
基于向量空间模型的自动摘要冗余处理研究
2010-03-26 02:33:20张筱丹胡学钢
合肥工业大学学报(自然科学版) 2010年9期
张筱丹, 胡学钢
(1.合肥工业大学计算机与信息学院,安徽合肥 230009;2.安徽农业大学信息与计算机学院,安徽合肥 230036)
0 引 言
随着信息技术的飞速发展和互联网的普及,文本资源呈现出几何级的增长。但是,网络上的信息量大,更新速度快,用户很难迅速地找出目标信息。自动文摘是继信息检索之后信息或知识获取的一个重要步骤,对高质量的文档文摘十分重要[1]。自动文摘是利用计算机从文章中自动提取内容生成摘要的方法,其中摘要应包含原文的核心内容或用户感兴趣的内容,并以语意连贯的段落乃至篇章的形式输出[2]。因此,自动摘要是文本信息处理中重要的基础性工作。
自动文摘系统的研究起源于20世纪50年代末,文献[3]提出了可以用计算机进行文献的压缩。我国对中文自动文摘的研究起步较晚,1985年才有学者正式撰文介绍国外自动文摘方面的研究情况。20世纪80年代有学者将人工智能中一些理论应用在自动摘要中,90年代开始基于统计的自然语言处理方法再次兴起,受此影响,自动摘要系统中统计方法的研究逐渐增多[4]。自动摘要技术总体上分为2类:基于机械统计的方法和基于知识理解的方法。
基于机械统计的方法[5,6]利用统计信息获取文档的关键词,并结合提示词、位置等启发信息,从文档中挑选出一些合适的句子,进行润色后得到文档的摘要。机械统计方法具有速度快、领域不受限的特点,但生成的摘要质量较差,存在反映内容不够全面以及语句冗余等问题。基于知识理解的方法[7,8]利用各种知识和形式化理论,在理解文档语义内容的基础上生成文摘(对原文的概括或浓缩)。与机械统计方法相比,理解摘要质量较好,具有简洁精炼、全面准确及可读性强等优点。但是,理解摘要不仅要求计算具有自然语言理解和生成能力,还需要表达和组织各种背景、领域知识。这些工作的难度十分巨大,迄今为止进展甚微。
本文针对以上2类方法存在的不足,提出了一种利用向量空间模型进行冗余处理的自动摘要方法。该方法以统计为基础,利用向量空间模型解决语句冗余问题,有效提高了摘要质量,同时设计了一个中文自动摘要系统。
1 相关工作
1.1 向量空间模型
向量空间模型(Vector Space M odel,简称VSM)是一种较著名的用于文档表示的统计模型,该模型以特征项做为文档表示的基本单位,特征项可以由字词或短语组成。每一个文档可以看成是由特征项组成的n维特征向量空间的一个向量,即

其中,W i为第i个向量T i在文档中的权重,一般选词做特征项比选字做为特征项要好一些。最初的特征向量表示完全用0和1表示,如果文本中出现了该词则文本向量的维为1,否则为0。这种方法无法体现这个词在文本中的作用程度,所以0和1被更精确的词频代替。一般使用TF-IDF公式计算特征项权重,其中TF(Term Frequency,简称TF)表示词频,IDF(Inverse Docum ent Frequency,简称IDF)表示逆文档频率,反映文档集合中出现该特征项的文档数目的频率,TF-IDF权重的计算公式为:其中,W(t,d)为词t在文本d中的权重;tf(t,d)为词t在文本d中的词频;N为训练文本的总数;nt为训练文本集中出现t的文本数;分母为归一化因子。
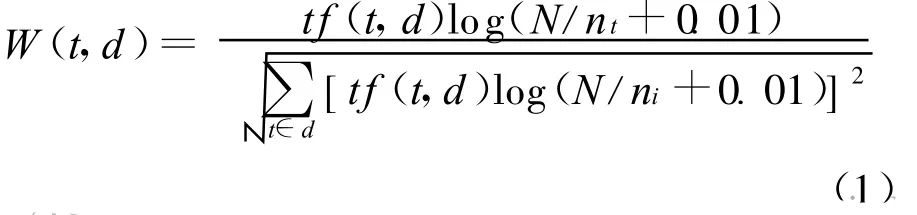
