
基于WebGL与微前端的虚拟仿真平台技术方案
2024-12-31 00:00:00侯珏盛士能朱昕宇
信息系统工程 2024年11期


摘要:采用WebGL技术实现3D渲染,利用微前端架构提升系统灵活性。通过WebGL着色器优化和微前端模块化设计,显著提升了渲染效率和系统扩展性。实验结果表明,该方案可显著提升渲染帧率和用户交互体验,同时降低了平台开发和维护成本。通过该方式建立的虚拟仿真平台有希望解决传统虚拟仿真平台硬件要求高、跨平台能力弱和可扩展性差的问题。
关键词:WebGL;微前端;虚拟仿真;3D渲染;模块化设计
一、前言
WebGL作为基于Web的图形库,具有跨平台、高性能的特点,为Web端3D渲染提供了强大支持。微前端架构通过将前端应用分解成小型、独立的模块,有效提高了系统的可维护性和灵活性。将WebGL与微前端技术相结合,有望解决当前虚拟仿真平台面临的技术挑战。针对这一思路,提出了基于WebGL与微前端的虚拟仿真平台技术方案,旨在提升仿真系统的渲染性能和可扩展性。
二、WebGL技术在虚拟仿真中的应用
(一)WebGL渲染管线分析
WebGL渲染管线优化关键在于减少GPU与CPU间的数据传输和提高GPU利用率。通过合并绘制调用(draw calls)来减少API调用开销。例如,使用instanced rendering技术,一次绘制调用可渲染多个相似对象。对于静态几何体,将顶点数据存储在GPU缓冲区中,避免每帧重复传输[1]。利用Vertex Array Objects(VAO)预先定义顶点属性状态,减少状态切换。在着色器中,将常用但不常变的数据存储为uniform变量,减少数据传输。对于大型场景,实现视锥体剔除和遮挡剔除,仅渲染可见物体。通过空间分割结构,如八叉树或BSP树来加速。
(二)性能优化策略
1.几何优化
几何优化实施中,网格简化可采用迭代边折叠算法。实现时,预计算多个LOD级别,在运行时根据距离选择合适的模型。对于地形等大型网格,使用Chunked LOD技术,将地形分割为网格块,近处使用高精度,远处使用低精度。视锥体剔除通过包围盒与视锥体的相交测试实现,使用空间划分结构,如四叉树加速。遮挡剔除可利用分层Z-buffer技术,在低分辨率下进行快速遮挡测试。对于复杂场景,结合GPU遮挡查询(Occlusion Query)提高准确性[2]。
2.纹理压缩
纹理压缩优化需针对不同平台选择适当格式。在WebGL中,可使用浏览器支持的压缩格式。实现时,为每种格式准备不同版本的纹理,运行时动态选择。Mipmaps生成可在加载纹理时自动完成,或使用WebGL的generateMipmap函数。纹理图集可通过将多个小纹理打包到一个大纹理中实现,使用UV坐标映射到正确位置。对于大型场景,实现纹理流式加载,根据视点位置动态加载高分辨率纹理,卸载不可见区域的纹理,控制内存使用。
3.着色器优化
着色器优化实践中,可将顶点变换和基础光照计算移至顶点着色器,减轻片元着色器负担[3]。复杂光照,如PBR可使用查找纹理(LUT)预计算光照结果。对于大量光源,采用延迟渲染技术,将光照计算与几何处理分离。在片元着色器中,使用早期z测试(Early-Z)技巧,尽早剔除被遮挡的片元。复杂数学运算,如sin、cos可用泰勒级数展开近似。对于透明物体,实现Order Independent Transparency(OIT)技术,如深度剥离(Depth Peeling)或加权混合,提高渲染质量和性能。
