
基于决策树的软件使用异常用户挖掘
2010-05-09 06:00刘玉峰李新友袁鼎荣
网络安全技术与应用 2010年1期
刘玉峰 李新友 袁鼎荣
广西师范大学计信学院 广西 541004
0 引言
非法登录会对系统或其所有组织造成极大的危害,而这些非法行为很可能不会被及时发现。当发现了系统的异常症状后也不容易找到非法用户对系统造成的危害。对于这样的问题,传统的方法有:就是在软件系统中增加日志功能,记录所有用户的状态信息和对系统所做的操作。但是在海量数据日志信息中找到可疑的信息,是一件极其繁琐的事情。对于这些违规异常操作使用传统的方法已经很不现实,那么如何能及时而且自动的发现系统中可疑的用户行为呢?为此,我们提出一个对软件使用异常用户的识别技术。首先我们对以往软件运行的日志数据进行预处理,得到以用户使用会话为单位的日志数据,然后我们使用统计的方法,统计出可以表现用户行为特征的属性值,作为训练决策树的数据集。利用决策树方法的ID3算法构建用户的分类模型。例如,对于利用获得的训练数据集进行训练决策树,得到三个类的分类规则,由归纳得到的规则库可以对未来使用软件的用户做出预测。根据预测的结果来决定是否有异常用户对数据库的入侵行为,根据其操作路径便于做出决策,来决定是否对数据库进行重新审核或者进行还原备份处理。
1 相关研究
我们研究的问题,实质上是对软件系统运行的日志进行挖掘。日志就是程序运行时为了记录当前状态而产生信息,它由软件工程师根据具体需求设置具体内容,如可以记录错误,程序当前状态等,用户访问信息等。以往关于日志挖掘的研究主要有:软件数据挖掘,Web使用挖掘等。
1.1 软件挖掘
软件挖掘就是对软件生命中期中产生的数据使用数据挖掘的方法找到有趣的模式从而辅助软件的各个阶段的需求。软件数据挖掘对运行时系统数据的研究从其目的上分为:系统完善与重构;源代码潜在错误检测,逆向工程等。其中主要研究有:S.Breu分析程序产生的日志信息,寻找被重复执行的函数,从而找到程序的切面。在方面挖掘方向中,分析程序日志是一个主要的研究方法。Liu在他的文章中记录测试程序函数调用的日志,然后绘制出函数调用的频繁图,在图中抽出主要特性构造出基于SVM的分类器,来检测异常程序。El-Ramly使用遗留系统中嵌入特定日志记录功能,使用频繁序列挖掘的方法找到了用户使用老系统的交互模式,然后根据找到的模式在新系统开发中用于自动生成用户的图形界面。我们的研究工作也属于软件挖掘,其目的就是增强系统在执行阶段的安全性。是数据挖掘技术在软件领域的一次应用。
1.2 Web使用挖掘
Web使用挖掘就是利用数据挖掘技术对Web日志信息进行分析从而找到浏览者的使用模式。但是传统的Web日志很难还原会话状态这一信息,虽然Tanasa提出了一个方法来还原用户会话,以角色用户行为模式分析对传统的Web日志挖掘还是很困难的,主要的研究有:Web服务器性能改进包括:页面缓存、预读取、交换、定制访问者个性化服务、分类浏览者等,主要使用数据挖掘的方法是:频繁模式和分类。现在越来越多的软件系统是基于Web,即B/S模式,Web日志的功能也被加强,不再是服务器的一个附加功能,而是软件系统中一个必需的功能。
系统日志就是系统运行时状态的记录,而日志挖掘就是利用数据挖掘方法通过分析系统运行时状态寻找系统运行时的有趣模式。
2 基于决策树的分类方法
在决策树学习方法中有各种各样的算法。其中最为著名的是ID3算法,它是Quinlan于1986年提出来的。ID3算法体现了决策树分类的优点:算法的理论清晰、方法简单、学习能力较强。缺点是:只对比较小的数据集有效,且对噪声比较敏感。当训练数据集加大时,决策树可能会随之改变,并且在测试属性选择时,他倾向于选择取值较多的属性。基本的ID3算法通过自顶向下构造决策树来进行学习,通过定义一个度量标准来衡量每一个实例属性单独分类训练样例的能力。分类能力最好的属性被选为树的根节点的测试属性,然后为根节点属性的每个可能值产生一个分支,并把训练样例划分到适当的分支(也就是,样例的该属性值对应的分支)之下。然后重复整个过程,用每个分支节点所关联的训练样例来选取在该节点被测试的最佳属性。这形成了对合格决策树的贪婪搜索(greedy search),也就是算法从不回溯重新考虑以前的选择。
