
中国学术期刊论文元数据的开放和再利用
2025-01-20 00:00:00朱江罗煜周海晨
四川图书馆学报 2025年1期
关键词:学术期刊


摘 要:随着中国学术期刊繁荣发展以及开放获取出版的推广,中国学术期刊论文元数据已成为重要的资源、资产甚至资本。文章阐述了元数据的概念及相关理论,分析了中国学术期刊论文元数据和全文的开放现状,结合初步完成的开放中国学术期刊论文数据库项目,讨论了中文期刊论文元数据的开放、期刊官网全文的链接方法以及开放中国学术期刊论文元数据的再利用方向。
关键词:学术期刊;期刊论文数据库;开放获取出版;元数据开放;元数据再利用
中图分类号:G255.2 文献标识码:A
文章编号:1003-7136(2025)01-0016-10
Open and Reuse of Metadata of Chinese Academic Journal Articles
ZHU Jiang,LUO Yu,ZHOU Haicheng
Abstract:With the prosperous development of Chinese academic journals and the promotion of open access publishing,the metadata of Chinese academic journal articles has become an important resource,asset,and even capital.This paper expounds the concept and associated theories of metadata,analyzes the opening status of metadata and full text of Chinese academic journal articles,and discusses the opening of metadata of Chinese academic journal articles,the linking methods for accessing full-text content from journal websites and the reusing directions for metadata of Chinese academic journal articles in combination with the initially completed open Chinese academic journal article database project.
Keywords:academic journal;journal article database;open access publishing;metadata opening;reuse of metadata
0 引言
习近平总书记指出:“我国基础研究存在题目从国外学术期刊上找……取得成果后再花钱到国外期刊和平台上发表的‘两头在外’问题。……鼓励重大基础研究成果率先在我国期刊、平台上发表和开发利用。”[1] 这反映了我国科研成果存在“两头在外”的问题,即科研成果在国外期刊上发表,阅读这些成果时又需要从国外购买[2]。可以认为,我国出版的学术期刊与论文是解决“两头在外”的关键抓手,也是实现高水平科技自立自强的重要基础。
从学术论文来看,中国科技人员的外文学术论文主要发表在国外各类学术期刊上,中文学术论文主要发表在国内各类学术期刊上,且中文学术期刊论文年度发文量已达到200万篇。中国学术期刊论文体量庞大,然而其数字出版或者更进一步的开放获取(OA)出版所带来的相关元数据的开放和再利用程度并不高。从学术期刊来看,中国学术期刊的OA出版普遍采取青铜OA出版模式,并呈多元化、快速发展态势。按照通行的OA标准,中国学术期刊的OA出版模式不尽规范,导致被开放获取期刊目录(DOAJ)收录的中国出版的期刊数量严重偏低。实际上,中国学术期刊发表的论文,绝大多数可在期刊官网上免费获取全文。
随着中国学术期刊影响力和论文数量的提升,公众对中国学术期刊论文元数据的开放和再利用需求显著增加。如能全面掌握中文期刊论文元数据,并与相对开放的外文期刊论文元数据、专利文献元数据整合,即可利用多种文献计量方法和知识挖掘技术对我国的学术产出数量、研究热点和前沿、空白点、技术方案和研究趋势等,作出比较客观的计量、分析、比较和预测。期刊论文全文的开放有利于学术成果的传播、交流,以及更加深入、全面的知识挖掘,从而进一步推动科学技术、文献计量、知识挖掘,甚至高可信度人工智能技术的发展。但当前中国学术期刊论文这一片“金矿”还有待进一步开发,其价值潜力有待进一步释放。中国学术期刊论文及元数据的开放只是第一步,由开放到利用才是其价值的进一步实现。
1 中国学术期刊论文元数据和全文的开放现状
1.1 概念阐述
