
基于用户评分多元关系分析的个性化推荐研究
2025-02-20 00:00:00张君
江苏科技信息 2025年2期
关键词:个性化推荐





摘要:随着信息爆炸,个性化推荐技术成为提高信息检索效率和用户体验的关键。文章针对传统协同过滤推荐方法仅依赖用户静态评分导致推荐质量低的问题,提出基于用户评分多元关系分析的个性化推荐方法。该方法综合分析用户评分一致性、信任关系及用户行为,引入时间因素反映用户兴趣变化,建立用户间多元关系模型。实验结果表明,相较于其他推荐方法,文章方法在实际应用中能提供更精确的推荐服务,有效满足用户信息需求,实现了推荐质量的显著提升。
关键词:个性化推荐;用户评分;用户多元关系;用户行为量化
中图分类号:G202中图分类号文献标志码:A
0 引言
随着信息技术和移动互联网的高速发展,互联网中的信息流以指数级别的速度激增,提供了丰富的信息资源。但这无形地增加了用户准确获取自身所需信息的难度,即如何从海量的信息中准确地找到用户真正需要的信息。传统的信息筛选机制已经无法满足用户的个性化信息需求。在此背景下,个性化推荐技术应运而生,该方法主要通过分析用户的行为、偏好,比较用户间的相似度,给出个性化的信息推荐。这种技术不仅提高了信息检索的效率,也极大地增强了用户的使用体验。它已经在电子商务、社交网络、新闻推送、音乐电影推荐等领域得到了广泛应用。
目前,很多信息服务平台提供了用户评分功能,用于显式体现用户对于信息资源的偏好程度。协同过滤算法是应用最为广泛的推荐算法之一,具有简单、有效等优势[1]。然而,该方法仅仅依赖用户对项目的评分数据进行计算,未充分考虑其他关键因素。例如,用户之间的信任关系,这可能导致推荐质量不够理想。针对这一问题,本文以用户对项目的评分为基础,分析用户间的评分一致性与信任关系,结合用户行为进行综合分析,构建用户间的多元关系模型。通过此模型,为目标用户找到更加相似的最近邻集合,从而提供更精确的信息资源推荐服务。
1 相关研究
协同过滤推荐是一种主要依赖用户对项目的评分来进行推荐的算法,其首要工作是进行相似性度量,即找到与目标用户兴趣偏好相似的用户群体[2]。由于用户的兴趣偏好会随着时间推移发生变化,过去评分较高的项目在实施推荐时不一定与用户当前兴趣偏好相匹配,因此相关学者将时间因素与用户评分相结合。任磊[3]针对传统协同推荐算法一般只利用评分的数值,而忽视评分产生时间对推荐的作用,从而表现出随时间变化的概念漂移问题,结合评分时间信息对推荐的作用,从评分时间角度对推荐算法的相似度计算和评分预测过程进行改进,提出一种结合评分时间特性的协同推荐算法。韩亚楠等[4]考虑到用户兴趣随时间的变化,将基于时间的兴趣度权重函数和偏好度引入到项目相似度计算和推荐过程中,确定项目最近邻集合,从而实现最优推荐。
除了依赖用户对于项目的评分进行相似性度量设计推荐算法之外,相关研究还对用户之间存在的关系进行分析,为目标用户寻找相似用户集合,进而设计合理的推荐方法。用户间关系的获取主要通过两种方式:一种是通过用户间的显式关系。如在社交网络中的好友关系或对其他用户的评价点赞等。国内外学者基于用户间的显式关系设计了相关的推荐方法。Lai等[5]提出了一种基于社交网络环境的推荐方法,通过分析用户间的互动行为、好友关系以及产品流行度,实现个性化推荐。该方法重点在于通过用户评分和商品评论推断用户间的关联关系,结合商品受欢迎程度完成推荐。张继东等[6]以新浪微博为研究对象,利用微博用户间的好友关系衡量信任关系,据此进行分析以提供推荐服务。此外,张继东等[7]还构建了一个基于社区划分和用户相似度的好友信息服务推荐模型,通过用户间的交互级别、专业知识水平以及信任程度划分用户社区,以此计算用户兴趣偏好相似性,从而实现推荐。在上述研究中,用户间的信任关系是通过显式关系的分析建立的,这种信任并非实际社会关系上的信任,而是从目标用户对推荐项目的反馈行为中挖掘出的潜在兴趣关联。这种关联通常是隐性的,目标用户可能并未察觉[8]。
