
基于改进RRT*算法的机器人路径规划
2025-03-04 00:00:00李鑫帝武曲周子涵
物联网技术 2025年5期
关键词:路径规划


摘 要:针对机器人路径规划问题,设计了一种基于改进RRT*算法的机器人路径规划方法。首先,针对RRT*算法环境适应能力差的问题,提出基于奖励的自适应步长设计,以提高RRT*算法的环境适应性;其次,针对RRT*算法在采样空间随机采样的特性,提出偏向目标采样与贪心采样结合的采样策略,并设置路径长度阈值,对采样点进行控制;最后,针对路径冗余且存在尖角的问题,采用先对路径进行拉伸处理再进行平滑处理的方式来解决。实验结果表明,所提出的改进RRT*方法相较于其他方法,效率更高、运行时间更短,在路径的平滑处理方面表现出色。
关键词:改进RRT*;自适应步长;偏向目标采样;路径拉伸;路径平滑;路径规划
中图分类号:TP242 文献标识码:A 文章编号:2095-1302(2025)05-00-06
0 引 言
路径规划问题可以描述为以一定评价指标(如路径长度最短、路径拐点最少)为目标,根据给定的地图或网络,找到从起点到终点且不发生碰撞的最优路径[1]。路径规划是机器人移动的基础,是实现机器人自主导航和任务执行的关键技术之一。现阶段路径规划方法主要分为图搜索方法(如A*算法)、基于模型的方法(如动态规划法)、机器学习方法[2](如人工神经网络)以及基于采样的路径规划方法(如快速搜索树算法)。图搜索方法能够找到全局最优解,但其在面对大规模环境时计算复杂度较高。基于模型的方法可以考虑机器人的运动特性,但对环境模型的准确性要求较高。机器学习方法的环境适应性较强,但需要大量的训练数据及计算资源,同时易陷入局部最优。基于采样的路径规划方法,在计算效率方面更具优势。快速搜索树(Rapidly-exploring Random Trees, RRT)算法是基于采样的路径规划方法之一[3]。RRT算法通过随机采样及快速扩展在搜索空间构建一棵树,完成对搜索空间的探索并找到可行路径,适用于各种复杂环境和高维空间的路径规划,但其生成的路径不一定是最优路径。针对这一问题,文献[4]提出了RRT*算法,用于获得全局最优路径,但RRT*算法的运行时间较长。为了解决这一问题,文献[5]提出了RRT-Connect算法,该算法采用双向搜索策略来提高算法的运行效率;文献[6]提出了改进的RRT*与动态窗口法(Dynamic Window Approach, DWA)相融合的动态路径规划方法,以实现移动机器人在复杂动态障碍物环境中的避障;文献[7]提出了MI-RRT*算法,该算法引入贪心采样和自适应步长的方法来提高算法收敛速度,降低内存占用;文献[8]提出了黄金正弦下的RRT*势场算法,利用人工势场对全局路径进行预处理,再利用黄金正弦进行局部路径寻优,实现了三维环境下的路径规划。
