
FFConvNeXt3D: 提取中大规模目标特征的大卷积核网络
2025-01-01 00:00:00黄乾坤黄蔚凌兴宏
郑州大学学报(理学版) 2025年2期







摘要: 目前大卷积核模型在图像领域已经证明其有效性,但是在视频领域还没有优秀的3D大卷积核模型。此外,之前的工作中忽视了时空行为检测任务主体是人的特点,其中的骨干网络只针对通用目标提取特征。针对上述原因,提出了一种含有特征融合结构的3D大卷积核神经网络feature fusion ConvNeXt3D(FFConvNeXt3D)。首先,将成熟的ConvNeXt网络膨胀成用于视频领域的ConvNeXt3D网络,其中,预训练权重也进行处理用于膨胀后的网络。其次,研究了卷积核时间维度大小和位置对模型性能的影响。最后,提出了一个特征融合结构,着重提高骨干网络提取人物大小目标特征的能力。在UCF101-24数据集上进行了消融实验和对比实验,实验结果验证了特征融合结构的有效性,并且该模型性能优于其他方法。
关键词: 大卷积核; 目标检测; 时空行为检测; 行为识别; 特征融合
中图分类号: TP391
文献标志码: A
文章编号: 1671-6841(2025)02-0037-07
DOI: 10.13705/j.issn.1671-6841.2023124
FFConvNeXt3D: Large Convolutional Kernel Network for Extracting
Target Features of Medium and Large Size
HUANG Qiankun1, HUANG Wei2, LING Xinghong1,3,4
(1.School of Computer Science and Technology, Soochow University, Suzhou 215006, China;
2.Department of Computer Science, Soochow College, Soochow University, Suzhou 215006, China;
3.School of Computer Science and Artificial Intelligence, Suzhou City University, Suzhou
215104, China;
4.Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education,
Jilin University, Changchun 130012, China)
Abstract: Large convolutional kernel models was proven effective in the image domain, but the available 3D large convolutional kernel models were not good enough in the video domain. Additionally,
the backbone network only could extract features for generic targets, and human was ignored as the subject in the spatio-temporal action detection task in previous work. To address these issues, a 3D large convolutional kernel neural network containing a feature fusion structure feature fusion ConvNeXt3D (FFConvNeXt3D) was proposed. Firstly, the mature ConvNeXt network into a ConvNeXt3D network was extended to the video domain, where pre-training weights were also processed for the expanded network. Secondly, the effect of the size and position of the temporal dimension of the convolutional kernel on the performance of the model was investigated. Finally, a feature fusion structure that would focus on improving the ability of the backbone network to extract features from targets of medium or larger size such as humans was proposed. The ablation experiments and comparison experiments were conducted on the UCF101-24 dataset. The experimental results verified the effectiveness of the feature fusion structure, and the model performed better than other methods.
