
基于内容偏好和情绪倾向的微博用户兴趣画像构建方法
2025-02-28 00:00:00徐建民王铭宇
河北大学学报(自然科学版) 2025年1期








DOI:10.3969/j.issn.10001565.2025.01.010
摘" 要:微博数据的爆炸式增长,使信息筛选变得越来越困难.构建合理的微博用户兴趣画像,有助于实现精准化服务,提高推荐性能.首先,利用LDA(latent Dirichlet allocation)模型从用户历史内容中挖掘用户的内容偏好特征,并通过情绪分析模型计算用户不同内容偏好对应的情绪倾向,得到包含内容偏好及其对应情绪倾向2个维度的用户兴趣画像;在基于用户兴趣画像进行微博推荐评估时,利用用户内容偏好进行初步筛选,比较待评估博文内容与用户的内容偏好是否匹配,若匹配则进一步通过情绪倾向进行过滤,比较同一内容偏好下的情绪相似度,选取高于阈值的博文加入推荐集.真实微博数据集的实验结果表明,与基于标签的推荐模型、基于情感关联规则的推荐模型和基于主题的推荐模型相比,本文微博推荐方法具有更好的性能,在F1值上分别提升了10%、6%和2%.
关键词:用户兴趣画像;内容偏好;情绪倾向;微博推荐
中图分类号:TP391.3" ""文献标志码:A" ""文章编号:10001565(2025)01009113
Construction method of microblog user interest profile based on content preference and emotional tendency
XU Jianmin,WANG Mingyu
(School of Cyber Security and Computer, Hebei University, Baoding 071000, China)
Abstract: The explosive growth of microblogging data makes information screening increasingly difficult.Constructing a reasonable microblog user interest profile helps to achieve accurate service and improve recommendation performance. First, the LDA (latent Dirichlet allocation) model is used to excavate the users content preference characteristics from the users historical content,and the corresponding emotional tendency in the users different content preferences is calculated by the emotional analysis model, so as to obtain the users interest profile containing two dimensions of content preferences and their corresponding emotional tendencies. When evaluating microblog recommendations based on user interest profile, where the users content preferences are used for the initial screening first to see whether the content of the blog post matches with the users content preference. And if they match each other, the algrithm would further filters the blog posts by emotional tendency, compares their emotional similarity under the same content preference, and select the blog posts above the threshold to add into the recommendation set. The experimental results on the real microblog dataset show that the microblog recommendation
收稿日期:20240919;修回日期:20241105
基金项目:
国家社会科学基金资助项目(23BTQ092)
第一作者:徐建民(1966—),男,河北大学教授,博士生导师,主要从事信息检索方向研究.
E-mail:hbuxjm@hbu.edu.cn
通信作者:王铭宇(1997—),男,河北大学在读硕士研究生,主要从事微博推荐方向研究.E-mail:yu668135@163.com
method in this paper has better performance compared with the label-based recommendation model, sentiment association rule-based recommendation model and topic-based recommendation model, with 10%, 6% and 2% improvement in the F1 value, respectively.
Key words: user interest profile;content preference;emotions tendency;microblog recommendation
近年来,微博凭借其信息简短、传播快、更新及时的优势,已成为国内主流的社交媒体.然而,随着微博用户和信息的爆炸式增长,信息过载现象也日益突出,导致用户难以获取自己真正感兴趣信息.如何在海量的微博数据中精准地挖掘出用户感兴趣的内容,构建用户画像并应用于微博推荐,已成为被广泛关注的问题之一[1-3].
用户画像是真实用户的虚拟代表,是建立在真实数据上的目标用户模型[4].通过对用户行为、兴趣的挖掘和分析得到的用户画像,可以直观展示用户的兴趣偏好[5],已有用户画像构建的研究主要分为数值型标签的构建和文本型标签的构建[6],数值型画像标签数据通常借助调查问卷、用户行为日志以及第三方数据等[7]途径获取,研究人员按需构建统计类、规则类、模型类等不同类型标签,继而借助数理统计和算法开展用户画像建模.如夏立新等[8]采用K-means聚类算法获取不同业务场景的群体特征和信息需求构建用户画像.金吉琼等[9]采用聚类分析和判别模型对用户基础属性和消费行为数据进行汇聚,按照不同城市群进行分类,识别出城市群中用户价值类型.费鹏等[10]构建包含类别、聚类和数值等多源特征体系的多视角用户画像融合框架,从而建模预测不同用户特性.为丰富用户画像构建维度,很多研究融入语义表达的文本型标签构建用户画像并展开用户识别与推荐.如Cui等[11]基于评论文本内容挖掘用户的内容特征,并与现有的知识图谱融合来生成用户画像.于伟杰等[12]针对目前用户画像的特征构建效果不佳以及泛化能力不足的问题,提出基于全词BERT(bidirectional encoder representation from transformers)词嵌入的集成用户画像方法,并使用多分类器对不同标签分类.杨洋洋等[13]以引爆点理论为基础,从用户传播力和用户影响力入手,构建用于网络辟谣信息治理的用户画像.