1.2 自动摘要的依据
在自动摘录中,计算词权、句权和选择文摘句的依据是文本的6种形式特征:
(1)词频。能够指示文章主题的所谓有效词(SignificantWords)往往是中频词。根据句子中有效词的个数可以计算句子的权值,文献[3]首先提出了自动摘录方法的基本依据。分析文章时,往往需要统计词语出现的频率,因为文章中一般出现频率高的词语能表示文章的中心内容。
(2)标题。标题是作者给出的提示文章内容的短语,借助停用词词表(Stoplist),在标题或小标题中剔除功能词或只具有一般意义的名词,剩下的词和原文内容往往有紧密的联系,可以作为有效词。由于新闻报道的特殊性,新闻标题一般更简洁,与新闻报道的内容联系更紧密,对摘要的生成起重要作用。
(3)位置。句子的位置可以指句子在文章中的位置、在段落中的位置或在章节中的位置。一般地,一篇文章中的首句、末句,每个段落中的首句、末句等都是和句子中心内容紧密相关的,因此,有必要提高处于特殊位置的句子的权值。
(4)线索词。线索词是指能提示文章主题出现的词,如“总的来说”。另外,专有名词如人名、机构名等也可看作是线索词。包含线索词的句子在分析时应给予一定的重视。
(5)句法结构。句式与句子的重要性之间存在着某种联系,如文摘中的句子大多是陈述句,而疑问句、感叹句等则不宜进入文摘。
(6)指示性短语。1977年,英国Lancaster大学的Paice提出根据各种“指示性短语”来选择文摘句的方法[9]。和线索词相比,指示性短语的可靠性要强得多。
2 基于VSM的自动摘要冗余处理
2.1 基本思想
对新闻网页过滤后的文本首先进行分词,根据句子中词语的重要性以及句子的位置,抽取文本的初始文摘,将初始文摘中的句子表示成向量形式,利用向量空间模式中计算2个向量相似度的公式,计算原始文摘中句子的相似性,去除相似性比较大的冗余句子,从而得到自动摘要的冗余处理。
假设原文中包含的词为W1,W2,…,Wn,则每个句子都可以表示为n维向量:T=〈T1,T2,…,Tn〉。Ti(1≤i≤n)的计算方法为:设n为W i在这个句子中出现的个数,m为其它所有句子中含有Wi的句子的个数,M为句子的总数,那么Ti=n log(M/m)。
用同样的方法[10],可以计算目标句子的n维向量T′=〈T′1,T′2,…,T′n〉。2个句子T和T′之间的相关程度常常用它们的相似度Sim(T,T′)来度量。在向量空间模型下,借助向量之间的夹角余弦值来表示文本间的相似度,即
利用(2)式计算出2个句子的相似度,当相似度达到给定阈值,说明句子之间的相似度很大,存在冗余,将其中权值较小的句子从文摘中删除,进而达到去除冗余的目的。
2.2 算法描述
算法:基于向量空间模型文本摘要的自动生成。
输入:新闻网页URL地址;生成摘要的百分比;原文最小长度阈值。
(1)对原始新闻网页进行预处理,过滤掉其中存在的一些广告链接、导航链接或图片信息等。在进行自动摘要之前首先要对Web新闻网页进行前期处理工作,去除页面中无用信息,保留文档正文。
(2)对抽取出来的正文文本长度进行统计,如果原文长度超过给定的阈值,则对原文进行分词处理。如果正文长度不超过设定的阈值,则不再进行分词等操作,直接将原文作为文摘结果输出。
(3)按(3)式计算词语ti在文档d中的TFIDF i值,从高到低抽取若干词语作为原文的关键词,即
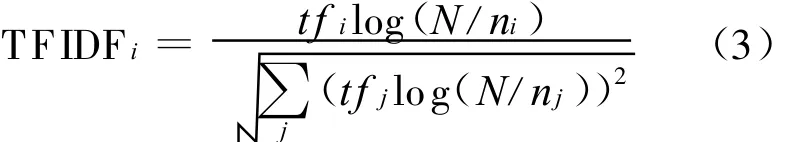