期刊论文元数据是对期刊论文的题名、作者、作者机构、研究内容和主题等进行描述的文字和代码,由作者、图情工作者、期刊编辑部等通过人工或机器加工形成,不包括论文的实验数据、观测数据、支撑数据或其它关联数据(这类数据通常要求作者自行提交到特定的数据存储库)。元数据与期刊论文全文关系紧密,所以需对期刊论文元数据及全文一并予以探讨。期刊论文元数据和全文一般可通过期刊官网或电子期刊集成出版平台获取,国内一些学术机构自主开发的学术期刊论文数据库亦可提供这类服务。
从主体来看,论文元数据在不同主体间流动加工,其一般顺序为:作者(论文形式)→出版者(期刊形式)→集成商(平台形式)→图书馆(馆藏形式)。对元数据的生产影响最为突出的是作者:①因资助者需要,提供基金元数据;②因出版者需要,提供关键词、分类、摘要等元数据;③因同行的需要,提供参考文献元数据;④因机构的需要,提供机构元数据。出版者则主要添加期刊型元数据(如来源期刊、卷期),出版者掌握的元数据最容易开放,也最为准确。平台进一步提供评价计量型元数据(如被引频次)。图书馆则更加关注访问量、版本、获取方式等元数据。
元数据的开放和论文的开放关系密切,但又有所不同。元数据的开放除了受到经济因素的限制外,最大的问题是开放科学背景下的信息安全问题,这是任何元数据在开放和利用过程中无法回避的问题。①元数据的开放将增加网络攻击、数据篡改的风险。元数据脱离文本的相对独立性可能导致其在传递过程中出现对论文描述的失真,从而影响元数据的真实性、完整性和可用性。②元数据的跨国流动为分析国家的科研态势提供了情报信息,政治关系也将影响到元数据的跨国开放。③通过数据汇聚,从元数据能够推导出的信息越来越多,元数据和信息内容之间的界限日益模糊,越全面的元数据越可能泄露关键信息。如果论文全文内容是封闭的,其元数据的开放也将更加困难,并且可能涉及知识产权等问题。④随着元数据种类的丰富、拓展,涉及个人隐私的敏感信息(如联系方式、地理位置、选题方向)可能被泄露或不当使用。
1.2 期刊官网
中国五千余种科技期刊的主管、主办和出版单位极其分散,其中出版单位共四千个左右[3]。虽然大约80%~90%的科技期刊拥有自己的官网,但这些官网普遍不提供论文元数据和全文的批量下载,一般仅提供论文的检索、卷期目次浏览、引用信息导出和全文阅读、下载服务。以《图书情报工作》为例,期刊官网提供了论文题名、作者、作者机构、摘要、关键词、学科分类号、基金等检索入口,可查看基本的题录信息、收稿日期、出版日期、参考文献等信息,有OA标识的论文可即时获取PDF格式的全文。
虽然绝大多数期刊官网上的元数据较为齐备,并且较大概率提供全文,但期刊官网极其分散,导致读者要获取某一学科领域多个期刊较大数量的元数据和全文存在很大的困难。
1.3 电子期刊集成出版平台
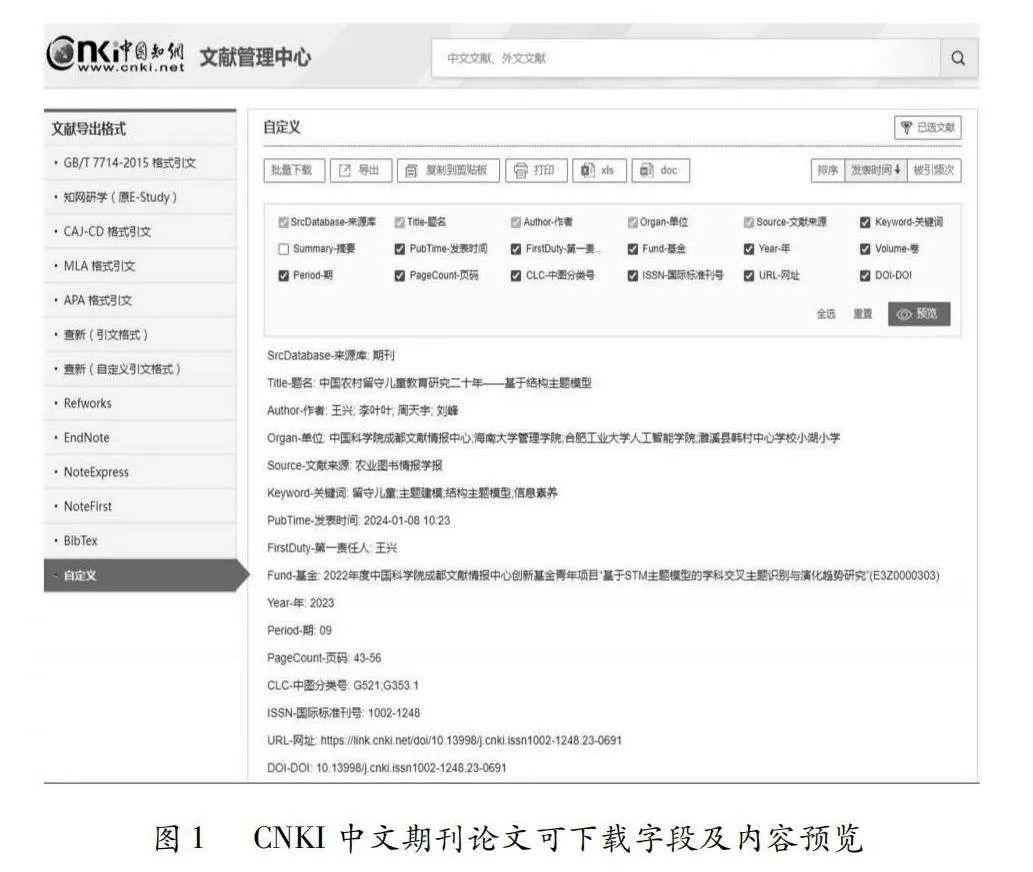
中国电子期刊出版高度集中在中国知网(CNKI)、万方数据知识服务平台(以下简称:万方)、维普资讯(以下简称:维普)三大商业电子期刊集成出版平台,其中CNKI的期刊种数最多,在中国具有最强的影响力和最大的用户群体。用户在这三大平台上能很方便地检索到自己需要的文献,有访问权的用户还可下载多种格式的全文。这三大平台收录的期刊数量、提供的平台功能虽然有差异,但有一个共同点就是期刊论文元数据高度封闭,用户仅能下载少量几个元数据字段。以CNKI为例,可以下载的字段只有18个(见图1),且元数据下载条数有严格的限制。Web of Science 、工程索引等国外商业数据库对元数据下载虽有不合理的限制,但可下载字段数量和元数据条数都比CNKI宽松。
1.4 中国学术机构建设的学术期刊论文数据库
三大商业电子期刊集成出版平台的电子期刊论文元数据的高度封闭,导致基于中国学术期刊论文元数据的学术评价、知识挖掘等工作存在较大的困难。
跟绝大多数国家类似,中国也非常强调学术机构和学者的学术产出评价,但受中国学术期刊论文元数据难于获取和中国学术期刊学术影响力较低等因素的影响,现阶段的学术评价更侧重于外文学术期刊(特别是Web of Science来源期刊)论文。
随着中国政府越来越鼓励学者将高水平学术论文发表在国内期刊上,中国学术期刊的论文质量和影响力开始显著提升。根据2024年6月发布的《期刊引用报告》,20种中国出版的学术期刊已在21个学科中排名全球第一[4]。学术评价如果继续忽视中国学术期刊论文,其评价结果的偏差势必会越来越大。
正是由于中国学术期刊论文数据在学术评价、知识挖掘等方面有着重要的作用,中国的学术机构正在大力建设中国的学术期刊论文数据库,并积极推动中国学术期刊论文元数据的开放和再利用。
1.4.1 国家科技图书文献中心(NSTL)
NSTL是国家级的科技文献服务机构联盟,由9家核心机构组成,外文科技类期刊是NSTL文献资源保障服务的主体,面向全国开通OA学术期刊14,000余种[5]。读者利用NSTL检索服务平台可对中外文期刊论文进行检索(包括人工智能检索)、导出论文元数据,或申请基于公益服务价格的有偿文献传递服务。
