槽电阻.将模型描述为:
ΔY(K)=aΔV(K)+bΔL(K)+cΔC(K)+d
(3)
即:
Y(K)-Y(K-1)=
a[V(K-1)-V(K-2)]+
b[L(K-1)-L(K-2)]+
c[C(K-1)-C(K-2)]+d
(4)
式中Y(K),Y(K-1)分别为K时刻与K-1时刻的氧化铝浓度;V(K-1),V(K-2)分别为K-1时刻与K-2时刻的槽状态;L(K-1),L(K-2)分别为K-1时刻与K-2时刻出铝量;C(K-1),C(K-2)分别为K-1时刻与K-2时刻槽电阻值,由槽电压除以系列电流可以得到,β(a,b,c,d)T相关系数.针对某一电解槽,取其相关数据,即:槽状态,出铝量,槽电阻,用经典的多元线性回归法,求解模型的相关系数.再将相关系数代入(3)式,对浓度变化进行预估,从而得到以后浓度的估计值.
模型中影响氧化铝浓度最主要的两个参数是出铝量以及槽状态,本研究假定模型的输入对输出的影响是有一定时间限度的.定义这个时间限度为39 d,来进行相关系数的估计.以预估第42 d即K=42时的氧化铝浓度Y(42)为例.首先对数据进行预处理,即按照公式(4),将K=3,4,…,41的数据分别代入,求得ΔY(K),ΔV(K),ΔL(K),ΔC(K),其中K=3,4,…,42.
构造输入矩阵:
Xorg(1)(K-I)=
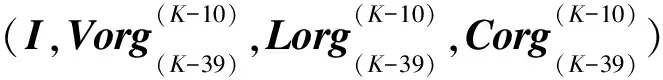
Xorg(2)(K-I)=
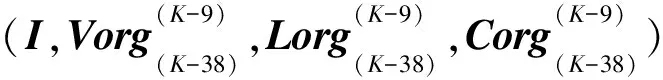
⋮
Xorg(P)(K-I)=
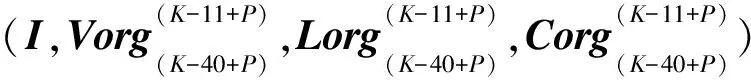
⋮
Xorg(10)(K-I)=
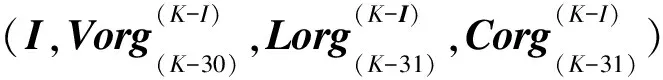
(P=3,4,…,9;K=42,43,…)
I(I,I,…I)T

ΔV(K-39+P),…ΔV(K-11+P))T
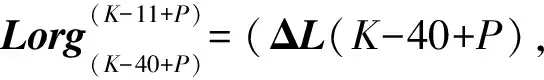
ΔL(K-39+P),…ΔL(K-11+P))T
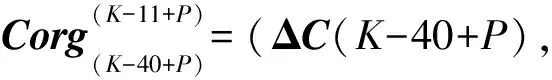
ΔC(K-39+P),…ΔC(K-11+P))T
(P=1,2,…10;K=42,43,…)
构造输出矩阵:
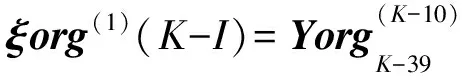
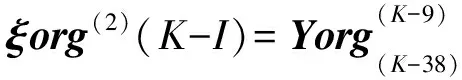
⋮
(P=3,4,…9;K=42,43,…)
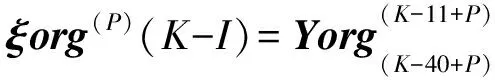
⋮
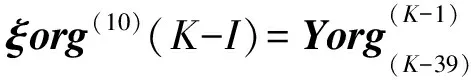
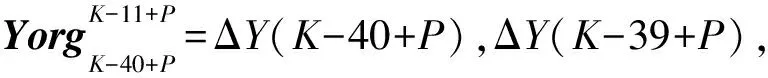
…ΔY(K-11+P))T
其中(P=1,2,…10;K=42,43,…)
(5)
将输入输出矩阵作如下组合,构造一个新的矩阵作为论文的预测对象.令:
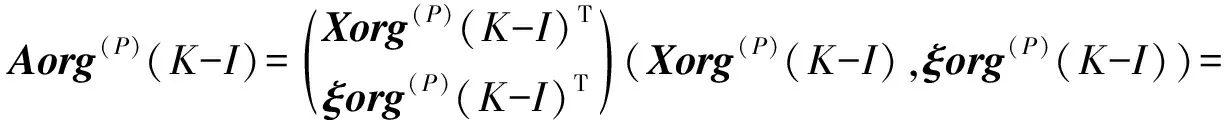
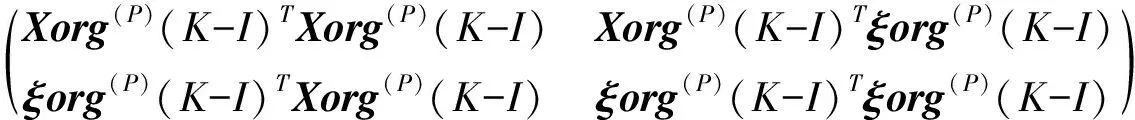
(P=1,2,…10;K=42,43,…)
其中,矩阵Aorg(P)(K-I)应该是一个5维方阵.观察矩阵Aorg(P)(K-I),按此种结构,若P=11,则输出矩阵中就包含了ΔY(K)元素,只要将此元素提取出来,即可通过Y(K)=Y(K-1)+ΔY(K)求的需要预测的氧化铝浓度Y(K).