Key words: large convolution kernel; object detection; spatio temporal action detection; action recognition; feature fusion
0 引言
视频理解任务是指计算机视觉和机器学习领域中,对视频内容进行分析、理解和处理的任务。时空行为检测(spatio temporal action detection)任务是视频理解任务里一个重要的子任务,除了需要分类目标人物的动作,也需要确定人物的位置[1-2]。模型的性能非常依赖特征提取网络的性能。Tang等[3]使用SlowFast[4]作为骨干网络,Zhao等[5]使用CSN(channel-separated convolutional networks)[6],这些检测网络的分类性能都随着骨干网络性能提升得到了提升。
在图像领域,ConvNeXt网络吸收了swin transformer网络的优秀设计[7-8],重新对ResNet网络改进[9],在速度和准确率上较为优秀。而I3D(inflated 3D ConvNet)[10]证明了将成熟的2D网络扩展成3D网络是行之有效的方法。因此本文将ConvNeXt2D扩展为ConvNeXt3D网络。保留ConvNeXt的一系列优秀设计,同时将网络的卷积核扩张成3D卷积核,在网络结构里加入了提取时间信息的能力。通过I3D中提到的方法,将ConvNeXt的预训练权重扩张成3D预训练权重。同时对比了时间卷积核大小和位置对性能和速度的影响。
此外,目前的骨干网络对所有尺寸的目标都统一提取特征,忽略了动作检测任务的特点。动作检测任务的目标主体是人,而人往往是中等和相对较大的物体,根据这一点,提出了一种特征融合结构,用于提取中等和较大尺寸物体的特征。在UCF101-24数据集上进行的大量对比实验证明,本文提出的feature fusion ConvNeXt3D(FFConvNeXt3D)网络具有优秀的性能。
本文主要贡献如下。
1) 提出了一种含有特征融合结构的3D大卷积核神经网络(FFConvNeXt3D),用于视频理解中的时空行为定位任务,模型性能在UCF101-24数据集上达到了最优。
2) 在UCF101-24数据集上进行了充分的消融实验,证明了3×7×7卷积核和先2D再3D卷积的合理性。
3) 提出了一个有效的特征融合结构,能够很好提升骨干网络提取尺寸在中等及以上目标特征的能力。
1 相关工作
图像领域的分类和检测在视频领域都有对应的任务,如行为识别、行为检测。在实际生活中,大量的应用场景往往以视频居多,视频理解是非常值得研究且很有难度的方向。而视频理解中以人为主体的行为识别和行为检测任务更为重要。
