
多股价指标下集成机器学习的股价操纵检测
2025-03-05 00:00:00赵俊杰刘金涛周永辉
电脑知识与技术 2025年3期





关键词:中国证监会;异常波动;机器学习;股价操纵检测;股票市场;集成学习
中图分类号:TP39;F832.5 文献标识码:A
文章编号:1009-3044(2025)03-0077-05 开放科学(资源服务) 标识码(OSID) :
0引言
股价操纵行为往往涉及散布虚假信息、囤积资产等复杂且隐蔽的交易手段。这些行为不仅对市场的公平性和透明度造成了严重破坏,也给投资者带来了不小的风险。众多学者对此问题进行了深入探讨,从不同角度剖析了股价操纵的影响与识别方法。刘胜军(2001) [1]指出操纵者通过一系列手段如渲染气氛、做尾盘等获得大量非法利益。孙开连等(2002) [2]则强调股价操纵对市场的公平性和透明度的破坏。李珍和夏中宝(2020) [3]根据供求关系理论,分析交易型操纵对价格的影响,并提出了一系列加强反操纵监管的具体措施。随着市场操纵手段的不断演变,学者们也在不断探索新的研究方法。刘溪等(2019) [4]构建理性预期均衡模型,分析非知情交易者前后价格波动,揭示了噪声信息对市场的影响。李梦雨(2015) [5]利用Logit模型设计了一种市场操纵预警机制,为监管提供了有力支持。近年来,机器学习在股价操纵识别中发挥了越来越重要的作用。李博等(2023) [6]基于支持向量机提出了时态数据的粒度变换概念,有效识别了不同程度操纵股票的模式。张颖和李路(2024) [7]构建了基于随机森林特征选择的RF-MIP-LSTM模型,并通过推导前向与反向传播算法证明了其可行性。同时,不同机器学习模型在股价操纵识别中的性能也成为研究的热点。陈宇龙和孙广宇(2023) [8]通过综合比较发现, K-近邻模型在股价操纵识别中具有较好的表现。而刘振清等(2020) [9]则基于新型指标使用逻辑回归模型,证明了操纵事件前后特定指标会发生显著变化。此外,胡金霞(2010) [10]提出了一种用于股票价格操纵识别的人工神经网络,此模型具有良好的检测性能,为股价操纵问题的解决提供了新的思路和方法。
在集成学习领域,Wang等(2019)[11]集成了多个循环神经网络(RNN) ,显著增强了日内股票价格操纵的检测效果。随后,Liu等(2024)[12] 运用堆叠泛化技术,将多个RNN子模块进行有效集成,进一步提升了检测效果。 Chullamonthon等(2023) [13]开创性地将有监督学习和无监督学习进行集成,针对泰国股票市场操纵行为进行了精准检测, 从而验证了集成无监督深度神经网络在该领域的实用性。除模型设计之外,样本特征的选取也极为重要。Aggarwal和Wu(2006)[14]发现,在操纵期间,股价操纵活动往往伴随着股票流动性增加、波动性的加剧和回报率的提升。Öğüt等人(2009) [15]则进一步将操纵股票与指数之间的日均收益率、波动率和交易量的差异作为关键解释变量,为股价操纵的检测提供了新的视角。
尽管以上学者们的贡献为股价操纵检测与防范提供了强有力的支持,但市场环境瞬息万变,常常存在数据质量不高和信息透明度差等现象。鉴于此,本文收集了近15年中国证监会股价操纵案例和相似股价信息,构建一种先进的机器学习模型对股价操纵进行识别,并选取了五个指标对模型的性能进行全面评估。特别地,在特征选择上,纳入被操纵股票与当日大盘指数的差异,提出了一系列新颖的股价度量指标。实验表明,本文模型相对其他单一股价操纵检测模型,在股价操纵检测的准确性方面表现出了显著的优势。