现将目标锁定在求取矩阵Aorg(11)(K-I),将Aorg(11)(K-I)分解得到:
Aorg(11)(K-I)=
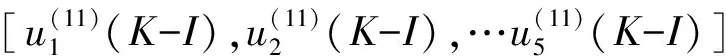
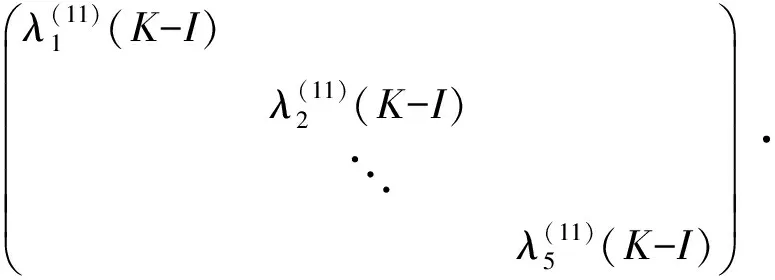
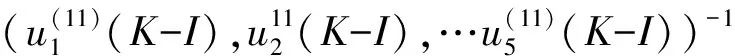
(6)
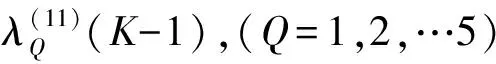
对矩阵Aorg(p)(K-I),(P=1,2,…10)中的10个元素同样分解.则有:
Aorg(p)(K-I)=
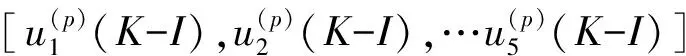
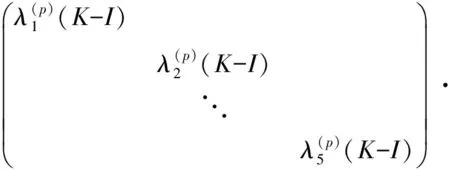
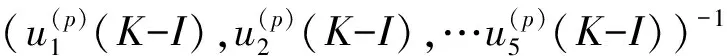
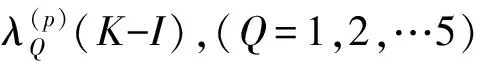
G(p)(K-I)=
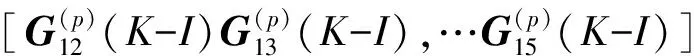
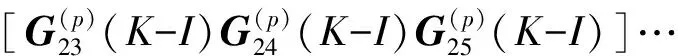
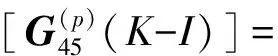
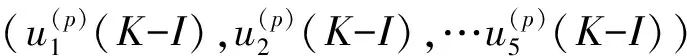
(P=1,2,…10)
并分别分别建立:
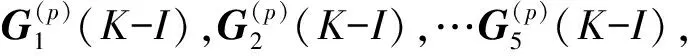
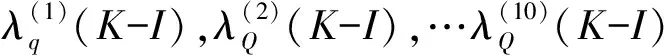
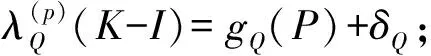
gQ(P)=φ(1,P,P2)T
(7)
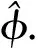
(8)
其中(P=1,2,…10)
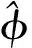
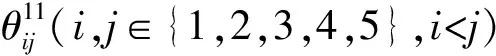
(9)
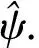
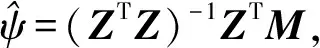
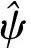
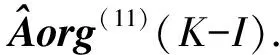
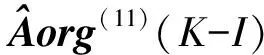
则能够得到Y(K)的最小二乘估计为:
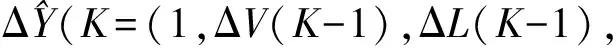
ΔC(K-1))(A4×4)-1B4×1
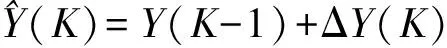
(10)
4 氧化铝浓度预测结果
按照上面介绍的方法,选定任意电解槽参数按如下流程对氧化铝浓度进行预测.