2.1 ID3算法基础
ID3算法的核心问题是如何选取在树的每个节点要测试的属性,它的解决方法是利用信息理论,通过定义一个信息增益(information gain)的概念来衡量给定的属性区分样例的能力。它在增长树的每一步都使用这个信息增益标准来从候选属性中选择最佳测试属性。在信息理论中,对于一个分布P=(p1,p2,…,pn),它的信息量为:
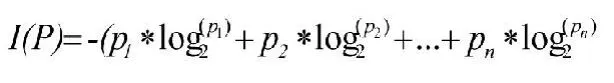
根据信息理论,假设一个数据样例集合T被无遗漏的划分为k个不同的类C1,C2,…,Ck,那么在T中识别一个样例的类别所需要的信息量为:Info(T)=I(p),其中P为类别的分布,P=(|C1|/|T|,|C1|/|T|,…,|C1|/|T|)。
如果我们用一个属性A将训练样例集T划分为m个子集:T1,T2,…,Tm,那么在划分后,在T中识别一个样例的类别所需要的信息量则为在每个子集中识别一个样例所需要的信息量的加权平均数,即:
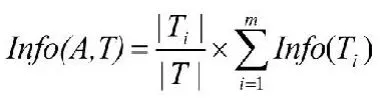
则属性A的信息增益为:
Gaub(A,T)=Info(T)-Info(A,T)
2.2 ID3算法的描述
给定一个非类别属性C1,C2,…,Cn的集合、类别属性C及记录的训练集T。
ID3算法的基本框架如下:
Function ID3(R: a set of non-categorical attributes,C: the categorical attribute,S: a training set)
return a decision tree;
Begin
If S is empty,
return a single node with value Failure;
If S consists of records all with the same value for the categorical attribute,
return a single node with that value;
If R is empty,
return a single node with as value the most frequent of the values of the categorical attribute that are found in records of S; [ note that then there will be errors,that is,records that will be improperly classified ];
Let D be the attribute with largest Gain(D,S)among attributes in R;
Let {dj | j=1,2,…,m}be the values of attribute D;
Let {dj | j=1,2,…,m}be the subsets of S consisting respectively of records with value dj for attribute D;
Return a tree with root labeled D and arcs labeled d1,d2,…,dmgoing respectively to the trees ID3(R-{D},C,S1),ID3(R-{D},C,S2),…ID3(R-{D},C,Sm);
MDL pruning(root);
End ID3;