1.4.2 PubScholar公益学术平台
PubScholar公益学术平台是中国科学院文献情报中心2023年推出的公益性学术文献服务平台,收录国内外期刊、专利、科学数据等多种类型的文献信息,提供检索、数据导出、全文链接等服务,其中国期刊的全文链接主要指向期刊官网和维普、中国科学引文数据库(CSCD)、中国科学院机构知识库网格等资源合作方,较好地满足了读者检索并获取全文的需求。平台可检索的科技论文元数据约9639万条,可免费获取的科技论文全文约2338万篇[6],期刊论文中中文占比约74%,中文期刊论文中可获取全文占比约1%,其中大部分为中国科学院主管期刊,非中国科学院主管的期刊,如武汉大学主办的《图书情报知识》,其官网可以提供即时的全文下载功能,但PubScholar公益学术平台仅给出指向维普的原文链接。
1.4.3 中国科学引文数据库(CSCD)
CSCD是我国第一个引文数据库,已实现与Web of Science的跨库检索,是该平台上第一个非英文数据库。2023—2024年度CSCD收录来源期刊1341种,其中中国出版的中文期刊1024种。数据库已累积600多万条论文记录、1亿多条引文记录[7],并提供数据链接机制(即CSCD-LINK服务),链接对象包括出版者、图书馆、知识库渠道,支持用户获取全文(仅部分论文)。
1.4.4 中文社会科学引文索引(CSSCI)
与CSCD类似,CSSCI针对的是中文社会科学领域的论文收录和被引用情况,可检索到来源文献200余万篇,引文文献1000余万篇[8]。同样提供对来源文献和被引文献的简单和高级检索功能,但数据库的访问及数据获取需要购买使用权限。
1.4.5 存在的不足
中国学术机构建设的各类学术期刊论文数据库,特别是公益性的学术期刊论文数据库,对中国学术期刊论文元数据的开放和再利用起到了积极的推动作用,但受知识产权和数据安全法规的限制,这类数据库与三大商业电子期刊集成出版平台相比还存在明显不足。
(1)元数据总量不足。与三大商业电子期刊集成出版平台,特别是与CNKI相比,NSTL和PubScholar公益学术平台的元数据量都略显不足,CSCD和CSSCI则分别是自然科学和社会科学领域的引文数据库,且有较高的入选门槛,仅收录较高质量的学术期刊。
(2)主要提供检索服务,暂时不能提供大批量的元数据下载服务,现有的元数据导出功能较弱。NSTL的元数据导出格式与CNKI类似,以各种参考文献格式为主,但字段数量明显少于CNKI平台;PubScholar公益学术平台仅可导出10余个字段,且可导出的记录总数也非常有限。
(3)全文开放性不足。PubScholar公益学术平台部分记录提供多种形式的全文链接,NSTL只提供全文传递服务链接,且极少数可检索到的OA全文也需要登录才能跳转。
2 开放中国学术期刊论文数据库项目的建设
2.1 建设理论
2.1.1 元数据与图书馆
纸本期刊时代,元数据是图书馆的强项。但电子期刊时代,出版者独占元数据,集成商抢占元数据,图书馆、读者要获取元数据存在一定困难。面对这种情况,图书馆应当集成元数据,并为读者提供相关服务。一方面,目前的元数据服务并没有超越简单搜索和浏览,图书馆需要提供更好的数字图书馆服务,使读者能够发现和探索各种文献中埋藏的内容。另一方面,尽管图书馆在过去收集了大量元数据,但这些数据较少用于学术研究。相反,数据提供商如Web of Science、Scopus、Dimensions、Microsoft Academic Graph、CrossRef和OpenCitations,通常是学术研究的元数据来源[9]。
2.1.2 元数据与治理社区
国际层面的元数据治理已经孕育并发展出了相应的社区。从社区原则来看,开放获取知识库联盟和学术出版与学术资源联盟制定的七项良好实践原则之一,即内容和元数据需要依据开放标准以机器可读格式即时、公开和免费提供[10]。从社区实践来看,CrossRef是最大的数字对象唯一标识符(DOI)注册机构,主要工作是通过开放文献的元数据和DOI来链接全球学术文献。CrossRef为许多下游用户提供元数据,例如Dimensions、The Lens和SpringerLink[11],进而影响到计量指标、搜索引擎、文献管理、科研产出分析等应用。除此之外,OpenAlex、Unpaywall、DOAJ等社区从不同方面集成元数据,并由此制定相应的元数据标准。我国对开放元数据的重视程度相对不足,尚未建立持续有效的元数据获取途径及利用机制,更未形成元数据社区的协同建设体系。大量零散的出版者缺乏统一的元数据标准,在数据交换共享时存在障碍。
2.1.3 元数据与语种