1.1 时空行为检测
行为识别任务是最基础的视频理解任务,给定一个剪辑好的视频片段,片段中只会有一个动作。时空行为检测任务类似于目标检测在视频领域的扩展,需要在样本帧中识别待检测人物,同时给出人物动作。行为检测分为目标检测和行为识别两个任务,先利用优秀的目标检测器(如FasterRCNN[11])检测人物边界框,与此同时将视频片段送入3D骨干网络(如I3D等)得到特征[10],之后在3DCNN特征的基础上执行区域特征聚集,最后对得到的特征行为分类。
1.2 3D骨干网络
在行为识别任务上,Carreira等[10]提出了I3D网络,验证了网络从ImageNet图像数据集学习的知识迁移到视频领域。R(2+1)D[12] 和S3D[13]网络用分解3D卷积的思想,将3D卷积分解成2D空间卷积和1D时间卷积,探索降低3D网络方向计算量。SlowFast借鉴双流网络和分解3D卷积网络的思想[4],利用快和慢两个网络分别融合不同帧率的网络。CSN和X3D网络借鉴了图像领域分组卷积和深度可分离卷积的思想[6,14],保证精度的情况下大幅度降低了计算量[15]。本文将ConvNeXt,结合3DCNN网络设计思路[15],重新设计了一个高效的大卷积核骨干网络FFConvNext3D。
2 模型设计
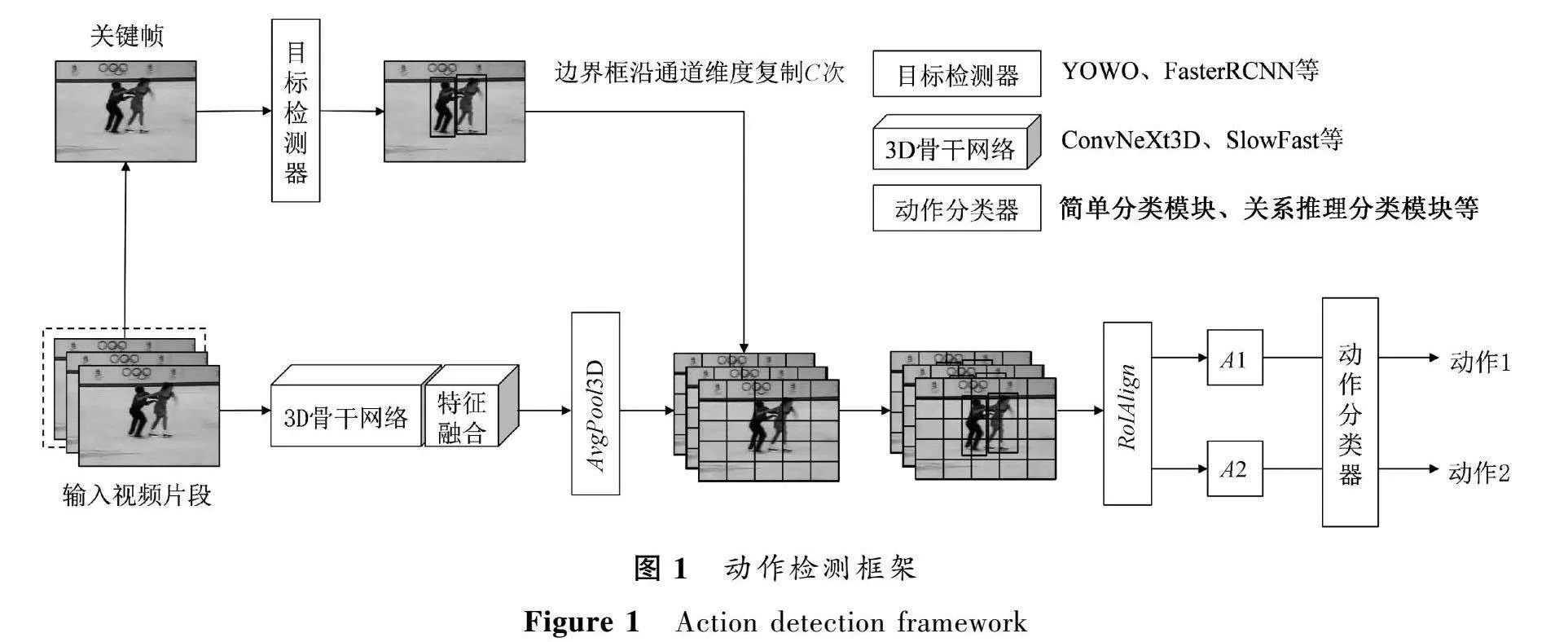
本文提出了一个基于ConvNeXt2D设计的3DCNN网络:FFConvNeXt3D网络,它是由一个检测器和一个骨干网络构成。检测器可以是任意的人体检测器,本文使用文献[16]中提到的检测器。图1显示了FFConvNeXt3D的总体架构设计。具体为,输入视频片段并提取成连续的图像帧Xi,输入3D骨干网络得到特征图Xb,之后进入特征融合模块后得到特征图Xf∈RT×C×H×W,T、C、H、W分别是时间、通道、高度、宽度。
经过3D平均池化后,去除时间维度,调整为Xo∈RC×H×W,
用公式表示为
Xo=AvgPool3D{ffeaturefusion[fbackbone(Xi)]}。
在Xi中取最后一帧Fk作为关键帧,进入目标检测器,得到N个人物的边界框,同时在通道维度上复制C次,
{Bi}Ni=1=ObjectDetector(Fk),{Bi,j}NCi=1, j=1=fθ({Bi}Ni=1),
其中:fθ(·)表示通道维度上的复制。通过RoIAlign后得到人物特征{Pi∈RC×7×7}Ni=1,进行空间最大池化得到人物特征{Pi∈RC}Ni=1,将人物特征放入关系推理模块进行关系建模[17]。用全连接层对人物特征进行分类。总结为
