
基于电话内容文本的数据增强模型研究
2025-03-05 00:00:00曾孟佳阳子聪黄旭
电脑知识与技术 2025年3期
关键词:文本分类




关键词:来电文本;数据增强;文本分类;ERNIE
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2025)03-0009-03 开放科学(资源服务) 标识码(OSID) :
0引言
公共群众热线的发展有利于提高工作人员的服务效率,便于培养部门咨询中心的专业性;来电服务的专业化有利于分门别类地梳理群众问题,细化各个流程服务标准,经过部门的汇总,最终成为政府公共监督部门的重点追踪对象[1]。当前,群众来电内容一般由人工记录并分类至相应部门,此种分类方式,一方面分类速度跟不上数据量增加速度,另一方面受处理人员业务熟悉程度、认知差异等因素影响,导致错分概率较大。此外,由于文本内容长短不一、语言逻辑复杂和群众访问部门过度集中而造成的数据分布不均等问题,导致目前流行的中文文本分类模型分类效果普遍较差。基于上述问题,本文利用数据增强模型,从不同角度和层次进行变换,从而构造出更多能满足电话文本分类场景的数据,以提高分类模型效率。本文将ERNIE文本分类模型[2]与RoFormer-Sim[3]数据增强模型相结合,用于来电文本分类任务,主要贡献在于:针对群众来电文本数据集的样本分布不均问题,采用基于UniLM[4]思想的RoFormer-Sim技术,通过改进训练,使其能够生成与输入语义相似的句子得到增强样本,并验证对比得出最佳的样本增强比例,解决因数据集种类分布不平衡造成分类器效果差的问题。
1模型设计与整体框架
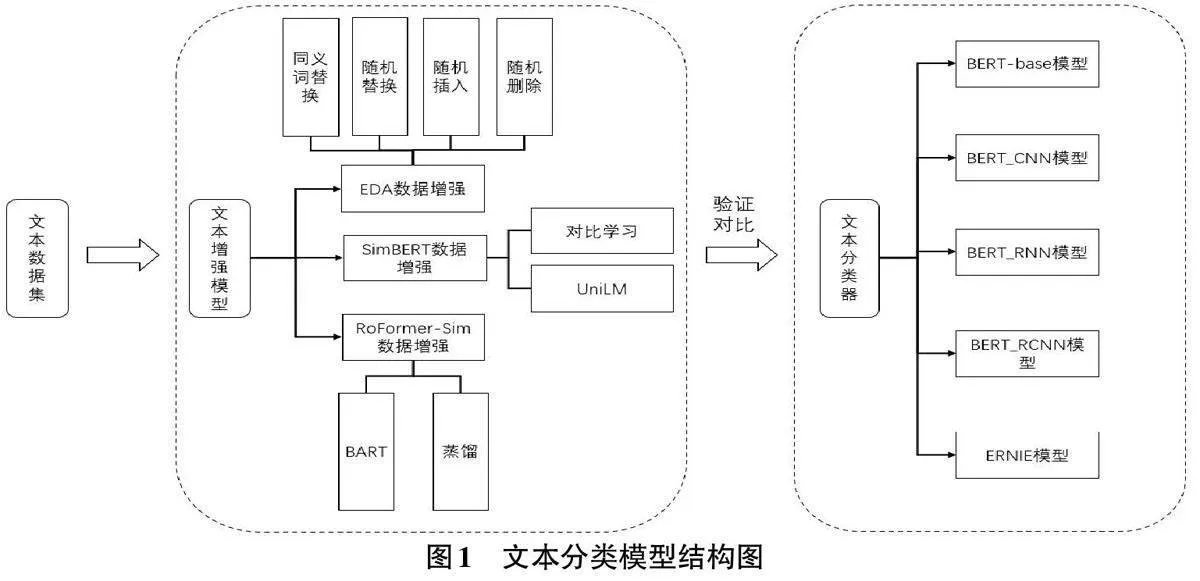
文本增强技术分别采用基于规则数据增强的EDA简单数据增强模型[5],SimBERT文本增强模型和RoFormer-Sim文本增强模型,文本分类器选取近年来适用于文本分类任务的BERT-base模型[6],ERINE模型和BERT的网络模型作为集成对比实验,通过字符集粒度嵌入文本特征向量完成文本分类任务。文本分类模型设计如图1所示。
1.2文本分类器
在文本分类任务中,BERT通过使用双向Trans⁃former架构来动态调整词向量,从而将词语的上下文信息融入其中,进而更好地理解语义信息。和独热编码、word2vec不同的是,BERT可以较好地解决一词多义问题[9]。ERNIE是百度提出的一种基于知识增强的持续学习语义理解框架,它通过结合大数据预训练和多源知识,不断吸收海量文本数据中词汇、结构、语义等方面的知识,提升模型效果。与BERT相比,ERNIE在预训练过程中使用了不同的MASK策略、语料库和知识图谱信息,并在预训练阶段增加了外部的知识,且由三种等级的MASK组成。
2实验过程与结果分析
2.1数据来源与预处理
数据集包含12685条由政府部门人工记录的群众来电文本。本文在预处理阶段,删除了重复和错误数据,并对敏感词汇进行了脱敏处理。部分数据如表1所示。
2.2实验设置
