
基于本体的食品安全信息整合模型
2009-08-25 09:37张玉学
新媒体研究 2009年15期
[摘要]分析食品安全信息资源整合的现状及存在问题。根据食品信息资源分布的特点,借助本体(Ontology)在信息共享应用中的优势,构建一种新型的基于本体的食品信息资源整合模型。阐述该模型的思想及结构,在一定程度上解决食品信息系统“信息孤岛”的问题。
[关键词]食品安全信息 整合 本体
中图分类号:Q50文献标识码:A文章编号:1671-7597(2009)0810103-02
目前,我国已从解决温饱型的社会向全面小康转变,人民对食品关心的是“吃得好,吃的健康”的问题,但是近几年来,食品安全事件频繁发生,08年三鹿奶粉事件的发生,把人民群众对食品安全的关注推到顶点,促进了食品安全法的诞生。
食品安全跟法律法规、科学技术和公民道德有关,也跟监管技术、力度等相关。作为一种监管技术,我国目前的食品安全信息管理系统由于系统建设的阶段性、技术性和一些人为的因素,造成了在各行政部门和食品企业内部积累着大量的采用不同方式存储的业务数据,形成了一个个信息孤岛。近年来,源自哲学的本体论的研究日益成熟,已经超过了哲学的范畴,本体论逐渐用于信息科学和知识工程等领域,在信息共享方面享有较大优势[1]。
一、目前食品安全信息整合的若干方案及存在问题
(一)定制转换工具
在不同数据源之间定制专用的转换工具,实现数据的交流与共享,例如使用各种电子数据交换(EDI)软件进行数据交换。该方式技术较为简单,但存在实现成本高,系统扩展性差,数据存在多个备份,难以保持一致性等不足,正在被新的数据集成方式逐步取代[2]。
(二)集中复制数据
以建立数据仓库为典型,通过对异构数据源中的数据进行分析、转换和装载,将各个数据源中的数据移入数据仓库,实现异构数据源中数据的集中式管理、集中式存储,其优点是原来分散的应用系统仍然独立运作,不会破坏原有的应用架构;可以集成多种数据源和复杂的商业规则,数据集成质量好。但是通过集中复制数据实现数据集成,只能定期更新数据,无法实时变化,而且每当现存的异构数据源的数据库模式发生变化或一个新的数据源加入到系统中,就必须重新生成一次全局模式,使得维护全局模式十分困难,系统可扩展性差。
(三)数据集成中间件
利用中间件集成异构数据源。中间件作为一种基于分布式处理的独立软件成分或服务程序,具有标准的程序接口和协议,可实现不同软硬件平台上的数据共享和应用互操作。负责数据集成的中间件系统位于异构数据源(数据层)和应用程序(应用层)之间,向下协调各数据库系统,向上为访问集成数据的应用系统提供统一的全局数据模式。中间件技术由于数据源自治性好、查询实时、配置灵活等优点,自出现以来被广泛应用,但还是面临如何更好地解决语义异构的问题[3]。
二、Ontology
Ontology(本体)最早是一个哲学概念,是对客观存在的一个系统的解释或说明,关心的是客观现实的抽象本质。近年来,许多计算机领域的专家和学者都应用了这个概念。1998年,Studer等给出了一个广为流行的定义,即“本体是共享概念模型的明确的形式化的规范说明”。这个定义包含四层含义:概念模型明确、形式化和共享。简单的说,本体就是关于某个领域内人们公认的一个概念集,其中的概念含有公认的语义,这些语义通过概念之间的各种联系来体现。
三、异构数据源整合模式
信息整合技术是信息资源分布式建设与集成应用相互作用的产物[4]。
在信息资源海量化、信息渠道多元化、信息载体多样化的互联网时代,信息管理技术已经历了三个发展阶段,目前已进入数据结构多元化、存储异构化的时代。信息整合已经成为信息管理技术的必然趋势。它的目标是通过一个公共的方法来访问不同数据源[5]。
本体是共享概念的基础,反过来它又帮助我们实现对数据的一致性的解释。可以采用全局本体库的思想解决应用系统的数据源异构问题,其模型图如图1所示:

各个层次的功能说明如下:
1.数据源层:提供了各种不同存储方式的数据,来自于系统的各个应用子系统。针对不同的数据源编写不同的CORBA包装器,无论是Windows下的数据源还是Linux下的数据源,都可以进行透明的连接。
2.网络层:网络层是基于已有的网络通信协议,通过对等层之间的协商端口传输数据,完成与上层之间接收和发送数据流,同时还要接收更底层的异常信息,来判断是否发送、接收和保存数据流。
3.数据整合层:经过包装后的数据,存储在各个包装器中,我们通过创建一个全局本体,将这些异构的数据转化成统一的数据模式,消除数据之间的语法和语义差异。