另一种方法是通过用户的隐式关系来设计推荐系统,即通过分析用户的行为数据(如共同购买的商品、共同观看的电影等),推断用户之间可能存在的关系,据此进行相似性度量设计推荐方法。廖宏建等[9]充分利用学习行为日志和评分数据,挖掘学习者之间的隐式信任关系,通过信任传播建立MOOC社区的信任网络,构建动态结合兴趣和隐式信任感知的混合推荐方法。王根生等[10]将用户对资源的学习行为转化为评分,从而缓解评分矩阵稀疏问题,引入用户初始化标签改进用户相似度计算,找出与目标用户兴趣偏好相近的用户集合,以实施推荐。在社交网络环境中,社会化标签不仅可以提供内容的摘要信息,还能反映用户的需求倾向,因此在个性化推荐中表现出更好的效果[8][11]。郭雪梅等[12]以标签为媒介,构建用户和项目的标签特征表示,应用于用户相似性和项目相似性的协同过滤算法,预测用户对项目的偏好值并进行排序,从而生成最终的推荐列表。Shambour等[13]融合标签和时间等因素,通过分析用户使用标签的频率及标注资源的时间信息,构建用户-资源评分矩阵,结合协同过滤算法计算目标用户的最近邻,从而实现知识推荐。
综上,现有研究多通过用户好友关系、用户标签等显性数据结合用户评分分析用户关系。但在仅提供用户评分的情况下,通常采用Pearson相关系数或修正余弦相似性度量用户相似性。因此,本文基于用户评分并结合用户行为,分析用户多元关系,设计个性化推荐方法。
2 融合评分和行为的用户间多元关系构成
2.1 问题引入
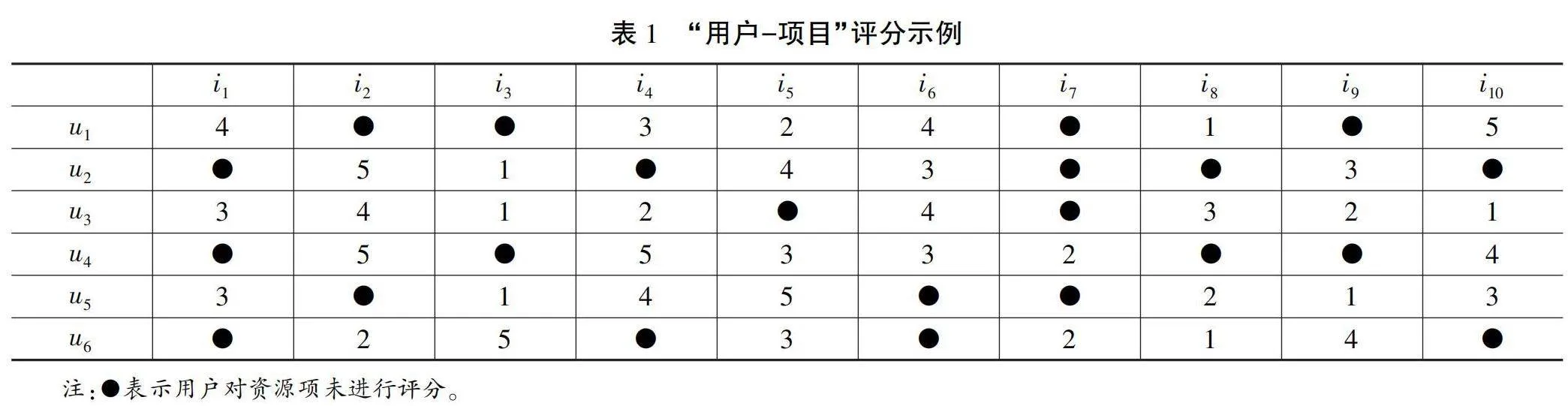
推荐系统中提供了用户对于资源项评分的功能,假定系统中的6个用户对10个资源项的评分,用户评分的取值区间为[1,5]的正整数,如表1所示。
如果该推荐系统仅提供评分功能,而未涉及好友关系、用户评论等扩展功能,那么在实施推荐前,用户相似性的度量只能依赖用户对项目的评分。通过修正的余弦相似性或Pearson相关系数,可以找到与目标用户偏好相似的用户集合。然而,这种方法难以深度挖掘用户的兴趣偏好。因此,本文结合用户对项目的评分与用户行为,共同描述用户的兴趣偏好,进一步利用项目的静态评分挖掘用户之间的潜在关系,如图1所示。
2.2 基于静态评分的用户间可靠性度量
用户的可靠性是用于衡量对用户评分预测准确性的指标。本文对于用户可靠性从用户评分确定性以及基于评分的用户间信任关系这两方面因素相结合进行考虑。
2.2.1 用户评分确定性的度量
用户评分的确定性是衡量用户评分行为可预测性或稳定性的重要指标,基于用户历史评分数据的统计分析得出。在推荐系统中,用户评分数据是反映用户对特定项目喜好或满意度的关键信号。如果用户的评分行为具有较高的确定性,说明其评分模式或习惯较为稳定且具有一定的可预测性;相反,低确定性则表明用户的评分行为较为波动,难以预测。
确定性的概念可以被看作是不确定性的相反。在推荐系统中,用户对于项目赋予的评分具有随机性和不确定性的特点,因此可以借助信息熵进行度量。信息熵是度量信息的不确定性的一种方式。这个概念由Claude E. Shannon在20世纪40年代提出,在信息论和相关领域得到广泛应用。其基本思想是,信息的不确定性越大,其信息熵就越大。信息熵计算公式为:H(X)=-∑nj=1p(xj)×log2p(xj)。