目前,英语是元数据描述和搜索界面最常用的语言,开放元数据也基本是英文的。部分中文期刊实际上早已开放了元数据,但尚未得到公众的关注与利用,使得开放中文元数据的可见度不高,更不用说利用中文元数据提供便捷的知识服务。语种元数据也是论文元数据的重要组成部分,多语言元数据能够促进跨系统元数据的融合。比如中文元数据的引入可以缓解中文作者在英文数据库中的重名问题,实现作者和论文的精准匹配。
2.1.4 元数据与开放获取
OA对象包括了科学出版物和元数据,开放元数据是OA运动的重要成果。OA运动促进了论文元数据开放性的提升。比如,开放引文元数据得益于开放引文倡议(I4OC),开放摘要元数据得益于开放摘要倡议(I4OA)。最近,有学者提出开放编辑者倡议(I4OE)[12]。这些倡议推动了国际期刊开放特定的元数据,从而营造了公平的开放科学环境。OA运动也带来了新的元数据,主要包括标识符型元数据和OA状态型元数据:①回顾国际标识符的历史,从论文客体DOI到论文写作主体ORCID,再拓展到主体所属的研究机构ROR,这些标识符元数据都是完全开放的(属于CC0数据,提供开放API)、可以相互关联的,从而搭建便于分析、利用的数据生态,促进科研生态的建设、评价。同时,这些标识符元数据来源于出版者的主动提交,这种社区合作的模式有利于形成开放、共享的期刊生态。但是在我国,论文及参考文献著录DOI的普及率和利用率并不高,更不用说ORCID和ROR。各出版者之间也较为缺乏元数据合作共享渠道。②OA状态包含了颜色、许可证、版本等方面。国际主流平台标注的颜色主要是金色、青铜、绿色,许可证主要是知识共享(CC)协议和出版者自拟型协议,版本主要是已出版、已接受、已提交。也有学者指出如果更多的出版者以机器可读的格式报告文章级别的OA出版成本信息,将增加学术出版的透明度[13]。但是我国出版者或集成商自主标识的OA元数据是相对缺失、模糊的,可见度很低。
2.2 建设实践
中国科学院文献情报系统长期从事开放资源服务系统的建设,2009年在国内率先启动“重要会议开放资源采集与服务系统”的建设。之后,开放资源的类型逐步扩展到期刊论文、图书、科技报告、教育资源等,并建立了OAinONE开放资源集成服务系统(以下简称:OAinONE系统)。
OAinONE系统在对开放资源发现、遴选和评价的基础上,采集并集成开放期刊论文、开放会议论文、开放课件、开放科技报告等12类[14]优质开放科技资源。同时,推出领域开放知识资源服务定制工具(OAtoYOU)、开放资源评价评估体系(OAEvalua-tion)等服务。OAinONE系统还支持OAI-PMH和WEB Service,支持第三方收割本平台开放资源元数据,并在允许范围内支持收割全文[15]。
令人遗憾的是,由于中国学术期刊论文元数据的封闭和分散,导致OAinONE系统一直未能收录中国学术期刊中的OA论文,资源类型存在一定的缺失。
2.3 开放中国学术期刊论文数据库项目的建设
开放中国学术期刊论文数据库项目将能解决我国OA期刊论文的精准检索、有效发现和定位获取问题,打破期刊网站的信息孤岛,为用户提供一站式的集成服务和市场替代途径,为OA生态提供基础设施支持,促进OA期刊论文的传播,进一步提升中国学术期刊及其论文的可见度。
具体来看,开放中国学术期刊论文数据库项目的建设目标是收录尽可能全面的、中国出版的学术期刊论文元数据,并尽可能提供全文连接URL,这是该数据库的亮点之一。用户在该数据库检索到相关论文后,拥有CNKI平台访问权的用户可直接链接到CNKI平台下载全文,没有CNKI平台访问权的用户可跳转到期刊官网查看更加详细的题录、文摘信息,如该期刊采用金色OA、混合OA或青铜OA模式出版,用户则可在其上获取全文。
2.3.1 论文DOI号的解析和跳转
DOI能够进行跨出版者、跨系统、跨语言的资源链接,已经成为论文的关键元数据。据国际DOI基金会统计,中文DOI注册数量已居全球第二位[16]。开放中国学术期刊论文数据库项目收录的期刊论文DOI号是用户实现全文链接跳转的关键。由于在中国有CNKI、万方两家机构负责DOI的登记和管理,导致部分期刊论文可能拥有2个不同的DOI号,可分别解析跳转到期刊官网、CNKI和万方平台。下面以发表在《海洋开发与管理》的论文《基于CiteSpace的国内外海洋空间规划研究发展态势分析》为例进行
说明,CNKI为该论文注册的DOI号为“10.20016/j.cnki.hykfygl.2022.01.016”,直接解析该DOI号,可得到如图2的结果,除该论文的基本信息外,还包括3个URL。第一个URL直接跳转到期刊官网该论文的详细信息页,点击“下载PDF全文”按钮,即可阅览、保存该论文的PDF全文;第二个URL可直接跳转到CNKI平台该论文的详细信息页,有CNKI访问权的用户可选择多种格式的全文进行阅览、保存;第三个URL可能是CNKI平台的境外链接,国内用户暂时无法利用。
万方平台为该论文注册的DOI号为“10.3969/j.issn.1005-9857.2022.01.002”,直接解析该DOI号,可跳转到万方平台该论文的详细信息页,有万方平台访问权的用户可在线阅读或下载PDF全文。
