
中医药本体构建研究
2008-10-30 05:24刘耀穗志方周扬章成志王振国
大学图书馆学报 2008年4期
刘 耀 穗志方 周 扬 章成志 王振国
摘要利用自然语言处理(NLP)理论和技术方法对中医药领域中已有的公认领域知识进行了重构与利用,在成功实现了中医药学知识描述体系的自动构建与获取的基础上。利用领域专家知识,实现了受限文本的Ontology自学习机制,并对领域本体的进化进行了有益的探索,有效地解决了Ontology研究的瓶颈问题,从而为中医药知识的挖掘与利用奠定了数据基础。从目前看来,这是一种较为理想、实用的方法,为专业领域Ontology的自动构建提供了理论依据及技术支持。
关键词中医药本体数据共享知识工程
1、概述
几千年来,中医药领域的无数临床实践与理论研究积累了海量的科学知识,这些知识包含在中医药古籍以及当前的研究文献中。面对浩如烟海的中医文献,如何有效利用,服务于临床及中药新药研发,是中医药行业普遍关注、亟待解决的重要问题。
中医学的数据多建立在人的经验基础上,其规律受自身理论的支配,其客观性与科学实验数据不在一个层面上。如果用科学实验数据的获取方法和标准来衡量中医的数据,即便是四诊数据仍不可避免带有主观因素。例如对同一病人脉象信息的获取,不同的医生很可能有不同的结论。但是从认知层面来讲,中医确切的疗效这一事实,说明这些数据具有客观性,即诊治的认识符合了病症的客观存在。本体是一种能在语义和知识层次上描述系统的概念模型,其目的在于以一种通用的方式来获取领域中的知识,提供对领域中概念的共同一致的理解,从而实现知识在不同的应用程序和组织之间的共享和重用,这对中医药领域的知识挖掘、发现与利用将会起到不可忽视的作用。因此,基于历史文献进行中医药本体的构建,利用历史文献及公认的领域知识对中医药核心概念进行全面诠释,以期通过概念及其相关要素的关系进行全面分析,解释中医病、证、方、药等核心概念的实质与内涵。但是本体的构建并不是一件简单的事情,课题组在大量实践的基础上,利用自然语言处理(NLP)理论和技术方法对已有公认领域知识,如中医药主题词表、专业辞典、专业教材或权威著作等进行重构利用,并借助领域专家知识,实现基于网络的知识采集与加工,建立起受限文本的Ontology自学习机制,从而实现领域Ontology概念描述体系的自动构建,最终有效地解决了On-tology的自动构建这一瓶颈问题,成功地探索出了一种较为理想、实用的理论与方法,为专业领域Ontolo-gy的自动构建提供理论依据及技术支持。
2、建设流程
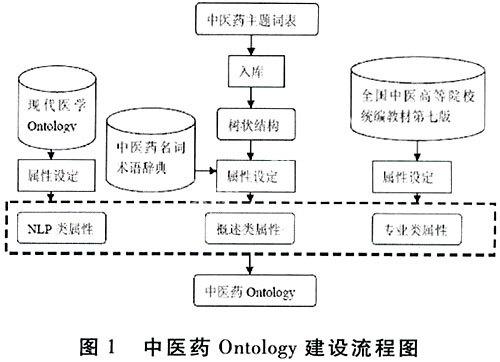
3、资料来源
3.1《中医药学主题词表》
《中医药学主题词表》1987年首次面世,被社会各界广泛应用。1996年,研究人员在大量词频统计及用户意见反馈的基础上,对《中医药学主题词表》进行了增补修订,推出第2版并更名为《中国中医药学主题词表》,以印刷版和电子版两种形式出版。该版主题词表与《汉语主题词表》以及美国国立医学图书馆的《医学主题词表》(MeSH)相兼容,成为目前使用最广泛、影响最大的一部中医药学主题词表,也是国内中西医大型数据库建设的支撑。
3.2《中医药常用名词术语辞典》
《中医药常用名词术语辞典》是一部查检中医药常用名词术语的综合性工具书,共收载中医基础理论、中药、方剂、诊断、内经、伤寒、金匮、温病、中医内科学、中医外科学、中医妇科学、中医儿科学、中医骨伤科学、针灸学、推拿学、中医眼科学、中医耳鼻喉科学、中医急症学等学科的常用名词术语共5701条。但涉及医史文献的人物、著作、事件不在收词之列。