在评分可预测性的情景中,信息熵可以用来衡量用户评分的不确定性。高信息熵意味着用户的评分行为更随机、不可预测,而低信息熵则表示评分行为更有规律、可预测。在推荐系统中项目评分取值为[1,…,5],假定用户u对系统中项目评分向量记为Ru={ru,1,ru,2,…,ru,i,…,ru,n}。由于用户u在评分取值范围内对不同项目赋予不同的评分是相互独立的事件。用户u对项目赋予评分的不确定性度量计算,如公式(1)所示。
UnCeru=-∑r∈RDpu(r)log2(pu(r))(1)
其中,RD表示项目评分的取值范围,假定评分为5分制正整数,即RD={1,2,3,4,5};pu(r)表示评分取值r∈RD在评分向量Ru中发生的概率,计算公式如下所示:
pu(r)=(评分值r在评分向量Ru中出现的次数) /(评分向量Ru中包含元素的数量)
根据信息熵公式的定义,在均匀分布下,信息熵达到最大值。当用户的评分是均匀分布时,即给出每个可能的评分的概率都是相等时,那么每个评分的概率就是1/RD=1/5。此时,用户评分不确定性取得最大值Max(UnCeru)=log2(RD),其中RD为评分取值区间内分值的数量。由于确定性的概念可以被看作是不确定性的相反,因此在得到公式(1)的用户u对项目赋予评分的不确定性度量后,可以得到用户对项目评分的确定性度量方法,即Ceru=1-[UnCeru/log2(RD)]。根据该公式,表1中各用户的评分确定性度量结果如表2所示。
2.2.2 基于静态评分的用户间信任关系
这里的信任关系不同于社会关系中的信任,推荐系统中,由于两个用户间会产生共同评分的项目,假设Ia和Ib分别表示用户a和b评分项目的集合,Ia和Ib分别表示用户a和b评分项目的数量。Ia∩Ib和Ia∩Ib分别表示用户a和b共同评分的项目集合及其对应的项目数量。本文采用基于共同项目的评分计算用户间直接信任关系的方法,该方法根据用户b的项目评分产生用户a对共同评分项目的预测评分pa,i,计算公式为pa,i=i a+(rb,i-b)。其中,i a表示用户a已评分项目中不包括项目i(i∈Ia∩Ib)的评分均值,b表示用户b项目评分的均值,rb,i表示用户b对项目i的实际评分。通过pa,i与ra,i的差值度量用户a和b间的信任关系,差值越小,信任关系程度越高。
在表1的 “用户-项目”评分示例中,以用户u1和u2为例,这两个用户的共同评分项目集合为{i5,i6},用户u2项目评分均值为3.2,进而计算用户u1对于共同评分项目的预测评分。
本文通过预测评分与实际评分的偏差来衡量用户之间的信任关系程度,因此使用均方差分的方法进行计算,如公式(2)所示。
Trusta→b=1-∑i∈Ia∩Ib(Pa(i)-Ra(i))2|Ia∩Ib|×|Ia∩Ib||Ia∪Ib|(2)
其中,为使用户间信任关系度量结果取值范围为[0,1],需要对预测评分和实际评分进行归一化。公式(2)中Pa(i)和Ra(i)分别表示用户a对项目i的实际评分ra,i和预测评分pa,i归一化处理后的结果。同样以上面的示例为例,MAX{ru1}=ru1,i10=5,MIN{ru1}=ru1,i8=1,用户u1及其与用户u2共同评分项目i5、i6的预测评分和实际评分归一化结果,如表3所示。
表3 用户u1与u2信任关系度量结果
VarPu1(i5)Ru1(i5)Pu1(i6)Ru1(i6)
Var-ru1,i8ru1,i10-ru1,i80.80.250.450.75