从上例还可以看出,该篇论文的全文在期刊官网上可以免费下载,这就是中国目前大多数学术期刊采用的青铜OA出版模式;但在CNKI、万方、维普平台上都需要付费下载。
金色OA论文也面临着大同小异的困境。《中国科学数据(中英文网络版)》作为中国唯一面向多学科领域科学数据出版的OA期刊,有明确的OA声明、文章处理费标准和作者保留版权的声明,读者在其官网上可免费下载全文,且论文有OA及CC协议标识;但目前在CNKI和万方平台上还需付费下载,论文无OA标识;在维普平台上可免费下载,论文有OA标识,用户需注册才可获得全文。
实际上,CNKI也关注到了OA出版这一发展趋势,推出了开放获取资源平台(CNKI Open Resource),给论文增加了OA字段及标识。然而该平台仅收录中国出版的英文期刊,其目标是促进中国学者向国内的英文期刊投稿,并方便全球读者便捷获取中国创新成果,并没有将中国出版的大批量中文期刊纳入其中。与此同时,维普也推出了CBOA(communication based on open access)平台,整合了3000余种中国出版的中文OA期刊,并对其刊载的论文赋予OA标识、提供免费下载。通过维普的期刊导航可以发现其收录的中文OA期刊,一方面,在有些期刊官网上能够即时下载所有论文的PDF全文,但期刊官网却没有相应的OA标识;另一方面,有些期刊官网对论文赋予了OA标识,但在维普中却没有该标识,如《中国公路学报》,CBOA平台虽然收录了该期刊,但论文收录时间存在滞后性(于2024年7月11日检索该期刊,期刊文章列表中最新收录的论文出版时间为2023年11月)。这反映了识别论文OA状态时可能存在不一致、不准确以及时滞等问题,需要为读者提供即时可直达资源的链接与论文级的OA标识。
开放中国学术期刊论文数据库项目的建设目标之一就是为读者提供更多的全文链接,特别是指向期刊官网的免费全文链接并准确标注论文的OA属性。与元数据相结合的全文链接对于训练和评估从学术论文全文中提取各种信息的工具非常有用,这包括提取论文的元数据和参考文献,以及从基金资助或致谢中提取资助者信息等。
2.3.2 期刊官网URL、论文URL字段的生成
期刊官网是获取论文元数据的源点,能够提供比商业期刊数据库更为即时、开放、可靠的数据资源,但从其获取论文元数据和全文建设数据库的难点在于期刊官网的分散性和不规则性。
开放中国学术期刊论文数据库项目中的官网URL、论文URL两个字段是指向期刊官网免费全文链接的关键字段。通过论文DOI号解析,可以获取该篇论文在CNKI、万方平台上的全文链接,而期刊官网上的全文链接却不能100%获取,往往需要自行加工生成。
虽然80%~90%的期刊都有自己的官网,但只有部分期刊官网是独立建设的,如《图书情报工作》的官网是https://www.lis.ac.cn/CN/,另有很大一部分期刊的官网都是依托期刊投审稿系统服务商建设的。
期刊官网URL比较容易获取,论文URL则需要根据一定规则进行拼接并检测其有效性。论文URL拼接规则如下,其中少许不规则的论文URL需人工处理并总结其规律。
(1)期刊官网URL+论文DOI号,如《图书情报
工作》:https://www.lis.ac.cn/CN/10.13266/j.issn.0252-3116.2024.01.001。
(2)期刊官网URL+论文出版年代、卷、期、起始页,如《情报学报》:https://qbxb.istic.ac.cn/CN/Y2023/V42/I11/1265。
(3)期刊官网URL+流水号。
(4)不规则。
2.3.3 开放中国学术期刊论文数据库项目第二阶段建设思路
开放中国学术期刊论文数据库项目目前已基本完成第一期的开发和建设,初步实现了中国学术期刊论文元数据的开放,第二期项目将围绕期刊全文的开放开展建设工作,具体流程如下。
(1)标注期刊的OA出版模式、起止年代和变化情况。
(2)利用论文DOI号逐一检查论文的OA属性,主要判断依据是该论文是否可免费下载+所在期刊的OA模式。如某论文在期刊官网上可免费下载,且发表时期刊的OA模式为青铜OA模式,则该论文的OA属性为“Free”;若发表时期刊的OA模式为混合OA、金色OA或钻石OA模式,则该论文的OA属性为“金色OA(含钻石OA)”。同时将官网上该论文的URL写入开放中国学术期刊论文数据库项目Paper_URL字段,全文PDF的URL写入PDF_URL字段。
(3)利用开放接口实现与中国主要机构仓储库集成系统的链接,通过题名+作者+作者机构的比对,将机构仓储库中绿色OA论文的URL写入开放中国学术论文数据库项目的Green_OA_URL字段。这项工作更加复杂,工作量也更大。
3 开放的中国学术期刊论文数据的再利用
3.1 开放的中国学术期刊论文数据的FAIR化
