
标准数字化平台技术路径研究
2024-12-31 00:00:00顾鑫徐术坤张晨鸣刘颖顾利平涂俊李响
中国标准化 2024年19期
关键词:知识图谱
摘 要:随着数字技术和信息技术的迅速发展,标准数字化平台逐渐成为标准化领域的重要工具。本文根据ISO的SMART标准数字化成熟度划分方法,探索level 3-4的标准数字化平台技术实现路径,重点介绍了标准大模型实现知识图谱、智能问答功能的实现方法,为后续研究提供了基础。
关键词: 标准数字化,成熟度模型,知识图谱
DOI编码:10.3969/j.issn.1002-5944.2024.19.008
0 引 言
近年来,数字技术和信息技术的迅速发展,标准数字化平台逐渐成为标准化领域的重要工具。标准数字化平台是一种将标准文献、标准规范、标准数据等标准化资源进行数字化、网络化、智能化管理的技术平台,旨在提高标准的制定、实施和管理效率,促进国家质量基础设施的数字化转型[1],标准数字化平台建设对数字中国发展有着重要的战略意义。《国家标准化发展纲要》《质量强国建设纲要》等顶层规划文件中,均提出要发展新型标准化工具,探索建立全国统一协调、分工负责的标准数字化公共服务平台,为各方广泛参与标准化工作提供有效途径。
1 标准数字化平台现状
国外标准数字化平台的发展可以追溯到20世纪90年代。美国国家标准局(ANSI)于1993年建立了数字图书馆,旨在将国家标准转化为数字格式,并免费向公众提供。此后,许多国家和标准化组织也开始意识到标准数字化的重要性,并开始建立自己的标准数字化平台[2]。目前,国际标准化组织(ISO)和欧洲标准化协会(ESA)已经建立了自己的标准数字化平台,分别为ISOReference Platform(ISO-RF)和ESA-RF。ISO-RF是一个开放的平台,旨在为全球标准化组织提供标准文献、标准规范、标准数据等的数字化服务。ESA-RF是一个专门为欧洲标准化组织服务的平台,提供标准文献、标准规范、标准数据等的在线检索、下载、管理等服务。除了国际标准化组织之外,许多国家和标准化组织也建立了自己的标准数字化平台。例如,中国国家标准化管理委员会(SAC)建立了国家标准数字图书馆,提供了国家标准文献、标准规范、标准数据等的数字化服务。此外,日本、韩国、澳大利亚、加拿大等国家和标准化组织也建立了自己的标准数字化平台。
国内标准数字化平台的发展相对较晚,但发展速度较快。2000年,中国国家标准化管理委员会(SAC)建立了国家标准文献数据库,提供国家标准文献的数字化服务。此后,国内标准化组织也陆续建立了自己的标准数字化平台。目前,国内已经建立了多个标准数字化平台[3],例如,中国标准化协会(CAS)建立的中国标准数字图书馆、中国标准化研究院(CNIS)建立的中国标准文献信息平台、中国电子信息产业发展研究院(CESI)建立的中国标准信息服务平台等。这些平台提供标准文献、标准规范、标准数据等的数字化服务,并具有检索、下载、管理等功能。
2 发展与挑战
国内外标准化组织都积极建立自己的标准数字化平台,为标准化文献、标准规范、标准数据等的数字化服务提供支持。但标准数字化是一个长期而复杂的任务。随着数据量的不断增长,标准的数据要素构成涵盖越来越多,标准数字化面临着越来越大的挑战[4]。一是数字标准化中的重点技术是机器可读,需要规范地描述数据结构和内容格式,但目前各行业机器可读标准还没有统一的定义和分类,这导致了标准数字化难以实现。二是标准数字化要广泛应用,还需结合多个领域,如法律、技术和业务,这使得标准数字化的研究变得更加困难。三是标准数字化除了可读外,还需要正确被机器理解,能根据复杂场景输出可用的结构化文本信息,结合智能AI模型进行应用研究,复杂性地对较高,需要投入大量的人力、物力和财力,这使得许多组织望而却步。
因此,如何建立一个高效、丰富、全面的标准数字化平台就成了助力标准化高质量发展、助推新质生产力的关键问题。
3 标准数字化成熟度模型
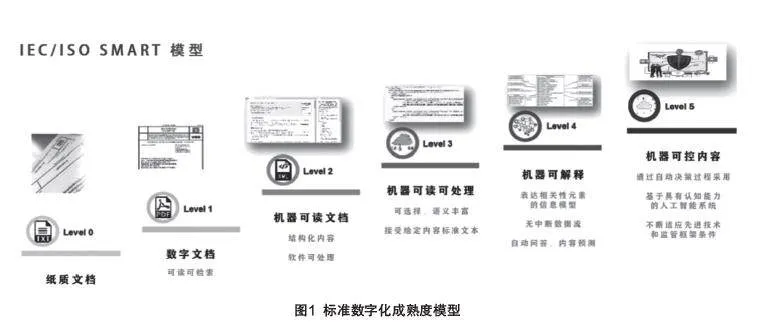