其中,t fi为词语ti在文档d中出现的频率;N为所有文档的数目;ni为包含词语ti的文档数目;分母是归一化因子。
(4)根据标题关键词、抽取的关键词、句子的位置信息计算句子的权值,按权值大小排序,选取权值高的若干句子作为初始文摘句。
(5)原始文摘中句子表示成向量形式,计算任意2个句子的相似度,删除相似度高的冗余句,得到原文的最终摘要句。
3 实验和分析
3.1 自动摘要评价标准
由于文档摘要所具有的不确定性,因此在摘要质量的评估上缺乏比较理想的定量评估方法。对自动摘要的结果进行自动评估成为一个难题,目前还没有比较理想的定量评价方法能进行自动评估,所以一般用人工摘要结果与之相比较,而摘要评估方法采用主观评价和客观评价2种。
3.1.1 主观评价
本文探讨了基于HPLC-DAD稻谷中叶黄素的提取方法,通过单因素试验确定了各个因素的最佳条件。应用响应曲面法对四氢呋喃用量、KOH甲醇溶液质量浓度和提取温度三个因素进行优化,建立具有良好拟合度的回归模型,得到最佳的提取方法为四氢呋喃用量15.5mL、KOH甲醇溶液质量浓度0.1g/mL、提取温度51℃,稻谷中叶黄素提取量为(1.63±0.03)μg/g。该方法缩短了反应时间,避免了游离叶黄素的分解和异构化,具有较好的重复性。
主观评价包括:①完全性,即摘要是否能完全反映文档的主要内容,是否有遗漏;②冗余性,即句子不能有重复;③可读性和可理解性,即文摘句前后连贯,意义相承,语句流畅。
本系统生成的文摘属于机械性文摘,所以可读性和可理解性要差些。由于是按照段落抽取文摘,能保证其完全性;根据文中提到的句子相似度计算,去除文摘中的冗余,可以保证文摘句子没有重复。
3.1.2 客观评价
一般用准确率和召回率来衡量摘要的质量,两者的数值越高说明摘要的质量越好。假设自动摘要出的句子集为X,人工摘要出的句子集为Y,则准确率和召回率可采用以下方法进行计算。
(1)准确率(P)。它是自动摘要结果中属于应摘出的句子数目和自动摘出的所有句子数目的比值,即

(2)召回率(R)。它是自动摘要结果中属于应摘出的句子数目和应该摘出的句子数目的比值,即

如某篇文章在文摘长度占文章比例10%时,系统抽取出文摘句子数为8句,该文章的专家文摘抽取的句子数量为12句,同时存在于文摘系统和专家文摘句中的句子数量为5句,则系统在该文章的文摘长度为10%时,有

3.2 内部测评
实验的测试语料集来源于网易163网站http://new s.163.com.cn上抓取的新闻,涵盖了军事、科技、体育等10个类别的文档集,在每个类别中随机抽取10篇新闻,这样共得到10个类别的500篇文档。
测试文档类的类名及其包含的文档数目,见表1所列。

表1 文本摘要测试数据集
在硬件环境CPU Celeron1.7 GH z,内存512 M;软件环境W indow s XP,Java6.0上实现了自动文摘系统。文本平均测评参数,见表2所列。此摘要系统的质量虽然不能和人工摘要质量相比,但处理速度还是令人满意的。
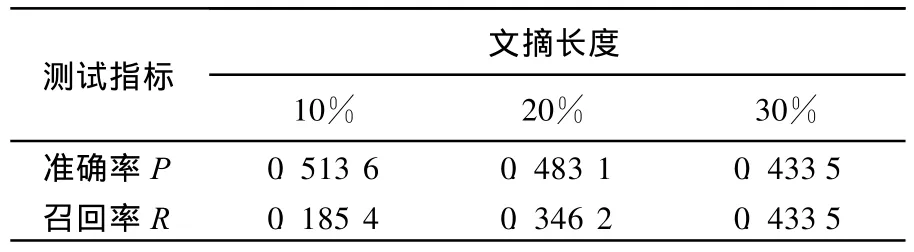
表2 自动文摘评价参数
从表2可以看出,随着抽取摘要长度比例的增加,准确率呈下降趋势,而召回率呈上升趋势。这是因为随着抽取摘要长度的增加,抽取的文摘句数也增加,抽取的句子数增加的趋势大于抽取的文摘句增加的趋势,所以准确率有所下降;原文实际的文摘句始终保持不变,所以准确率呈上升趋势。
