
创业企业信用风险度量模型与实证研究
2010-05-22 07:56:14迟建新
中国流通经济 2010年5期
迟建新
(重庆大学经济与工商管理学院,重庆市 400030)
一、引言
风险评估是企业得以融资的重要前提,是投资方进行决策的重要依据,它不仅关系到企业自身的融资效果,同时也关系到投资方的风险控制。然而,创业企业自身的特点,如创建初期风险较高、自身资产规模较小、经济体制不健全、盈利能力波动较大等,都进一步加大了对其进行风险评估的困难性,从而使其在市场上的融资变得更加困难,这也在一定程度上限制了其经济潜能的发挥。因此,正确认识创业企业的发展周期与规律,对其进行科学的风险评估将具有重要意义。
关于信用风险度量的研究,经历了从古典信用分析、多元统计分析到现代信用风险模型的快速发展过程,然而由于信用风险本身的固有特点,国际公认和统一的模型和方法至今还未出现,各种模型和方法其本身都存在这样或那样的缺陷,且大多是针对上市公司等大型企业的,并没有考虑中小企业或创业企业自身的一些特点,因此有必要对这些模型和方法进行分析、比较、评价,从中选择合适的模型来度量我国创业企业信用风险。
古典信用分析法在实践中存在许多难以克服的缺点和不足:(1)古典信用分析属于定性分析,它过分依赖专家的主观经验判断。(2)专家制度与银行较为严格冗长的经营管理制度紧密相连,大大降低了银行应对市场变化的能力。(3)专家制度加剧了银行在贷款组合方面过度集中的问题,使银行面临着更大的风险。
古典信用风险度量方法的弊病使得人们不得不去寻求更加客观、更为有效的度量信用风险的方法和手段,以提高银行信用评估的准确性。单变量判定模型是介于古典信用分析和多元统计分析之间的一种过渡方法,具有简单可行的优点。其缺陷是任何单个财务指标都无法全面地反映公司财务特征及公司总体情况,甚至任何单个财务指标将在很大程度上排斥其他指标的作用。多元线性判别模型具有相当的影响,它克服了单变量模型的缺点,判别的准确性也有大幅提高,但其本身也存在缺陷:(1)它是一个线性模型,但判断一个公司信用风险的因素非常复杂,不太可能成简单的线性关系。(2)多元正态分布的假设——在线性判别模型中,如果不是正态假设就不能利用F检验加以检定,而未经检定的模型的适用性如何便难以判断了,而信用评级的相关研究所使用的资料绝大多数都是财务比率,但财务比率大都违反正态假设。而信用评级的相关研究所使用的资料绝大多数都是财务比率,但财务比率大都违反正态假设。(3)采用历史财务比率会影响对借款人信用评价的时效性。
由于线性判别模型在假设上的弊端,越来越多的研究以概率模型核心,这类模型并不假设所有的样本可以截然划分为单独的两组,也不要求多元正态分布的变量假设,其中最具代表性的是Logit模型和Probit模型。而对于现代风险分析的三个典型模型,在应用方面的问题主要表现为:(1)KMV公司的组合管理者模型(Portfolio Manager)与传统方法相比,主要优点在于:以股票市场数据为基础,而不是依赖会计核算数据,反映了市场中投资者对公司未来发展的综合预期,具有前瞻性、高敏感性。同时,KMV模型的优势还包括,应用的数据更新快速,因为假如利用计算机设计程序的方式,可以每天以实时的市场资料重新计算违约概率;实证检验证明违约预测能力较强,并且估计过程应用的模型可观察到,不存在"黑箱"作业的嫌疑等等。然而KMV模型针对未上市公司具有一定的局限性,而且片面强调股票市场,变动敏感度太高。另外,虽然KMV理论应用上比传统信用风险管理方法的优点多,但仍然存在应用上的限制,如:有时因次级市场的缺乏,无形资产的估计是很不容易的,或是因为标的资产的次级交易市场与价格透明度的欠缺,使价值的编译程度不易衡量;违约的历史数据库不容易获得或过少,增加估计上的样本获得的困难度等等。(2)信用尺度模型(Credit Metrics)成功地把信用风险度量与信用等级的转移、违约率等相关因素结合起来,使模型考虑的因素更加全面,适用范围更加广泛,但它片面强调信用评级,不能够反映特定债务人当前的信用质量变化情况。而且我国目前还没有一个权威的、完善的信用评级体系,也缺乏有效的信用风险转移矩阵,同时也缺少准确的基准贴现率,因此现阶段该模型在我国尚无法应用。(3)信用风险模型(Credit Risk+)忽略了信用级别的变动,未解释风险头寸的变化与这些随机因子的关系。
总之,以KMV模型为代表的现代信用风险度量模型用来分析和度量财务不健全、规模小、信用状况不佳的创业企业贷款的信用风险的可操作性不强。而以Logit模型和Probit模型为代表的概率模型是现有模型当中,在度量创业企业信用风险上是兼具较高准确性和可操作性的理想模型。
二、度量创业企业信用风险的基本思路