如何实现标准的机器可读是实现标准数字化平台的关键问题。一般来讲,研究机器可读离不开分级模型,可利用计算机技术和人工智能技术,为机器可读标准提供分类和分级的框架。在标准领域,针对标准的特殊性,ISO的SMART标准提供了一种标准数字化成熟度级别划分,它将机器可读融入到标准数字化技术各个阶段,体现了标准数字化和标准的机器互操作性的关联关系,基本为未来标准机器可读制定了明确的技术路线图,也是标准数字化发展路线的重要依据,如图1所示。
标准数字化成熟度分级中,level_0表示传统的纸质标准,没有和机器相交互。level_1表示电子化的文档,可以在计算机上展示内容,比如我们现在常用的pdf版的电子标准。Level_2表示机器可读文档,这些文档内容经过数据处理加工,成为结构化的信息文本;这两级标准代表着标准可以实现形式信息化和基本字符的定位,目前来说,2级水平也是国际标准和部分先进国家标准普遍能达到的级别。Level_3表示机器可读和可执行内容。这个级别重点突出了信息元素之间的关联关系,可以实现多目标关联,根据不同需求对跨文档的内容进行加工处理。Level_4表示机器可解释内容,能学习分析和自动验证,实现智能推送,问题回答等功能;这两级主要侧重标准语料的含义分析,以及相关联信息知识的获取与学习,比如,DIN基于自身的产业实践探索,按照XML多标签的方式,将已有标准构建成“机器可读”的程度,达到了3-4级。Level_5表示机器可控内容,实现在数字标准方面具有认知能力的人工智能系统,可以根据标准内容的修订,自动决策过程采用。Level_5级属于远期的目标,目前处于理论探索阶段。这0到5级成熟度模型中,机器对于信息数据分类细化和智能化要求逐步提高。因国内标准机构发展水平不均,总体数字化水平还处于1-2级标准,投入力度大的平台,如国家标准馆、中国标网、中国知网等已在专业领域开展3-4级标准数字化的探索。
4 标准数字化平台建设技术路径
标准数字化平台实现关键在于底层标准数据的处理和知识库的建立。已有研究表明,数据处理技术路径可以为:数字化、结构化、知识化、网络化、图谱化[5]。其本质是在明确标准数据的完整性、准确性、关联性、可读性的基础上,实现标准数据的知识化、协同化、交互化、智能化等要求。
本研究简化了数据知识库的获取方式,采用json格式作为基础,通过信息采集、数据清洗、图谱生成三个数据处理过程,外加使用采用自回归空白填充的自监督训练方式,实现从电子化文档到知识库的转化。信息化时代的标准文本加工,已经让大部分纸质标准转化成了pdf电子档,所以本研究在采集过程中,主要针对还未经过ORC识别标准电子文本,将符合要求的标准电子版标准作为信息采集过程的输入,采集过程解决标准文本的信息化和结构化问题。数据清洗过程针对信息采集过程的输出,利用规则将标准数据进行加工并整合打上标签,形成json条目的干净数据,完成标准数据知识化和关系立体化。图谱生成过程主要将形成的语料进行关联性分析,构建知识库,完成标准数据图谱化。最后利用自回归空白填充模型的自监督训练方式搭建标准大模型,用于支撑标准智能化中对比分析、智能填写、智能问答等标准数字化平台功能。下文将针对部分内容进行重点说明。
4.1 标准数据清洗加工
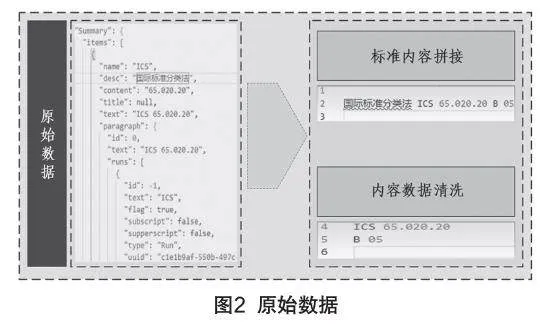
本研究中数据清洗主要是对OCR处理后的数据进行筛选、转换、合并、去重的过程,此过程可以消除数据中的错误、缺失、重复、异常等问题。数据清洗主要根据筛选规则,利用Pandas工具,将问题数据去除,实现对ORC后标准数据的重新检查和校验,提高数据质量。基于传统技术文档的电子版标准多通过图片或pdf文档转换而来,内容存在大量不可读标签、文本等,其内容无法直接使用,该过程基本步骤为:数据收集、数据预处理、数据清洗、数据验证。通过这几步,可以将脏数据清洗为可用的原始数据。如图2所示。
从图中可见,在采集标准ICS和CCS码信息时,数据采集端的输入数据包含很多无用的标签信息和非必要元素,目标信息被隔离分散。因此,经过数据清洗后,需要提取全部有效数据,然后通过规则将目标信息内容提取拼接。对于此类数据,常用的判断规则可参考“国际标准分类法”中ICS与CCS的固定格式,判断其内容的含义。经过类似清洗拼接过程,最终获得有效的结构化数据,还可以通过规则定义,解析出其它有含义的信息,如:图片、表格、指标项、公式等信息。