微博作为具有代表性的社交平台,具有广泛影响力,针对微博用户画像的研究也引发学者关注[14].一些学者从用户的基础属性和行为属性开展研究,如王志刚等[15]利用潜在狄利克雷分布(latent Dirichlet allocation,LDA)模型挖掘用户偏好主题,并结合用户性别、关注数、总微博数等基础属性数据构建政务微博用户画像;Xu等[16]对LDA模型进行改进,提出了一种UIS-LDA主题模型,以此来挖掘用户的兴趣主题和社交主题,根据主题分布进行用户聚类,构建微博用户画像.王战平等[17]为提升推荐效果,通过微博内容扩充用户标签,并进行标签语义映射和语义相关性挖掘,构建用户标签矩阵以提取用户兴趣偏好,为用户推荐相近兴趣的微博.Bao等[18]采用词频反文档频率(term frequency-inverse document frequency, TF-IDF)和LDA模型对用户间的交互信息进行偏好分析和主题分析,并通过主题中用户博文的TF-IDF平均值得到用户偏好,从综合用户偏好和主题影响力的角度挖掘用户兴趣,提升了推荐的准确性.情感特征是指用户对文本内容的看法,例如喜欢、不喜欢,可表达出用户的情感偏好,研究用户情感有助于揭示用户的情感需求,整合情感特征的用户画像能够更加全面地刻画用户兴趣[19].如王帅等[20]综合使用Word2Vec、LDA和长短期记忆神经网络(long short term-memory network, LSTM)从基本信息、情感、行为等多特征出发构建用户画像.李铁军等[21]在对用户历史行为进行关联规则挖掘的基础上,融合情感特征生成用户的情感画像.在已有研究中,大多将情感划分为积极和消极2类粗粒度情感,而多分类的情绪是一种细粒度的情感,可捕捉用户更全面丰富的心理状态,提高用户兴趣偏好识别准确率[22].现有研究表明,用户在不同内容主题中具有不同的情绪偏好,对其有效利用可更准确挖掘用户兴趣[23].例如,某些用户在“战争”主题中发布或产生交互行为的微博通常表现出厌恶的情绪,则在该主题下带有厌恶情绪的博文更容易引起用户关注;对于宋词主题,有些用户喜欢表现喜悦类的诗词,另外一些用户可能更偏向喜欢悲伤类的诗词,合理考虑这些因素可更有效获取用户兴趣偏好.同时考虑内容偏好与情绪偏好的用户画像可从多维度视角刻画用户特征,将其应用于信息推荐,有助于提升推荐效果,但目前在微博推荐领域,缺少将2个特征结合,挖掘用户的内容偏好以及在不同内容偏好中情绪倾向以构建用户兴趣画像,进而实现微博推荐的研究.
针对以上不足,本文提出一种基于内容偏好和情绪倾向的微博用户兴趣画像的构建方法.首先,构建了结合内容偏好和情绪倾向的微博用户兴趣画像,通过LDA模型提取博文内容主题,并结合用户历史数据筛选出用户的内容偏好;在此基础上,深入分析了用户在不同内容偏好下的多类情绪分布,挖掘用户情绪倾向用以捕捉其丰富的情绪需求,综合用户的内容偏好及其情绪偏好构建更为精准的微博用户兴趣画像.然后,基于该画像设计微博推荐模型,依次进行内容偏好过滤和情绪相似度比较,实现微博推荐.该模型通过结合内容偏好与情绪倾向的多维分析,使推荐结果更具针对性和情感关联性.
1" 微博用户兴趣画像构建及推荐模型
1.1" 研究框架
基于内容偏好和情绪倾向的微博用户兴趣画像构建与推荐模型(constructing microblog user interest profiles based on content preference-emotional tendency and recommendation model, CERM)的研究框架如图1所示.
研究框架分为以下2部分:
1) 基于内容偏好和情绪倾向的微博用户兴趣画像构建.该部分包含内容偏好的提取及其情绪倾向的挖掘.
①内容偏好的提取.使用LDA模型对用户历史微博集中每一篇微博进行内容主题提取,得到每篇博文的主题向量;将用户的历史博文主题向量进行矢量加和,根据概率值高低选取前m个主题,作为用户的内容偏好.
②情绪倾向的挖掘.对于用户的内容偏好微博集中每一篇历史博文,首先对其进行数据预处理,去除不含中文的微博,删除每条微博中多余的空格、乱码,删除微博文本中不包含情绪内容的URL链接、标签信息.然后,输入Ernie-BiLSTM-Attention(ERBA)模型计算其对应的情绪分布,取分布中最大概率值所对应情绪类别表示博文情绪.计算不同内容偏好在每类情绪中的条件概率分布,以表示用户在不同内容偏好中所对应的情绪分布,挖掘用户的情绪倾向.
2) 微博推荐.首先利用LDA模型获取待评估博文的内容主题,取概率最大值对应的主题为该博文主题,使用ERBA模型计算该博文的情绪分布;其次,通过将博文主题与用户内容偏好集进行比较实现内容匹配,并进一步比较博文和用户在同一内容偏好中的情绪相似度,若情绪相似度超过阈值,则将该博文加入推荐集.
1.2" 微博用户兴趣画像构建
生成用户兴趣画像的前提是挖掘用户兴趣,用户兴趣可从内容偏好及其对应情绪倾向2方面体现.据此本文通过挖掘和分析用户历史交互数据中的内容主题和情绪分布,以生成反映其内容偏好及其情绪倾向的微博用户兴趣画像.
1.2.1" 用户内容偏好提取
用户内容偏好包括2部分:第一,借助自然语言工具LDA模型识别博文内容主题;第二,基于用户交互博文以及博文的内容主题信息,识别用户感兴趣内容主题信息.基于上述2部分提取出用户内容偏好.
1)基于LDA模型的博文内容主题挖掘
LDA模型是一种基于概率图的3层贝叶斯经典主题模型,常被应用于微博文本内容主题挖掘[24-25],LDA模型如图2所示.
图2中:T是主题数量;D、N分别表示文档总数和文档中词总数;θd表示文档d主题分布;z表示主题z中的主题词分布;α、β分别是主题分布的超参数和主题词分布的超参数;wdi、zdi分别表示文档中第i个词及其主题.
LDA模型假设每篇文档是由多个主题以一定概率组成的,每个主题由一组词语以一定概率混合生成,通过不断迭代生成文档中的词语,得主题分布θ.根据模型生成文档d的过程为:①从Dirichlet (α)分布中取样生成文档的主题分布θd;②从θd的多项式分布中取样生成文档第i个词的主题zdi;③从Dirichlet(β)分布中取样生成主题zdi下对应的词分布z,从词分布中生成词语wdi,重复以上操作生成文档d,接着重复D次得到整个语料库,确定最终的主题分布θ,表征为文档的主题向量.
在利用LDA模型对博文进行内容主题的抽取时,通过计算不同主题数T所对应的困惑度(Preplexity)确定最优主题个数,困惑度最小或处于拐点时对应的主题数为最优主题数k[26],困惑度的计算公式如式(1)所示.
Perlplexity(ND)=exp∑Dd=1logp(wd)∑Dd=1Nd,(1)
其中:ND表示文档中所有词的集合;D表示文档的数量;wd表示文档d中的单词集合;Nd表示文档d中词语数量.