本文其余部分安排:第1节讨论了数据来源及特征工程。在第2节介绍了用于股票操纵检测的集成学习模型。随后在第3节展示了实验过程及结果。第4 节总结了研究工作,并提出了未来的研究方向。
1 数据和特征工程
1.1 数据来源
出于安全性的考量,中国证券监督管理委员会(CSRC) (http://www.csrc.gov.cn/)仅公开了部分信息,包括股价操纵案的涉案人员、股票名称、操纵天数、活动描述以及造成的经济损失金额。研究系统地收集了2008年至2023年的股价操纵案例,对于股票部分数据缺失的案例,进行整行删除并对其余数据Z-score标准化。最后共计获取了196只被操纵股票数据。考虑到操纵时间长短对研究分析至关重要,我们筛选出操纵时间较短的,特别是3天以内的股票案例,并将这些时间段标记为异常时段。进一步收集了申万行业指数以及交易所指数,这些数据将作为后续特征工程的基础,部分数据展示如表1所示。
此外,采用控制样本的方法进行对比分析。依据市值、股价及所属行业等关键指标,在同花顺财经(ehatsttpms:o/n/wewy.wc.o1m0j/q),ka腾.co讯m.自cn/选) ,东股方(h财ttp富s://网gu(.hqttqp.sc:/o/mww/rwe⁃. source/products/portfolio/m.htm) 等股票网站中,为每个被操纵的股票找到了一个最为相近的未受操纵的股票作为控制样本。对于控制样本,要求没有报告出任何不良消息且从未出现在中国证监会行政处罚决定书中。在此基础上,在锐思金融数据网站(Resset) (https://db.resset.com/index.jsp?actionResult=index) 下载了这些股票的相关数据,形成了本次研究的基础实验数据集,整体数据处理流程如图1所示。
1.2特征工程
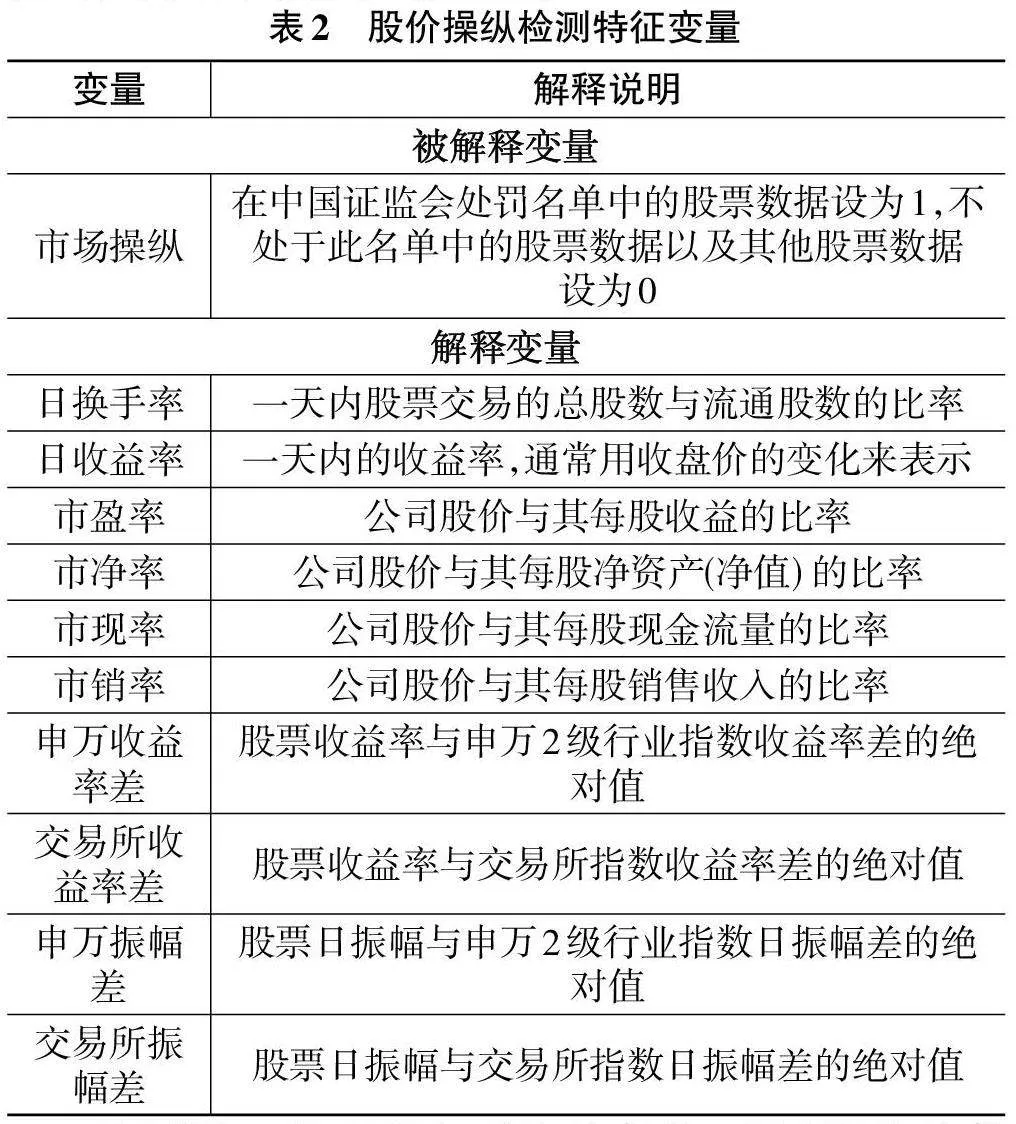
在股价操纵过程中,股票价格、交易量和持股集中度往往会呈现出明显的异常变动。操纵行为,通常都被隐藏在庞大的股票交易数据中。为了更好地挖掘交易数据中隐藏的信息,同时考虑了换手率、收益率、振幅等股票特征。
换手率:股票的换手率越高,说明其交易越频繁,操纵者通过频繁交易,增加股票的换手率,诱使其他投资者跟风买入或卖出。其计算公式如下:
收益率:操控行为可能导致股票价格在短期内上升,从而使得收益率看似较高。然而,一旦操控结束,股价往往会回落,实际收益率可能大打折扣。其计算公式如下:
另外,分析特别引入了两组对比指标,一组是与市场正常交易状况相对照的差异化指标,另一组是与行业平均水平相比较的差值指标。具体来说,分析将当日股票的收益率与对应的申万2级行业指数日收益率进行比较,计算出其差的绝对值,即“申万日收益率差”,以衡量股票与行业整体的收益偏离程度;同样地,研究者也计算了与交易所指数日收益率的差值绝对值,即“交易所日收益率差”,以反映股票与交易所整体市场的收益差异。类似地,为了进一步探究股票价格波动幅度的异常情况,研究者还计算了股票的振幅与申万2级行业指数振幅及交易所指数振幅的差值绝对值,分别命名为“申万振幅差”和“交易所振幅差”。这些差值指标不仅能够帮助研究者识别出异常波动的股票,还能为后续的股价操纵检测提供有力的数据支持。此外,Siddiqi(2007) [16]强调了市盈率、市净率、市现率、市销率等财务指标在股价操纵行为检测中的重要性。