针对RRT*算法对环境变化适应性差的问题,本文建立了步长调整与环境变化的随动关系,提出了一种改进的RRT*算法。该算法基于奖励机制根据环境变化自适应调整步长,通过在迭代过程中不断对RRT*扩展步长进行调整,实现对当前周边环境的适应。针对RRT*算法采样目的性不强的问题,提出偏向目标采样与贪心采样相结合的采样策略,同时引入路径长度阈值,以提高RRT*算法采样的目的性。针对RRT*算法规划的路径冗余点多、尖角多的问题,采用先对路径进行拉伸处理再进行平滑处理的方式来解决。
1 RRT*算法介绍
RRT算法以起始点为根节点,以步长为增量,构建搜索树,通过反向查找形成可行路径。假设机器人的起始位置为gbegin,结束位置为gend,RRT算法单步扩展如图1所示。
RRT算法在采样空间内随机确定采样点grand,遍历随机树叶子节点集合,找到与随机采样点grand距离最近的叶子节点gnear,从叶子节点gnear出发沿gnear与grand方向进行一个步长为λ的扩展,得到新节点gnew[9]。若此过程中未碰撞障碍物,则将新节点gnew加入随机树,反之则放弃该节点,重新进行扩展,重复以上步骤,直到新节点gnew与结束位置gend距离小于步长λ,代表搜索完成。搜索完成后,从结束位置gend出发,不断寻找其父节点,直至到达起始位置gbegin,形成路径。
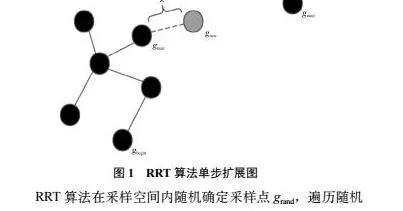
RRT*算法是RRT算法的改进版本,RRT*在RRT算法的基础上添加了重新选择父节点与重布线操作。图2所示为RRT*算法的单步扩展图,以图2为基础对重新选择父节点与重布线进行介绍。
重新选择父节点:确定以新节点gnew为圆心,以r为半径范围内的叶子节点集合,依次计算从起始位置gbegin经叶子节点集合中的节点至新节点gnew的路径长度,选择路径长度最短的叶子节点作为新节点gnew的父节点。重布线:将新节点gnew与原父节点gnear的连线断开, 将新节点gnew与新父节点连线。
2 环境建模
本文采用二维栅格地图法(Grip Map)[10]进行环境建模。栅格地图以二维坐标系为基础,将环境划分为许多离散的小栅格,每个小栅格的位置对应二维坐标系中的一个坐标点。小栅格中存储描述环境信息的方法,一般为存储“1”或“0”。“1”表示该位置存在障碍,不能通行;“0”表示该位置无障碍,可以通行。设置两种路径规划环境,一种是简单障碍环境;第二种是复杂障碍环境,栅格大小为500×500,起始节点坐标为(20,480),结束节点坐标为(480,20),二维栅格地图法环境建模结果如图3、图4所示。
3 改进的RRT*算法
3.1 基于奖励的自适应步长
3.1.1 步长分析
RRT*算法确定当前目标位置后,计算所有叶子节点与采样点位置的距离,取最近的叶子节点沿采样节点位置方向行进步长λ。由此可见,步长是RRT*算法中的一个重要参数,它决定了树中节点与节点间的距离。
步长对RRT*算法的影响主要体现在以下两个方面:
(1)路径质量:步长越小,算法搜索的路径精度越高。较小的步长可以使得RRT*算法更加细致地搜索空间,并找到更优的路径。然而,因为需要生成更多的节点,较小的步长也会导致算法的运行时间增加。