1.基本思路。基于对相关文献的分析,本文将采用Logit回归模型对创业企业进行信用风险度量。由于创业企业的发展是一个分阶段的过程,各个时期的风险特点和风险程度均有所不同,所以本文从抽样阶段开始,运用逐步多元判别分析法对处于不同生命阶段的创业企业筛选出具有区别力的分析变量,以对不同生命阶段的企业的信用风险进行度量。
然后,运用定量模型计算信用风险。研发评分模型的前提是企业未来的行为模式与过去相似,而且这种行为模式可以用适当的数理统计技术提炼和总结出来,从而用过去的数据预测未来,因此先确定研究所取的样本。由于创业企业发展的每一个阶段所面临的风险和需要的资金的配合、性质和规模都有所不同,本文借助企业生命周期理论,利用模型将研究样本按照其所处的不同生命阶段分为4类,即:种子期、导入期、成长期和成熟期。接着用财务和非财务变量来表示量化后的处于四个不同生命阶段的创业企业的信用风险有关因素。再运用Logit模型进行回归分析,计算出信用风险,并以此对创业企业进行信用风险度量。
2.数据来源与样本选取。构建我国创业企业信用风险分析模型,理论上讲,企业样本必须是从全国所有创业企业总体中选取,这样选出的样本和得出的模型才具有代表性和权威性。由于创业企业与中小企业融资方式与信用风险水平的类似性,本文认为以中小企业为建立模型的样本较为恰当。在选取样本时遵循如下原则:
(1)样本区间确定。根据数据的可获得性,同时也能很好地反映近几年创业企业违约状况,样本选定为2008年所有有贷款的中小企业样本。
(2)按地区选择。考虑到创业企业信用风险的大小可能与其所在的地区有关,本研究按国家行政区域划分以及地区经济发展水平把全国划分为三个地区,即东部发达地区、中部发展中地区及西部欠发达地区。
(3)选出的样本必须要有可获得的准确可靠的财务报表。
(4)违约企业与非违约企业分类。为了研究需要,本应根据这些企业在银行的历史贷款偿还情况进行违约企业与非违约企业的两类分类。然而,由于此类历史贷款偿还资料不可得,可选择其他指标进行分类,例如用一个信用指标(IScredit)来反映样本企业以往的信用状况。它是由企业利润率变动率(本文采用净资产收益率变动率)和企业负债率变动率大小的比较来确定。若企业的利润率变动率大于负债率变动率,则表明企业以往信用状况良好;若企业的利润率变动率小于负债率变动率,则表明企业以往信用状况较差。据此,将样本企业分为信用“好”的企业和信用“差”的企业。
医院药品费用是一个复杂的研究对象,笔者运用层次分析法建立医院药品费用影响因素评价指标分层模型,拟建了医院药品费用影响因素指标体系。对医院药品费用的影响因素进行定性和定量研究;根据医院药品费用影响因素指标体系建立了控制监督评分标准。同时,将医院药品费用控制监督评分标准与实例结合,用以评价医疗机构的药品费用控制水平,该评价指标才更能体现出现实意义。
按照评估模型的要求和实证经验,样本中信用“好”的企业和信用“差”的企业必须相等,配对形成样本最终的总体。由于此处信用“差”的企业比信用“好”的企业多,因此,最适合的做法就是保留全部信用“好”的企业,然后从信用“差”的企业中随机抽取相等数目与之配对,形成最终的总样本。这样总样本中包括相同数量的信用“好”的企业和信用“差”的企业。根据以上原则以及企业数据的可获得性和易得性,本文认为采用深圳证券交易所中小企业板块的180家上市企业,作为样本企业较为恰当。
3.样本分类——不同生命阶段创业企业的识别。随着现代经济的发展,影响企业生命周期的因素越来越多,企业生命周期各阶段的区别也越来越不明确。但是,通过对主要影响因素的确定,可以对企业所处的生命周期阶段进行判别,本文借鉴企业生命周期阶段定量判定方法,从总资产(Z)、无形资产(W)、销售收入(S)、现金净流量(X)、生产成本(C)、利润(L)、R&D投入(R&D)、运营能力(Y)等几个影响企业生命周期的因素来确定企业所处的生命周期阶段。利用这种方法便可判定企业所处的生命阶段,从而将样本企业分组。种子期企业由于缺乏明确的财务状况,所需资金较少,多以内部融资为主。因此本文研究重点为处于导入期与成长期的创业企业的信用风险的度量提供有操作性、低误判率的方法和模型。
三、不同生命阶段的创业企业信用风险度量模型的构建
1.创业企业逻辑斯蒂(Logistic)信用评分模型的构建。根据Logit信用评分模型基本原理,在信用评分模型构建过程中,以P表示导入期企业i违约(或信用“差”)的概率,1-P为不违约的概率,违约与不违约的概率之比为P/(1-P)。另定义二值因变量Iscredit表示是否是信用差的企业,具体如下:

根据一般多元线性回归模型,并结合线性概率模型,对因变量取值为1的概率P进行建模:
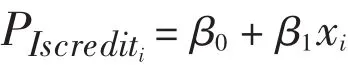
此处概率P的取值范围是0-1,而一般线性回归模型要求因变量的取值为(-∞,+∞),同时此处的因变量概率P与解释变量是线性关系,实际中概率与解释变量往往是一种非线性关系,因此,可以采用Logistic变换最终得到Logit回归模型:
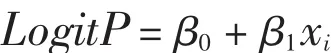
变形后为:
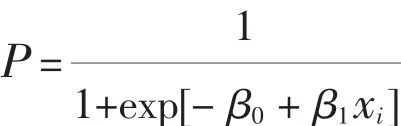
这样就很好地体现了概率P与解释变量之间的非线性关系了。其中为解释变量,接下来构建指标体系,确定该模型解释变量与被解释变量。
2.解释变量与被解释变量的确定。在进行指标的选取时,结合本文选取样本的特点,主要依据同类分析中曾使用过的有效指标来构建进入分析模型的指标体系。经过初步选择确定出影响创业企业贷款信用风险的指标变量分为两大类财务指标和非财务指标。财务指标借鉴穆迪公司对全球不同国家和地区的私人公司信用风险研究中使用的方法,分为收益性、资本结构、流动性、公司活动、公司规模和增长性6个方面,分别揭示待评估公司的信用风险状况;非财务风险指标主要涉及到公司领导者、经营管理团队及其产品占有率等状况,间接反映其与公司信用风险的关系。
模型指标体系共选取22个指标有待检验,其中财务类指标16个,非财务类指标6个,这22个指标与企业信用风险的关系有待进一步的检验。依据指标体系确立Logistic信用评分模型的解释变量与被解释变量,建立创业企业Logistic信用评分模型:
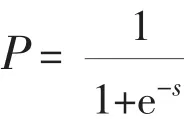
其中 :S=β0+ β1retnrati+ β2earnrati+ β3toraet+ β4adratio+ β5edratio+β6curtdrat+ β7operratio+ β8curtrati+β9actreceb+ β10invntory+ β11farratio+β12salerat+ β13salegrow+ β14profitgr+β15tassetgr+ β16cptaccum+ β17industry+β18region+ β19sex+ β20education+β21mpratio+β22mnaratio
其中,retnrati为总资产报酬率;earnrati为净资产收益率;toraaet为总资产周转率;adratio为资产负债率;edratio为权益负债比;curtdrat为流动负债率;operatio为营运资金与总资产比;curtrati为流动比率;actreceb为应收账款周转率;invntory为存货周转率;faratio为固定资产/大型企业资产总额标准;salerat为销售额/大型企业销售额标准;salegrow为销售收入增长率;profitgr为利润增长率;tassetgr为总资产增长率;cptaccum为资本积累率;Industry为行业性质;region为地区;sex为性别;education为受教育程度;mpratio为主要产品市场占有率;manaratio为企业行政管理人员占全部从业人员的比重。
四、实证研究
根据模型需要以及企业数据的可获得性和易得性,最后采用深圳证券交易所中小企业板块的80家上市企业,其中信用“好”企业与信用“差”企业各40家作为样本企业,建立Logit信用评分模型。
1.指标体系的筛选。根据前期研究成果,构建种子期企业指标体系主要考虑数据的可得性。因此以行业性质、企业所处地区、产品市场状况、企业主情况等非财务指标为指标体系的主要组成部分。本文研究的重点对象为导入期和成长期创业企业。这里以成长期为例说明指标体系筛选具体方法和过程。
首先进行第一轮变量筛选。对初步选定指标体系中的22个指标变量分别进行单变量Logistic回归(由于主要产品市场占有率和企业行政管理人员占全部从业人员的比重两个指标暂不完整,实证中采用前20个指标作为解释变量),剔除对被解释变量无显著影响的解释变量。显著水平定为0.05。利用Eviews软件,运行结果显示2008年深交所75家处于成长期的样本企业的总资产报酬率与其违约概率在0.05的显著水平上呈反向变动关系,即总资产报酬率越高其违约的可能性越小。该单变量Logistic回归结果显示解释变量retnrati(总资产报酬率)对被解释变量Iscredit的解释力较强,且与理论预期吻合,经过第一轮筛选该变量进入模型。依次类推,对余下19个解释变量分别进行单变量回归分析,发现除了解释变量总资产报酬率(retnrati),净资产收益率(earnrati),营运资金与总资产比(operatio),销售收入增长率(salegrow),利润增长率(profitgr)和总资产增长率(tassetgr)之外的其他变量的P值均大于0.05,即在0.05的显著水平上接受原假设,在回归分析时对被解释变量的解释能力较差,应从模型中删除。因此经过第一轮单变量的Logistic回归筛选得出进入模型的解释变量为六个,分别为总资产报酬率(retnrati),净资产收益率(earnrati),营运资金与总资产比(operatio),销售收入增长率(salegrow),利润增长率(profitgr)和总资产增长率(tassetgr)。
