
基于知识图谱增强的恶意代码分类方法
2025-01-01 00:00:00夏冰何取东刘文博楚世豪庞建民
郑州大学学报(理学版) 2025年2期




摘要: 针对应用程序接口(application programming interface,API)序列识别的恶意代码分类方法存在特征描述能力弱和调用关系缺失的问题,提出一种基于知识图谱增强的恶意代码分类方法。首先,基于函数调用图抽取恶意代码所含的API实体及其调用关系,在此基础上构建恶意代码API知识图谱。其次,使用Word2Vec技术计算携带上下文调用语义的API序列向量,借助TransE技术捕获API知识图谱中的API实体向量,将这两个向量的融合结果作为API特征。最后,将恶意代码所含的API表示为特征矩阵,输入TextCNN进行分类模型训练。在恶意代码家族分类任务中,与基线模型相比,所提方法的准确率有较大提升,达到93.8%,表明知识图谱可以有效增强恶意代码家族分类效果。同时,通过可解释性实验证实了所提方法具有应用价值。
关键词: 恶意代码; API序列; 语义抽取; 知识图谱; 可解释性
中图分类号: TP309.5
文献标志码: A
文章编号: 1671-6841(2025)02-0061-08
DOI: 10.13705/j.issn.1671-6841.2023165
Malware Classification Method Based on Knowledge Graph Enhancement
XIA Bing HE Qudong1,2, LIU Wenbo1,2, CHU Shihao1,2, PANG Jianmin3
(1.The Frontier Information Technology Research Institute, Zhongyuan University of Technology,
Zhengzhou 450007, China; 2.Henan Key Laboratory on Public Opinion Intelligent Analysis,
Zhengzhou 450007, China; 3.Key Laboratory of Mathematical Engineering and Advanced
Computing, Zhengzhou 450001, China)
Abstract: Aiming at the weak feature description ability and the lack of call relations in malware classification methods with application programming interface(API) sequences, a malware classification method based on knowledge graph enhancement was proposed. Firstly, on the basis of a function call graph, an API entity and its call relations contained in malware were extracted so as to construct an API knowledge graph for malware. Secondly, the Word2Vec technology was used to get an API sequence vector that was blended with context semantics, and the TransE technology was used to learn an API entity vector in the knowledge