根据公式(2),可以计算得到Trustu1→u2=0.1786。同理计算Trustu2→u1,根据表1可以得到用户u1项目评分均值为3.8,进而计算用户u2对于共同评分项目的预测评分。
根据公式(2),可以计算得到Trustu2→u1=0.1673。可以发现,由于用户u1和u2各自评分具有差异性,因此Trustu1→u2和Trustu2→u1计算结果并不相同。此外,如果用户a和b之间不存在任何共同评分项目,但他们分别与用户c存在共同评分项目,那么用户a和b之间就存在间接信任关系,可以利用a和b各自与用户c的直接信任关系计算这二者之间的间接信任关系,其计算方法如公式(3)所示。
Trustacb=|Ia∩Ic|×Trusta→c+|Ic∩Ib|×Trustc→b|Ia∩Ic|+|Ic∩Ib|(3)
综上所述,用户a和b之间信任关系的计算方法如公式(4)所示。
Trust*a→b=Trusta→bIa∩Ib≠
TrustacbIa∩Ib=amp;Ia∩Ic≠amp;Ic∩Ib≠(4)
2.2.3 用户间可靠性的计算
综上所述,用户可靠性需要通过将用户间评分的确定性差值和基于静态评分的信任关系相结合进行计算,如公式(5)所示。
CONF(a,b)=Trust*a→b×(1-CerDiff(a,b))(5)
其中,CerDiff(a,b) 表示用户a和b之间评分确定性的差值,CerDiff(a,b)=Cera-Cerb,CerDiff(a,b)∈[0,1]。结合表2和表3的用户评分确定性以及各个用户间信任关系度量结果,根据公式(5)介绍的计算方法,计算用户u1和u2各自的用户间可靠性,即计算CONF(u1,u2)和CONF(u2,u1)。
∵ CerDiff(u1,u2)=|Ceru1-Ceru2|=|0.0303-0.1723|=0.142
∴ CONF(u1,u2)=0.1532CONF(u2,u1)=0.1435
在用户间可靠性度量中,用户a和b的评分确定性差值是衡量两位用户评分行为稳定性差异的关键指标。评分确定性反映了用户评分行为的一致性和可预测性。当两位用户的评分确定性差值较小,说明他们在评分行为上表现出相似的稳定性和一致性;相反,差值较大则表明他们在评分行为上的稳定性和一致性存在显著差异。因此,该差值可用于评估用户间评分行为稳定性方面的相似性。此外,将用户间评分确定性的差异与基于评分的信任关系相结合,可以更全面地判断两位用户间是否具备较高的可靠性。通过将这两项指标的乘积作为权重,可以更准确地反映用户评分的整体可靠性,为推荐系统的用户信任评估提供更精准的依据。
2.3 基于静态评分的用户间一致性
2.3.1 用户间最近邻的一致性
传统的推荐方法中,根据与目标用户相似性度量的结果进行排序,选择Top-N用户作为目标用户的最近邻进行推荐,可能会导致推荐结果的多样性不足。通过设定一个阈值δ,使推荐结果涵盖了一个较大的用户集合,可以提高推荐结果的多样性,满足用户的多元化需求。
根据Jaccard相似性度量方法,即SIMJaccard(a,u)=|Ia∩Iu||Ia∪Iu|。通过逐个计算目标用户a与系统中其他用户的相似性后,并计算平均值以此作为与目标用户a相似性比较的阈值,如公式(6)所示。
δa=1|U|-1×∑u∈USIMJaccard(a,u)
SIMJaccard(a,u)≠0amp;a≠u(6)
用户间最近邻一致性的度量方法可以解释为,用户a和b各自相似性高于阈值δa和δb所形成的最近邻集合的交集中,存在一个用户,该用户分别与a和b相似性度量结果的差值小于阈值ε(本文设定ε≤0.05),满足该条件的用户数量与交集用户数量的比值,计算公式如公式(7)所示。