3.3专业教材
采用全国中医高等院校统编教材第七版。自1960年出版高等中医院校试用教材(俗称第一版)以来,迄今已达七版。从高等中医药院校中医学专业规划教材的第二版到第七版,其课程设置体系和教学内容没有发生质的变化,处于比较稳定的状态,鉴于多方面的考虑,我们采用了距今较近的第七版。
4、本体的构建
将主题词作为Ontology的知识元,对分类及其属性设置进行调整与修改。将上下位关系作为the medical domain Ontology的知识元树状结构。以此建立知识描述体系的原型。
4.1中医药主题词表的重构与利用
中医药主题词表的自动导入只是实现了描述语言上的一种转换,但是,领域本体中概念的设计应最大限度地贴近研究者要研究的专业领域中的客观对象和对象间的关系法则。因此,中医药主题词表虽然是该专业公认的领域知识,但主题词表多是由图书情报人员编写而成,有较强的文献标注覆盖面,却不能够深层次反映学科内在联系,必须对其进行知识重构,使其具备更强的学术性、专业性。
①从树状结构到多层嵌套的立体网状结构的转变:主题词表为了文献标引的方便,多把主题词平行分布在多个树状结构内。背离了专业知识体系描述习惯与方法,因此,必须在中医药主题词表中寻找关键类,以此作为知识描述的基本单元,建立层次结构体系。该设计不但可以实现概念描述体系从树状结构到多层嵌套的网状结构的转变;同时,也有效地实现了领域本体最大单向可扩展性。
②从文献检索与标引到专家系统双重功能的转变:从树状结构到多层嵌套的立体网状结构的转变,虽然可以改变概念体系的描述结构,却没有改变对知识深层的描述方式,必须依据专业知识进行再次重构。从而实现从主要服务于文献检索与标注到既服务于文献检索与标注又服务于临床诊断与治疗的双重功能的转变。如医学领域可以“临床”为核心组织疾病类知识,根据临床医学的知识描述框架,将疾病类知识框架中其他类(解剖、化学制品和药物、卫生保健)合并、拆分,得到疾病类属性包含症状与体征、治疗与护理等。并将其他类也根据专业知识进行进一步的描述,如中药的描述属性有起源、产地、采收、炮制、药性、功效主治、中药分类、配伍规律、中药毒性、中药禁忌、用量用法等。以此分别建立其他类知识的描述框架。具体属性如下所述:
中医基础理论:释义、理论概念产生与发展、学术观、主要代表人物、主要代表著作。
藏象学说:藏象学说产生与发展、基本功能、脏腑关系。
气血津液:气血津液概念、生成、功能、运行及其方式、分类与分布、气血津液相互关系。
经络腧穴:概念学说产生与发展、循行走向、分布部位、生理功能、经络腧穴关系、临床应用。
病因病机:产生发展、特征、层次结构。
诊断:分类、方法、意义。
中药:起源、产地、采收、炮制、药性、功效主治、中药分类、配伍规律、中药毒性、中药禁忌、用量用法。
方剂:来源、方剂分类、剂型、组成、组方原则、功用与主治、煎服法、禁忌。
伤寒与温病属性:相关定义、症状、体征、病因病机、诊断、治则治法、方药、传变、转归预后、预防调摄。
症状、病证:病位、病性、病症相互关系。
治疗方法:发生发展、内容与分类、相互关系。
中医药器械设备:类型、仪器功能、仪器应用、生产商、销售商。
中医药及相关学科:发展史、代表人物、代表著作、主要学术观。
中医药文献及情报学:定义、产生与发展、主要人物、主要著作、学术观点。
中医药机构:名称、成立年代、机构性质、职责。
人物:姓名、生存年代、籍贯、著作、学术观念、所属学派、学术成就。
地理:现代名称、古代曾用名、地方病、流行病、地方学派、地方名医、道地药材。