graph, then the blending result of the two vectors was used as the API feature. Finally, with the feature matrix that contained API, the classification model was trained on TextCNN. In the task of malware family classification, compared with the baseline models,the proposed method had a significant improvement in accuracy,reaching 93.8%, thus indicating that the classification effect of malware family could be effectively enhanced by such a knowledge graph. Meanwhile, the method was also confirmed of application value by the explainability experiment.
Key words: malware; API sequence; semantic extraction; knowledge graph; explainability
0 引言
根据国家互联网应急中心发布的《互联网安全威胁报告》,恶意代码引发的网络安全事件占比高达38%,对网络空间安全产生严重威胁[1]。因此,开展恶意代码检测工作意义重大。
开展恶意代码分类识别是恶意代码检测的一项基础工作。同一类别的恶意代码往往存在开发风格一致、代码复用等情况,这为基于特征的恶意代码静态检测提供了分类依据。静态检测不运行恶意代码样本,通过逆向工程提取文件所含函数参数、函数变量、函数调用关系和汇编指令等静态特征,利用训练好的检测模型,快速批量地分析恶意代码样本。依据恶意代码所在文件线性地址的先后顺序,可快速抽取内部调用的应用程序接口(application programming interface,API),进而生成恶意代码API序列。由于API序列信息具有一定程度的前后关联性,因此API序列能捕获恶意代码行为特征,进而实现恶意代码分类[2-3]。然而,上述方案无法完整捕获恶意代码行为,仅捕获了API先后顺序属性,存在特征表示能力弱和API间复杂调用关系缺失的问题。
针对上述问题,本文基于函数调用图抽取API实体及其调用关系,构建恶意代码API知识图谱,将具有可推理、可解释的知识表示学习应用到恶意代码分类中,提出一种基于知识图谱增强的恶意代码分类方法。实验结果表明,所提方法能提高恶意代码分类任务中的语义特征描述能力。主要贡献如下:1) 提出一种恶意代码知识图谱构建方法。基于预定义的8种恶意代码知识本体,设计一种API调用关系图实现方法,在此基础上抽取恶意代码实体和关系,采用三元组形式构建恶意代码知识图谱。2) 提出一种基于知识图谱增强的恶意代码分类方法。分别抽取API序列信息和API调用信息并生成嵌入向量,将两个向量融合拼接得到API知识图谱增强特征向量,输入TextCNN进行恶意代码分类模型训练。实验结果表明,所提模型的分类准确率达到93.8%。
1 相关工作
1.1 基于静态特征的恶意代码分类
常见的恶意代码种类包括病毒、蠕虫、木马和勒索软件等。准确描述恶意代码的行为特征是恶意代码静态检测的关键。乔延臣等[4]通过逆向技术获取恶意程序的汇编代码,将汇编指令看作词,函数看作句子,将每个恶意程序转化为一个文档,然后使用CNN实现恶意程序的分类。Nataraj等[5]将恶意代码文件映射为灰度图像,抽取图像的gist特征,并基于此特征使用K近邻算法进行分类。郎大鹏等[6]提出基于多特征融合的恶意代码分类方法,分别提取灰度共生矩阵、操作码序列、操作码3个特征后用随机森林分类器实现分类。Huang等[7]提取恶意代码的一致执行序列、软件基因、指令序列、控制流图和调用图等特征,借助图卷积神经网络实现恶意代码检测。