IDENUser(a,b)=∑USIMa∩USIMbu=11|USIMa∩USIMb|
USIMa={u|SIMJaccard(a,u)gt;δa}amp;
USIMb={u|SIMJaccard(b,u)gt;δb}amp;
|SIMJaccard(a,u)-SIMJaccard(b,u)|≤ε(7)
其中,USIMa和USIMb分别表示相似性度量结果分别高于用户a和b的相似性阈值的用户集合。USIMa∩USIMb表示这个共同相似用户集合中的用户数量。
2.3.2 用户间评分一致性
用户间评分一致性的度量方法可以解释为,用户a和b共同评分项目的集合中,存在一个项目,用户a和b对该项目的评分值相同,满足该条件的项目数量与共同评分项目数量的比值,如公式(8)所示。
IDENInfo(a,b)=∑IRa∩IRbi=11|IRa∩IRb|Ra(i)=Rb(i)(8)
2.3.3 用户间的综合一致性
综合用户间最近邻一致性水平和用户间评分一致性,计算二者的算数平均值,可得用户间的综合一致性,如公式(9)所示。
IDEN(a,b)=12(IDENUser(a,b)+IDENInfo(a,b))(9)
2.4 考虑时间因素的用户评分间调和相似性
2.4.1 考虑时间因素的用户评分
传统的基于用户协同过滤的推荐方法中,用户评分向量通常未考虑时间因素的影响。例如,用户可能对某个项目的评分较高,但随着时间推移,其兴趣偏好发生了变化,对于之前评分较高的项目不再访问。在这种情况下,基于用户静态评分形成的评分向量无法准确描述用户当前的兴趣偏好。为了解决这一问题,本文引入时间因素对用户的项目评分进行调整。相比于较早的评分,用户近期的评分行为具有更高的参考价值。因此,距离当前时间越近的评分应当赋予更大的时间权重,从而更准确地反映用户的实时兴趣偏好,提高推荐系统的准确性和时效性。考虑到时间因素的用户a对项目i的评分记为R*a(i),如公式(10)所示。
R*a(i)=Ra(i)×exp-tnow-tRate(a,i)tnow-tFirstRate(a)(10)
2.4.2 Pearson相关系数
在推荐系统中,Pearson相关系数被用来衡量两个用户的评分向量之间的相关性,其取值范围为[-1,1]。本文中,对于用户a和用户b,基于他们在相同项目上所形成的行为偏好向量,使用Pearson相关系数,可以计算出这两个用户之间的相关性,即
PCCa,b=∑i∈Ia∩IbR*a(i)-R*a×R*b(i)-R*b∑i∈Ia∩IbR*a(i)-R*a2×∑i∈Ia∩IbR*b(i)-R*b2
2.5 欧式距离
对于两个用户a和b的评分向量,使用欧式距离,以测量这两个用户在相同项目上所形成的行为偏好模式之间的距离,即DistEuca,b=∑i∈Ia∩Ib(R*a(i)-R*b(i))2。欧式距离的值范围为[0,+∞)。如果欧式距离为0,意味着两个用户对所有项目的行为偏好完全相同。如果欧式距离很大,表明两个用户的行为偏好模式存在显著差异。
2.6 用户调和相似性
综上所述,对用户a和b在相同项目上所形成的行为偏好向量上计算得到的Pearson相关系数和欧式距离,在取值范围上存在着巨大差异。Pearson相关系数衡量的是两个向量的线性相关性。特别是在[0,1]取值范围内,值越大表示两个用户的行为模式越相似。因此需要将用户a和b的行为偏好向量的欧式距离进行处理,使其取值范围与Pearson相关系数范围相同。标准化欧式距离的计算方法为DistNorma,b=1-11+DistEuca,b。
