
网络环境下的信息检索与数据挖掘技术
2009-07-10 09:03陈维阮海红
现代情报 2009年5期
陈 维 阮海红
〔摘 要〕首先对网络环境下信息检索的现状进行分析,主要介绍网络信息检索的代表工具—搜索引擎的工作原理、缺陷及发展方向,引出数据挖掘技术,并进一步对WEB数据挖掘技术作了概要的介绍,阐明WEB数据挖掘技术是网络信息检索智能化的重要发展方向之一。最后,提出一个结合数据挖掘技术的新的搜索引擎结构模型。
〔关键词〕信息检索;搜索引擎;WEB数据挖掘
〔中图分类号〕G250.73 〔文献标识码〕B 〔文章编号〕1008-0821(2009)05-0144-03
Information Retrieval and Data Mining in the Network EnvironmentChen Wei Ruan Haihong
(Library,Zhejiang University of Media and Communications,Hangzhou 310018,China)
〔Abstract〕Based on the analysis of information retrieval in the network environment,this paper introduced the working principle,defects and development of search engine which was a kind of typical tools of information retrieval.Then,data mining and its applications in the web were introduced.It was illuminated that web data mining technology was an important development of intelligentized information retrieval.A new search engine structure model which was combined with data mining was presented in the end.
〔Keywords〕information retrieval;search engine;WEB data mining
随着网络应用的普及,网上信息量以惊人的速度增长。网络信息资源具有数量巨大,增长迅速,形式多样,分布广泛,结构复杂等特点。人们面对的问题不再是缺乏有用信息,而是如何高效地找到自己所需要的信息。但目前的现状是“数据丰富,但信息贫乏”,人们迫切需要能够从网络上快速、有效地发现资源和知识的工具。
网络搜索引擎的出现部分地解决了资源发现问题,但是它检索效率低,往往会返回给用户成千上万个检索到的网页,存在大量的隐性信息,其中很大一部分与用户的检索要求无关,用户不能快速、准确地得到所需的有价值的信息,无法满足用户个性化的需求。此外,搜索引擎的目的在于发现网络上的资源,就网络上的知识发现而言,即使检索精度再高,搜索引擎也不能够胜任。因此,人们需要比信息检索层次更高的、能包含网络数据库在内的新的数据挖掘技术,以更有效的手段对各种大量数据进行挖掘并发挥其潜能[1]。
数据挖掘正是在这样的应用需求环境下产生并迅速发展起来的。但是,数据库领域采用的数据挖掘技术所涉及的多是结构化数据,为了处理WEB上的异质、非结构化或半结构化数据,WEB数据挖掘成为数据挖掘研究的一个重要分支。尽管WEB数据挖掘是比网络信息检索更高层次的技术,但它并不是用来取代网络信息检索技术的,二者是相辅相成的[2]。
1 网络信息检索
信息检索(information retrieval)作为一门学科,其历史可追溯到20世纪中期。在此之前,信息存储和传播主要以纸质介质为载体,信息检索活动也围绕着文献的获取和控制展开。20世纪50年代,计算机技术开始得到实际应用,“情报检索”也开始与IT技术紧密结合,从而产生了现代意义的“信息检索”[3]。