{Pi}Ni=1=RoIAlign(XO,{Bi,j}NCi=1, j=1),
{Pi}Ni=1=MaxPool({Pi}Ni=1),
Actioni=softmax{fc[RelationModule({Pi}Ni=1)]}。
2.1 时间维度膨胀
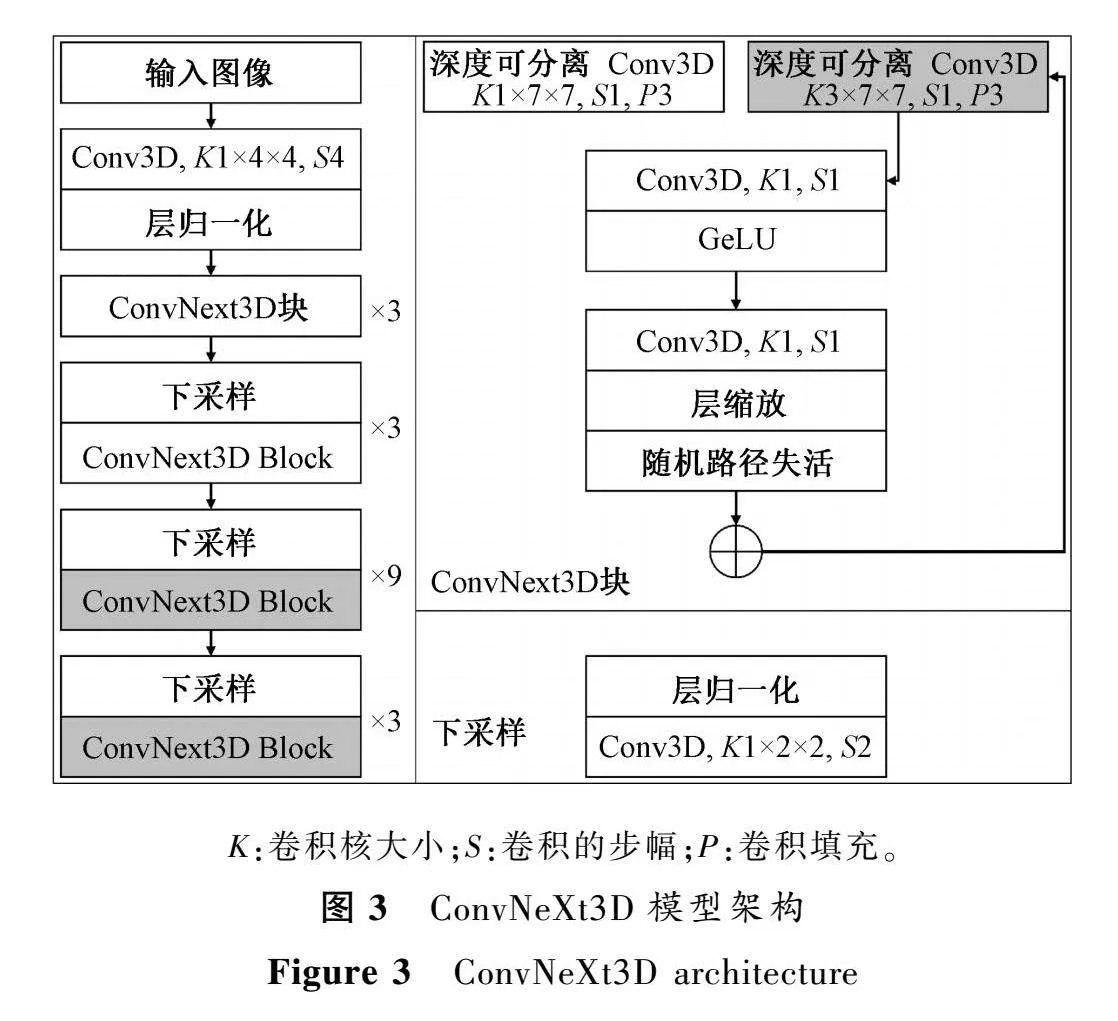
本文使用文献[10]中2DCNN迁移3DCNN架构的方法,将N×N的2D卷积核扩张成N×N×N的3D卷积核,将预训练权重也同步膨胀相应维度,并且将预训练权重数值除以相应维度。
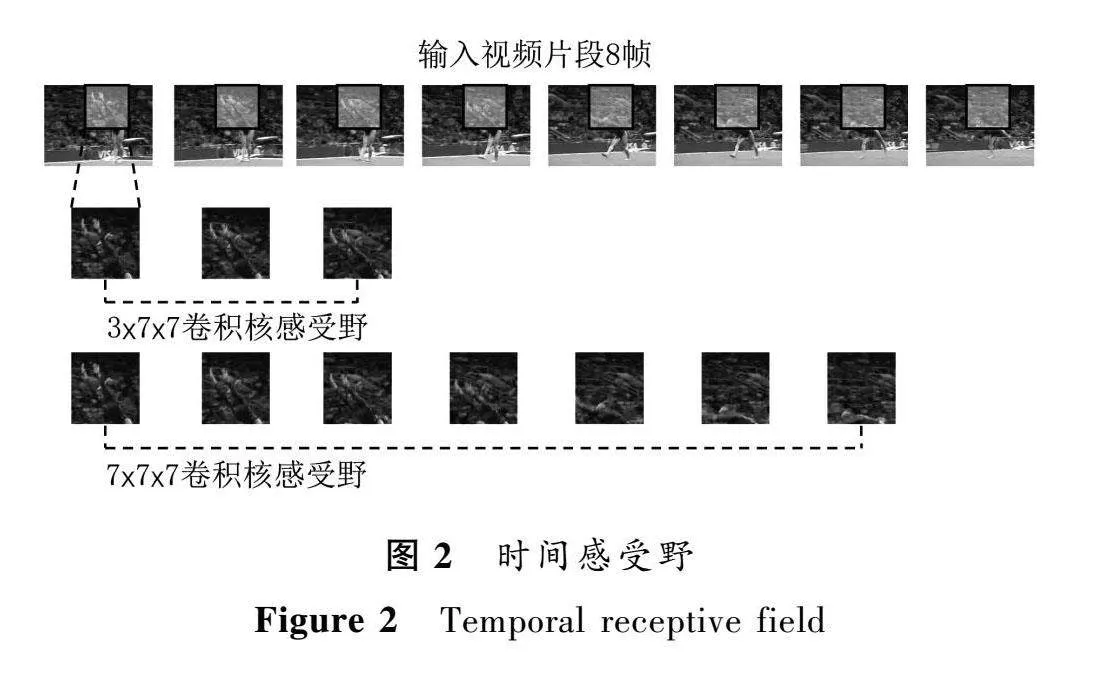
ConvNeXt是7×7的大卷积核,本文首先将卷积核扩张成7×7×7,但针对视频样本,时间维度和空间维度需要的感受野是不一样的。本文空间分辨率从224×224开始下采样,而时间分辨率是从32帧或者16帧开始,如果3D卷积核的时间维度和空间维度采用一样的大小,会对提取该特征点的语义信息造成负面影响。现实中人眼通过望远镜看一个固定的、有人物活动的区域时,当人物原地活动时,可以准确理解该人物动作,但如果人物的活动超出了望远镜的观察范围,则会对一个动作造成误解,所以望远镜的视野(空间感受野)要跟上人物动作的变化速度(时间感受野)。如图2,第一行框内是3D卷积核当前的感受野范围,当时间卷积核为3时,感受野范围内语义信息没有过多的干扰信息。当时间卷积核为7时,空间感受野并没有跟上时间感受野扩张的速度,所以感受野内缺少了有效信息,多了干扰信息。所以我们将时间膨胀维度设置为3,实验证明,3×7×7的卷积核更为合理,提取的语义特征更加明确。
2.2 慢速路径
与以前的3DCNN网络(如C3D等)不同的是,在第一个和第二个残差块中,本文没有对时间维度进行卷积,因为在低层语义中,每个特征图的像素点在时间维度上的相关性很低。之前一系列对卷积网络可视化的工作表明,低层残差块输出的特征图局部细节信息丰富,而残差块的层数越往后,特征图的语义信息愈加丰富。
如图3,本文借鉴了SlowFast中慢速路径的设计,只在第3个和第4个残差块中进行时间卷积,用灰色方块标出。目前多数3DCNN架构的模型输入图片帧长度在8~64帧,最长为2 s左右,这在时空行为检测任务中属于较低的时间分辨率。因此本文在整个骨干网络中不进行时间下采样,在时间维度上保持高分辨率。网络架构的细节如图3所示。
2.3 特征融合
在目标检测任务中,每个物体的尺寸不会完全相同,在特征金字塔结构(FPN)出现以前,小目标的检测是一个难题,原因是通过类ResNet骨干网络时,随着空间分辨率的降低,网络的提取特征变抽象的同时会损失定位信息。在行为识别这个领域里,任务检测目标是人,往往是占据图像中相当大的位置,而小目标应该是被剔除的对象。