(2)算法效率:步长越大,算法搜索的速度越快。较大的步长可以使得RRT*算法在搜索空间中快速生成节点,从而加快算法的运行速度。然而,因为可能会错过更优的路径,较大的步长也可能导致算法搜索的路径质量下降。
3.1.2 基于奖励的自适应步长设计
步长直接决定RRT*算法的搜索效率及质量。本文受强化学习奖励函数[11]启发,提出基于奖励的自适应步长设计。
(1)奖励函数
在强化学习中智能体的每一步状态会返回一个特殊信号,称为奖励R。假设智能体当前状态为S(t),当前奖励为R(t),若此时智能体未碰撞障碍物,则传递奖励,反之则传递惩罚。奖励函数如式(1)、式(2)所示:
(2)惯性因子
惯性是指物体保持原运动状态的能力。基于奖励的可变步长设计,步长跟随奖励的变化而变化。若智能体连续多次未触及障碍区域,则会造成奖励增长过快,导致步长增长过快。同时,步长越长,智能体触及障碍区域的概率越大。故若出现此种情况,则会造成连续惩罚,导致步长大量回撤,影响程序运行速度。故本文引入惯性因子θ对步长进行控制。文献[12]与文献[13]对惯性因子的设置问题进行了探讨,发现惯性因子设置动态的值比设置固定的值取得的效果更加优秀,故本文惯性因子采用线性递减策略,见式(3)、式(4):
3.2 采样策略
由于RRT*算法采取随机采样策略,路径的质量又取决于随机采样的分布,所以在某些情况下,RRT*算法可能生成一条较长的路径。针对这一问题,本文的采样策略首先执行贪心采样。贪心采样策略通过设置贪心采样阈值p, p∈[0, 1],在进行采样时会生成一个随机值k, k∈[0, 1],若k小于p,则直接将结束位置gend作为采样点,否则按照偏向目标采样进行采样。偏向目标采样[14]首先从地图中随机确定临时采样点ggoal,然后将临时采样点与结束节点gend进行连线,在连接线上采用均匀方式随机确定采样点ggoal并确定新节点gnew,同时设置路径长度阈值Dmax,计算从起始位置经新节点到结束位置的路径长度。若路径长度大于路径长度阈值,则重新进行采样,反之,则执行RRT*算法的其他步骤。从起始位置经新节点到结束位置的路径长度计算公式如下:
4 路径拉伸与平滑
4.1 路径拉伸
路径拉伸处理在RRT*算法已生成的路径节点集合基础上进行。主要思想是根据路径的两个端点判断从节点g1直接到达节点g3中间是否存在障碍物,若不存在则直接忽略两个端点中间的其他路径节点,如图5所示。
4.2 路径平滑
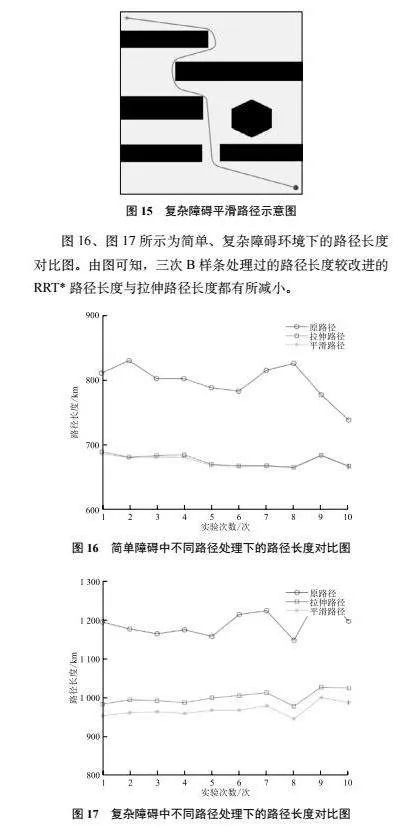
对路径进行拉伸处理后,虽然删除了路径上的冗余节点,但是路径仍然存在尖角,不利于车辆转向。针对这一问题,采取三次B样条曲线[15]对路径进行平滑处理。设有控制顶点p0, p1, p2, ..., pn,则k次B样条表达式见式(8):
5 仿真实验分析
为了验证改进的RRT*算法在简单障碍环境与复杂障碍环境下的实用性和可用性,采用传统的RRT算法、RRT*算法、RRT-Connect算法与改进的RRT*算法分别在简单、复杂障碍环境下进行路径规划仿真,试验次数为10次,旨在验证改进的RRT*算法的随机树生成采样点的目的性是否更强以及其路径规划效果和路径规划效率。本文使用MATLAB 2021版本进行实验。