信息检索主要是研究如何获取WWW上的信息资源,又称为Web信息检索[4],它有以下几个特点[5]:大数据量、分布式、多用户、非专业。网络信息资源检索的上述特点,造成了网上信息获取的障碍。从20世纪60年代以来,信息检索领域在索引模型、文档内容表示、匹配策略等方面取得了许多研究成果。这些成果被成功地应用在WEB上,产生了搜索引擎,著名的有Google,Yahoo!,Altavista等。
1.1 搜索引擎的工作原理
常见的Web信息检索系统的具体实例是搜索引擎。搜索引擎(Search Engine)[6]指对www站点资源和其他网络资源进行标引和检索的一类检索系统机制。其基本功能通常包含三部分:(1)下载Web文档和有关的信息资源到本地进行预处理;(2)对文档内容建立索引;(3)搜索引擎按照用户提出的检索请求,通过建立的索引检索出匹配的文档及其相关的链接返回给用户。
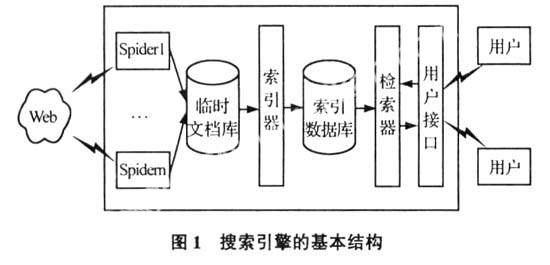
搜索引擎通常有6个相对独立的基本组成部分:Robot、临时文档数据库、索引器、索引数据库、检索器和用户接口。Robot(又叫做Crawler、Spider、Worm等)是一个能利用HTTP协议获取Web页面并沿着HTML文档中的超链在Internet上自动漫游的程序,对Internet进行系统、全面的遍历,将分布在不同Web服务器上的信息资源收集下载到本地存储在临时文档数据库中;索引器对下载的文档进行预处理,依据所使用的检索模型对文档进行形式化表示,建立索引后存储在索引数据库中以提高系统的检索效率;用户接口依据所使用的Web信息检索模型对用户提交的查询进行分析,并由检索器在索引库中查找匹配文档,计算各个文档与查询的相关度;最后,将相关的文档按照相关度递减的顺序排列作为检索结果返回给用户。其结构如图1所示[7]。
1.2 搜索引擎的缺陷
1.2.1 逻辑运算符
现有的搜索引擎提供的提问函数是相当有限的,大多数的搜索引擎只提供关键词间最基本的布尔连接。例如Yahoo只提供AND和OR运算,并且一旦选用了一个逻辑运算符,它必须应用于所有的关键词。OpenTextIndex允许用户用不同的布尔运算符,但仅运行4个运算符且必须按出现次序运算。像SQL语言那样复杂的查询语言在现有的搜索引擎中还不能应用。
1.2.2 仅使用关键词提问
现有的搜索引擎仅允许用一组关键词及逻辑运算符组成提问。但关键词检索不能完全满足用户的要求,而且它是一种盲目的匹配。而自然语言理解又是非常困难的任务,现在仍在研究之中。
1.2.3 简单的结果表示方法
大多数的搜索引擎都只返回一张长长的检索结果表,一般有好几页。该表中可能包含成千上万个指向Web站点的链接指针。用户可能只选择一小部分,而放弃其余部分。因为用户不可能有这么好的耐心。结果是他们可能丢失了很多有用的信息。
1.2.4 单个引擎的限制
由于现在Web上的信息量变得越来越大,单个搜索引擎不可能包括整个网络的轨迹。索引机器人的能力,索引数据库的大小,系统维护开销等,都限制了一个搜索引擎的能力,因此,用户必须尝试用所有搜索引擎去找出他所要的信息。最坏的是每个引擎互相覆盖,用户会重复发现一条信息。现在已出现了一些解决方法,如元搜索引擎和分布式搜索引擎。
1.2.5 不能利用检索历史信息
用户的每次检索都是从头开始的检索,不能从原有的查询结果中作进一步的提炼。
1.3 网络信息检索的发展方向
通过上面的分析可以看出,当前搜索引擎所使用的技术都难以解决“找信息难”的问题。造成这种困难的实质在于搜索引擎缺乏知识处理能力和理解能力,对要检索的信息仅仅采用机械的关键词匹配来实现,对所检索到的结果只经过简单的处理就直接送给用户,由用户自己逐个浏览取舍。