针对如何去除干扰的背景,让网络将注意力集中在图中的人物对象上,本文提出了一种特征融合结构,它将高层语义和低层定位信息相融合,得到的特征输出层既包含用于分类的高层语义,又包含用于定位的低层信息。在对高层特征图进行上采样后,与低层特征图融合出现的混叠效应,特征金字塔利用3×3的卷积来改善。本文采用了CSPConvNeXt3D块来改善混叠效应,这对高层特征和低层特征的融合会更加有效。
特征金字塔是由上向下融合低层特征,目的是传递顶层的高级语义特征,但这遗漏了低层定位信息的传递。所以本文用路径聚合结构加强了低层定位信息的传递[18]。在融合低层语义和高层语义之后,用CSPConvNeXt3D块来加强特征融合,经过路径聚合结构后会得到三种分辨率的特征图,取中等分辨率和高分辨率的特征图,对应中等目标和大目标的人物。详细的结构如图4所示,其中28×28,14×14,7×7三种类型的箭头分别代表了三种不同分辨率特征图的传递。
特征金字塔是由上向下融合低层特征,目的是为了传递顶层的高级语义特征,但会遗漏低层定位信息的传递。本文用路径聚合结构进行加强[18],同样,在融合低层语义和高层语义之后,用CSPConvNext3D块来加强特征融合。经过路径聚合结构后会得到三个分辨率的特征,取中等分辨率和高分辨率的特征图,对应中等目标和大目标的人物。如图4所示。
输入图像帧在经过骨干网络后取低、中、高三层特征图,进入特征融合模块。CSPConvNeXt3D块的结构如图4所示,输入特征通过两个3DConvBNSiLU块将通道降维至原来的1/2。ConvNeXt3D块和骨干网络中ConvNeXt3D块不同的是,没有使用残差连接。3DConvBNSiLU块如图4所示,由Conv3D、BatchNorm3D、SiLU激活函数组成,用于调整通道,融合特征。
3 实验与分析
本文在UCF101-24数据集上进行对比实验和消融实验,验证FFConvNext3D模型的有效性。
3.1 实验设置
3.1.1 数据集 本文选用在行为检测任务中常用的数据集UCF101-24。UCF101-24是UCF101数据集里面一个子集,并进行了重新标注,训练集和测试集分别是2 284和923个视频,数据集中包含24类动作。数据集样本视频分辨率为320×240,所有动作实例时长占了整个数据集时长的78%。
3.1.2 实验方法 本文在训练阶段,目标人物边界框使用真实边界框(ground truth boxes),在测试阶段,使用文献[16]的人体检测器,该检测器在ImageNet和COCO数据集上进行预训练。设置批处理大小为12,学习率为0.0001,权重衰减系数为0.0005,在UCF101-24数据集上进行微调10个轮次,定位精度可以达到91.7%。