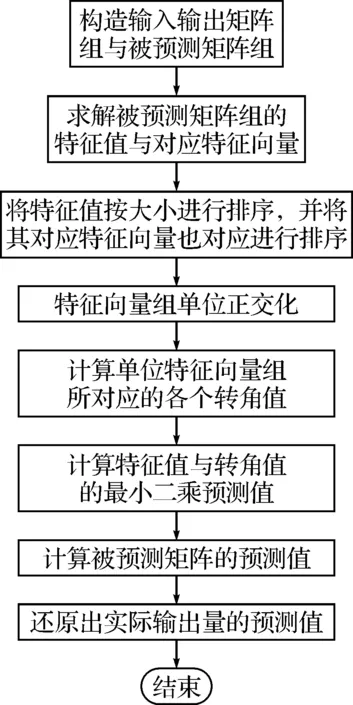
图1 基于正交变换预测函数的流程图
取贵铝某电解车间127#槽6月7日至9月7日的生产数据作为仿真的对象.定义6月7日为第1 d,6月8日为第2 d,以此类推,则9月7日为第93 d.
现用第1 d到第41 d的生产数据来预测第42 d的氧化铝浓度,用第2 d到第42 d的生产数据来预测第43 d的浓度,以此类推,一直预测到第93 d的氧化铝浓度.然后根据第93 d浓度值验证预测结果是否接近,若预测值与实际值相差较远,则可以修改权系数重新预测,直到结果趋近实际值为止保存权系数,供下一次与测使用.
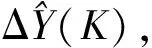
预测结束后利用下面公示计算标准差,检验模型与实际值的拟合程度:
(11)
式中,N为预测天数.从第43 d到第93 d共计检验52 d的预测情况,故N=52.由公式(11)计算得到,127#槽的氧化铝浓度基于正交变换的预测值与实际值的标准差为2.806 2,在修改了模型的修改权系数后得到标准差为1.263 4.仿真曲线如图2、图3所示.
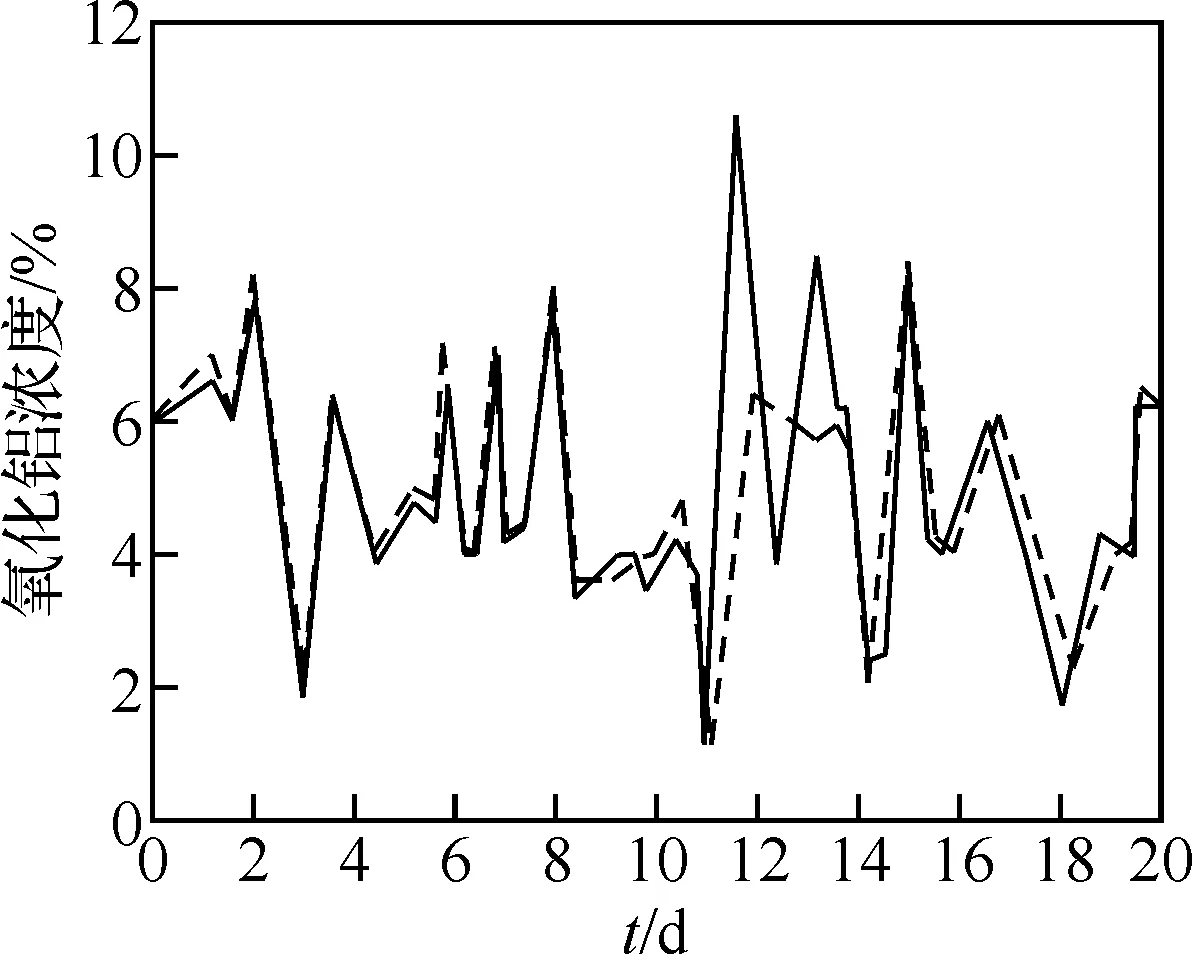
图2 未设定权系数时预测值与实际值曲线
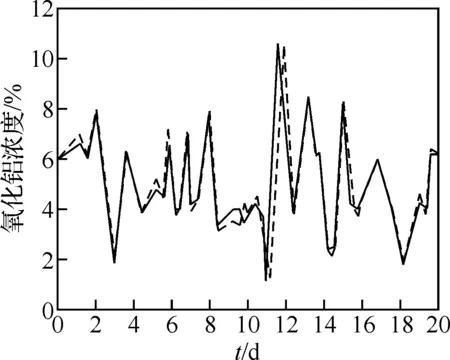
图3 设定权系数后预测值与实际值曲线
5 结 语
通过对比分析发现,采用正交矩阵变换来预测氧化铝浓度,在设定权系数前后预测值与实际值之间的拟合程度有了较大的改变.说明对氧化铝浓度进行线性回归预测时必须要对输入参数进行一些必要的约束,使方程的解范围缩小.因此研究给出的氧化铝浓度预测方法是比较正确的,相对于传统的槽电阻辨识法有了很大的改变.针对目前没有准确的数学模型来检验算法适用性与否,笔者将此算法应用于贵铝160 kA些列电解槽上,通过大量从事铝电解工作者的经验,以及试验进行验证该模型的效果,所以在这一方面还有大量的工作可以开展.
参考文献:
[1]田应甫.大型预焙电解槽生产实践[M].长沙:中南大学出版社,2003.
[2]孙捷,邱竹贤,孙勇,等.工业铝电解槽槽电阻-氧化铝浓度曲线研制[J].轻金属,1994(6):25.
[3]Han J,Kamber M.数据挖掘:概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2001.
[4]Agrawal R,Imielinski T,Swami A.Mining Association Rules between Sets of Items in Large Databases[C].In:Proceedings of the 1993 ACM SIGMOD international conference on Management of data.New York,NY,USA:ACM Press,1993:207-216.
猜你喜欢
石油石化绿色低碳(2022年2期)2023-01-06
山东冶金(2022年4期)2022-09-14
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
国外核新闻(2020年8期)2020-03-14
氯碱工业(2020年9期)2020-03-02
制造技术与机床(2019年8期)2019-09-03
江西建材(2018年1期)2018-04-04
环境保护与循环经济(2017年4期)2018-01-22
当代化工研究(2016年2期)2016-03-20