4.信息服务层:经过整合后的数据具有一定的完整性、一致性和安全性,可以为高级应用,诸如数据挖掘、高层决策等提供更为精确的服务。可以说大大提高了工作效率和决策的质量,在一定程度上大大增加食品安全评估的科学性。
四、数据整合层的设计与实现
数据整合层为食品安全端提供一个统一的接口对数据源进行查询,负责接收来自浏览器的全局查询请求,再根据相应的集成信息,将全局查询请求分解为多个局部查询请求传递给包装器,最后将包装器返回的结果进行处理后送回浏览器,同时还要维护
集成信息,保证全局事务执行的正确性和一致性。数据整合层主要由查询规划模块和结果合并过滤模块构成。
查询规划模块的设计:
查询规划模块负责将食品安全端提交的标准查询分解成针对各个异构数据库的子查询并提交到相应的包装器,涉及到请求的连接、排队、转发等方面的技术。图2为本模块的系统结构。
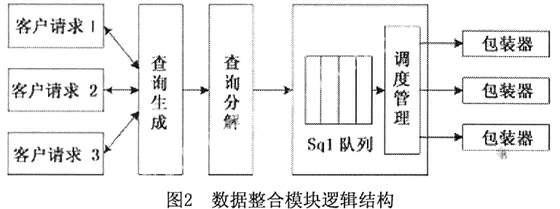
1.查询生成器
查询生成器负责接收用户由浏览器查询界面提交的查询请求,并根据本体库中全局本体定义的概念信息将用户请求实例化为内部统一的可识别的全局查询语句。
2.查询分解引擎
查询分解引擎的主要任务是进行查询分解工作。它主要负责接收查询生成器传递的全局查询语句,分析局部本体定义信息,确定要查询的局部数据源,并调用映射规则中全局本体和局部本体的对应关系执行分解算法,将全局查询分解为对应各局部数据源的子查询。
3.查询执行引擎
查询执行引擎由队列管理和调度策略子模块组成。队列设管理对生成的sq1子查询进行数据的接收、排队,再经过调度管理子模块发送到相应的包装器执行。调度管理模块采用基于FIFO调度策略的队列管理机制,调度线程首先取队列的头元素,然后判断其属性参数,最后发送到相应包装器执行。
4.结果合并过滤模块
模块通过包装器实现对各个异构数据库的查询访问,获取结果集。此结果集包含了不同数据库的查询结果,由数据库中的行数据构成。对于该数据必须进行判断,如果是重复的数据,就要进行合并过滤,返回惟一值。对于2个行数据的集成,需要定义每个行数据的关键属性组,这个关键属性组(如食品名称和出厂日期)用于判定2个同类的行数据是否为同一实体。当2行数据的关键属性组的值对应相等时,并不能像标识属性值相等时那样简单地过滤掉其中一个信息对象,而是将2个信息对象集成为一个包含更大信息量的信息对象。集成的方法是:如果2行数据的同属性取值相等,则集成信息对象中该属性的值取任一行数据的对应属性值;如果2行数据除关键属性组外的属性取值不同,则删除一行数据的相同属性值,并把剩余的属性值连接到另一行数据的末尾成为同一行数据输出。
五、小结
当一些数据分散在众多的资源中,或者以多种形式存在,那么必然会有一个统一的系统来整合这些数据。本文分析了目前食品信息资源整合方法存在的一些问题,结合Ontology在知识表示、共享及推理方面的优势,提出了基于Ontology集成的信息整合方案,为解决食品安全信息资源整合指出了一条新思路。随着本体表示、集成及推理技术的日益成熟,将会构建一个更加智能的信息整合和综合查询系统来满足食品安全信息化的需求。
参考文献:
[1]郭浩军、王海娇,一种基于Ontology的电力信息资源整合模型,东北电力技术,2008(7),17~18.
[2]周刚、郭建胜、石磊,基于本体的异构数据源集成系统分析与设计,北京联合大学学报(自然科学版),2007,21(1):45~46.
[3]娄雅斌、陶凤梅、马垣,基于“本体”的异构数据源的集成方法研究,微计算机信息,2005,21(10):116~118.
[4]王冬云,关于数字图书馆信息整合的思考,现代情报,2007,7(7):
73~74.
作者简介:
张玉学(1977-),女,江苏江阴人,本科,讲师,研究方向为:计算机科学与应用。
猜你喜欢
小天使·聪聪画刊(2022年6期)2022-06-21
哈哈画报(2021年10期)2021-02-28
中国建筑金属结构(2018年6期)2018-08-31
科技创新导报(2016年32期)2017-04-22
知音励志·社科版(2016年8期)2016-11-05
人间(2016年26期)2016-11-03
考试周刊(2016年76期)2016-10-09
成才之路(2016年26期)2016-10-08
成才之路(2016年25期)2016-10-08
小学教学参考(语文)(2016年9期)2016-09-30