综上所述,经过精心挑选和计算,研究最终确定了如表2所示的一系列变量,这些变量将作为后续研究的基础,帮助研究者更深入地理解股价操纵行为,提高检测的准确性和有效性。
为了进一步表明申万收益率差、交易所收益率差、申万振幅差和交易所振幅差四个关键指标对股票价格操纵行为的作用,对被操纵股票与正常股票在这四个变量上进行了统计分析,结果如表3所示。受操纵股票的均值、中位数、方差和极差均远高于正常股票。这意味着受操纵股票的收益与价格波动情况与市场整体或行业平均水平存在较大偏离,这通常是股票价格被人为干预的显著特征。这一发现不仅证实了这四个指标在衡量股票价格操纵行为方面的有效性,也为后续研究提供了重要的判断依据。
2模型配置
Wolpert(1992) 的研究表明,通过堆叠集成策略,即通过结合多个模型的预测结果,能够显著提高整体预测性能[17]。受此启发,本文所构建的模型主要采用了集成学习中堆叠(stacking) 的模型结构,如图2 所示。
模型选取了一系列性能优异的基学习器,包括支持向量机(SVM) 、随机森林(RF) 、K-近邻算法(KNN) 、逻辑回归(LR) 以及人工神经网络(ANN) 。这些基学习器独立对输入特征数据进行处理,通过五折交叉验证以及网格搜索来选择最佳超参数并训练模型,并输出受操纵的可能性预测。接下来,基学习器的预测值被合并成一个综合向量,作为集成学习器的输入。本文选择了逻辑回归作为元学习器。它可以整合各基学习器的预测结果,并通过其概率输出进行判断,其输出的预测概率将作为最终的判断依据,同样通过交叉验证来调整超参数。这样的集成方式有效地发挥了各个基学习器的优势,避免了单一模型可能出现的偏见或局限性,从而提高了整体的预测准确性和稳定性。
此外,本研究还借鉴了张贵生和张信东(2016) [18]的研究思路,将股票信息提取为一个梯度因子并引入到模型中。这一策略有助于模型更好地捕捉股票价格的动态变化,从而提高对股票价格操纵行为的识别能力。同时,与Liu等(2024) [12]一样,利用梯度分离方法对拼接后的股票信息进行处理。梯度分离通过反向传播算法能够有效训练深度神经网络,在股票价格预测中,市场行为和价格走势通常是非线性的,因此,神经网络能够识别并学习这些复杂的动态模式。
3 实验与评估
3.1 评估指标
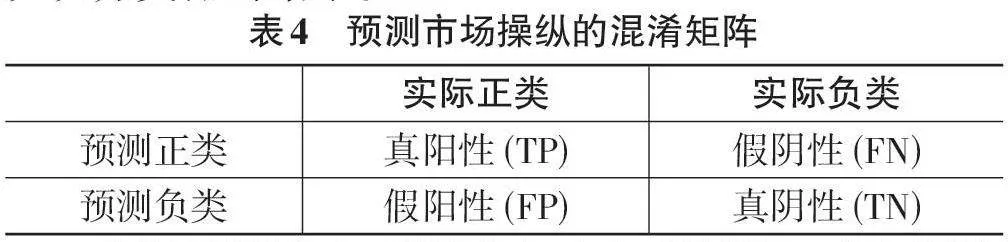
在深入的研究中,选取了五个指标,即准确率、召回率、精确度、F1分数以及AUC值,来对分类器的性能进行全面评估。表4展示了混淆矩阵,能够直观地反映分类器的结果。
在混淆矩阵中,真阳性(TP) 和真阴性(TN) 分别代表着分类器正确地将实例归类为阳性或阴性的数量,这直接反映了分类器的正确识别能力。而假阳性(FP) 和假阴性(FN) 则代表着分类器错误地将实例归类为阳性或阴性的数量,这体现了分类器的误判程度。此外,F1分数是精确度和召回率的调和平均值,能够综合评估分类器在精确度和召回率两方面的表现;而AUC值则基于ROC曲线计算得出,取值范围从0到1,能够衡量分类器在不同分类阈值下的性能,AUC 值越高,模型的预测性能就越好。上述指标的计算公式如下所示:
3.2实验结果
3.2.1实验Ⅰ:评估模型性能
研究将所提出的集成学习模型与支持向量机、朴素贝叶斯、决策树、K-近邻算法、逻辑回归和随机森林等机器学习模型在股价操纵检测方面的性能进行了对比分析,翔实的数据对比如图3所示。从中不难发现,本文所设计的模型在准确率上展现出了显著的优势,其准确率高达84%,远超过其他所有单一机器学习模型。特别地,即便支持向量机模型和随机森林这两种表现相对突出的模型,其准确率也仅为77%,而K-近邻算法的准确率为75%,均未能达到本文模型的性能水平。
在衡量模型检测效能的其他指标上,本文模型同样表现出了优越的性能。其召回率和精确率均为83%,高于其他所有对比模型。这反映了本文模型在减少漏报和误报方面的有效性,从而增强了其在股价操纵检测任务中的可靠性。
此外,进一步计算了F1分数,结果显示,本文模型的F1分数为83%,显著领先于其他模型,充分证明了本文模型的实用性和泛化能力。
并且还绘制了以上模型的ROC 曲线和AUC 面积,以确保对比实验结果的客观性和公平性,如图4所示。本文模型AUC=0.83,这是所有模型中最高的,表明它在区分正负类方面的能力最强。
3.2.2实验Ⅱ:消融实验
为了进一步验证申万收益率差、交易所收益率差与申万振幅差、交易所振幅差这四个特征在股价操纵检测中的有效性,研究进行了一项消融实验。在确保其他所有条件均保持一致的前提下,研究移除了这四个特征指标,并对模型的性能进行了重新评估。实验结果显示,如图5所示,虽然本文模型在移除这四个特征后仍然表现最佳,但其性能相比添加这些特征时(如图3所示) 出现了明显的下滑趋势。这一发现有力地证实了这四个特征在提升股价操纵检测准确性方面的重要作用,也进一步凸显了本文模型在特征选择和集成学习方面的优势。
本文同样绘制了消融实验的ROC曲线和AUC值,结果如图6所示。其中本模型AUC值为0.78,表明它具有最好的分类性能,缺少四个指标后,各模型的各模型ROC曲线和AUC面积都出现不同差异的下降。
4结束语
本研究收集了来自中国证监会2008年至2023年的股价操纵案例,并为每个案例选择了控制样本。同时提出四个特征指标,即申万收益率差、交易所收益率差、申万振幅差和交易所振幅差,构建了一个基于集成学习的检测模型。实验结果显示,相比于单一方法,检测效果获得了进一步提升,从而验证了所提出的这些指标在捕捉股价异常波动和操纵行为方面的重要性和有效性。
未来研究将进一步扩大数据集范围,探索更先进的模型架构和算法,结合实时监测和异常检测技术,有效地检测和响应市场操纵行为。同时,设计自适应机制进一步优化模型性能。
猜你喜欢
科技创新与应用(2017年6期)2017-03-23 20:57:00
现代电子技术(2017年1期)2017-02-16 11:32:52
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
时代金融(2016年23期)2016-10-31 13:47:33
科学与财富(2016年28期)2016-10-14 21:19:17
科技视界(2015年27期)2015-10-08 11:01:28