随着主题数量的增加,可能会存在困惑度值逐渐递减的情况,难以确定最优主题数,因此本文加入一致性(Coherence)指标[27]作为补充,一致性描述不同主题分布之间的距离.计算不同主题数对应的一致性,其得分越高,表示主题分类效果越好.最终根据困惑度值和一致性确定最优主题数k,根据主题模型得出每篇博文bi的主题分布θbi,表示为主题向量Lbi={z1:p1,z2:p2,…,zk:pk},∑ki=1pi=1.
2)内容偏好挖掘
通过LDA模型提取用户每篇博文内容主题,将这些主题向量累加并进行归一化操作,得到用户内容主题特征的整体分布,进一步选取分布中概率值较高的前m项,确定为用户的内容偏好.具体步骤如下:
①取用户发表或交互的博文集Bu={b1,b2,…,bn},其中n为博文数量.
②对Bu中每篇博文的主题向量使用公式(2)矢量相加.
③利用公式(3)进行归一化操作得到用户内容主题特征的整体分布.
Lu=Lb1+Lb2+…+Lbn={zu1:p1,zu2:p2,…,zuk:pk},(2)
pi=pi∑ki=1pi.(3)
对归一化后的分布进行降序的排序后,设置前m项主题类别作为用户u的内容偏好Tu={z1,z2,…,zm}.
1.2.2" 用户情绪倾向挖掘
在上述提取用户内容偏好的基础上,筛选出与用户内容偏好相关的博文,并利用ERBA模型获取到其情绪分布,随后进行统计分析,以确定用户在不同内容偏好中的情绪倾向,最终汇总各类内容偏好中的情绪倾向来表征用户情绪倾向.
1)情绪语料库构建
目前尚无用于情绪识别的权威情绪语料库,因此,本文选用2个公开的数据集NLPCC2014和NLPCC2018构建基础情绪语料库,情绪类别按照大连理工大学情感词典[28](DUTSD)的分类标准,分为“乐”、“好”、“哀”、“恶”、“怒”、“惧”和“惊”7个类别,同时取simplifyweibo_4_mood部分情绪数据作为补充数据集,合并到基础情绪语料库中,部分情绪文本示例如表1所示.
2)微博文本情绪挖掘
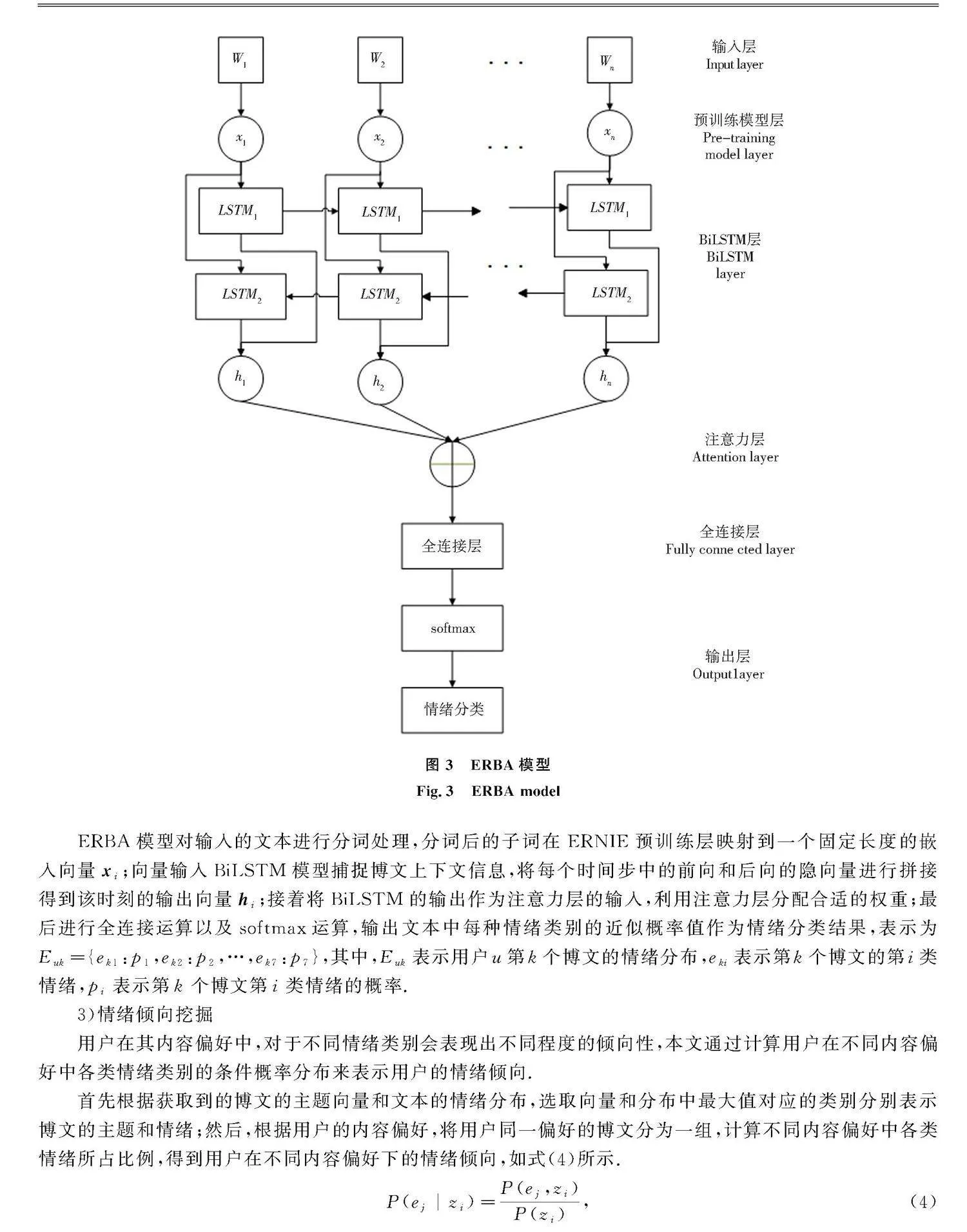
本研究采用ERBA模型对博文进行情绪分析.ERBA模型结合了深度学习模型ERNIE(enhanced language representation with informative entities)、双向长短期记忆网络(bidirectional long short-term memory network, BiLSTM)以及注意力机制(attention)3个模块,在文本分类任务上取得不错的效果[29].ERNIE预训练模型通过对文本的语法结构、词法结构和语义信息的统一建模,捕捉文本的多层次语义信息;同时BiLSTM进一步考虑文本前后信息,以获取更全面的语境信息;通过注意力机制动态分配权重,提高情绪分类的准确性.本文细化出7个情绪类别,并通过ERBA模型计算得出一条博文在7类情绪中的概率分布.ERBA模型图如图3所示.