4 结束语
Internet上的文本自动摘要是一个涉及多学科领域知识的应用技术,而中文分词技术有待进一步突破;网页中结构化信息的比例增大,虽然有助于自动摘要的质量提高,但最根本的还是文本理解技术要有本质性的突破。针对Internet上新闻网页的特征,本文提出了一套新的自动摘要方案:首先将新闻网页预处理,过滤掉其中的噪音;然后对文本内容进行分词及提取关键词,生成初步文摘;最后对文摘进行冗余处理,生成文字流程且具备一定质量的文摘。
理论和实验结果表明,该方法具有不受领域限制、摘要内容全面及摘要比例可调等优点。在今后的工作中,将进一步提高文摘生成的速度,适当利用一些自然语言理解技术来改进文摘的质量,从而提高Web文摘生成系统的性能。
[1] 江开忠,李子成,顾君忠.自动文本摘要方法[J].计算机工程,2008,34(1):221-223.
[2] 官礼和.Internet网络新闻文本自动摘要的研究[J].计算机工程与设计,2007,28(14):3518-3521.
[3] Luhn H P.The automatic creation of literatu re abstracts[J].IBM Jou rnal of Research and Developm ent,1958,2(2):159-165.
[4] 尹存燕,戴新宇,陈家骏.Internet上文本的自动摘要技术[J].计算机工程,2006,32(3):88-90.
[5] 王文欣,黄萱菁.基于统计方法的汉语自动文摘系统研究[J].计算机应用与软件,2000,17(9):28-33.
[6] 王永成,许慧敏.OA-1.4版中文自动摘要系统[J].高技术通讯,1998,(1):19-23.
[7] 吴 岩,刘 挺.中文自动文摘原理与方法初探[J].中文信息学报,1998,12(2):8-16.
[8] 孙春葵,李 蕾.基于知识的文本摘要系统研究与实现[J].计算机研究与发展,2000,37(7):874-881.
[9] Mathis B A,Rush JE.Abstracting en cyclopedia of compu ter and technology[M].New York:Marcel Dekker Inc,1975:102-142.
[10] 秦 兵,刘 挺,王 洋,等.基于常问问题集的中文问答系统研究[J].哈尔滨工业大学学报,2003,35(10):1179-1182.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
环境影响评价(2020年2期)2020-12-02 01:23:50
作文评点报·低幼版(2017年27期)2017-08-31 16:09:11
宝藏(2017年2期)2017-03-20 13:16:46
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
作文评点报·低幼版(2014年22期)2014-07-10 23:19:28
作文评点报·低幼版(2014年5期)2014-03-12 14:12:11
Water Science and Engineering(2014年1期)2014-03-06 06:21:56
电脑迷(2012年4期)2012-04-29 06:12:13