在此基础上,对最终数据进行初步的标记分类,记录在json文件中,形成可用的“语料”,为后期构建标准大模型提供有效输入。利用json架构标识时,应考虑层次、要素的多对多关系,有了合理的架构设计,才能提高标识的效率。一是要明确目的,要确定结构化标准的分类方式,如基础标准、管理标准、技术标准等,以此来明确标准内容所包含的内容要素。二是要根据不同分类的标准构成要素的关联关系,形成可以覆盖属性、要素、特殊要求等关键信息,能够反映标准内容的结构关系。三是要定义json标识,简洁、明确,且相互之间确保唯一性,能快速识别。目前该过程初始标识需要手动完成,后续在数据使用中,可以利用训练学习,对已有数据增加标识。
4.2 知识图谱构建
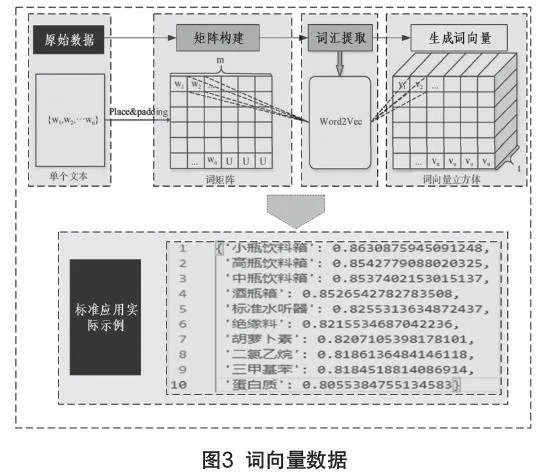
构建知识图谱一直以来有较多学者研究,传统的方法是将标准信息解构后,按照人员、单位、引用关系、系列文本、体系覆盖等因素作为关联关系,将众多标准相关联形成图谱。而本研究主要支撑标准数字化平台的智能问答功能,最终要形成一段语义丰富、内容准确的智能回复,因此采用简单化神经网络Word2Vec模型来构建语料间的知识图谱。如图3所示。
先通过模型标记数据集中语料分块单词,利用One-hot encoder将字词转化为单独的离散符号,再将离散符号转化为低维度的稠密向量,利用提取命令找出关键词中关联度最高的词汇,形成词向量。在构建图谱关系时,还可将所有关联的产品名称作为独立的产品库合集,当用户键入相关或类似的产品时,能快速地从中提取到关联的指标项。
5 实验结果对比
在实验中,如输入“蛋白质的指标有哪些?”的时候,得益于构建的词库,模型可快速地从用户输入内容中提取到“蛋白质”“指标”等有效的关键词。通过对比某通用大模型对“蛋白质”相关指标的输出,相同问题下,标准大模型的回答更为专业,并能根据需要展示更多相关的内容。如图4所示。
6 结 语
本文根据ISO的SMART标准数字化成熟度划分方法,探索level 3-4的标准数字化技术实现路径,重点介绍了标准大模型实现知识图谱、智能问答功能的实现方法。目前研究处于初始阶段,后续将持续优化。
参考文献
[1]刘彦林,甘克勤,马小雯,等.标准数字化发展现状与演进态势[J].中国标准化,2024(3):49-53.
[2]马超.标准数据形态变革视域下我国标准数字化转型发展综述[J].信息通信技术与政策,2024,50(2):74-81.
[3]袁文静,方洛凡.标准对话:标准数字化的阶段性目标与实践[J].中国标准化,2024(3):6-29.
[4]张伟.标准数字化现状分析及发展建议[J ] .大众标准化,2024(7):1-3.
[5]狄矢聪.标准数字化平台建设机制与发展路径研究[J].标准科学,2024(1):64-71.
作者简介
顾鑫,通信作者,博士,标准化高级工程师,国家软件与系统工程分技术委员会(SAC/TC 28/SC 27)专家委员,主要研究领域为数字标准化、全域标准化、综合标准化、信息安全、大数据挖掘等。
(责任编辑:张佩玉)
基金项目:本文受国家市场监督管理总局科技研发计划“标准数字化转型创新应用研究”(项目编号:2022MK088)资助。
猜你喜欢
现代情报(2016年11期)2016-12-21 23:54:23
现代情报(2016年11期)2016-12-21 23:53:46
现代情报(2016年10期)2016-12-15 12:32:46
现代情报(2016年10期)2016-12-15 12:27:57
新教育时代·教师版(2016年33期)2016-12-02 22:26:31
智富时代(2016年12期)2016-12-01 16:28:41
中国远程教育(2016年9期)2016-11-19 12:21:26
商场现代化(2016年23期)2016-11-17 19:31:01
中国教育信息化·基础教育(2016年9期)2016-10-18 02:29:50
电脑知识与技术(2016年7期)2016-05-19 13:54:36