将得到的六个解释变量全部引入Logistic回归模型,采用后向Wald逐步选择法确定最终的模型,并进行偏回归系数估计。回归结果发现,变量销售收入增长率(salegrow)的P值为0.9391,对被解释变量的解释能力很差,应从模型中删除。因此,初步确定经过第二轮筛选进入回归模型的解释变量为:总资产报酬率(retnrati),净资产收益率(earnrati),营运资金与总资产比(operatio),利润增长率(profitgr)和总资产增长率(tassetgr)。
2.成长期创业企业逻辑斯蒂信用评分模型的确立。对经过第二轮筛选所确定的解释变量进行回归,结果显示所有指标变量的t检验都显著,P值小于0.05,反应整个模型拟合程度的指标如R2为0.841051,说明整个Logistic回归模型拟合较好。因此确定最初指标体系中与因变量之间存在明显相关性的指标,进入最终的创业企业信用风险评价模型。
根据深交所75个上市中小企业样本,最终得到成长期创业企业Logistic信用评分模型为:

其中:S=-10.49317-363.0145retnrati-25.05086earnrati-5.221855operratio-33.83025profitgr-18.34455tassetgr
模型的确定显示最终进入Logistic评分模型的解释变量均为企业财务指标,说明实证分析证明企业财务指标的变动相对于非财务指标对企业的违约有较强的解释力。
3.模型的检验。对于本模型主要进行系数检验。首先进行系数的显著性检验。在使用Eviews软件进行逐步选择变量过程中,每步剔除变量以后都将观察R2统计量,以了解每次剔除一个不显著的变量以后,模型的整体显著水平。对于以Logistic模型为代表的非线性回归模型的检验,通常采用Wald检验法,在Eviews窗口选择View/Coefficient Tests/Wald-Coefficient Restrictions,在编辑对话框中输入约束条件,多个系数约束条件用逗号隔开。由于本模型对于各解释变量的系数,即为各解释变量对被解释变量的敏感程度或相关系数,无特别的联系与经济涵义,因此不需要任何约束条件,又由于本模型在选择变量时进行了严格的筛选,所以省略Wald检验。
接着进行遗漏变量检验。这一检验能给现有方程添加变量,而且询问添加的变量对解释因变量变动是否有显著作用。原假设是添加变量不显著。选择View/Coefficient Tests/Omitted Variables-Likehood Ration,在打开的对话框中,列出检验统计量名,用空格相互隔开。检验结果显示,在0.10的置信度下,Omiitted检验结果表明不能拒绝原假设,即引入模型意外的解释变量不合适,从而印证了模型筛选出的变量的解释力。
4.创业企业信用风险度量。假设处于成长期创业企业A财务数据为:
(1)总资产报酬率(retnrati)=0.021098644;(2)净资产收益率(earnrati)=0.03854017;(3) 营运资金与总资产比(operatio)=0.1455341;(4)利润增长率(profitgr)=-0.2181;(5)总资产增长率(tassetgr)=-0.0224。将成长期创业企业A财务数据代入(1)式,求得其违约概率为2.19439E-12,依此判定企业A为信用“好”的企业。
需要强调的是,变量筛选是在样本企业按照前述方法分组后分别进行的,因此,导入期、成长期与成熟期企业信用风险度量模型中所包括的变量存在差异。获得企业数据后,首先根据企业生命阶段判别模型判别企业所处的生命阶段,再将企业数据代入相应生命阶段Logistic评分模型。
五、结束语
本文采用Logit模型对我国创业企业信用风险进行了实证研究,结果表明这一方法在创业企业信用风险分析方面具有较好的可行性,为我国创业企业信用风险分析提供了一些可供借鉴的思路和方法。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
承德医学院学报(2023年1期)2023-04-16 12:36:27
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
辽宁经济(2017年6期)2017-07-12 09:27:35
当代经济(2016年26期)2016-06-15 20:27:18
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
特区实践与理论(2014年5期)2014-07-24 14:02:08