ERBA模型对输入的文本进行分词处理,分词后的子词在ERNIE预训练层映射到一个固定长度的嵌入向量xi;向量输入BiLSTM模型捕捉博文上下文信息,将每个时间步中的前向和后向的隐向量进行拼接得到该时刻的输出向量hi;接着将BiLSTM的输出作为注意力层的输入,利用注意力层分配合适的权重;最后进行全连接运算以及softmax运算,输出文本中每种情绪类别的近似概率值作为情绪分类结果,表示为Euk={ek1:p1,ek2:p2,…,ek7:p7},其中,Euk表示用户u第k个博文的情绪分布,eki表示第k个博文的第i类情绪,pi表示第k个博文第i类情绪的概率.
3)情绪倾向挖掘
用户在其内容偏好中,对于不同情绪类别会表现出不同程度的倾向性,本文通过计算用户在不同内容偏好中各类情绪类别的条件概率分布来表示用户的情绪倾向.
首先根据获取到的博文的主题向量和文本的情绪分布,选取向量和分布中最大值对应的类别分别表示博文的主题和情绪;然后,根据用户的内容偏好,将用户同一偏好的博文分为一组,计算不同内容偏好中各类情绪所占比例,得到用户在不同内容偏好下的情绪倾向,如式(4)所示.
P(ej|zi)=P(ej,zi)P(zi),(4)
其中:P(ej|zi)表示用户在第i个内容偏好下反映出情绪j的条件概率;P(ej,zi)表示用户博文中内容偏好i和情绪j同时出现的概率;P(zi)表示用户博文中属于内容偏好i的概率.最后将用户u在内容偏好下的情绪偏好表示为qui={P(e1|zi),P(e2|zi),…,P(e7|zi)}.
1.2.3" 构建用户兴趣画像
通过将上述提取到的用户内容偏好和不同内容偏好对应情绪倾向相结合,共同刻画用户兴趣画像,最终构建的用户兴趣画像描述模型如图4所示.
图4中以某一用户为例,首先利用LDA模型提取用户的内容偏好,将用户微博集按照不同内容偏好进行分类,计算属于同一偏好下的情绪分布,表示为当前偏好下对应的情绪倾向,构建了同时包含内容偏好及内容偏好对应的情绪倾向的微博用户兴趣画像,其中,情绪倾向中不同颜色表示不同的情绪类别,情绪占比越大,其颜色区域就越大,同时为方便展示,最终示例中只列举了情绪倾向中占比最高的2类情绪类别.
1.3" 微博推荐
判断一篇待评估微博d是否被推荐给用户u的步骤如下:
1)利用LDA模型生成的内容主题,取其中概率值最大的类别作为d的主题,记作zd;同时将d输入ERBA模型中生成该博文对应的情绪分布,表示为Ed={ed1:p1,ed2:p2,…,ed7:p7}.
2)将d的主题zd与u的内容偏好Tu进行匹配,若在Tu中存在zd,则进一步比较情绪相似度,否则,不进行推荐.通过式(5)计算d和u在zd下情绪倾向quzd的余弦相似度,得出情绪相似度,表示为si,当相似度高于阈值时推荐给用户u.
si=sim(Ed,quzd)=Ed·quzd|Ed||quzd|.(5)
2" 实验
2.1" 数据集
以新浪微博为例,通过python爬虫程序从新浪微博平台获取到用户的基本个人信息、博文、关注关系以及社交网络交互行为信息.首先对实验数据进行预处理,过滤掉文本中地址链接、@+用户名和其他无意义的字符等噪音数据;然后进行分词操作,去除停用词,其中,分词采用的python中jieba开源组件,最终所获原始数据包含454 407名用户、143 979条原创博文、26 915条评论信息、368 726条关注、124 356条点赞和24 531条转发.
2.2" 实验评价指标
采用精确率(Precision)、召回率(Recall)和F1值(F1)作为模型的推荐性能评价指标.精确率描述的是推荐列表中用户真实感兴趣的微博所占比例,如式(6)所示;召回率描述的是用户真实感兴趣的微博被推荐的比例,如式(7)所示;F1综合了模型的精确率和召回率,是调和平均数,如式(8)所示.
Precision=|R∩L|/|R|,(6)
Recall=|R∩L|/|L|,(7)
F1=2×Precision×RecallPrecision+Recall,(8)
其中:R表示推荐给用户的微博集合;L表示用户真实感兴趣的微博集合.目标用户发布、点赞、转发和评论的微博都属于用户真实感兴趣微博.
为验证推荐算法的精确率,挑选出833名活跃用户,以及用户的138 406条微博数据进行实验,将实验数据按照8∶2划分为训练集和测试集[21, 30],训练集学习用户的相关兴趣偏好,测试集验证实验方法的有效性.本文在计算评价指标时,选取测试集中用户实际感兴趣的博文作为正例,随机选取正例30%作为负例[11],正例和负例共同构成用户的测试集.
2.3" 实验参数设置
2.3.1" 情绪分类参数设置
采用ERBA模型对微博文本进行情绪分类,将基础情绪语料库文本输入ERBA模型中训练最优参数,保留最优参数用于生成文本的情绪分布,相关训练参数设置如表2所示.