5.1 采样点个数对比
从表1中可知:改进的RRT*算法无论在简单障碍环境下还是复杂障碍环境下,最优采样点个数与平均采样点个数均少于其余3种算法。由此分析:改进的RRT*算法的运行效率应优于其他3种算法,这得益于改进的RRT*算法采用目的性更强的采样策略。
图6、图7所示为各算法在简单、复杂障碍环境下的采样点个数对比图。改进的RRT*算法的随机采样点个数变化趋势较其他3种算法较为平缓。这表明了改进的RRT*算法在采样点的随机性方面展现出了更强的鲁棒性,不会因为较小的变化而导致结果发生显著变化。
5.2 路径长度对比
各算法在复杂、简单障碍环境下的路径长度对比实验结果见表2。
由表2可以看出:改进的RRT*算法虽然在路径规划的最优解上没有其他算法优秀,但是在平均路径长度方面表现出良好的性能;虽然改进的RRT*算法的采样点数减少,但是搜索质量确有提高。这主要是因为本文采取自适应步长设计,当遇到障碍物密集时,采用小步长进行扩展;当遇到障碍物松散时,采用大步长进行扩展。
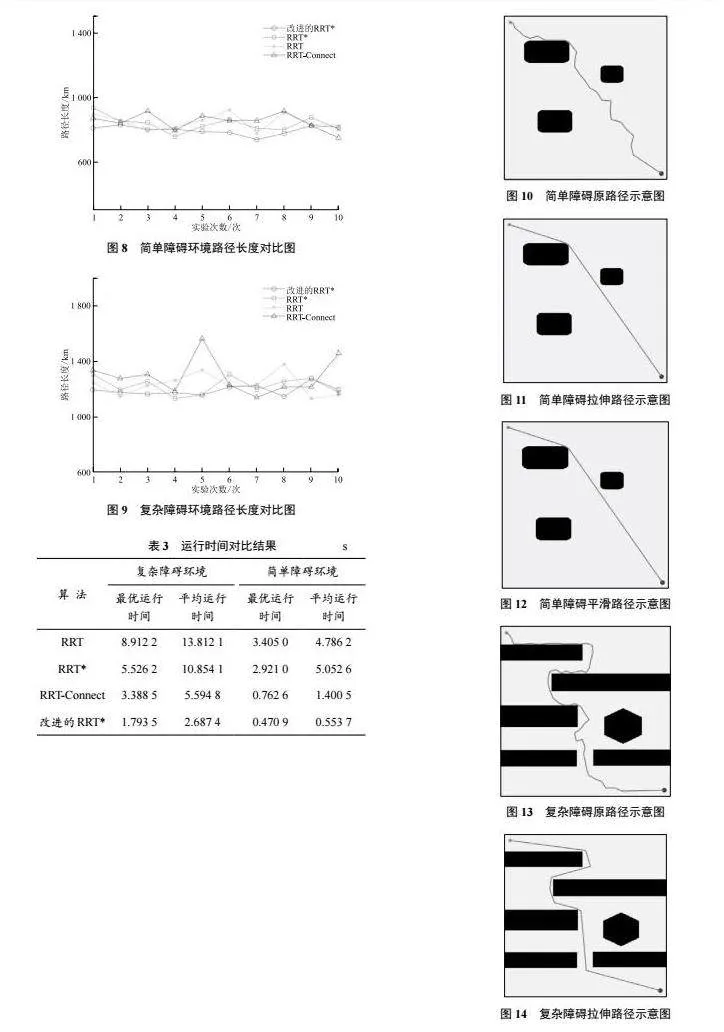
图8、图9所示为各算法在简单、复杂障碍环境下的路径长度对比图。由图可知,随着实验次数的增加,改进的RRT*算法的路径长度变化更平缓,表明该算法受其内部随机性影响较小,具有较好的鲁棒性。
5.3 运行效率对比
各算法在复杂、简单障碍环境下的运行时间对比结果见表3。
由表3可知,改进的RRT*算法相较于其他3种算法在运行效率上有较大提升;在简单障碍环境下,运行效率提升尤为明显。在复杂障碍环境下改进的RRT*算法相较于运行速度较快的RRT-Connect算法,速度提升了52%;而在简单障碍环境下,这一提升更是达到了60%。这主要是因为改进的RRT*算法采样的目的性更强,面对简单障碍环境时,改进的RRT*算法的扩展步长更长,使得算法可以更快地到达目标位置。
5.4 路径平滑对比
6 结 语
本文针对RRT*算法环境适应性差的问题,提出了一种基于奖励的可变步长策略,该策略可使RRT*算法根据所处的环境动态调整步长,提高环境适应性。针对RRT*算法采样的随机性,提出贪心采样与偏向目标采样相结合的采样策略,同时引入路径长度阈值,提高采样的目的性、有效性,加快算法的运行效率。针对RRT*算法规划的路径存在冗余及尖角的问题,采用先对路径进行拉伸处理以去除冗余路径,再用三次B样条曲线进行平滑处理以去除尖角的策略。虽然本文规划的路线较短且平滑,取得了良好的效果,但是并没有实际考虑机器人的运动模型,后续将结合机器人的实际运动模型进行完善。
参考文献
[1] FRAZZOLI E, DAHLEH M A, FERON E. Real-time motion planning for agile autonomous vehicles [C]// Proceedings of the 2001 American Control Conference. Arlington, VA, USA: IEEE, 2001.