在UCF101-24上,动作被分为24类独立的动作,每个人物在一个视频片段中只能有一类动作,因此这24类动作都是互斥的,后续使用softmax函数分类,并使用交叉熵损失函数进行训练。在训练阶段,采用一些常规的数据增强的方法。
3.1.3 评价指标
在行为检测任务中,需要综合考虑分类与定位的性能。因此本文采用每帧检测的各类别AP平均值
(frame-mean average precision,Frame-mAP)
作为评价指标。该指标考虑了模型的精度(P)和召回率(R),可以客观地评估行为检测算法的性能。交并比(IoU)是衡量预测框和真实框之间重叠程度的指标。当IoU大于等于某个阈值时,我们认为预测框和真实框匹配成功。本文取阈值为0.5,即统计所有IoU
≥
0.5人物框的动作分类。Frame-mAP的计算方法如下,
P=TPTP+FP,
R=TPTP+FN,
AP=∫10Pd(R),
Frame-mAP=∑Ni=1AAPiN,
其中:TP是正确检测到人且动作分类正确的边界框;
FP是正确检测到人但动作分类错误的边界框;
FN是漏检的含人物边界框和分类错误的含人物边界框;
AAPi值为P-R曲线下面积,
i表示第i个类别;Frame-mAP表示每一帧中所有行为类别的平均精度,Frame-mAP50表示IoU为0.5时的Frame-mAP;N表示类别总数,UCF101-24数据集有24个类别,因此N为24。
3.2 对比方法
如表1所示,本文分两组进行对比实验,第一组分别与以C3D为骨干网络的T-CNN[19]、以ResNeXt3D-101为骨干网络的YOWO[16]、以CSN-152为骨干网络的TubeR和以SlowFast-50为骨干网络的AIA进行比较[5,3]。第二组分别与TacNet[20]、ACT[21]、MOC[22]、STEP[23]、I3D[10]这5个双流网络对比。表中黑色加粗的结果是本文模型的结果。另外,本文提出了两种规格模型,FFConvNeXt3D-Tiny和FFConvNeXt3D-Small。在仅使用ImageNet22K预训练权重的情况下,Frame-mAP50指标达到了最优。在所有动作中,识别效果较好的是击剑类动作,这类动作的特征是图片中背景干净,没有多余的干扰人群。识别效果较差的是篮球的扣篮类动作,这类动作背景里人物众多,对识别目标人物的动作造成了干扰。
3.3 消融研究
所有消融实验均在ConvNeXt-Tiny的基础上进行,均用ImageNet22K数据集的预训练权重,使用相同的人体检测器。模型的输入样本为连续的16帧。不包含特征融合模块时,骨干网络的最后一个下采样层不进行下采样,保持14×14的空间分辨率。
