
基于YOLOv7的显著性目标检测
2025-03-04 00:00:00刘伟杨蕾徐争超龚大伟
物联网技术 2025年5期

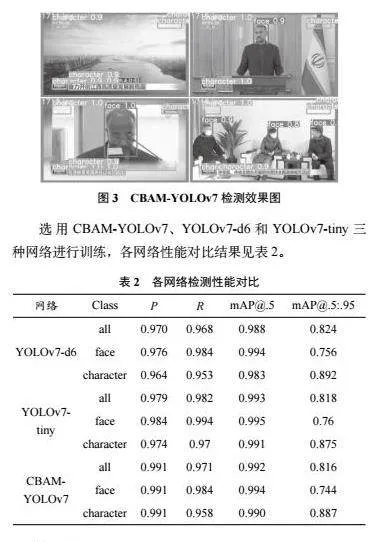
摘 要:随着信息显示技术的持续发展,信息显示的安全性问题愈发突出。信息加密显示技术的实现依赖于目标检测技术,需要根据不同信息的特点来选用相应的加密算法。为此,提出一种基于YOLOv7的显著性目标检测算法,该算法可以通过自建数据集标定显著性区域,对模型进行训练,并将得到的显著性区域用于自适应加密显示算法,以实现可分级的加密显示。实验结果表明,该模型性能优越,有着较高的检测准确率,能够为后续针对敏感信息区域进行加密提供有力的支撑。
关键词:YOLOv7;目标检测;深度学习;信息安全;CBAM;加密显示
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2025)05-00-03
0 引 言
当前,隐私保护议题受到社会各界的广泛关注,信息显示安全也成为人们讨论的热点。主流的加密显示技术通过生成与原图相关性很高的干扰帧,将其与原图叠加并进行前后帧间隔显示,再通过主动式快门眼镜在人眼接收端滤去干扰帧,从而达到加密显示的目的[1]。干扰帧的生成需借助目标检测算法检测出显著性区域,并根据区域内容特点,选择合适的自适应加密算法对区域进行加密。显著性区域主要包括人脸和字符。本文提出一种基于YOLOv7的显著性区域检测算法,通过自建数据集训练模型权重。当该算法与加密显示技术相结合时,能够广泛应用于会议室、作战室等场景,对多种类型的敏感信息进行加密处理,使得拥有不同权限的人仅能看到与其权限相匹配的保密信息。
1 研究现状
本文提出了一种基于YOLOv7的显著性目标检测算法,该算法通过对图像各个位置进行采样分析,检测是否存在特定对象,并根据测试结果动态调整区域边界,从而更准确地预测对象的真实边界框。当前,目标检测技术主要分为附着锚点和非附着锚点两类。无锚点算法能够借助密集预测直接推测目标位置与尺度,但该方法往往会产生大量候选框,其中大部分为无目标的背景框,从而增加了计算负担及误检风险。此外,对于体积小、不易察觉的目标,当感受野过大时,无法对目标进行准确提取,导致检测精度下降。针对上述问题,本文选择基于锚点的算法,其中一阶段检测算法将图像分成若干网格,再利用聚类算法找出每个网格内的锚点;二阶段检测算法,如Mask R-CNN[2]、Faster R-CNN[3]、Cascade R-CNN[4]等则使用区域建议网络(RPN)筛选锚点。常见的一阶段检测算法包括YOLOv4[5]、YOLOv5[6]、SSD等。自2016年推出以来,YOLO已被广泛应用于基于深度神经网络的实时目标识别和定位系统,并且随着不断迭代和改进,YOLO在平衡速度和精度方面不断精进,成为目标检测的主流技术。YOLOv5作为YOLO系列的一个经典版本,性能表现优越。而YOLOv7在YOLOv5的基础上将模型重新参数化引入到网络架构中,并提出了一种新的高效网络结构ELAN,以及一种包括辅助头部的训练方法。该方法使得YOLOv7得以在高达5~160帧/s的画面刷新率下保持优异的性能[7-9]。故本文选用YOLOv7作为本次研究的基准网络。
2 目标检测网络
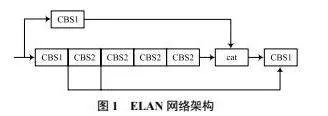
YOLOv7创新地引入了高效的ELAN网络架构,以控制最长与最短的梯度路径,优化网络特性学习并增强其抗干扰能力。图1所示为ELAN网络架构,该网络由两部分组成,第一部分采用1×1卷积对通道数进行调整;第二部分运用1×1卷积模块与3×3卷积模块对特征进行深度抽取。最后将两个部分的特征融合,形成最终的特征提取结果。
3 CBAM-YOLOv7改进算法
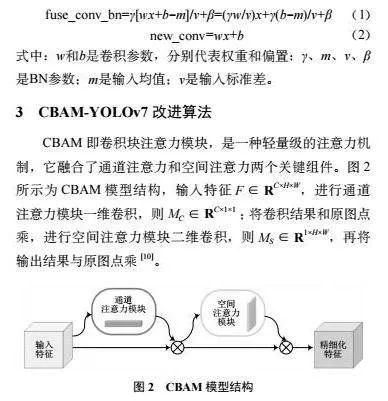
CBAM即卷积块注意力模块,是一种轻量级的注意力机制,它融合了通道注意力和空间注意力两个关键组件。图2所示为CBAM模型结构,输入特征F∈RC×H×W,进行通道注意力模块一维卷积,则MC∈RC×1×1;将卷积结果和原图点乘,进行空间注意力模块二维卷积,则MS∈R1×H×W,再将输出结果与原图点乘[10]。
通道注意力模块的核心任务在于增强各通道的特征表达能力。空间注意力模块的主要目的是凸显图像中不同位置的重要性。CBAM模块通过自适应地学习通道和空间注意力权重,显著提升了卷积神经网络的特征表达能力。通过将通道注意力和空间注意力相结合,CBAM模块能够同时捕捉不同维度上特征之间的相关性,进而优化图像识别的性能。
4 实验与结果分析
4.1 自制数据集
图像中的信息分为动态信息和静态信息,动态信息包括移动的人或物体,常出现在画面中部,表示情景、过程等信息;静态信息包括相对静止的说明性字符、符号、图表等,常出现在画面底部、侧边,表示状态名称、型号类别等信息。针对动态信息,需要对其运动变化趋势进行跟踪与标记,及时捕捉其位置,确保加密的全面性;针对静态信息,其在画面中的位置相对静止,重点在于捕捉图像内部的光学特征,包括亮度、对比度、饱和度、边缘信息丰富程度等,结合人眼的观看习惯,针对性地进行加密。