如何使WEB信息检索的智能化程度更高,更能满足用户的需求,一个很有发展潜力的方法就是:将WEB数据挖掘技术引入到WEB信息检索领域中来。下面,将概括介绍一下WEB数据挖掘技术,以及WEB数据挖掘和WEB信息检索的关系。
2 WEB数据挖掘
数据挖掘(Data Mining)是指从大量的数据中挖掘那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识,它是一门涉及面很广的交叉学科。WEB挖掘[8]从数据挖掘发展而来,但是,WEB挖掘与传统的数据挖掘相比有许多独特之处。WEB挖掘是指从大量、异质、分布的WEB文档的集合中抽取感兴趣的、有用的模式和隐含信息。
一般地,WEB挖掘可分为三类[9]:WEB内容挖掘(WEB Content Mining)、WEB结构挖掘(WEB Structure Mining)和WEB使用记录的挖掘(WEB Usage Mining)。
2.1 WEB内容挖掘
WEB内容挖掘是从文档内容或其描述中抽取知识的过程。由于WEB文档绝大部分内容是以文本形式存在,所以WEB内容挖掘主要针对的是WEB文档的文本部分。文本挖掘主要包括直接对WEB页面文档内容以及搜索引擎的查询结果进行文本的总结、分类、聚类、关联分析等。除了文本数据挖掘以外,还有针对多媒体数据等的挖掘。
2.2 WEB结构挖掘
WEB结构挖掘是从WWW的组织结构和链接关系中推导知识。由于文档之间的互连,WWW能够提供除文档内容之外的有用信息。利用这些信息,可以对页面进行排序,发现重要的页面。
2.3 WEB使用记录的挖掘
WEB使用记录挖掘的主要目标则是从WEB的访问记录中抽取感兴趣的模式。WWW中的每个服务器都保留了访问日志(WEB Access Log),记录了关于用户访问和交互的信息。分析这些数据可以帮助理解用户的行为,从而改进站点的结构,或为用户提供个性化的服务。
WEB数据挖掘和WEB信息检索是2种不同的技术,WEB数据挖掘是数据挖掘领域的一个分支,属于知识发现的范围,而WEB信息检索是以检索信息为目的的,属于信息查询的范围,从这个角度上来看,WEB数据挖掘技术的层次要比WEB信息检索高。但是因为WEB内容和结构特有的复杂性,使得WEB数据挖掘和WEB信息检索之间的界限并不像数据库领域中的数据挖掘和数据查询之间的界限那样直观分明。我们可以通过对数据挖掘若干技术的研究,来解决WEB信息检索中搜索引擎的模型,WEB上文本信息的预处理(即:文本分类),WEB上的知识发现及对WEB上已经获得知识的维护等问题,所以说WEB数据挖掘技术是WEB信息检索智能化的重要发展方向。
3 一个新的搜索引擎结构模型
按照搜索引擎的结构模型不同,目前搜索引擎系统可以分为两大类:两层结构(客户/服务器)、三层结构(客户/中间层/服务器),如图2、3所示。但是,由于这些模型的缺陷,它们所构造的搜索引擎并不能满足用户需求。

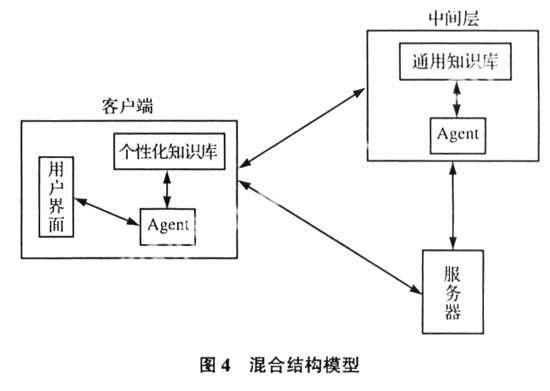
这里我们建立一个新的模型,如图4所示,其结构是三层,但是它的工作方式界于两层和三层之间,所以这里称该模型为混合模型。它的工作方式是首先在客户端根据用户在用户界面输入的查询信息,由Agent判断个性化知识库中是否含有相关知识,如有则构成查询语句后提交给服务器端,如果无则与中间层的Agent相联系,由Agent通过通用知识库来获得相关知识并加入个性化知识库,然后构成查询语句后提交给服务器端,由服务器查询并将结果返回给客户端的Agent,由它处理后给用户界面,并根据用户的使用来更新个性化知识库,这个过程随着用户查询不断进行,逐渐完善用户的个性化知识库。
实现此模型关键是依靠WEB挖掘中的一些技术。
3.1 数据分类技术