API是系统链接库中预先定义的函数,操作系统在执行内存分配、系统资源管理等行为时,通常通过API来操作。因此,API调用序列在一定程度上可以表示恶意代码的行为特征。Salehi等[2]将恶意代码中的API及API参数作为分类特征,采用降维方法与多元分类器实现恶意代码分类。Zhang等[3]将恶意代码的API及其对应的参数和类别作为输入特征,采用多个门控CNN和BiLSTM学习API调用之间的序列相关性,进而实现恶意代码分类。Li等[8]使用沙箱技术抽取API序列,借助LSTM模型学习恶意代码API序列特征。于媛尔等[9]融合程序的敏感权限信息和敏感API信息构建特征库,使用随机森林算法实现恶意软件家族分类。
1.2 基于知识图谱的软件安全分析
知识图谱是一种基于图的数据结构,由节点和边组成,节点表示实体,边表示实体间关系。知识图谱能够很好地表示实体、概念、客观事实及其之间的关系,具有可推理、可解释等特点。从知识涵盖的领域来看,知识图谱分为通用知识图谱和领域知识图谱,本文构建的恶意代码知识图谱属于领域知识图谱。
知识图谱的技术优势已在软件安全分析和分类任务中得到应用。王婷等[10]将文本实体链接到外部知识库实现实体增强表示,提出了一种基于知识增强的文本分类方法。王乐[11]通过提取NVD和CVE数据库的漏洞类型、源代码、供应商等数据构建软件漏洞知识图谱,借助知识图谱链式推理技术,提出一种基于知识图谱的软件安全漏洞挖掘方法。Chowdhury等[12]提出一种基于知识图谱的恶意代码行为捕获方法,所构建的知识图谱包含样本类型、行为、恶意代码家族、代码结构等信息。Bai等[13]提出一种通过API知识图谱检测安卓恶意代码变种的方法,依据API调用关系构建API知识图谱,用于检测安卓恶意代码变种。
2 恶意代码知识图谱构建
2.1 本体及关系定义
构建知识图谱首先要定义本体及其之间的关系。本体是知识图谱中的概念,可以将其理解为一类实体的集合,其描述了现实存在的事物。实体间存在的各种内在关联用关系来描述,图谱中丰富的关系有助于发掘深层知识和语义理解[14]。
2.1.1 本体定义
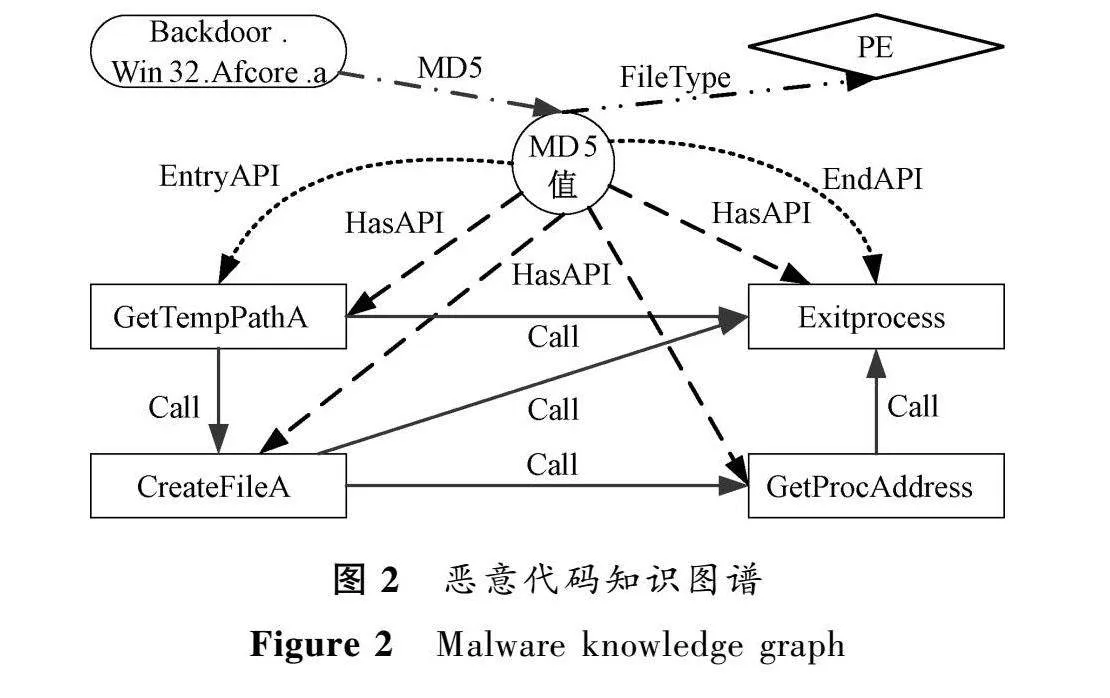
API调用之间的关系可以描述恶意代码行为,因此以API调用关系为基础构建了8种知识图谱本体。1) FileName本体:待分析样本的名称,将样本名放到图谱中是为了增加样本的描述信息。2) FileType本体:文件类型,主要包括PE、ELF、MS-DOS,不同系统上的恶意代码具有不同的链接库和不同的交互逻辑等特征。3) MD5本体:样本MD5值,由于文件名可能会重复或者命名不规范,因此用样本MD5值作为该样本的唯一标识。4) Caller_API本体:对于某个API,其前驱API函数称为Caller。5) Callee_API本体:对于某个API,其后继API函数称为Callee。通过Caller_API和Callee_API这两个本体可以清晰地描述某个API调用的前后关系。6) API_Name本体:Caller_API和Callee_API统称为API_Name,这些API名称可以清晰地表达恶意代码的操作行为。7) EntryAPI本体:API调用图的入口API。8) EndAPI本体:API调用图的结束API。EntryAPI和EndAPI描述了API调用的起始关系。
2.1.2 关系定义
恶意代码的8种本体间存在关联关系,这些关系清晰地表达了恶意代码行为,有助于恶意代码分类。恶意代码三元组如表1所示,显示了所建立的6种恶意代码本体间的关系。