1) 时间感受野。我们以ConvNeXt2D-Tiny作为基础网络,分别尝试了3×7×7和7×7×7卷积核的效果。如表2所示,实验结果证明3×7×7的3D卷积核大小效果是最好的,时间维度为7时,预测精度反而下降。这可能是因为时间维度和空间维度感受野并不相同,正如Transformer结构优势是对全局信息的获取,更大的空间感受野也有助于提高目标特征的提取能力。
而时间感受野过大,且人物边界框除关键帧以外均为复制过去的边界框时,造成人物动作管不吻合实际人物位置的情况,影响了特征提取效果。人物动作管(action tubelets)是由一连串紧密相连的人物边界框组成的,用于更细致地描述视频中人物动作发生的位置。
而时间感受野过大,且人物边界框除关键帧以外均为复制过去的边界框时,造成人物动作管不吻合实际情况,影响了特征提取效果。
2) 2D卷积和3D卷积的顺序。本文将模型分为两个部分,第1部分为Stem、Res2、Res3层,第2部分为Res4、Res5层。如表3所示,分别在这两部分使用不同的卷积,实验结果证明先2D后3D卷积的效果更好且计算量更少。最后使用的结构是将ConvNeXt-Tiny的Res4和Res5的卷积核设置为3×7×7,其余各层大小均为1×7×7,不使用时间卷积。
3) 特征融合。本文比较了FPN和PAN的效果,表4中基线是不加特征融合,FPN只取7×7和14×14分辨率的特征图,将7×7上采样至14×14,并与14×14的特征图进行拼接(Concat)操作。PAN同样如此,取7×7和14×14分辨率的特征图。如表4,我们尝试了加入28×28的特征图,平均精度反而
下降,产生该现象的原因是28×28的特征图中存在较多的小面积人物特征,一般不是目标人物,导致了对正确识别目标人物的干扰。
4 结论
本文基于ConvNeXt网络提出了FFConv-NeXt3D。在保留了ConvNeXt的大卷积核基础上,分组卷积设计并同时改造成3D卷积网络。本文还提出了新的特征融合结构,有效提高了骨干网络的特征提取能力。在UCF101-24公开数据集的消融实验证明,时间感受野需要和空间感受野匹配,因此3×7×7卷积核更合理。此外先2D再3D卷积效果更好,本文所提方法比单纯特征金字塔的效果更好。将本文所提出的方法在UCF101-24数据集上和单纯图像帧输入网络、双流输入网络进行了对比实验,效果达到了最优。
参考文献:
[1] 王阳, 袁国武, 瞿睿, 等. 基于改进YOLOv3的机场停机坪目标检测方法[J]. 郑州大学学报(理学版), 2022, 54(5):22-28.