将WWW上的资源进行分类,一方面利于资源管理,同时在查询时可以缩小范围,进行快速查询;另一方面有利于构建知识库,避免了多义词问题。例如:“美洲豹”在动物类中,我们知道它一定是一个动物的种类;如果在汽车类中,可以知道它是一个汽车品牌;在足球比赛中,可以知道,它一定是一个球队名字。因此在一个词在类中,好比它有了上下文,因此在很大程度上解决了多义词的问题。针对WWW上的数据特点,可以采用适应非在线和在线不同情况的分类算法。
3.2 关联规则
关联规则是发现大量数据中项目集合之间的关联或相关关系。它应用到WWW上,可以有助于发现用户的行为,从而有利于方便建立用户的知识库。
模型中对发现关联规则加上时间这个因素,可以发现周期性关联规则。同时由于数据挖掘目的是从大量的数据中找到数据之间的关系,但矛盾的是在数据挖掘的结果中却会产生许多规律,从而产生另一个新的知识管理问题。为了处理该问题,可以对已发现的规则进行修剪和分组,以更好地对已发现的规律进行的理解,同时可以保证知识库数据中正确和少冗余。
3.3 知识库维护
对于知识库中的数据维护技术已经有很多,这里可以采用序列模式的维护。利用样品抽样的方法来评估序列模式改变的程度,并根据改变的程度决定何时对整个数据库进行操作来更新序列模式,从而较好地解决了序列模式维护的问题。
这里同时必须注意到,要想使搜索引擎更好的工作,必须得利用数据挖掘的一些技术挖掘得知识,而要想充分发挥数据挖掘得作用,还需要更多更好得有关数据,这一定依赖于WWW网站的应用服务器的设计。它能更好的收集数据提供给数据挖掘用,同时数据挖掘不仅提供知识给我们建立知识库,同时也可以帮助组织网站的内容以更好发
挥网站的功能。
4 结束语
随着网络的不断发展,以及WEB信息的激增,如何快速、高效、准确地检索网络信息变得越来越重要,WEB信息检索的发展越来越需要借助各种技术来进一步推动。作为数据挖掘一个重要研究分支的WEB数据挖掘,由于它具有比WEB信息检索更高的技术层次,同时又与WEB信息检索的关系非常密切,对WEB信息检索有很大借鉴作用,所以可以通过应用WEB数据挖掘技术的研究成果到WEB信息检索领域中,提高WEB信息检索的智能处理能力,使得WEB信息检索发展到一个新的水平。
参考文献
[1]刘俊熙,吴英.信息检索和网络数据挖掘技术的比较分析[J].图书馆学刊,2005,(6):111-113.
[2]苑兆忠,姜华.Web挖掘技术在信息检索中的应用研究[J].聊城大学学报:自然科学版,2006,19(1):74-77.
[3]章俊玲.基于多Agent的智能信息检索技术研究[J].浙江工商职业技术学院学报,2007,6(1):39-41.
[4]Pokorny,J.Web searching and information retrieval[J].Computing in Science & Engineer-Ing,2004,6(4):43-48.
[5]封锋.网络信息检索现状研究综述[J].科技文献信息管理,2007,(1):16-18.
[6]张辉,赵需要.因特网信息检索模式及其优化设想[J].情报科学,2007,25(1):77-81.
[7]徐敏.基于数据挖掘的Web信息检索研究[D].南京:南京航空航天大学,2006.
[8]韩家炜,孟小峰.Web挖掘研究[J].计算机研究与发展,2001,38(4):405-414.
[9]刘振岩,王万森,陈立.WEB信息检索与WEB数据挖掘[J].微机发展,2003,13(7):66-68.
猜你喜欢
新闻传播(2016年18期)2016-07-19
新闻传播(2016年11期)2016-07-10
现代计算机(2016年11期)2016-02-28
中国卫生(2015年12期)2015-11-10
地理与地理信息科学(2015年4期)2015-10-13
警察技术(2015年3期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
河南科技(2014年11期)2014-02-27
科学导报·学术论坛(2013年5期)2013-06-26