实验按7:1:2比例划分数据集为训练集、测试集和验证集。本文选取BERT_base,ERNIE_chinese,BERT_RNN和BERT-CNN文本分类模型作为对比实验,其中BERT_base,BERT_RNN和BERT-CNN的学习率设为5e-5,输入句子长度为128,批量训练大小为128,隐藏层为768层。数据增强算法采用EDA,句中每个单词被替换的概率alpha为0.3,生成数据条数根据每个类别条数而定。SimBERT和RoFormer-Sim参数相同,生成总样本数量n为100,k值与EDA生成数相同,用于生成n条数据并返回最相似的k条数据。
2.3实验结果分析与讨论
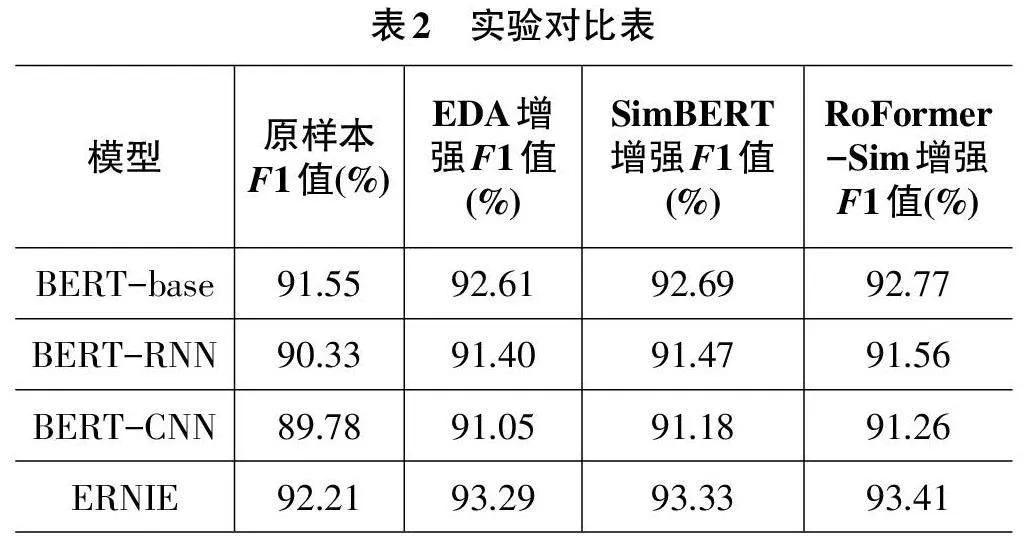
本文采用分类任务常用的评估指标精确率(P)、召回率(R)以及F1值进行结果的有效性验证。在本文设计的来电文本分类对比模型上,通过比较不同文本增强技术和预训练语言模型来验证其在群众来电文本分类任务上的效果。首先在训练集上进行训练,然后通过验证集优化,最终在测试集上评估模型效果。由于样本数据本身不平衡,原始样本在模型上实验结果较差。所以,本实验选择数据条数在500条以下的22个小样本类作为增强类进行数据增强,实验结果如表2所示。
如表2所示,ERNIE模型在原始样本群众来电文本分类任务上表现最佳,F1值为92.21%,比BERTbase模型高0.64%。这是因为ERNIE使用了细粒度的MASK策略,能更好地处理中文文本的复杂结构和语义信息。
采用EDA、SimBERT和RoFormer-Sim增强模型进行了文本增强后,扩充了训练集数据量。与未增强前进行比较,结果如表3所示。
各数据增强技术特点可归纳为:EDA基于规则,可对词语进行调序和替换。SimBERT和RoFormer-Sim在生成疑问句上相似,但RoFormer-Sim在陈述句方面效果更优。RoFormer-Sim和SimBERT的F1值均大于EDA,原因在于它们能在文本的句级别操作,保留更多语义信息和上下文关系,且利用预训练语言模型能生成丰富的相似句。
3结束语
传统网络模型主要依赖于词袋或词嵌入方法,只能捕捉到局部语义信息。而BERT模型通过多头自注意力机制和预训练任务,能够学习到更深层次的语法和语义知识,从而提高对复杂逻辑关系的理解能力。为解决样本不平衡问题,本文采用了RoFormer-Sim数据增强模型,其生成的样本质量优于EDA和Sim⁃BERT技术。在实验中,使用了BERT预训练语言模型及其改进版本结合数据增强模型,以探究不同模型的优缺点和适用场景,并对各模型效果差异的原因进行了解释。
猜你喜欢
电脑知识与技术(2016年30期)2017-03-06 20:28:59
计算机应用(2016年12期)2017-01-13 01:24:36
电子技术与软件工程(2016年22期)2016-12-26 12:56:34
数字技术与应用(2016年9期)2016-11-09 23:23:56
电脑知识与技术(2016年23期)2016-11-02 23:40:10
科教导刊·电子版(2016年23期)2016-10-31 21:38:23
科技视界(2016年24期)2016-10-11 09:36:57
湖南大学学报·自然科学版(2016年4期)2016-08-12 15:03:42
中国教育信息化·基础教育(2016年2期)2016-05-31 11:26:49
软件(2015年5期)2015-08-22 08:02:45