2.3.2" 内容偏好的相关参数确定
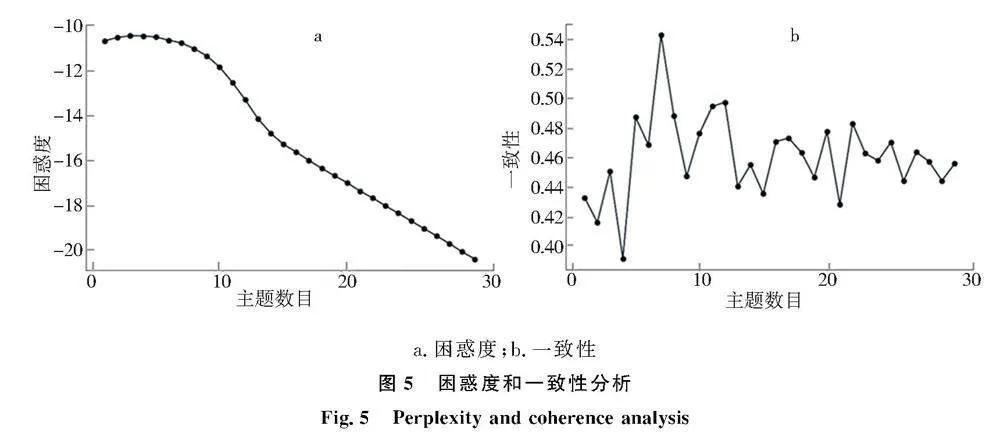
构建用户的内容偏好时,涉及到2个参数,分别是用户微博集中最优主题数的确定以及与内容偏好相关的主题数的确定.通过LDA模型进行用户博文主题分类时,首先利用LDA模型的困惑度和一致性指标确定用户微博集的最优主题数.计算结果如图5所示.
a.困惑度;b.一致性
通过观察困惑度曲线可得知,随着主题数目的不断增加,不同主题数目对应的困惑度值逐渐减小,主题数在15出现拐点,之后逐渐减缓,同时观察一致性曲线,发现当主题数目处于15~30时,主题数目为22时一致性得分相对最高,因此本文设置主题数目22为最优主题数.
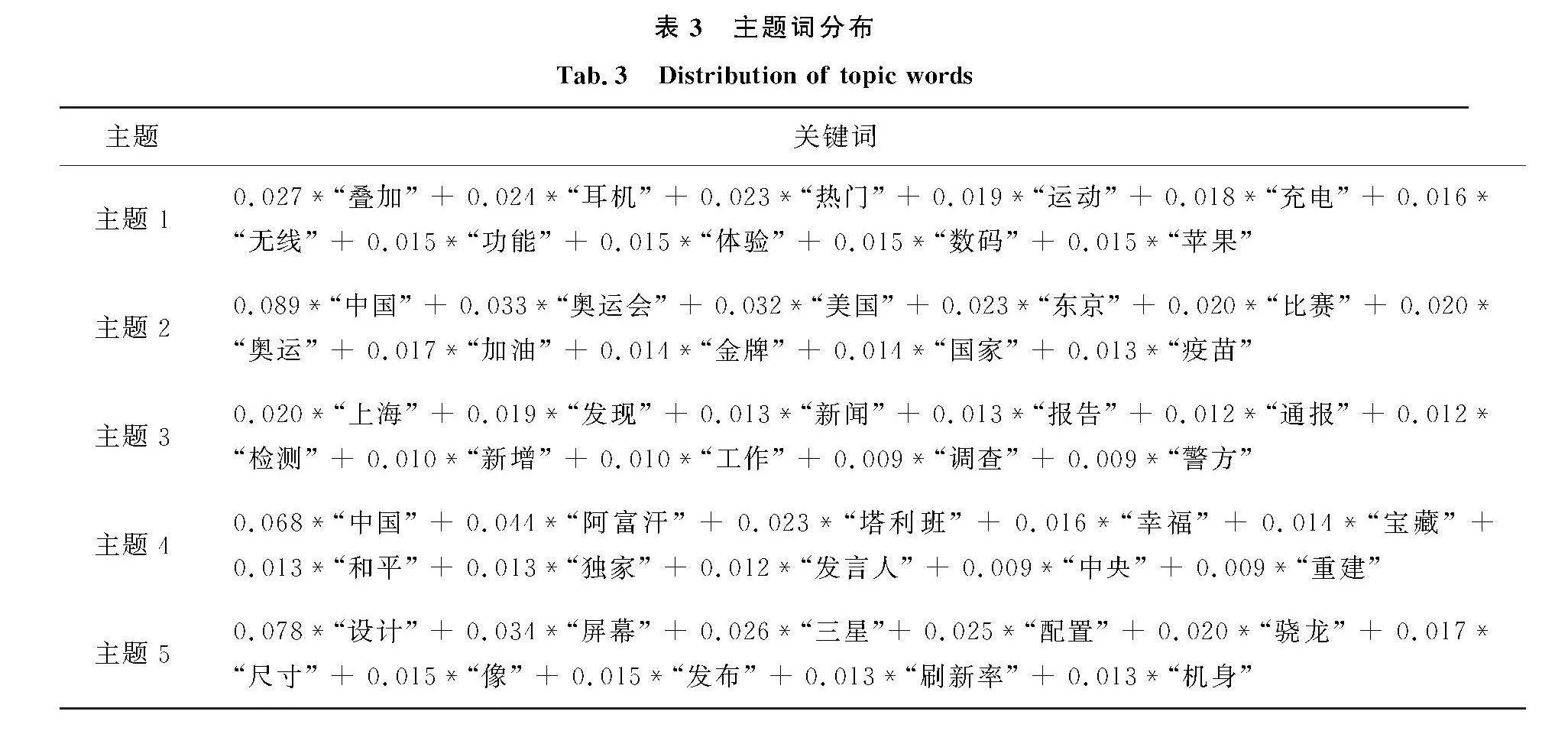
根据确定的最优主题数,利用LDA模型获取主题和主题下的相关关键词,部分数据见表3.
假设用户在某一主题中发布的博文与交互的博文表达相似的情绪,用户在主题中存在固定的情绪偏好.进行验证实验时,挑选出833名活跃用户,分为2组,一组为用户发布微博数据,另一组为用户点赞、评论和转发微博数据,作为用户交互行为数据.将用户同一个主题的原创与交互博文进行情绪余弦相似度比较,经实验验证,在85%的情况下,同一主题下发布与交互博文的情绪相似度大于0.6.分析表明,用户在同一主题下发布与交互博文之间表达了相似的情绪偏好,用户在某一主题下有着固定的情绪倾向,这种情绪倾向使得用户对该主题中相似情绪的博文产生兴趣并与之交互.因此,考虑主题和主题中情绪倾向将能有效地刻画出用户的兴趣.