表1所示的三元组在样本名称与样本MD5值间建立一一对应关系,即以MD5值作为样本的唯一标识;HasAPI关系连接了样本中的所有API;FileType表示该样本的文件类型;Call表示API间的调用与被调用关系;EntryAPI表示该样本的入口API;EndAPI表示该样本的结束API。建立上述关系后,采用三元组方式表示恶意代码分析结果。
2.2 API调用关系图构建
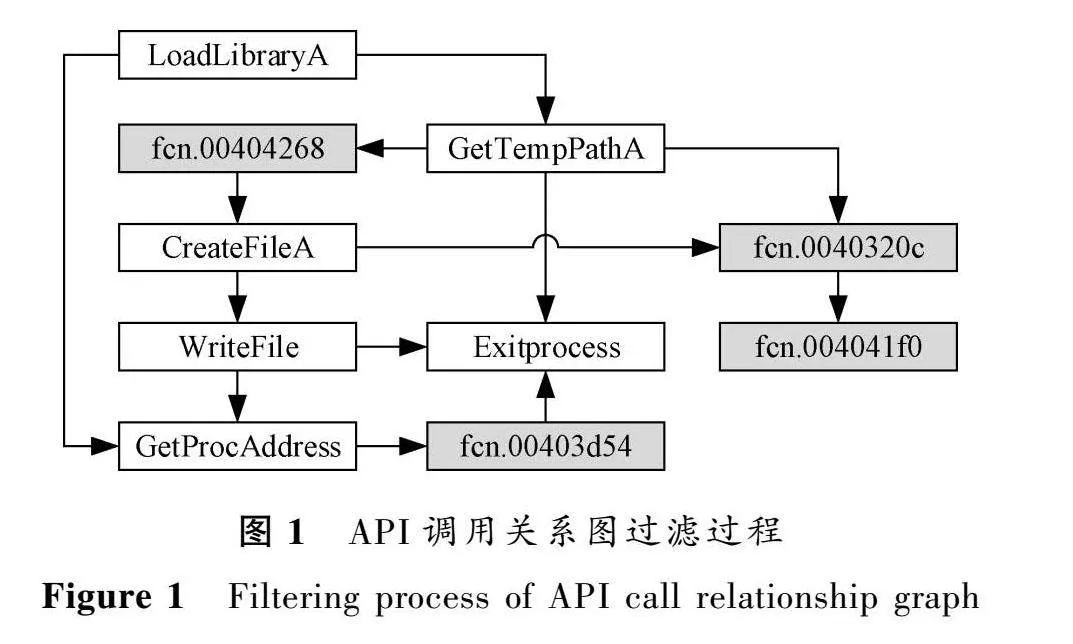
API调用关系是恶意代码知识图谱的核心。由于现有工具能分析出恶意代码的函数调用图以及函数内部的控制流图(control flow graph,CFG),但无法给出API的调用关系图。因此,基于函数调用图提出一种构建API调用关系图的方法。API调用关系图过滤过程如图1所示,显示了样本“Backdoor.Win32.Afcore.a”的API调用关系图构建过程,具体步骤如下。
Step 1 通过逆向分析生成函数调用图。
Step 2 对函数调用图中的每个函数进行如下操作:1) 获取函数CFG,将基本块视为节点,判断节点中是否包含API调用。2) 对不包含API调用的节点N跳转到3)。3) 分析节点N的前驱和后继,将节点N的前驱节点定义为N_P,后继节点定义为N_C。若存在节点N_C且含API调用,则将节点N_C作为节点N_P的直接后继,并删除节点N;若不存在节点N_C,则直接删除节点N。4) 反复上述过程直到遍历所有节点。如果存在生成的API图则替换该函数,否则从函数调用图中删除该函数。
Step 3 遍历完所有函数则停止,否则执行Step 2。这样就得到了恶意代码的API调用关系图。
用户自定义函数在编译过程中通常会被剥离,并用类似“fcn.00404268”的名称代替,在分析时并不清楚该函数的名称,不利于分析恶意代码的语义。因此,在构建API调用关系时过滤掉用户自定义函数。如图1中的“GetTempPathA-fcn.00404268-CreateFileA”这条调用关系,在实现过程中删除了灰色的“fcn.00404268”用户自定义函数,将“GetTempPathA”和“CreateFileA”直接连接。
2.3 恶意代码知识抽取
在知识图谱中,知识越丰富则知识表示学习的效果越好。恶意代码的FileName、FileType、MD5知识可利用逆向工具分析得到,如样本“Backdoor.Win32.Afcore.a”的文件类型是“PE”,MD5值为“10586070da6e1859b5b6dab5efae60f2”。对于Caller_API、Callee_API、API_Name、EntryAPI、EndAPI知识,则需要从2.2节中构建的API调用关系图中抽取。为此,基于API调用关系图给出一种恶意代码知识抽取算法。
算法1 恶意代码知识抽取算法
输入: Binary Malware
输出: Knowledge_List
1. Knowledge_List=[]
2. API_Three_Tuple=[]
3. Des=Read describe from Malware.elf
4. G=API Call Relation Graph
5. for API in G do
6. API_Three_Tuple.append(caller+callee+API_Name+EntryAPI+EndAPI)
7. end for
8. Knowledge_List.append(Des+API_Three_Tuple)
9. return Knowledge_List