[2]谢文显,孙文磊,刘国良,等.基于强化学习的机器人智能路径规划[J].组合机床与自动化加工技术,2022,581(7):13-17.
[3] LAVALLE S M. Rapidly-exploring random trees: a new tool for path planning [J]. Computer science dept, 1998, 98(11).
[4] KARAMAN S, FRAZZOLL E. Sampling-based algorithms for optimal motion planning [J].The lnternational journal of robotics reseach, 2011, 30(7): 846-894.
[5] KUFFNER J J, LAVALLE S M. RRT-Connect: an efficient approach to single-query path planning [C]// Proceedings of the 2000 IEEE International Conference on Robot and Automation. San Francisco, CA, USA: IEEE, 2000.
[6]张瑞,周丽,刘正洋.融合RRT*与DWA算法的移动机器人动态路径规划[J].系统仿真学报,2024,36(4):957-968.
[7]于强,彭昭鸿,黎旦,等.基于MI-RRT*算法的路径规划研究[J].现代防御技术,2023,51(4):116-125.
[8]彭熙舜,陆安江,刘嘉豪,等.黄金正弦下RRT*势场算法的三维路径规划研究[J].火力与指挥控制,2022,47(12):145-151.
[9] AN B, KIM J, PARK F C. An adaptive stepsize RRT planning algorithm for open-chain robots [J]. IEEE robotics and automation letters, 2018, 3(1): 312-319.
[10]彭君. 改进RRT算法在移动机器人路径规划中的应用研究[D].南京:南京邮电大学,2022.
[11]曹毅, 李磊, 张景涛.基于深度强化学习的机械臂避障路径规划研究[J].制造业自动化,2023,45(6):160-164.
[12] SHI Y, EBERHART R C. A modified particle swarm optimizer [C]// Proeeedings of the IEEE International Conference on Evolutionary Computation. Piscataway, NJ, USA: IEEE, 1998: 69-73.
[13] EBERHART R C, SHI Y. Comparing inertia weights and constriction factors in particle swarm optimization [C]// Proceedings of the 2000 Congress on Evolutionary Computation. Piscataway, NJ, USA: IEEE, 2000: 84-88.
[14]赵文龙,ABDOU Y M. 基于改进RRT算法的移动机器人路径规划方法[J].计算机与数字工程,2022,50(8):1733-1738.
[15]张宇龙,杨金山, 王鹏伟,等.基于B样条算法的智能车辆局部避障路径规划[J].山东理工大学学报(自然科学版),2023,37(4):36-39.
猜你喜欢
物联网技术(2016年12期)2017-01-21 21:28:10
中国新通信(2016年22期)2017-01-13 09:15:21
电脑知识与技术(2016年28期)2016-12-21 13:11:43
电子技术与软件工程(2016年20期)2016-12-21 10:52:33
科技视界(2016年26期)2016-12-17 15:53:57
电脑知识与技术(2016年26期)2016-11-25 00:00:00
科技视界(2016年20期)2016-09-29 12:00:43
电脑知识与技术(2016年17期)2016-07-23 20:25:51
电脑知识与技术(2016年13期)2016-06-29 20:13:01
中国科技博览(2016年3期)2016-04-25 17:11:10