为探究与用户内容偏好相关的主题,需要将每个用户的历史博文主题向量使用式(2)进行矢量相加,然后用式(3)进行归一化操作得出用户的主题分布,取分布中概率值较高的m类主题表示为用户的内容偏好Tu,然后从用户历史博文集中筛选出内容属于Tu的博文数据.例如,当选取用户的内容偏好相关的主题数为15时,统计出每个用户的主题分布中概率值前15对应的主题;使用用户在这15类主题下的历史博文用于训练用户在该类主题下的情绪偏好,同时根据本研究实证数据,确定情绪相似度阈值为0.6,根据测试集计算出该主题数对应的F1值.通过分析不同主题数对应推荐效果的F1值,确定与用户内容偏好相关的最优主题数.经统计发现,用户主题数主要集中在13~20,因此本文分析用户在该区间内的F1值,结果如图6所示.
由图6可以看出,推荐的有效性会受到不同主题数的影响,随着主题数的增加,模型F1值呈先上升后下降的趋势,在主题数为15时,达到最大值.这是由于随着主题数增加,扩大了用户的内容偏好范围,引入了用户实际不感兴趣的主题,最终影响到推荐的效果.在后续实验将选取15类主题作为用户内容偏好.
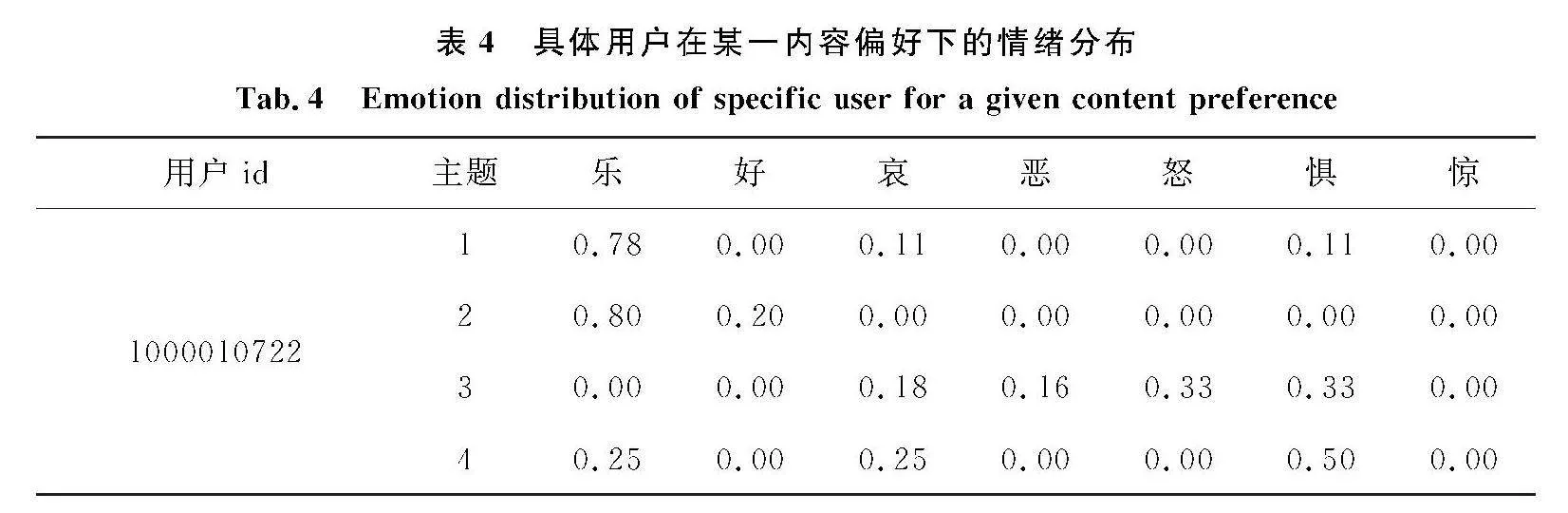
随机选取数据集中爬取的真实用户1000010722,分析其在内容偏好为4时的情绪分布,用户1000010722在偏好为4时的相关主题为主题1、主题2、主题3和主题4,情绪分布情况如表4所示.
表4中观察到用户在主题1和主题2中更喜欢“乐”的情绪,表现出一种积极的情绪,而在主题3和主题4中,更倾向于“惧”情绪,表现出一种消极的情绪,同时,相比于主题3,用户在主题4中也存在一部分积极的情绪.可以看出用户在不同主题之间情绪分布存在差异,划分效果较好.
2.3.3" 用户兴趣画像构建的消融实验
为研究不同特征结合的用户画像标签对用户兴趣画像识别的影响,本文运用随机森林算法对内容偏好特征及其情绪倾向特征画像标签的组合展开分类识别,随机种子设置为42,决策树数量设置为100,以准确率(ACC)指标比较不同兴趣画像的分类效果,其中,RF_T仅使用内容偏好特征作为随机森林的输入变量,RF_E仅使用情绪倾向特征作为输入变量,RF_TE使用内容偏好特征及其情绪倾向特征进行训练,如表5所示.
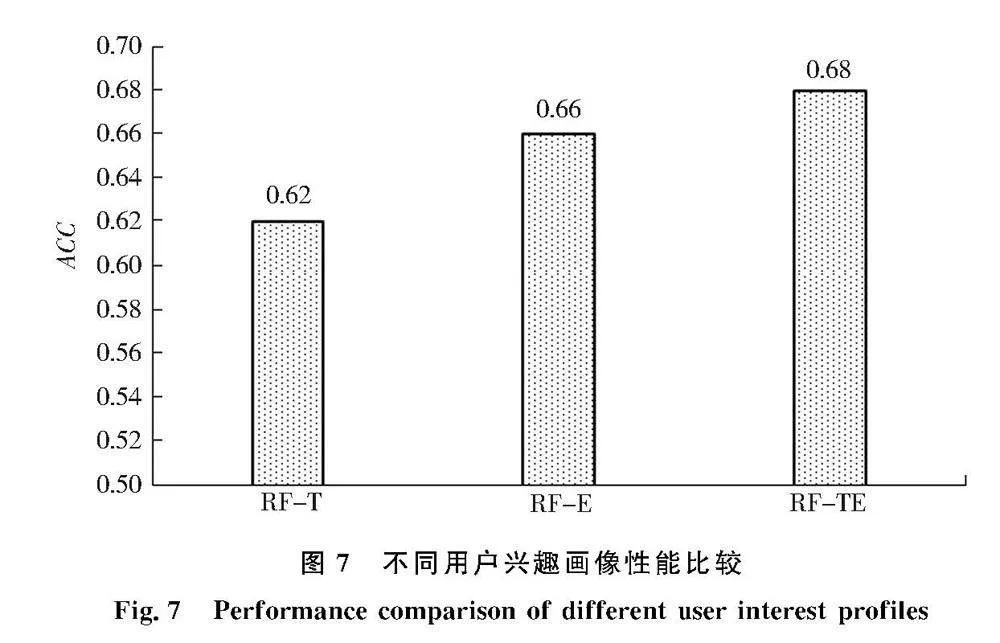
本文采用上述数据集,设定数据集的70%作为训练集,30%作为测试集,采用基尼指数作为分类标准.针对上述3个用户兴趣画像,得到结果如图7所示.