通过计算Pearson相关系数和标准化欧氏距离的调和平均数,可以同时考虑到评分的数值相似性和评分模式的相似性,获得一个更全面的相似性度量,计算如公式(11)所示。
SIM(a,b)=PCCa,b PCCa,b≠0amp;DistNorma,b=0
DistNorma,b PCCa,b=0amp;DistNorma,b≠0
0 PCCa,b=0amp;DistNorma,b=0
2×PCCa,b×DistNorma,bPCCa,b+DistNorma,b PCCa,b≠0amp;DistNorma,b≠0(11)
Pearson相关系数用于衡量两个向量之间的线性相关性,而欧式距离反映的是向量在多维空间中的实际距离。本文中通过计算两者的调和平均数,兼顾用户行为偏好值的差距(由欧式距离表征)和行为偏好值的趋势(由Pearson相关系数表征),从而使得相似性度量结果更加全面和准确。
3 基于用户多维度关联关系分析的个性化推荐方法
3.1 用户多维度关联关系
根据前述分析,可以通过静态评分计算用户间的置信度和一致性,结合时间因素计算用户评分中的行为偏好调和相似性。在此基础上,综合以上3方面因素深入分析用户间的关联关系。需要注意的是,用户间的信任关系既包括直接关联关系,也包括间接关联关系。因此,在构建用户关联关系模型时,应综合考虑这2种关联方式,以更准确地反映用户之间的潜在关系。
3.1.1 用户直接关联关系
当用户间存在共同项目或能够实现这两个用户间的调和相似性、置信度或一致性至少一项指标,则可以根据公式(12)计算这两个用户之间的直接关联关系。
D(a,b)=33×SIM(a,b)×CONF(a,b)×IDEN(a,b)SIM(a,b)+CONF(a,b)+IDEN(a,b)
SIM(a,b)+CONF(a,b)+IDEN(a,b)≠0
2×CONF(a,b)×IDEN(a,b)CONF(a,b)+IDEN(a,b)CONF(a,b)×IDEN(a,b)≠0amp;SIM(a,b)=0
2×SIM(a,b)×IDEN(a,b)SIM(a,b)+IDEN(a,b)SIM(a,b)×IDEN(a,b)≠0amp;CONF(a,b)=0
2×SIM(a,b)×CONF(a,b)SIM(a,b)+CONF(a,b)SIM(a,b)×CONF(a,b)≠0amp;IDEN(a,b)=0
0 CONF(a,b)=0amp;SIM(a,b)=0amp;IDEN(a,b)=0(12)
直接关联关系D的取值范围为[0,1],针对目标用户a,根据公式(12)分别计算其与系统中其他用户的直接关联关系并求得均值,以此作为目标用户a的直接关联关系的阈值,记为γa=1|U|-1∑u∈UD(a,u),其中,a≠uamp;D (a,u)≠0。
3.1.2 用户间接关联关系
用户a和b之间的关联关系不仅要计算他们之间的直接关联关系,还需要考虑通过中间用户所产生的间接关联关系,也称为传导关联关系,即存在中间用户u,通过分别计算D (a,u)和D (u,b)后,根据公式(13)计算a和b之间的间接关联关系。
P(a,b)=1|U′|×∑U′u=12×D(a,u)×D(u,b)D(a,u)+D(u,b)
D(a,u)gt;γaamp;D(u,b)gt;γu(13)
其中,集合U′表示用户a和b之间中间用户的集合,D (a,u)和D (u,b)分别需要满足高于直接关联关系阈值γa和γu。
3.1.3 用户关联关系模型
根据前面得到的用户a和b之间的直接/间接关联关系,按照公式(14)可以得到2个用户之间的关联关系模型。