根据算法1描述,输入为二进制恶意代码样本。算法第4行为构建的API调用关系图,每个节点为一个API,前驱API称为Caller,后继API称为Callee。算法第5~7行从API调用关系图入口开始,遍历每个节点及其后继节点,即Caller和所有Callee。将每个Callee与调用它的Caller、API_Name、EntryAPI和EndAPI合并,就得到所有API调用三元组。最后,结合样本描述得到该样本的所有知识。
2.4 API序列提取
Salehi等[2]和Zhang等[3]提出的方法表明,API序列在一定程度上可以描述恶意代码的行为特征。为验证提出的恶意代码知识图谱对恶意代码分类方法有性能提升,进行了基于API序列的恶意代码分类实验,但是所提取的API序列不用于知识图谱构建。
借助函数执行路径来抽取API序列会引发路径爆炸或循环调用等问题,因此依据文件线性地址建立API序列。使用逆向分析工具Radare2分析二进制恶意代码样本,通过工具中的“afl”功能抽取并过滤出样本中的所有API及其线性地址;再根据线性地址的先后顺序对API进行排序,得到样本的API序列;最后在分类标签和API序列之间建立关联。
2.5 恶意代码知识图谱构建
完成恶意代码知识抽取后,需要将其存储为结构化数据,接着将结构化数据中的实体、关系与相关的本体概念对应,生成恶意代码知识图谱三元组,最后将三元组存储到Neo4j图数据库,完成恶意代码知识图谱构建。图2为构建的恶意代码知识图谱。
3 基于知识图谱增强的恶意代码分类方法
3.1 总体设计
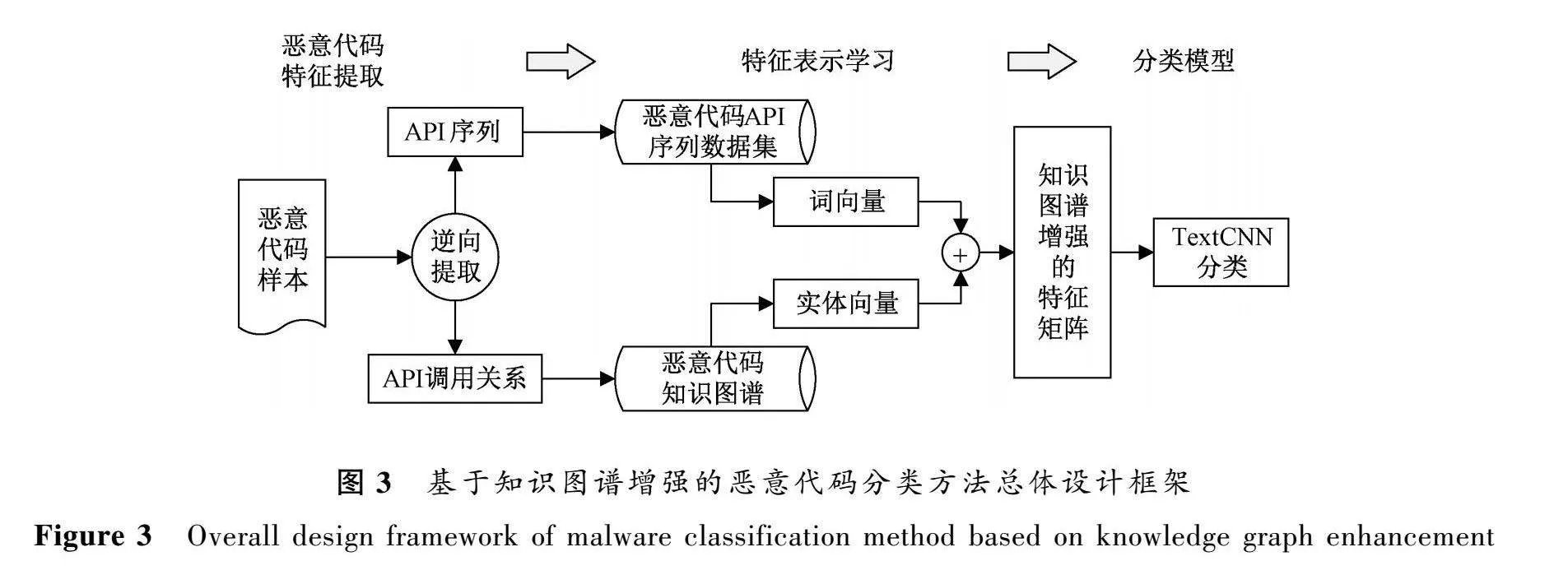
基于知识图谱增强的恶意代码分类方法总体设计框架如图3所示,由恶意代码特征提取、特征表示学习和分类模型3个部分组成。首先通过逆向工程提取恶意代码样本中的API序列和API调用关系,接着将API以地址的先后顺序作为排序依据,建立恶意代码API序列数据集。将API调用关系、恶意代码类型、样本名等信息及其之间的关系作为知识,建立恶意代码知识图谱,再使用Word2Vec技术将恶意代码序列特征数据集中的每个API转为词向量,使用TransE技术将知识图谱中的每个实体转为实体向量,实现一个API在两个向量空间中的表示。然后,将两个向量拼接为一个向量,得到知识图谱增强的恶意代码特征矩阵。最后,以该特征矩阵作为输入,构建TextCNN网络,训练恶意代码分类模型。
3.2 特征表示学习
3.2.1 API序列向量化
Word2Vec[15]是谷歌公司提出的一种词嵌入模型,实现了将词转化为可计算的、融合上下文的语义向量。因此,通过向量的余弦距离可以衡量词之间的相关性。由于Word2Vec生成的是静态向量,具有很好的通用性,可移植到不同的任务中,所以采用该技术作为词嵌入模型。
Word2Vec有CBOW和Skip-gram两种训练模式,前者通过上下文来预测中间词,后者通过中间词来预测上下文。CBOW模式更适合小型语料库,而Skip-gram模式在大型语料库中表现更好。由于所选用的数据集词典长度在5 000以内,因此采取CBOW模式训练词向量。本文方法中的词为API序列中的每一个API。
3.2.2 知识图谱表示学习
知识表示学习将知识图谱中的实体和关系嵌入向量空间,使实体和关系变成可计算的低维稠密向量[16],得到的向量表示结果可应用于语义增强、知识推理等场景。
知识图谱通常采用三元组方式来表示,即[头实体head,关系relation,尾实体tail]的形式,简写为[h,r,t]。选取Bordes等[17]提出的TransE模型作为知识表示学习模型,其原因在于该模型将每个三元组中的关系r看作从头实体h到尾实体t的翻译,通过不断调整h、r、t,使得(h+r)尽可能地逼近t,越接近则三元组的嵌入效果越好。与此同时,TransE模型参数少,计算复杂度低,语义表示能力强。
在实际学习过程中,为了增强知识表示的区分能力,TransE模型采用最大间隔方法[18],定义的优化目标函数为
L=∑(h,r,t)∈S
∑(h′,r′,t′)∈S-