目前,期刊论文全文的格式以PDF为主,HTML/XML使用率的下降导致出版者提供的论文级别的元数据减少,另外期刊、卷期级别的元数据著录在同一出版者的不同期刊、同一期刊的不同卷期也不尽相同。数据结构的不统一,使得机器难以对大量元数据进行快速处理。要实现开放的中国学术期刊论文元数据的再利用必须按照科学数据FAIR原则,实现开放元数据的可查找(findable)、可获取(accessible)、可互操作(interoperable)和可重复使用(reusable),使之符合人工智能就绪数据(AI-ready data)规范[17]。
在这一过程中,元数据与人工智能是双向交互的关系。一方面,人工智能通过吸收人工标注(期刊原有或平台自加工)的元数据来增强自身的知识水平,比如人工智能如果读取了准确的、机器可读的权限元数据就可以智能规避相应的法律风险。另一方面,人工智能能够对元数据进行质量评估和增强,比如自然语言处理技术可用于分析文档的语言内容,以提取缺失的元数据片段,甚至自动生成元数据。机器学习技术可用于数据的消歧,提升数据的准确度,有学者使用2.39亿篇出版物的元数据对2.43亿名作者进行了作者姓名消歧,将作者实体总数减少到1.51亿[18]。
最终开放中国学术期刊论文元数据和全文的潜在路径之一将是打造FAIR化的中国学术期刊开放研究平台,利用知识图谱技术构建一套支持科研数据生产、管理、出版和使用的一体化平台,加速科研信息与学术交流从封闭的文档进化为开放的数字信息[19-20]。
3.2 开放的中国学术期刊论文元数据再利用方向
3.2.1 知识挖掘
知识挖掘的发展趋势可以从技术发展和应用扩展两个方面来看。从技术层面看,随着人工智能、机器学习、深度学习等技术的不断发展,知识挖掘的能力和效率将得到显著提升。深度学习技术的应用,特别是在自然语言处理和生成式人工智能等方面的进步,将使得知识挖掘能够处理更加复杂的数据类型,提高挖掘的准确性和深度[21]。此外,大数据技术的普及以及OA运动的推进将使知识挖掘能够处理更大规模的数据集,发现更加深层次的知识[22]。从应用领域看,文献资源揭示粒度正从书目层级逐步深化到篇章级别乃至文章内部的图表、科研实体、公式等知识单元,对应文献元数据规模数以亿计。开放的中国学术论文元数据作为一种开放数据集,可利用知识挖掘技术来进一步帮助研究人员更高效地获取和利用信息[23],提升文献的增值服务价值。例如,在中医药治疗产后抑郁症的研究中,研究人员通过对医学学术文献的挖掘分析,发现常用药物及其组合,为临床治疗提供理论依据[24]。此外,开放的中国学术论文元数据在增强学术研究的可发现性和影响力方面起着关键作用。通过优化元数据并确保其准确性,出版者可以提高其出版物在网络中的显示度,提升成果传播能力[25]。
3.2.2 学术评价
随着科技的发展,AI已经在许多领域中发挥了重要作用。文本挖掘、自然语言处理、深度学习等人工智能技术为学术评价提供了更加有效的技术支撑,如何利用AI进行更加客观、准确和高效的学术评价,已经成为一个重要研究课题。学者们不断从以下维度探索更多的学术评价手段。
(1)替代度量分析是通过社交媒体平台、学术平台、新闻网站等来源,收集论文下载、浏览、评论、书签和转发等数据,进行影响力分析。但目前通用的替代计量数据都是针对国际主流平台进行的观测,中文社区并没有得到重视,针对中国学术期刊论文影响力的分析有必要引入中文社区的替代计量数据。
(2)语义计量学试图基于引用关系和学术文本相似性,从学术文本层面挖掘学术价值[26]。元数据将有助于形成论文的内容网络。
(3)基于内容的引文分析,基于全文学术数据(引文的频率、位置、功能、情感等细粒度特征),从微观角度揭示文献之间的影响程度和方向[27],这些角度实际上可以认为是更为细粒度的元数据。
总之,这些新的方法都离不开开放的学术期刊论文元数据和全文的支持。
3.2.3 开放获取率测度
由于中国学术期刊普遍采用青铜OA模式,且OA运行模式不够透明、规范,再加上电子期刊集成平台对各种类型OA论文的标注不规范,导致外国对中国的OA现状缺乏全面、准确的判断。与此同时,目前Web of Science、Scopus、Dimensions等知名数据库都接入了Unpaywall数据[28],Unpaywall从50,000多个出版商和存储库中收集OA内容,并使其易于查找、跟踪和使用。但对于中国期刊及论文的开放状态,Unpaywall的判断往往不准确,使得我国的开放获取率被低估,相关数据及资源得不到全球的广泛传播及利用。开放中国学术期刊论文数据库项目全部完成后,能够比较准确地反映绝大多数中国学术期刊的OA发展历程和绝大多数中国学术期刊论文的OA属性,用户可按照时间序列、学科领域、地域、OA模式等方式,对中国学术期刊的OA发展历程和现状进行统计、分析,并对未来发展趋势进行预测。一个典型的例子可供借鉴:德国开放获取监测(OAM)汇集了Unpaywall、Dimensions、Web of