针对目标用户a,根据公式(14)分别计算其与系统中其他用户的关联关系并求得均值,以此作为目标用户a的关联关系的阈值,记为θa。EQ θa=1|U|-1∑b∈UREL(b,u),其中a≠bamp; REL (a,b)≠0。
3.2 评分预测方法
根据前文所阐述的用户间关联关系计算方法,根据公式(15)可以计算目标用户a对于未访问项目的行为偏好预测值。其中,根据目标用户a关联关系阈值θa,系统中其他用户与目标用户a的关联关系高于θa所形成的最近邻集合记为UREL a={uREL(a,u)gt;θa }。
4 实验分析
4.1 数据准备
本文依托于研究课题建立的“信息素养课程教学平台”,该平台保存了用户信息、课程资源信息以及用户对于课程资源的评分信息。保存这些数据的数据库关系模型,如图2所示。
4.2 结果比对
为了验证实验效果,本文在对比实验中采用均方根误差(RMSE)和平均绝对误差(MAE)来验证推荐方法的推荐质量,这2项评价指标如下:
其中,U表示用户集合,IPRED u表示用户u未进行评分的项目集合,Ru(i)表示用户u对项目i的实际评分,Pu(i)表示用户u对项目i的预测评分。
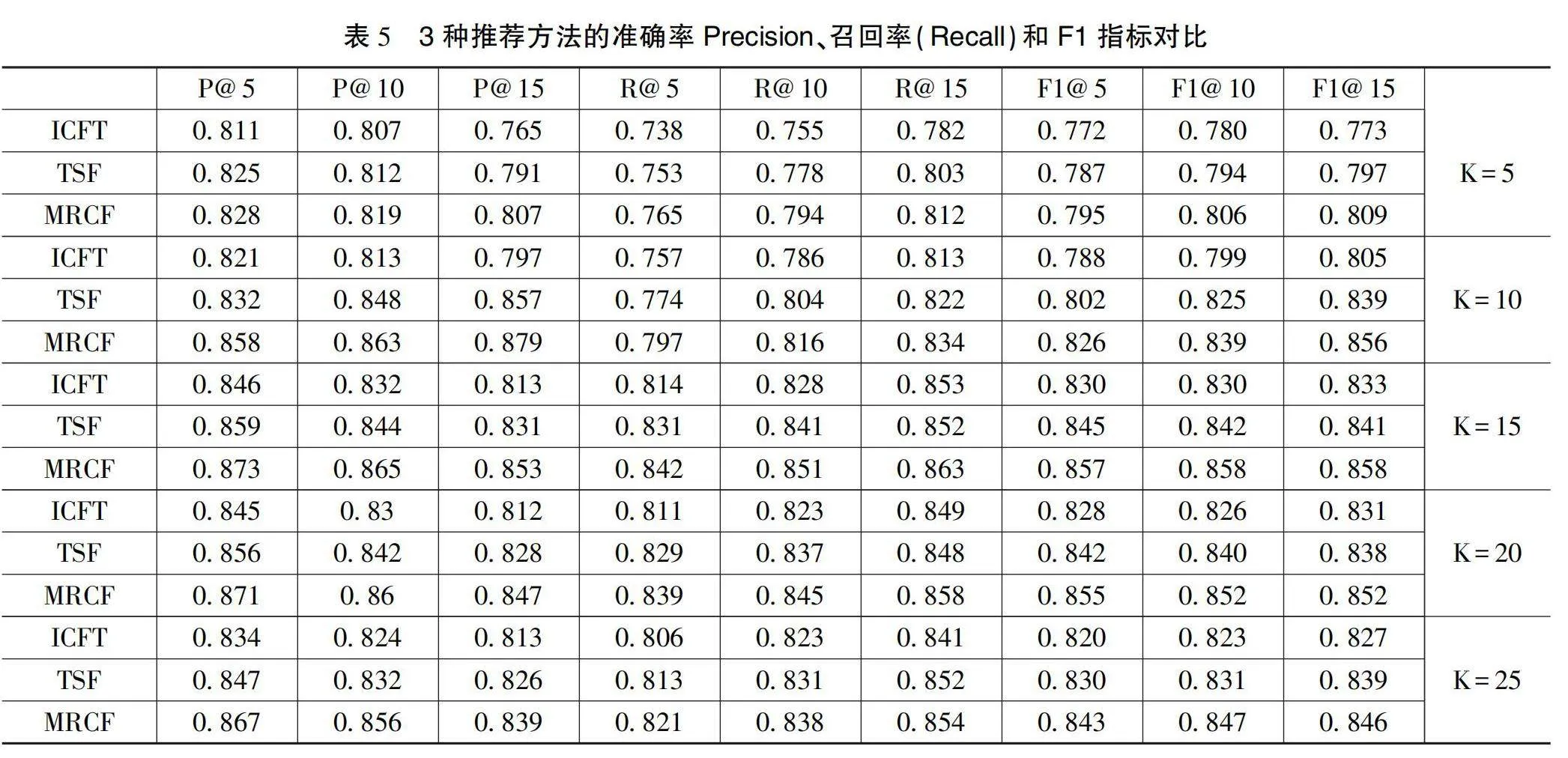
本文采用基于用户评分结合评分时间特性的协同推荐算法[3](记为“ICFT”),基于用户评分分析用户间信任关系的推荐方法(记为“TSF”)与本文设计的推荐方法(记为“MRCF”)在实验数据上进行对比,将目标用户最近邻集合的数量设置为K={5,10,15,20,25},实验结果如表4所示。
通过实验结果可知,随着目标用户最近邻用户数量的增多,3种方法的RMSE和MAE值均降低,表明推荐精度均有所提高。本文设计的方法在推荐效果上优于其他2种方法且ICFT方法推荐精度最低。
此外,在对比实验中本文还采用准确率(Precision)、召回率(Recall)和F1作为评价标准,比较3种推荐方法在目标用户最近邻集合的数量设置为K={5,10,15,20,25}这5种条件下和每个用户推荐项目数量N为{5,10,15}的3种情况下进行实验,实验结果如表5所示。
根据表5,在目标用户最近邻集合的数量设置为K={5,10,15,20,25}这5种条件下,本文提出的推荐方法在准确率Precision、召回率(Recall)和F1这3项指标上均优于其他2种对比方法。其中,ICFT方法推荐效果最差,其原因在于该方法仅从评分时间角度对推荐算法的相似度计算和评分预测过程进行改进,没有从用户静态评分中分析和挖掘用户间的信任关系。而TSF方法虽然通过用户评分分析用户间的信任关系,但其没有考虑时间因素对用户兴趣偏好的影响。
5 结语
传统的协同过滤推荐算法单纯依赖用户对项目的评分数据进行计算,未充分考虑其他关键因素,如用户之间的信任关系,这往往导致推荐质量较低。为了解决这一问题,本文以用户对项目的评分为基础,分析用户间评分的一致性和信任关系,结合用户行为进行综合分析。同时,引入时间因素对用户项目评分的影响,充分考虑时间对用户兴趣偏好的作用,构建用户间的多元关系模型。在此基础上,为目标用户找到更为相似的最近邻集合,从而提供精准的信息资源推荐服务。最后,将本文提出的方法应用于实际信息服务平台中,通过对实验数据的分析,比较本文方法与其他推荐方法的效果。实验结果表明,该方法能够提供更优质的推荐效果,有效满足用户的信息需求。
参考文献
[1]魏玲,郭新悦.融合用户画像与协同过滤的知识付费平台个性化推荐模型[J].情报理论与实践,2021(3):188-193.