max(0, fr(h,t)+γ-fr′(h′,t′)),(1)
式中:S为正确三元组集合;S-为错误三元组集合;max(x,y)返回x,y中较大的值;γ为正确三元组得分与错误三元组得分之间的间隔距离。S-是利用TransE将S中每个三元组的h、r、t其中之一随机替换为其他实体得到的。
3.3 恶意代码分类模型
3.3.1 特征矩阵
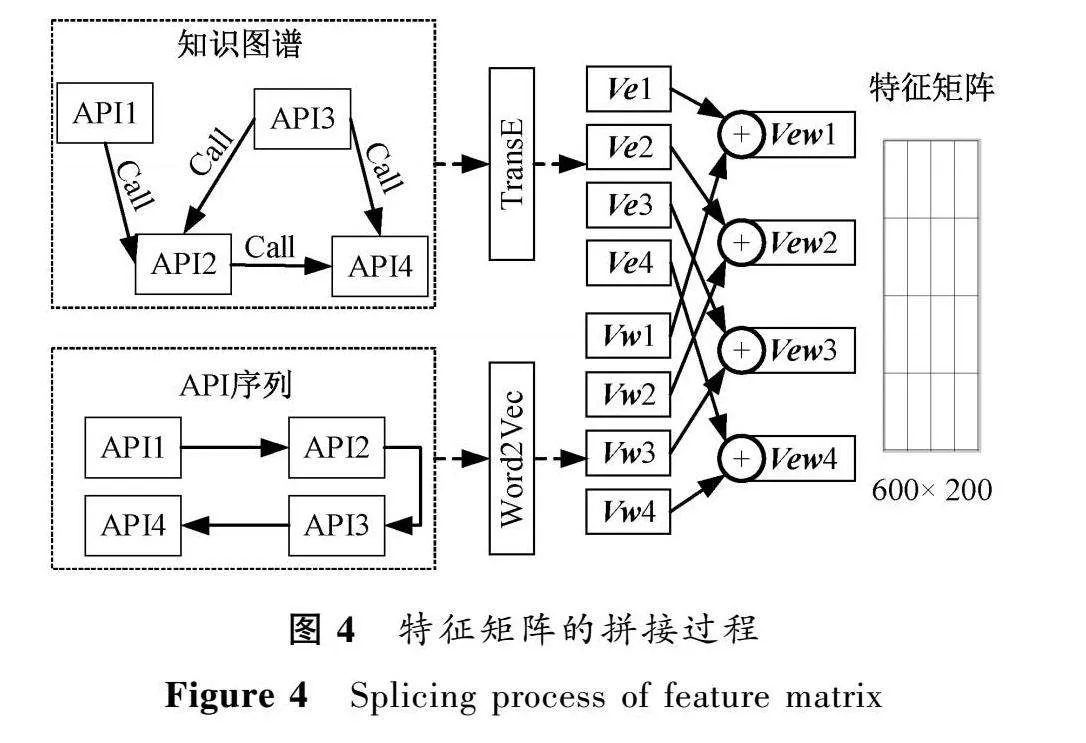
恶意代码分类模型的输入是一个特征矩阵,由恶意代码API序列中的词向量和知识图谱中的实体向量拼接而成。其中,词向量采用Word2Vec技术将API序列嵌入向量空间,维数dim为100,用Vw表示;实体向量采用TransE技术来对恶意代码知识图谱进行表示学习,将三元组中的每个实体及其关系嵌入向量空间,维数dim为100,用Ve表示。特征矩阵的拼接过程如图4所示。
首先检索API序列,从Word2Vec模型中取出API的向量Vw,从TransE模型中检索该API在知识图谱中的向量Ve,接着将Vw与Ve进行拼接,得到维数dim为200的知识图谱增强的特征向量Vew。以上述方式遍历一个样本的所有API,最后形成尺寸为n×200的特征矩阵,作为深度学习模型的输入。特征矩阵计算过程可表示为
FeatureMatrix=∑n=1(Vwn+Ven),(2)
式中:Vwn表示API序列中的第n个API词向量;Ven表示该API在知识图谱中的实体向量。
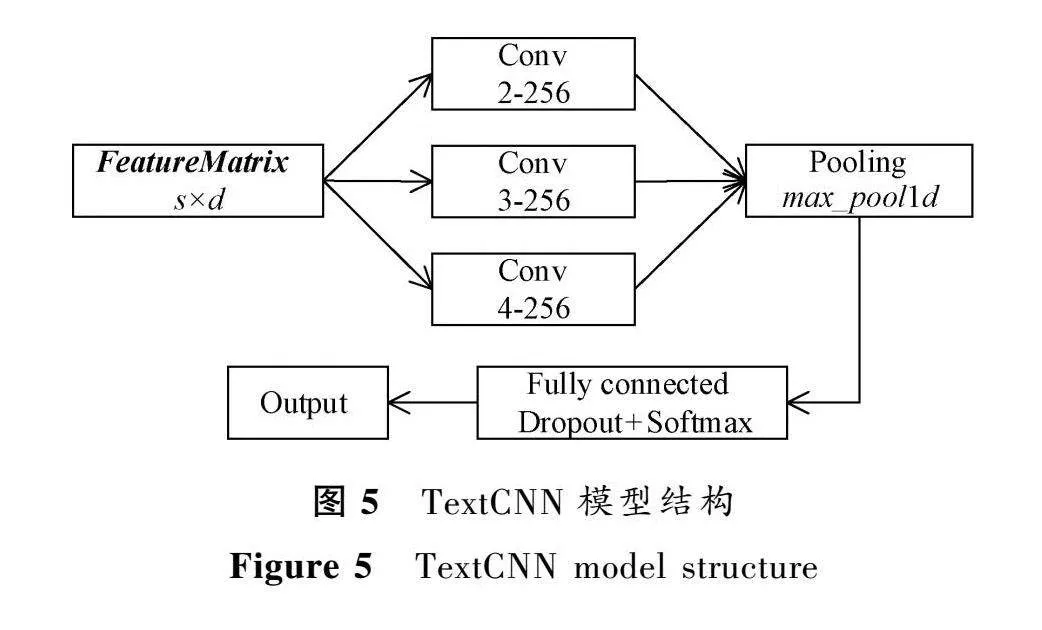
3.3.2 模型结构
TextCNN是由Kim[19]提出的文本分类模型,与传统的应用于计算机视觉的CNN模型相比,TextCNN对模型的输入层进行了一些变形,使文本能够以特征矩阵的形式输入神经网络。TextCNN模型结构如图5所示。模型输入是一个s×d的特征矩阵,其中:s表示文本序列中词的数量;d代表向量的维数。模型包含卷积层和池化层,最后连接一个带Softmax的全连接层。
在卷积层中,设置卷积核的尺寸分别为2、3、4,卷积核数量为256。使用3个尺寸的卷积核,保证了每次滑动的位置都是一个API的完整特征,从而全面学习特征矩阵的语义信息。卷积过程可表示为
y=LeakyReLU∑s-h+1i=1W×A[i:i+h-1]+b,(3)
式中:W表示卷积核;h为卷积核的高度;A[i:i+h-1]表示特征矩阵A的第i行到第i+h-1行;b为偏置;LeakyReLU为激活函数。
在池化层中,采用最大池化max_pool1d进行池化操作,将每一个卷积层输出的向量都通过最大池化方法映射为一个具体的数值,然后再将池化后的结果进行合并,得出一个全新的特征向量,用作全连接层的输入。
在全连接层中,将所有特征图堆叠成一个长度固定的特征向量,并应用Dropout来保持特征不变性并防止过拟合。模型输出采用Softmax分类器,其输出是分类标签的概率分布。
通过监督学习的方式训练模型,模型训练的损失函数可表示为
loss=-1N∑i∑Cc=1yi,cpi,c,(4)
式中:N为样本总数;C为分类任务中的类别数;pi,c为样本属于类别c的概率;若样本分类预测正确则yi,c为1,不正确则为0。
4 实验与结果分析
4.1 数据集
实验使用VxHeaven[20]恶意代码数据集,从中选出Hupigon、Buzus、Small、OnLineGames、Delf、Agent和Vapsup 7个恶意代码家族。为避免数据量带来的误差,每个家族随机选取1 000个左右的样本,使每个家族恶意代码数量基本持平。训练时,将数据集的80%作为训练集,10%作为测试集,10%作为验证集。
4.2 基线方法与评价指标
为评价模型在恶意代码分类任务上的性能,引入文献[8]和文献[21]中典型模型作为基线对比。其中,文献[8]采用LSTM模型,训练数据为API序列;文献[21]采用逻辑回归模型,训练数据为TF-IDF值和API序列。