WANG Y, YUAN G W, QU R, et al. Target detection method of airport apron based on improved YOLOv3[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(5):22-28.
[2] 蒋韦晔, 刘成明. 基于深度图的人体动作分类自适应算法[J]. 郑州大学学报(理学版), 2021, 53(1):16-21.
JIANG W Y, LIU C M. Adaptive algorithm for human motion classification based on depth map[J]. Journal of Zhengzhou university (natural science edition), 2021, 53(1):16-21.
[3] TANG J J, XIA J, MU X Z, et al. Asynchronous interaction aggregation for action detection[EB/OL].(2020-04-16)[2023-03-11]. https:∥arxiv.org/abs/2004.07485.pdf.
[4] FEICHTENHOFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]∥IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 6201-6210.
[5] ZHAO J J, ZHANG Y Y, LI X Y, et al. TubeR: tubelet transformer for video action detection[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 13588-13597.
[6] TRAN D, WANG H, FEISZLI M, et al. Video classification with channel-separated convolutional networks[C]∥IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 5551-5560.
[7] LIU Z, MAO H Z, WU C Y, et al. A ConvNet for the 2020s[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11966-11976.
[8] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[EB/OL]. (2021-03-25)[2023-03-11]. https:∥arxiv.org/abs/2103.14030.pdf.
[9] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778.
[10]CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 4724-4733.
[11]REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137-1149.
[12]TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6450-6459.
[13]XIE S N, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]∥European Conference on Computer Vision. Cham: International Springer Publishing, 2018: 318-335.
[14]FEICHTENHOFER C. X3D: expanding architectures for efficient video recognition[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 200-210.
[15]佘颢, 吴伶, 单鲁泉. 基于SSD网络模型改进的水稻害虫识别方法[J]. 郑州大学学报(理学版), 2020, 52(3)49-54.
SHE H, WU L, SHAN L Q. Improved rice pest recognition based on SSD network model[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(3): 49-54.
[16]KPKL O, WEI X Y, RIGOLL G. You only watch once: a unified CNN architecture for real-time spatiotemporal action localization[EB/OL]. (2019-11-15)[2023-03-11]. https:∥arxiv.org/abs/1911.06644.pdf.
[17]PAN J T, CHEN S Y, SHOU M Z, et al. Actor-context-actor relation network for spatio-temporal action localization[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 464-474.
[18]LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768.
[19]HOU R, CHEN C, SHAH M. Tube convolutional neural network (T-CNN) for action detection in videos[EB/OL]. (2017-03-30)[2023-03-11]. https:∥arxiv.org/abs/1703.10664.pdf.
[20]SONG L, ZHANG S W, YU G, et al. TACNet: transition-aware context network for spatio-temporal action detection[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11979-11987.
[21]KALOGEITON V, WEINZAEPFEL P, FERRARI V, et al. Action tubelet detector for spatio-temporal action localization[C]∥IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 4415-4423.
[22]LI Y X, WANG Z X, WANG L M, et al. Actions as moving points[C]∥European Conference on Computer Vision. Cham: Springer International Publishing, 2020: 68-84.
[23]YANG X T, YANG X D, LIU M Y, et al. STEP: spatio-temporal progressive learning for video action detection[C]∥IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 264-272.