从图7可看出,使用情绪倾向特征的RF_E高于使用内容偏好特征的RF_T,说明相较于用户的内容偏好,细粒度的情绪可挖掘用户丰富的情感信息,可更有效刻画用户兴趣画像;与模型RF_TE相比,仅使用内容偏好特征的RF_T和仅使用情绪倾向特征的RF_E评价指标都较低,说明内容偏好及其情绪倾向进行结合可提升随机森林算法在用户兴趣画像的分类识别效果.
2.4" 对比实验
为验证本文提出的CERM模型在微博推荐中的效果,选取了其他4种推荐模型进行对比,如表6所示.
为验证结合用户的内容偏好和情绪偏好应用于推荐的有效性,设置了对比实验,其中,LBRM[17]基于社会化标签,通过标签语义相似度构建用户-标签矩阵,实现了微博推荐.SARM[21]利用情感信息,挖掘关联规则,将强关联规则用于微博推荐.TPRM[18]综合考虑主题相关性和用户偏好,找出相似用户实现微博推荐.CERM-EM是本文模型的变式,其只考虑了情绪特征,依据用户博文的情绪分布,计算出每类情绪的条件概率,表示为用户的情绪分布,计算其分布和待评估博文之间的情绪相似度实现推荐.
对比实验结果如表7所示.根据表7可知,与LBRM、SARM、TPRM和CERM-EM相比,CERM的F1值分别提升了10%、6%、2%、4%.主要原因是CERM模型利用LDA模型获取博文内容主题信息,利用用户一段时间内博文的内容主题信息进行计算,在众多主题信息中筛选出用户感兴趣的内容信息,作为用户的内容偏好;接着引入情绪特征,挖掘出用户在不同内容偏好下的情绪倾向,使用户内容偏好与情绪倾向得到有效表示,获得更好的推荐效果.
LBRM模型利用标签信息,未考虑到内容特征和情绪特征对用户兴趣偏好的影响,致使推荐效果不如CERM模型;SARM模型引入情感特征,验证了情感有助于提升推荐效果,但效果差于CERM-EM模型,表明细粒度的情绪可更有效刻画用户兴趣;TPRM模型考虑到了内容特征,通过结合用户的主题影响力和计算主题中用户博文的TF-IDF平均值得到的用户偏好,实现了微博推荐,但对用户兴趣的挖掘不够深入,忽略了用户与内容特征相关的情绪偏好.CERM模型在内容特征的基础上引入情绪特征,挖掘用户在内容偏好下的情绪倾向,在同一内容偏好下推荐与用户情绪倾向相似的博文,提升了推荐效果.同时相较于CERM-EM模型仅挖掘情绪倾向,忽略了用户的内容特征对用户偏好的影响,导致情绪倾向与内容特征未能有效结合,影响推荐的效果.
CERM模型效果好于上述对比模型,说明用户存在固定的内容偏好,在不同偏好下有着固定的情绪倾向,利用内容偏好首先过滤一部分信息,只关注用户感兴趣内容,减少计算量的同时也能提高推荐的精确率,进一步推荐与用户情绪相似度高的博文,能有效提升推荐效果.总结上述实验分析可得,同时考虑用户的内容偏好及其情绪倾向能够满足个性化需求,可提升推荐的有效性.
3" 结语
利用LDA模型挖掘用户内容偏好,并在此基础上引入不同内容偏好下的情绪倾向,将二者整合得到用户兴趣画像,实现了对微博用户的精准描述.与已有方法相比,该方法能更为准确地刻画用户兴趣画像,并提升推荐效果.本文的研究方法不仅可以应用于微博平台,还可以扩展到其他平台,例如Twitter、知乎和小红书等.不足之处在于:1)目前仍缺乏完善的情绪语料库,用户情绪倾向的刻画还不够精细.2)只考虑了文本的情绪特征,并没有深入分析不同用户的等级和差异性.未来将针对上述不足展开深入研究,进一步提高微博推荐的性能.
参" 考" 文" 献:
[1]" AZZAM F, KAYED M, ALI A. A model for generating a user dynamic profile on social media[J]. J King Saud Univ Comput Inf Sci, 2022, 34(10): 9132-9145. DOI: 10.1016/j.jksuci.2022.08.036.
[2]" KHALIL M M Y, WANG Q X, CHEN B, et al. Cross-modality representation learning from transformer for hashtag prediction[J]. J Big Data, 2023, 10(1): 140-148. DOI: 10.1186/s40537-023-00824-2.
[3]" DJENOURI Y, BELHADI A, SRIVASTAVA G, et al. An efficient and accurate GPU-based deep learning model for multimedia recommendation[J]. ACM Trans Multimedia Comput Commun Appl, 2024, 20(2): 1-18. DOI: 10.1145/3524022.
[4]" 邵一博,秦玉华,崔永军,等.融合多粒度信息的用户画像生成方法[J].计算机应用研究, 2024, 41(2): 401-407. DOI: 10.19734/j.issn.1001-3695.2023.05.0234.
[5]" 李丹,高建忠.基于用户画像的图书馆推荐服务初探[J].图书馆, 2019(7): 66-71.DOI: 10.3969/j.issn.1002-1558.2019.07.010.