[2]朱帅.基于微博引用的个性化推荐[D].北京:北京邮电大学,2013.
[3]任磊.一种结合评分时间特性的协同推荐算法[J].计算机应用与软件,2015(5):112-115.
[4]韩亚楠,曹菡,刘亮亮.基于评分矩阵填充与用户兴趣的协同过滤推荐算法[J].计算机工程,2016(1):36-40.
[5]LAI C H ,LEE S J ,HUANG H L. A Social Recommendation Method Based on the Integration of Social Relationship and Product Popularity[J].International Journal of Human-Computer Studies,2019(121):42-57.
[6]张继东,段小萌.基于移动社交平台的用户信任度分析研究[J].现代情报,2017(9):93-96,102.
[7]张继东,蔡雪.基于社区划分和用户相似度的好友信息服务推荐研究[J].情报理论与实践,2019(4):151-157,165.
[8]胡吉明,胡昌平,邓胜利.社会网络环境下的信息推荐研究述评[J].情报资料工作,2013(2):35-39.
[9]廖宏建,谢亮,曲哲.一种基于隐式信任感知的MOOCs推荐方法[J].情报理论与实践,2021(2):128-135,95.
[10]王根生,袁红林,黄学坚,等.基于改进型协同过滤的网络学习资源推荐算法[J].小型微型计算机系统,2021(5):940-945.
[11]WU P ,ZHANG Z K . Enhancing personalized recommendations on weighted social tagging networks[J].Physics Procedia,2010(3):1877-1885.
[12]郭雪梅.基于社会化标签的用户标注行为和时间因素的个性化推荐方法研究[J].情报科学,2020(2):68-74.
[13]SHAMBOUR Q,LU J.A trust-semantic fusion-based recommendation approach for e-business applications[J].Decision Support Systems,2012(1):768-780.
(编辑 姚 鑫)
Research on personalized recommendation based on multi-relationship analysis among users ratings
ZHANG Jun
(Laboratory and Asset Management Division, Tianjin Medical University, Tianjin 300070)
Abstract:With the explosion of information, personalized recommendation technology has become key to improving information retrieval efficiency and user experience. This article addresses the issue of low recommendation quality caused by traditional collaborative filtering methods that rely solely on users' static ratings. It proposes a personalized recommendation method based on multi-dimensional analysis of user ratings. This method comprehensively analyzes user rating consistency, trust relationships, and user behavior, introduces temporal factors to reflect changes in user interests, and establishes a multi-dimensional relationship model among users. Experimental results show that compared to other recommendation methods, the approach presented in this article can provide more accurate recommendation services in practical applications, effectively meeting users' information needs and achieving a significant improvement in recommendation quality.
Key words:personalized recommendation; user ratings; user multi-relationship; quantifying user behavior
猜你喜欢
软件(2016年4期)2017-01-20 09:44:28
东方教育(2016年8期)2017-01-17 19:47:27
软件导刊(2016年11期)2016-12-22 21:40:40
电脑知识与技术(2016年27期)2016-12-15 19:46:14
电脑知识与技术(2016年27期)2016-12-15 19:41:16
商(2016年34期)2016-11-24 16:28:51
中国科技博览(2016年21期)2016-11-14 18:27:30
电脑知识与技术(2016年22期)2016-10-31 20:12:44
中国科技博览(2016年18期)2016-10-19 06:43:40
商(2016年16期)2016-06-12 09:07:08