属性的信息增益描述了这样一个概念:对于一个训练样例集T,在使用一个属性A划分T之后,从T中识别一个样例的类别所需要的信息量的减少量。通过它,可以度量属性分类训练样例集能力的大小。ID3算法正是把信息增益作为增长树的每一步中选取最佳属性的度量标准,选择信息增益作为选择属性的标准有下面两个好处:①通过最少的属性测试步骤就可以分类一个实例;②生成最短的决策树,符合“奥坎姆的剃刀”(Occam's razor)的原则。决策树学习算法是最流行的归纳推理算法之一,已经被成功的应用到从学习医疗诊断到学习评估贷款申请的信用风险的广阔领域。
3 软件日志的挖掘过程
我们针对教务处的B/S模式成绩管理系统的特定使用对象划分软件使用用户为:学生、教师、异常用户三个类别。下面对三类用户的特点进行分析和数据获取、预处理操作进行介绍。
3.1 三类用户的特点分析
3.1.1 学生
学生的使用记录是软件系统的主体对象,学生登录系统主要是查看自己各科目的成绩,登录验证后通过调用成绩显示模块(Show()函数)查看成绩,当发现自己某一门课程成绩不及格的时候,有的学生可能会产生修改自己成绩的想法,找机会获得非法登录软件系统的权限。这也就是本文要解决的问题,能及时的检测出这种行为的发生,维护数据库系统的安全。
3.1.2 异常用户
在非法窃取登录权限后,由于害怕被发现的心理作用,登录软件系统后的目的性很明确,找到相应的页面后,对自己的不及格成绩做出快速的修改(调用了Modify()函数或者Add()函数),页面停留时间很短。由于非法修改完成后不会在访问其它的页面就会立即退出,所以访问的深度不会太深。
3.1.3 教师用户
登录软件系统后,要对学生的成绩进行输入、修改、删除等操作。教师在页面操作停留的时间较长,主要访问页面是:成绩录入、修改、删除和统计等页面。访问的层次较深,调用Login()、Show()、Add()、Modify()、Statistic()、Delete()等函数。非法用户主要是获取这个权限,才能调用Modify()模块函数进行非法操作。
3.2 数据获取和预处理
针对教务处的B/S模式的成绩数据库管理系统软件,本文在构造日志函数时,主要是考虑到不同用户的会话状态、操作时间、该用户执行的程序模块调用对数据库的操作,因此我们给运行系统增加专门的日志切面,其关注点是系统中业务逻辑层中的每个函数的调用关系。从而得到如表1形式的日志内容。

表1 软件运行日志的记录及编号
软件系统运行日志内容的解释如表2所示。

表2 构造分类器的5个属性及解释
其中,表中软件系统用户操作函数路径关系如表3所示。

表3 操作函数对应的编号
决策树学习方法学习到的决策树很容易转换为if-then的规则,而且分类规则易于理解,经过以上分析我们采用ID3决策树学习的方法来构造分类器,理论上能够达到较好的分类效果。
注意到在我们所选择的5个属性当中,A1和A2的取值是连续的,A3和A4的取值虽然是离散的,但它们的取值比较多,因此我们有必要对这些属性进行离散。尽管在决策树学习算法中,能够处理连续取值的属性,但是通过把它们的取值离散可以达到提高学习效率和分类精度的目的,每个属性的值都映射为0、1或2。数据集的数据离散化处理如表4所示。
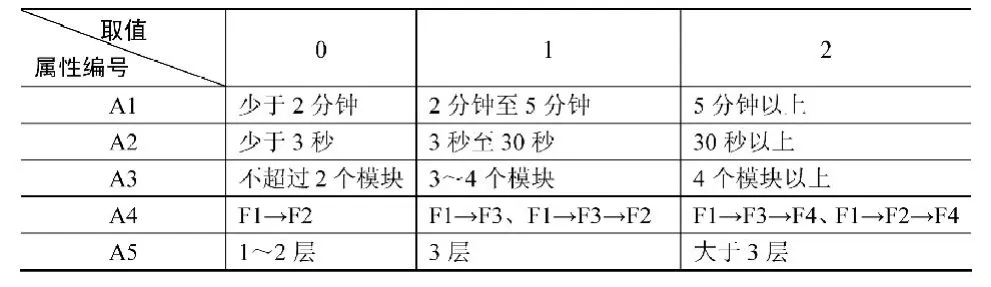
表4 属性的离散化处理
4 实验
我们从学校教务处的基于B/S成绩管理系统的历史软件运行记录日志,选取其中的9000条记录来进行实验。原始日志经过会话识别后得到3600条访问记录,我们从3600条访问记录中选取了两类访问各9条组成小训练样本集和根据异常用户的登录和操作情况构成的7条异常训练样本集来训练分类器形成规则库,便于我们以后异常用户登录系统的预测,如表5所示。读入属性和训练集生成决策树的界面如图1所示。由训练样本集生成的决策树如图2所示,其中叶节点中的0、1和2分别代表学生用户、教师用户和异常用户。
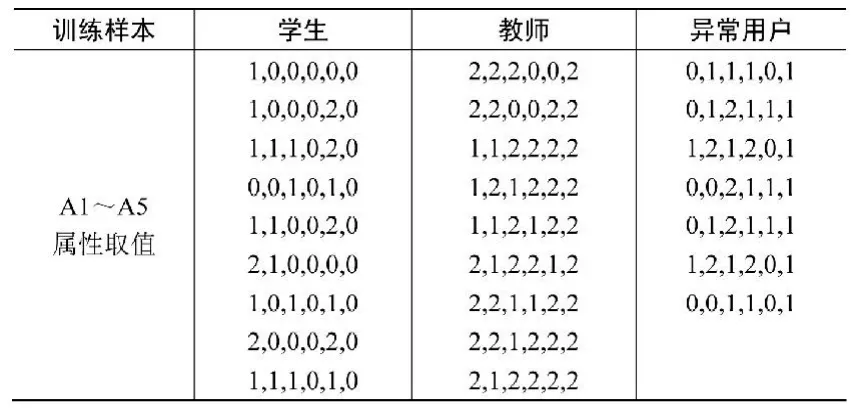
表5 包含25条记录小训练样例集
系统输入属性和训练集的界面:
生成的决策树如下:
我们从3600条会话中挑选出300条记录(包含异常用户记录)并标记出它们的类别,用生成的决策树进行分类测试,测试的结果。对三类访问者的分类精度分别为:92.1%、89.6%和83.3%,总体分类精度为90.6%。分类的准确率如表6所示。