[6]" 陈添源,梅鑫.多源数据融合的用户画像识别与推荐实证研究[J].情报理论与实践, 2024, 47(4): 171-180. DOI: 10.16353/j.cnki.1000-7490.2024.04.022.
[7]" PUJAHARI A, SISODIA D S. Item feature refinement using matrix factorization and boosted learning based user profile generation for content-based recommender systems[J]. Expert Syst Appl, 2022, 206: 117849. DOI: 10.1016/j.eswa.2022.117849.
[8]" 夏立新,胡畔,刘坤华,等.融入信息推荐场景要素的在线健康社区用户画像研究[J].图书情报知识, 2023, 40(3): 116-128.DOI: 10.13366/j.dik.2023.03.116.
[9]" 金吉琼,居雷,张易,等.基于用户画像的卷烟消费者特征识别和价值评估[J].烟草科技, 2023, 56(1):105-112. DOI:10.16135/j.issn1002-0861.2022.0531.
[10]" 费鹏,林鸿飞,杨亮,等.一种用于构建用户画像的多视角融合框架[J].计算机科学, 2018, 45(1): 179-182. DOI: 10.11896/j.issn.1002-137X.2018.01.031.
[11]" CUI Y C, YU H L, GUO X X, et al. RAKCR: reviews sentiment-aware based knowledge graph convolutional networks for Personalized Recommendation[J]. Expert Syst Appl, 2024, 248: 123403. DOI: 10.1016/j.eswa.2024.123403.
[12]" 于伟杰,杨文忠,任秋如.基于全词BERT的集成用户画像方法[J].东北师大学报(自然科学版), 2022, 54(4): 87-92. DOI: 10.16163/j.cnki.dslkxb202104053.
[13]" 杨洋洋.数据驱动下网络辟谣信息画像与治理模式研究——基于引爆点理论[J/OL].情报科学, 1-14[2024-05-07]. http://kns.cnki.net/kcms/detail/22.1264.G2.20240506.1702.014.html.
[14]" 吴树芳,吴崇崇,朱杰.基于兴趣转移的微博用户动态画像生成[J].情报科学, 2021, 39(8): 103-111.DOI: 10.13833/j.issn.1007-7634.2021.08.013.
[15]" 王志刚,邱长波.基于主题的政务微博评论用户画像研究[J].情报杂志, 2022, 41(3): 159-165.DOI: 10.3969/j.issn.1002-1965.2022.03.022.
[16]" XU K, ZHENG X S, CAI Y, et al. Improving user recommendation by extracting social topics and interest topics of users in uni-directional social networks[J]. Knowl Based Syst, 2018, 140: 120-133. DOI: 10.1016/j.knosys.2017.10.031.
[17]" 王战平,夏榕.基于社会化标签挖掘的微博内容推荐方法研究[J].情报科学, 2021, 39(5): 91-96.DOI:10.13833/j.issn.1007-7634.2021.05.013.
[18]" BAO F, XU W, FENG Y, et al. A topic-rank recommendation model based on microblog topic relevance amp;user preference analysis[J]. Hum-Cent Comput Info, 2022, 12(10): 1-19.DOI: https://doi.org/10.22967/HCIS.2022.12.010.
[19]" 杨永清,孙凯,张媛媛,等.基于信息画像的突发事故灾难舆情传播效果的预测模型研究[J].情报科学, 2024, 42(4), 27-35. DOI: 10.13833/j.issn.1007-7634.2024.04.004.
[20]" 王帅,纪雪梅.基于在线健康社区用户画像的情感表达特征研究[J].情报理论与实践, 2022, 45(6): 179-87. DOI: 10.16353/j.cnki.1000-7490.2022.06.024.
[21]" 李铁军,颜端武,杨雄飞.基于情感加权关联规则的微博推荐研究[J].数据分析与知识发现, 2020, 4(4): 27-33. DOI: 10.11925/infotech.2096-3467.2019.0765.
[22]" 赵又霖,林怡妮,陆颖隽,等.社会感知数据驱动下用户时空行为画像及语义关联研究[J].图书馆学研究, 2024(2): 54-62. DOI: 10.3969/j.issn.1672-0504.2022.01.011.
[23]" ROBERTS K, ROACH M A, JOHNSON J, et al. EmpaTweet: annotating and detecting emotions on twitter[C]//Proc 8th Int Conf Lang Resour Eval LREC 2012, 2012: 3806-3813.DOI: 10.1155/2012/678107.
[24]" 张柳,王晰巍,黄博,等.基于LDA模型的新冠肺炎疫情微博用户主题聚类图谱及主题传播路径研究[J].情报学报, 2021, 40(3): 234-244. DOI: 10.3772/j.issn.1000-0135.2021.03.002.
[25]" LIU X, BURNS A C, HOU Y J. An investigation of brand-related user-generated content on twitter[J]. J Advert, 2017, 46(2): 236-247. DOI: 10.1080/00913367.2017.1297273.
[26]" 张国防,王鑫,徐建民.基于主题词共现的文档非对称关系量化研究[J].数据分析与知识发现, 2023, 7(3): 110-120. DOI: 10.11925/infotech.2096-3467.2022.0342.
[27]" 曾子明,陈思语.基于LDA与BERT-BiLSTM-Attention模型的突发公共卫生事件网络舆情演化分析[J].情报理论与实践, 2023, 46(9): 158-166. DOI: 10.16353/j.cnki.1000-7490.2023.09.019.
[28]" 徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报, 2008, 27(2): 180-185. DOI: 10.3969/j.issn.1000-0135.2008.02.004.
[29]" 黄山成,韩东红,乔百友,等.基于 ERNIE2. 0-BiLSTM-Attention 的隐式情感分析方法[J].小型微型计算机系统, 2021, 42(12): 2485-2489. DOI:1000-1220(2021)12-2485-05.
[30]" 张金柱,孙雯雯,仇蒙蒙.融合异构网络表示学习与注意力机制的引文推荐研究[J/OL]. 数据分析与知识发现, 1-17 [2024-06-19]. http://kns.cnki.net/kcms/detail/10.1478.g2.20240117.1104.012.html.
(责任编辑:孟素兰)