经统计发现,95%的API序列长度在600个词以内,因此实验模型固定序列长度为600。词向量维数dim为100,每个知识的维数dim为100。为评估恶意代码分类性能,采用准确率、精确率、召回率和F1值作为模型的评价指标。
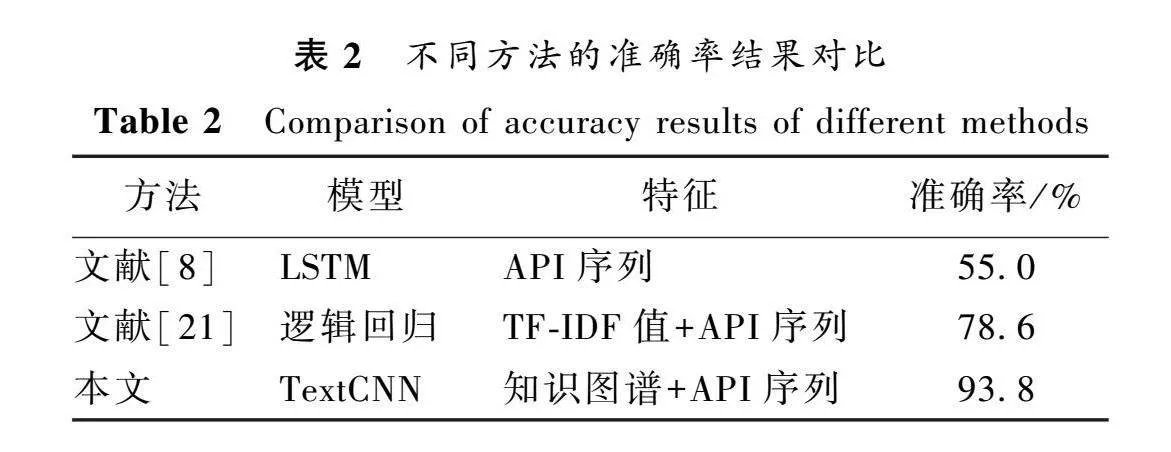
4.3 模型准确率对比
为验证本文所提出的将知识图谱与API序列融合的方法能够提高恶意代码分类准确率,与采用API序列及加其他特征的方法进行了对比,不同方法的准确率结果对比如表2所示。可以看出,与本文方法相比,文献[8]和文献[21]的准确率均有所减少。这表明引入知识表示学习的API调用关系更好地描述了恶意代码的行为,增强了恶意代码语义特征的描述能力,进而提升恶意代码分类准确率。
4.4 消融实验
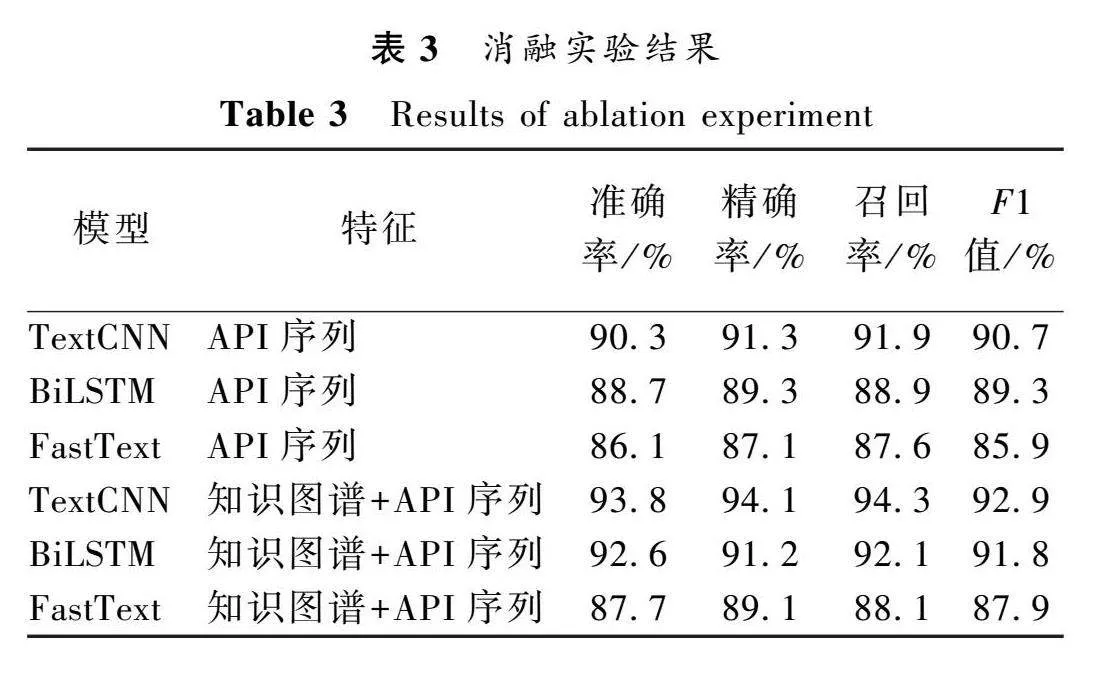
选取了文本分类中常用的TextCNN、BiLSTM和FastText模型进行了恶意代码分类预测消融实验,将“API序列”和“知识图谱+API序列”两种特征进行对比分析,消融实验结果如表3所示。在两种特征下,TextCNN模型均取得了最好的实验效果,鉴于此,实验均采用该模型进行。在TextCNN模型中,单纯使用API序列作为特征时,分类准确率为90.3%,加入知识图谱后,分类准确率有所提升。实验结果表明,知识图谱提升了恶意代码分类的准确率。
4.5 可解释性实验
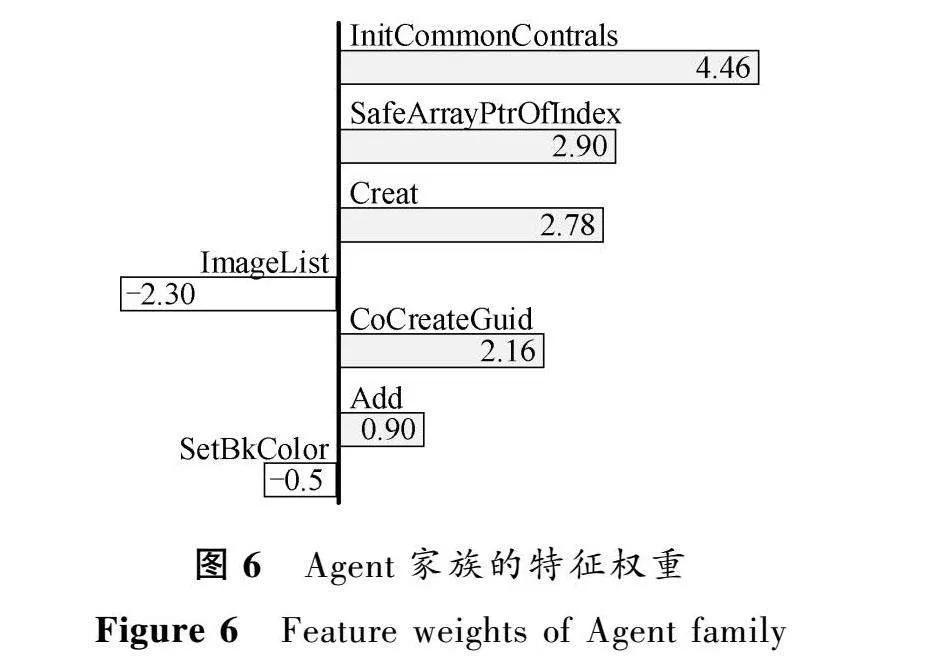
同一家族或同一类型的恶意代码,往往具有特定API行为特征。为探究是哪些API对恶意代码分类结果产生了影响,采用可解释性预测模型LIME[22]。以API序列和训练后的TextCNN分类模型作为输入,进行可解释性实验。Agent家族的特征权重结果如图6所示,由上至下为该类别中对分类结果影响权重最大的API排序。
以Agent家族的恶意代码为例,InitCommonContrals、SafeArrayPtrOfIndex、Creat、CoCreateGuid、Add这5个API对分类结果产生了最大的正影响,拥有这5个API的样本被分类为Agent家族的概率较大。ImageList、SetBkColor这2个API对分类结果产生了最大的负影响,即包含这2个API的样本被分类为Agent家族的概率较小。
通过人工分析发现,InitCommonContrals函数实现了通用控件的初始化;SafeArrayPtrOfIndex函数可以获取指向数组元素的指针;CoCreateGuid函数通过调用RPC功能的函数UuidCreate来创建GUID;Creat是C语言中的函数,用来创建文件;Add函数实现了内容的增加。这些函数的组合实现了文件创建和内容增加,并通过远程过程调用实现数据传输,属于典型的木马行为。综上所述,本文提出的恶意代码分类方法行之有效,具有实际应用价值。
5 结语
本文针对当前基于API序列的恶意代码分类任务无法完整捕获行为特征的不足,提出一种基于知识图谱增强的恶意代码分类方法。实验结果表明,引入知识表示学习的API调用关系和API序列两种特征的结合,可以更好地描述恶意代码的行为,增强恶意代码语义特征的描述能力,提升恶意代码分类的效果。下一步研究计划通过虚拟机捕获隐含的API调用关系,丰富与完善恶意代码知识图谱,融合二进制代码指令行为特征和图神经网络,进一步提升恶意代码分类效果。
参考文献:
[1] 国家互联网应急中心.互联网安全威胁报告[EB/OL].[2023-06-23].https:∥www.cert.org.cn/
publish/main/upload/File/CNCERT-report202201.pdf. 2022.