人脸和字符检测作为计算机视觉领域的常见算法,已被广泛应用于多个场景。因此,为了获得准确详细的结果,构建一个场景丰富、规模庞大、注释更详细准确的数据集进行训练和测试显得尤为重要。网上已有的数据集往往只针对某一动态信息进行归纳收集,比如固定摄像头拍摄的车辆车牌检测数据集只包括动态的车辆车牌,而缺乏对路边的固定指示牌等静态信息的标记。为了满足静态信息和动态信息并存的要求,通过官网下载新闻联播录像,并借助MATLAB R2017a工具对录像按照固定的时间间隔提取视频帧。通过手动筛选,删除重复的演播室图像,得到2 000张分辨率为1 280×720的图像。随后,使用labelimg工具进行手动标注,标注内容包括人脸和字符两种标签,采用YOLO格式标签并保存为txt文件,用于训练YOLOv7目标检测网络。将训练集、验证集和测试集按8∶1∶1的比例进行分配,划分为1 600张训练集、200张验证集和200张测试集,进行300轮训练。选用CBAM-YOLOv7、YOLOv7-d6和YOLOv7-tiny三种网络进行训练。
4.2 实验环境
本实验使用的服务器为七彩虹BATTLE-AX B560M-FPRO台式电脑,搭载Intel i5-10400F@2.90 GHz六核处理器,配备2块16 GB威刚DDR4 3 200 MHz内存条,具体实验环境配置见表1。
4.3 评价指标
通过查准率(Precision Rate)、查全率(Recall Rate)和mAP(mean Average Precision)等指标来衡量目标检测网络的性能。其中,mAP指标是对每种类别分别求出精确度,然后进行平均处理;而针对特定IoU区间的mAP,例如mAP@.5:.95,则代表了在0.5至0.95的间隔中按照步长0.05逐步选择IoU数值进行评估后得到的所有mAP值的平均结果。查准率、查全率的计算公式如下:
5 结 语
本文提出了一种基于YOLOv7的目标检测网络,自建新闻联播数据集并进行训练,针对人脸和字符进行检测。实验结果表明,该网络在检测查准率和查全率方面均表现出色,特别在CBAM-YOLOv7模型上,查准率高达99.1%。这一成果为后续针对敏感信息区域进行加密处理奠定了坚实的基础。今后将增加更多的检测标签,不局限于人脸和字符,还将纳入枪械、坦克等武器装备,进一步增强敏感区域的检测能力。
参考文献
[1]王鹏,王鹍. 一种用于信息安全防护的同步式屏幕显示: CN202011003136. X [P]. 2021-01-01.
[2] HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN [J]. IEEE transactions on pattern analysis and machine intelligence, 2020, 42(2): 386-397.
[3] DING X T, LI Q D, CHENG Y Q, et al. Local keypoint-based faster R-CNN [J]. Applied intellgence, 2020, 50: 3007-3022.
[4] CHENG M, FAN C, CHEN L, et al. Partial atrous cascade R-CNN [J]. Electronics, 2022, 11(8): 1241.
[5] ZENG L, DUAN X, PAN Y, et al. Research on the algorithm of helmet-wearing detection based on the optimized YOLOv4 [J]. The visual computer, 2023, 39: 2165-2175 .
[6] ZHANG R, ZHENG K, SHI P, et al. Traffic sign detection based on the improved YOLOv5 [J]. Applied sciences, 2023, 13(17): 9748.
[7]刘虎成.基于YOLOv7的交通标志目标检测方法研究[D].西安:西安电子科技大学,2023.
[8]韩朔.基于YOLOv7的缺陷鸡蛋在线检测系统的研究[D].银川:宁夏大学,2023.
[9]马铭骏.基于YOLOv7的市区道路拥堵检测研究[D].兰州:兰州交通大学,2023.
[10] YANG K, ZHANG Y, ZHANG X, et al. YOLOX with CBAM for insulator detection in transmission lines [J]. Multimedia tools and applications, 2023, 83: 43419-43437.
猜你喜欢
现代企业文化(2018年13期)2018-06-09 08:22:16
消费导刊(2017年20期)2018-01-03 06:26:38
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 23:45:18
公民与法治(2016年21期)2016-05-17 04:19:31