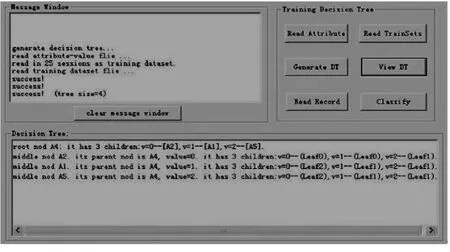
图1 读入属性和训练集生成决策树的界面
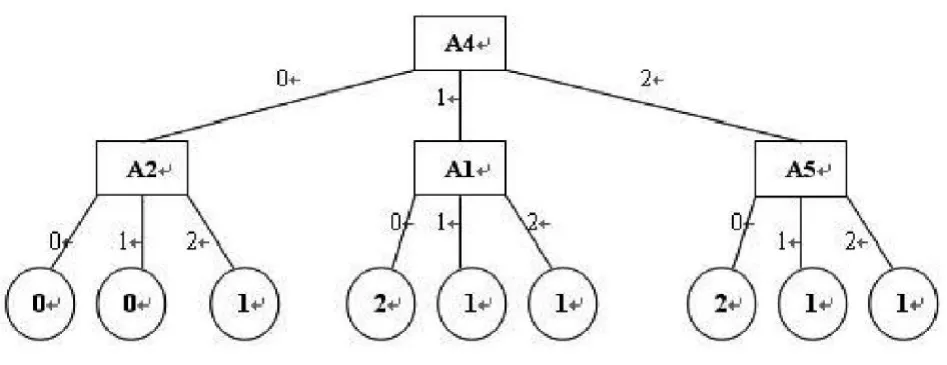
图2 训练样例生成的决策树
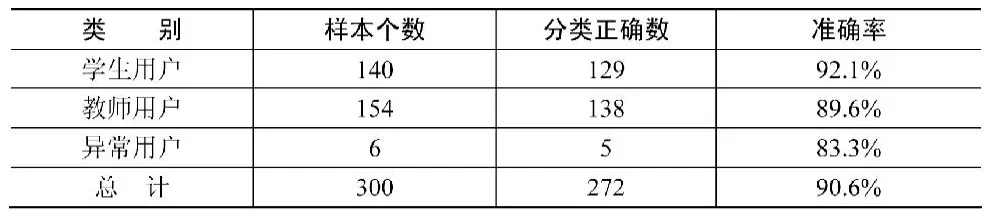
表6 决策树的分类精度
我们对诊断出来的异常用户进行分析,决定是否有异常用户对数据库系统进行了非法操作,还原出其函数操作路径,根据操作函数路径分析异常用户进行的非法修改数据库管理系统,能够及时的对数据库管理系统安全管理和维护。从中我们可以体会到对B/S模式数据库管理系统的软件用户进行分类是非常重要和必要的。
5 总结与以后的工作
本文我们先对软件系统运行日志数据进行事务还原处理,找到代表每次事务的特征属性,然后使用ID3决策树算法找到分类规则,挖掘出异常用户,而这个异常事物就代表了对系统进行异常操作的用户。我们将在以后的研究中,由于获得用户类别付出代价较大,对这个方法进行扩展,首先用聚类方法找到不同的用户类别,标记整个数据集的类别后使用决策树、SVM等方法对这类用户的使用模式建立一个模型,然后使用这个模型区分出不同类型的用户。本文讨论的系统异常用户的检测只是这方面研究的一个开端,我们会在以后的工作中不断扩展和细化这个领域的研究。
[1]S.Breu and J.Krinke,"Aspect Mining Using Event Traces,"in Automated Software Engineering,2004.Proceedings.19th International Conference on.2004.
[2]C.Liu,X.Yan,H.Yu,J.Han,and P.S.Yu,Mining Behavior Graphs for“Backtrace”of Noncrashing Bugs.SDM05.2005.
[3]M.El-Ramly,E.Stroulia,and P.Sorenson,From run-time behavior to usage scenarios: an interaction-pattern mining approach.Edmonton,Alberta,Canada: ACM.2002.
[4]D.Tanasa and B.Trousse.Advanced data preprocessing for intersites Web usage mining,Intelligent Systems.IEEE.2004.
[5]Han Jiawei,Kamber M.范明,孟小峰译.数据挖掘:概念与技术[M].北京:机械工业出版社.2001.
[6]毛国君,段立娟,王实等.数据挖掘原理与算法[M].北京:清华大学出版社.2005.
[7]Tom M.Mitchell.曾华军,张银奎译.机器学习[M].北京:机械工业出版社.1998.
[8]Chang K.C,He B,Li C,Patel M,Zhang Z.Structured dat- a bases on the web: Observations and Implications[J].SIGM- OD Record.
[9]Robert Cooley,Bamshad Mobasher and Jaideep Srivastava.Data Preparation for Mining World Wide Web Browsing Patterns.Knowledge and Information System.1999.
猜你喜欢
心理学探新(2022年1期)2022-06-07
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
广东教学报·教育综合(2020年15期)2020-03-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