CNCERT. Internet security threat report[EB/OL]. [2023-06-23]. https:∥www.cert.org.cn/publish/main/upload/File/CNCERT-report202201.pdf. 2022.
[2] SALEHI Z, GHIASI M, SAMI A. A miner for malware detection based on API function calls and their arguments[C]∥Proceedings of the 16th CSI International Symposium on Artificial Intelligence and Signal Processing. Piscataway:IEEE Press, 2012: 563-568.
[3] ZHANG Z Q, QI P P, WANG W. Dynamic malware analysis with feature engineering and feature learning[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2020: 1210-1217.
[4] 乔延臣, 姜青山, 古亮, 等. 基于汇编指令词向量与卷积神经网络的恶意代码分类方法研究[J]. 信息网络安全, 2019(4): 20-28.
QIAO Y C, JIANG Q S, GU L, et al. Malware classification method based on word vector of assembly instruction and CNN[J]. Netinfo security, 2019(4): 20-28.
[5] NATARAJ L, KARTHIKEYAN S, JACOB G, et al. Malware images: visualization and automatic classification[C]∥Proceedings of the 8th International Symposium on Visualization for Cyber Security. New York: ACM Press, 2011: 1-7.
[6] 郎大鹏, 丁巍, 姜昊辰, 等. 基于多特征融合的恶意代码分类算法[J]. 计算机应用, 2019, 39(8): 2333-2338.
LANG D P, DING W, JIANG H C, et al. Malicious code classification algorithm based on multi-feature fusion[J]. Journal of computer applications, 2019, 39(8): 2333-2338.
[7] HUANG Y Z, QIAO M, LIU F D, et al. Binary code traceability of multigranularity information fusion from the perspective of software genes[J]. Computers & security, 2022, 114: 102607.
[8] LI C, ZHENG J J. API call-based malware classification using recurrent neural networks[J]. Journal of cyber security and mobility, 2021: 617-640.
[9] 于媛尔, 张琳琳, 赵楷, 等. 基于敏感权限和API的Android恶意软件家族分类方法[J]. 郑州大学学报(理学版), 2020, 52(3): 75-79, 91.
YU Y E, ZHANG L L, ZHAO K, et al. Android malware family classification method based on sensitive permissions and API[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(3): 75-79, 91.
[10]王婷, 朱小飞, 唐顾. 基于知识增强的图卷积神经网络的文本分类[J]. 浙江大学学报(工学版), 2022, 56(2): 322-328.
WANG T, ZHU X F, TANG G. Knowledge-enhanced graph convolutional neural networks for text classification[J]. Journal of Zhejiang university (engineering science), 2022, 56(2): 322-328.
[11]王乐. 基于知识图谱的软件安全漏洞挖掘技术研究[D]. 西安: 西安工业大学, 2021.
WANG L. Research on software security vulnerability mining technology based on knowledge graph[D]. Xi′an: Xi′an Technological University, 2021.
[12]CHOWDHURY I R, BHOWMIK D. Capturing malware behaviour with ontology-based knowledge graphs[C]∥IEEE Conference on Dependable and Secure Computing. Piscataway:IEEE Press, 2022: 1-7.
[13]BAI Y D, CHEN S, XING Z C, et al. ArgusDroid: detecting Android malware variants by mining permission-API knowledge graph[J]. Science China information sciences, 2023, 66(9): 192101.
[14]昝红英, 窦华溢, 贾玉祥, 等. 基于多来源文本的中文医学知识图谱的构建[J]. 郑州大学学报(理学版), 2020, 52(2): 45-51.
ZAN H Y, DOU H Y, JIA Y X, et al. Construction of Chinese medical knowledge graph based on multi-source corpus[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(2): 45-51.
[15]MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL].[2022-12-21]. https:∥doi.org/10.48550/arXiv.1301.3781.
[16]刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 247-261.
LIU Z Y, SUN M S, LIN Y K, et al. Knowledge representation learning: a review[J]. Journal of computer research and development, 2016, 53(2): 247-261.
[17]BORDES A,USUNIER N,GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data [J]. Advances in neural information processing systems, 2013:2787-2795.
[18]王昊奋, 漆桂林, 陈华钧. 知识图谱: 方法、实践与应用[M]. 北京: 电子工业出版社, 2019.
WANG H F, QI G L, CHEN H J. Knowledge graph:methods,practices,and applications [M]. Beijing: Publishing House of Electronics Industry, 2019.
[19]KIM Y. Convolutional neural networks for sentence classification[C]∥Proceedings of the Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 1746-1751.
[20]VxHeaven Dataset[EB/OL].[2023-06-12]. https:∥1vx.ug/archive/Vx-Heaven.
[21]周杨. 基于行为特征的Windows恶意代码检测与分析[D]. 北京: 中国人民公安大学, 2021.
ZHOU Y. Windows malicious code detection and analysis based on behavior characteristics[D]. Beijing: Chinese People′s Public Security University, 2021.
[22]RIBEIRO M T, SINGH S, GUESTRIN C. "Why should I trust You?": explaining the predictions of any classifier[C]∥Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2016: 1135-1144.