Science、Scopus和OpenAPC等元数据资源。Unpaywall用作出版物元数据的中央数据源,包括开放获取可用性。然后,这些数据与期刊级元数据的CrossRef数据进行匹配,最后与隶属机构和引文数据的Dimensions、Web of Science和Scopus数据进行匹配。与 OpenAPC的连接则提供了每个参与机构的出版成本数据[29]。
3.2.4 大模型训练
大语言模型是依赖海量文本数据,经过无监督预训练及有监督标注数据微调而成。领域大模型则是通用大模型经过领域数据的微调而得到,具备解决领域问题的能力,满足领域应用需求[30]。目前,以ChatGPT为代表的生成式人工智能技术主要使用各种类型的英文语料,相对缺乏中文语料,且生成的内容可能存在“幻觉”文字(或称人工智能生成的虚假信息)。为降低“幻觉”带来的风险,爱思唯尔公司推出了Scopus AI[31]。该系统基于AIGC技术和Scopus引文数据库及其中可信的学术文献,可针对用户选定的科学问题快速生成可溯源(即标注出相应的参考文献)且经过凝练的观点概要(见图3),并可根据用户的需求进行文字扩展,帮助用户确定本领域的核心文献和专家,确保用户能够全方位了解自己感兴趣的科学问题。
中国的科应全球创新数据平台也推出了类似的功能。但由于中文学术期刊论文元数据相对匮乏,上述系统都很少使用中文学术期刊论文。从期刊论文传播角度看,这会导致用户在使用这些工具时无法获得中文呈现的知识,可能会影响中文学术期刊论文的影响力,至少不能促进影响力的提升。从AI平台建设角度看,会使AI的训练语料库缺少中文素材,回答的中文结果不理想,对中文用户不够友好。
近年来,中国学术期刊普遍推行同行评议制度,促使中国学术期刊论文质量和影响力快速提升。开放中国学术期刊论文数据库项目收录的这些跨度几十年、相对可信的学术文献能够很好地用于大语言模型或领域大模型的训练,并增强大模型的时间序列分析能力。
目前,国内已有期刊如《粉末冶金技术》《物理学报》使用检索增强生成技术融合论文元数据、论文正文和大语言模型,为读者提供智能问答服务。类似的,Web of Science也推出了研究助手WOSRA,其本质也是生成式AI驱动的工具,目前能够回答标题、DOI、主题等元数据相关的问题,比如“推荐一些关于气候变化(主题)的论文”。可以认为,元数据与知识图谱相结合进而与大模型相结合,是实现AI for Science的可能趋势。
4 结语
中国电子学术期刊出版市场的高度集中,在一定程度上造成了电子学术期刊出版和服务的封闭。二十多年来,OA运动已在全球出版界掀起了巨大的波澜,虽然中国大部分学术期刊都在积极实践,但OA出版在中国的电子学术期刊出版领域仍是波澜不兴。随着中国图书馆界本着开放科学和开放获取精神建立起来的公益性、开放的学术期刊论文元数据平台或其他类似系统的日益完善,中国三大商业电子期刊集成出版平台势必也将变得更加开放,并朝着重塑商业运维模式、升级服务手段和形式、增加高附加值服务项目和内容的方向发展,从而共同推动中国学术期刊论文元数据和全文的开放和再利用,为知识挖掘、学术评价、开放获取率测度、大模型训练等提供高质量的数据和语料库支持,从而让更多的学者和民众享受到学术研究成果开放对科学技术、经济社会发展带来的益处。
参考文献:
[1]习近平.加强基础研究 实现高水平科技自立自强[J].求是,2023(15):4-15.
[2]高雅丽.中国科技期刊的一流之路[N].中国科学报,2024-07-19(3).
[3]中国科学技术协会.中国科技期刊发展蓝皮书(2022):数字经济时代的学术出版与交流平台专题[M].北京:科学出版社,2022:12.
[4]张楠.2024年度《期刊引证报告》发布[N].中国科学报,2024-06-21(1).
[5]资源介绍[EB/OL].[2024-07-10].https://www.nstl.gov.cn/Portal/zyyfw_zyjs.html.
[6]PubScholar公益学术平台[EB/OL].[2024-07-10].https://pubscholar.cn/resource.
[7]中国科学引文数据库(CSCD)[EB/OL].[2024-07-10].http://www.sciencechina.cn/scichina2/index_more1.jsp.
[8]中文社会科学引文索引[EB/OL].[2024-07-10].http://cssci.nju.edu.cn/.
[9]LÜSCHOW A.Application of graph theory in the library domain:building a faceted framework based on a literature review[J].Journal of librarianship and information science,2021,54(4):558-577.