体质:定义、形成与发展、分型、体质特征、生理学基础、应用。
著作:异名、著者、成书年代、卷次、版本与流传、类别、主要学术观点。
通过这次重构,实现从主要服务于文献检索与标注到既服务于文献检索与标注又服务于临床诊断与治疗的双重功能的转变。
4.2基于NLP技术的知识描述体系的构建与获取
通过对中医药主题词表的重构与利用,我们也就获得了领域本体的基本架构,但这还远远不够,需要集成NLP技术,实现从传统的知识描述到NLP智能分析描述的功能转变。
4.2.1概念属性的深化描述
为了获得广泛意义上的构建方法与技术,我们突破学科限制,从自然语言分析和知识挖掘的高度出发,将每个概念的属性描述都分为三种方式:概述类描述、专业类描述、NLP语义类描述。
概述类描述:名称、英文名、释义、代码与约束。其中名称、英文名、代码等由主题词表等所带信息自动生成。释义是利用概念词(主题词)与专业词典词条匹配后,实现概念定义文本的自动填充。
专业类描述:每个概念的专业类属性又分为两种描述形式——自然语言文本描述、知识元描述(NLP主题自动标引)。
如病证类专业属性描述:“症状与体征”、“发病部位”以及“症状与体征2”、“发病部位2”等。其中“症状与体征”、“发病部位”的属性值是利用自然语言文本进行描述的,即槽值是用自然文本填充的。而“症状与体征2”、“发病部位2”的属性值则是利用自然语言文本描述属性中的文本内容进行NLP主题自动标引后进行映射关联形成的,即:槽值是相关结点(概念)属性的集成与关联(关联概念携带其固有关系及结构)。
NLP语义类描述:由自由词(NLP自动切分)、同义词、相关词、中文概念词典(CCD)词等构成。
4.2.2领域概念的自动获取
关于概念的自动获取方法,无论国内还是国外,统计方法都是主流。我们也曾经尝试着将已有的这些方法应用到医学领域中,希望能够自动抽取出医学概念,但结果却不理想。其中的主要困难在于如何识别概念的领域相关性。因此,本文采用已有本体NLP语义类技术,获取新的概念,即由系统对自然文本进行自动切分标注,并利用所得术语与已有概念集(主题词表)进行匹配后,没有相应匹配的术语也就组成新术语备选集合。将新获取的术语备选词与关系术语(本体原有概念)进行冗余度计算,大于一定阈值后,可认为是新概念。
5、本体的进化
Ontology是一个开放集成的体系,底层知识库与概念集应该随着学科领域的更新和发展随时进行修正和更新,因此针对权威机构网站发布的更新信息,进行定期采集与获取,可以有效地解决这一问题。
5.1进化流程
基于网络资源,进行知识采集与加工,进而实现受限文本的Ontology自学习机制。
5.2概念关系自动获取方法及技术
使用扩展的关联规则挖掘方法获取概念间的非分类关系。其基本思想是:如果两个概念经常出现在同一文档(或段落,或句子)中,则这两个概念之间必定存在关系,因此,使用已有的概念层次作为背景知识,然后利用关联规则来发现概念间的非分类关系;如在基于模式识别的层次关系提取中,通过部件的语义类别,利用汉语的命名规律,可推导出术语的语义类别,以确定术语关系。
术语自动提取与术语层次关系自动提取技术,是领域本体进化过程中的两个关键环节,通过上述方法,实现了从传统的知识描述到NLP智能分析描述的功能转变,从而为本体的自动进化奠定了物质基础。
6、构建平台的研制与开发
利用自然语言处理(NLP)理论和技术方法,将多种公认领域知识自动导入编译,是实现中医药本体构建、进化的必备条件之一。我们在Protege3.1的基础上,加入了大量NLP的处理技术,成功开发出了中医药本体辅助构建系统,其主要功能如下:
①多样化的导人、导出方式(RTF/XML/OWL等):方便与国际上相关的Ontology之间的知识交流、知识共享和知识重用;
②强大的编辑功能:层次结构的调整、属性关系的调整、属性值的增删改等;
③强大的检索功能:可以对知识元或属性进行精确查找和模糊查找;
④多层次网络的知识互联;
⑤NLP自动分析处理功能:包括结构化词表处理功能,主要处理中医药主题词表、主题词表、分类词表、分类主题词表等带有结构信息的资源,是领域Ontology自动构建的基础;教材及其他文本处理,主要处理教材等行文相对规范的电子文本;专业词典处理功能,主要对专业词典进行导入与处理。
⑥网络内容提取与挖掘:主要包括批量网络内容提取功能(离线),输入批量的医学网站地址,定期、主动下载所有网页并建立索引,输入知识元类别,完成网上医学知识的自动提取与批量填充;知识元相关的批量网络内容提取功能,输入某一种疾病,并提供该疾病相关的批量的医学网站地址,完成网上医学知识的自动提取与批量填充。
⑦本体关系的可视化功能:可视化是利用计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。为了使用户能够更形象地看到本体的关系结构,我们为平台集成了本体关系的可视化功能。
7、应用研究
在成功构建的基础上,课题组也进行了多种应用研究,主要体现在以下几个方面:
7.1文献知识标引
建立每篇文献与核心知识库的多点链接:对海量的文献资料库,以领域的核心知识元数据库为主轴,对每篇文献进行结构化的知识标引,使当前文献中蕴涵的知识骨架结构显性化地呈现出来,形成解构后的文献资料映像库,其中的每篇文献都与核心知识元数据库相链接,并藉此形成不同文献之间的相互关联。
7.2网络资源的知识标引
更大范围内的知识资源集合分类型、分领域与核心知识库进行链接:以核心知识元数据库为底层的本体,通过Semantic Web语义标注技术,对互联网信息资源以及其他国家的知识资源集合进行分类型、分领域的对接。
7.3精准知识服务系统
基于本体,自动生成医学知识,引证和补充知识库;在搜索文献基础上分析文献内容,基于知识元数据库整理相关数据,形成对当前最新研究现状的总结、述评以及趋势预测。
通过以上几方面的分析对比,既可以基于网络资源更新百科全书,又可以基于百科全书指导网络资源的开发和利用。
8、结论
本文利用自然语言处理(NLP)理论和技术方法对中医药领域中已有的公认领域知识进行了重构与利用,成功实现了中医药学知识描述体系的自动构建与获取,从而为中医药知识的挖掘与利用奠定了数据基础,并在此基础上,借助领域专家知识,实现了受限文本的Ontology自学习机制,对领域本体的进化进行了有益的探索,有效地解决了Ontology研究的瓶颈问题,从目前看来。是一种较为理想、实用的方法,该研究的成功实现,为专业领域Ontology的自动构建提供理论依据及技术支持。
猜你喜欢
哲学分析(2023年4期)2023-12-21
现代临床医学(2021年3期)2021-07-16
中国民间疗法(2021年5期)2021-06-09
数字图书馆论坛(2021年10期)2021-01-30
数字图书馆论坛(2021年9期)2021-01-30
中国音乐学(2020年4期)2020-12-25
数字图书馆论坛(2020年10期)2020-02-24
数字图书馆论坛(2020年11期)2020-02-23
知识经济·中国直销(2017年7期)2017-07-24
中国卫生(2016年11期)2016-11-12