[10]Good practice principles for scholarly communication services[EB/OL].[2024-07-10].https://sparcopen.org/wp-content/uploads/2019/01/Sparc-Good-Practice-Principles-v4.pdf#:~:text=COAR%20and%20SPAR C%20have%20developed%20seven%20good%20pract ice.
[11]BESANÇON L,CABANAC G,LABBÉC,et al.Sneaked references:fabricated reference metadata distort citation counts[EB/OL].[2024-07-10].https://asistdl.onlinelibrary.wiley.com/doi/full/10.1002/asi.24896.
[12]NISHIKAWA-PACHER A,HECK T,SCHOCH K.Open Editors:a dataset of scholarly journals′ editorial board positions[J].Research evaluation,2023,32(2):228-243.
[13]JAHN N,MATTHIAS L,LAAKSO M.Toward transparency of hybrid open access through publisher-provided metadata:an article-level study of Elsevier[J].Journal of the association for information science and technology,2021,73(1):104-118.
[14]肖曼,黄金霞,王昉,等.领域特色资源的开放共享建设机制探析:以OAinONE项目为例[J].数字图书馆论坛,2019(9):2-8.
[15]帮助中心[EB/OL].[2024-07-02].http://oa.las.ac.cn/oainone/static/html/help.html.
[16]陶云云,张志林,刘华坤.DOI标准提升我国学术期刊传播效能研究[J].新闻传播科学,2024,12(1):65-71.
[17]CHEN Y F,HUERTA E A,DUARTE J,et al.A FAIR and AI-ready Higgs boson decay dataset[J].Scientific data,2022,9(1):31.
[18]FÄRBER M,AO L.The Microsoft Academic Knowledge Graph enhanced:author name disambiguation,publication classification,and embeddings[J].Quantitative science studies,2022,3(1):51-98.
[19]STOCKER M,OELEN A,JARADEH M Y,et al.FAIR scientific information with the Open Research Knowledge Graph[J].FAIR connect,2023,1(1):19-21.
[20]
AHRABIAN K,DU X W,MYLOTH R D,et al.PubGraph:a large-scale scientific knowledge graph[EB/OL].[2024-10-10].https://arxiv.org/pdf/2302.02231.
[21]WANG S H,SUN X F,LI X Y,et al.GPT-NER:named entity recognition via large language models[EB/OL].[2024-07-02].https://arxiv.org/pdf/2304.10428.
[22]KNOTH P,HERRMANNOVA D,CANCELLIERI M,et al.CORE:a global aggregation service for open access papers[J].Scientific data,2023(10):366.
[23]NICHOLSON J M,MORDAUNT M,LOPEZ P,et al.Scite:a smart citation index that displays the context of citations and classifies their intent using deep learning[J].Quantitative science studies,2021,2(3):882-898.
[24]罗江,杨艺萌,肖媛媛,等.基于数据挖掘分析产后抑郁的中医用药规律[J].中医与中药材研究,2022,1(2):7-13.
[25]
WILLEY E,RADOVSKY S.LIS journals′ lack of participation in Wikidata item creation[J].KULA:knowledge creation,dissemination,and preservation studies,2024,7(1):1-12.
[26]KNOTH P,HERRMANNOVA D.Towards semantometrics:a new semantic similarity based measure for assessing a research publication′s contribution[J].D-Lib magazine,2014,20(11/12):8.
[27]DING Y,ZHANG G,CHAMBERS T,et al.Content-based citation analysis:the next generation of citation analysis[J].Journal of the association for information science and technology,2014,65(9):1820-1833.
[28]Citation indices[EB/OL].[2024-07-11].https://unpaywall.org/integrations.
[29]BARBERS I,STANZEL F,MITTERMAIER B.Open access monitor Germany:best practice in providing metrics for analysis and decision-making[J].Serials review,2022,48(1/2):49-62.
[30]刘倩倩,刘圣婴,刘炜.图书情报领域大模型的应用模式和数据治理[J].图书馆杂志,2023,42(12):22-35.
[31]Scopus[EB/OL].[2024-07-02].https://www.scopus.com/search/form.uri?display=basic#scopus-ai.
作者简介:
朱江(1968—),男,硕士,研究馆员,任职于中国科学院成都文献情报中心、中国科学院大学经济与管理学院。研究方向:数字资源建设、开放资源组织。
罗煜(2000—),男,通信作者,任职于中国科学院成都文献情报中心,中国科学院大学经济与管理学院硕士研究生在读。研究方向:信息组织。
周海晨(1993—),男,博士,助理研究员,任职于中国科学院成都文献情报中心。研究方向:科学计量与评价、知识挖掘。
猜你喜欢
中国病理生理杂志(2022年1期)2022-02-16 02:59:46
西南石油大学学报(社会科学版)(2021年6期)2021-12-07 14:37:50
西南石油大学学报(社会科学版)(2021年3期)2021-06-11 07:43:24
西南石油大学学报(社会科学版)(2020年3期)2020-06-12 09:25:02
宁夏医学杂志(2020年4期)2020-03-01 13:16:20
宁夏医学杂志(2020年3期)2020-02-27 14:17:11
传媒评论(2017年9期)2017-12-20 08:07:58
水利科技与经济(2017年6期)2017-04-28 08:30:06
新闻传播(2016年2期)2016-07-12 10:52:28
出版与印刷(2015年1期)2015-12-20 06:33:07