(三)WebGL与物理引擎的集成
WebGL与物理引擎集成优化需要平衡计算负载。实现中,可将物理模拟步长与渲染帧率解耦,使用固定时间步进行物理更新。对于大量物体的碰撞检测,实现空间哈希或八叉树来快速筛选潜在碰撞对。软体模拟可使用Position Based Dynamics(PBD)算法,在顶点着色器中实现布料模拟。流体模拟可采用粒子系统结合SPH(Smoothed Particle Hydrodynamics)方法,使用Transform Feedback在GPU上更新粒子位置。对于复杂的物理计算,利用WebAssembly将高性能C++物理库,如Bullet,编译为Web可用版本,提升计算效率。同时,使用WebWorker将物理模拟放入后台线程,保证渲染线程的流畅性。
三、微前端架构设计
(一)微前端核心原理
微前端架构的核心是将大型前端应用拆分为多个独立、自治的小型应用。这种方法允许每个子应用独立开发、测试和部署,提高了开发效率和系统可维护性。实现微前端的主要技术包括基于路由的分发、WebComponents、iframes和JavaScript模块联邦。这些技术可以单独使用或组合应用,以满足不同项目需求。为保证一致的用户体验,建立共享的样式系统和组件库。微前端架构还需要解决应用间的状态同步、性能监控和错误追踪等问题,以确保整个系统的稳定性和可靠性。
(二)模块化设计与实现
模块化设计是微前端架构的基础,主要涉及子应用的划分和组织。实践中,根据业务域、功能模块或页面组件来划分子应用,确保每个子应用都是自包含的,拥有独立的构建流程和版本控制。可以使用NPM工作空间或Lerna等工具管理多包仓库,简化项目管理[4]。在代码层面,广泛采用ES6模块系统或CommonJS实现模块化,确保每个模块职责单一。公共组件和工具函数可以抽离为独立包,通过私有NPM仓库共享。构建过程中,使用Webpack或Rollup等工具优化资源加载。统一的脚手架工具可以提高开发效率,快速创建规范化的子应用。在集成阶段,可使用SystemJS或模块联邦实现运行时动态加载。样式隔离可采用CSS Modules、CSS-in-JS或Shadow DOM等技术。此外,还考虑版本兼容性,制定清晰的API演进策略,并使用语义化版本控制。
(三)微前端间通信机制
常用的通信方式包括基于事件的通信、全局状态管理和URL参数传递。事件通信可以利用CustomEvent API或实现发布—订阅模式的事件总线。全局状态管理可使用Redux或MobX等库,但需谨慎设计状态结构以避免冲突。URL参数传递适用于简单的数据共享。对于实时通信需求,考虑使用WebSocket或Server-Sent Events。在框架层面,可以实现统一的通信API,封装底层细节,为子应用提供一致的接口[5]。安全性也是重点考虑因素,需要实现消息签名和验证机制。设计通信机制时应遵循最小知识原则,只暴露必要接口,维护子应用间的低耦合度,不仅确保了系统的可维护性,也为未来扩展留下了空间。
四、虚拟仿真平台整体架构
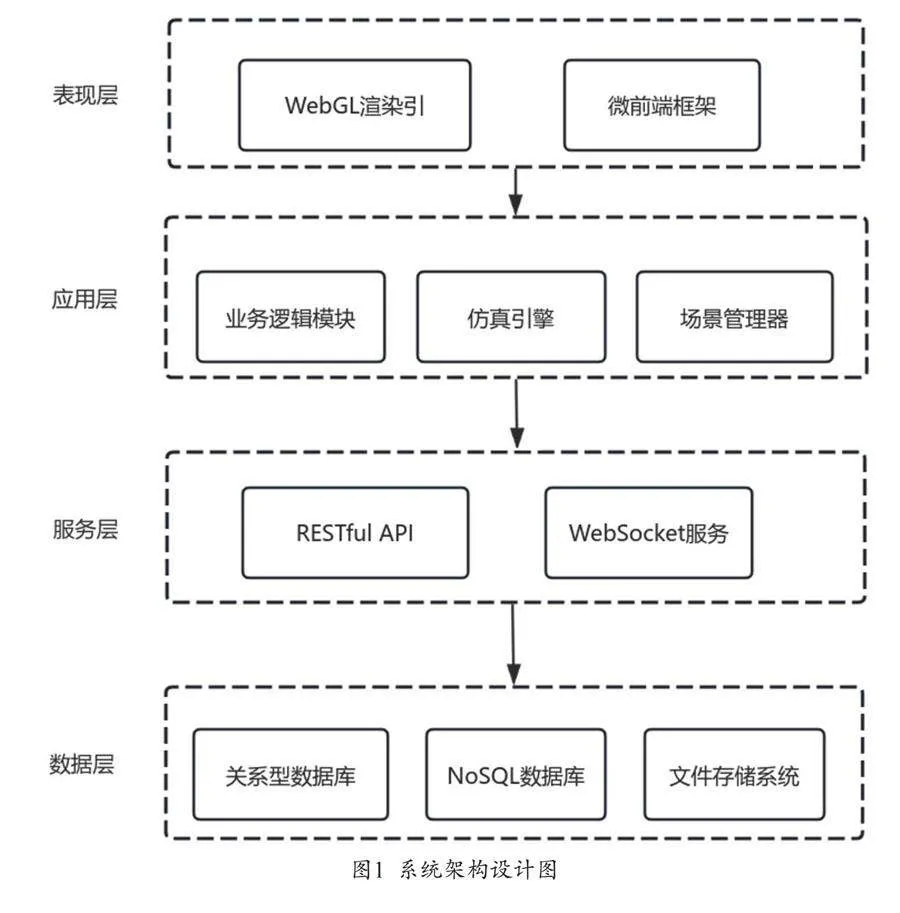
(一)系统架构设计
虚拟仿真平台采用多层架构设计,包括表现层、应用层、服务层和数据层。表现层集成WebGL 3D渲染引擎和微前端框架,处理用户界面和交互[6]。应用层包含业务逻辑、仿真引擎和场景管理器,负责核心仿真计算。服务层提供RESTful API和WebSocket服务,实现前后端通信。数据层使用关系型和NoSQL数据库存储数据,文件系统管理3D资源,如图1所示。
系统引入Redis缓存层提升性能,使用负载均衡器确保可扩展性。采用Docker容器化技术封装组件,Kubernetes实现自动化部署。大规模并发仿真通过消息队列分发到专门计算集群。贯穿各层的监控和日志系统支持持续优化和故障排查。集成的权限管理和安全模块确保数据安全和访问控制。
(二)WebGL与微前端集成方案
集成架构采用基于路由的微前端框架,如Single-SPA作为基础,将WebGL渲染模块封装为独立的微应用。主应用负责全局路由、认证和基础UI框架,WebGL微应用则专注于3D场景渲染和交互。为优化性能,WebGL上下文在主应用中初始化,通过依赖注入的方式共享给WebGL微应用,避免多次创建WebGL上下文的开销。3D资源加载采用动态导入策略,结合WebGL的纹理压缩和几何优化技术,实现按需加载和渐进式渲染。为解决WebGL在不同微应用间的状态共享问题,实现了一个中央状态管理器,使用发布—订阅模式同步WebGL相关状态。渲染循环通过RequestAnimationFrame API在主应用中控制,确保在多个微应用间平滑切换时保持稳定的帧率。
为处理大规模3D数据,引入WebWorkers进行离屏数据处理和物理计算,通过TransferableObjects最小化线程间数据传输开销。WebGL着色器代码采用模块化设计,使用glslify等工具管理着色器依赖,便于在不同微应用间复用复杂的渲染效果。为适应不同设备性能,实现了自适应渲染质量控制机制,根据FPS动态调整渲染参数。微前端的样式隔离通过Shadow DOM实现,确保WebGL应用的CSS不会影响其他微应用。
(三)数据流与状态管理
虚拟仿真平台的数据流与状态管理设计采用了分层和分布式的策略,以应对复杂的仿真场景和大规模用户交互。在前端,使用Redux作为中央状态管理工具,结合Redux Toolkit简化样板代码。状态树按功能模块划分,包括用户信息、场景配置、仿真参数等主要分支。为优化性能,使用reselect库实现选择器的记忆化,减少不必要的状态计算。异步操作通过Redux-Saga中间件处理,实现复杂的仿真控制流程。针对WebGL渲染状态,设计了专门的Reducer和中间件高效处理,如相机位置、光照变化等高频更新。大型3D场景的状态采用分块加载策略,结合虚拟列表技术,实现高效的内存管理。在服务端,使用Event Sourcing模式记录状态变化,结合CQRS模式优化读写性能。仿真数据流采用流处理架构,使用Apache Kafka作为消息队列,实现仿真事件的实时处理和分发。
为支持多用户协同仿真,引入Operational Transformation算法处理并发编辑冲突。状态同步采用增量更新策略,通过WebSocket传输差异数据,最小化网络负载。数据持久化层使用时序数据库,如InfluxDB存储仿真时间序列数据,便于后续分析和回放[7]。为保证数据一致性,实现了基于两阶段提交的分布式事务机制。缓存策略采用多级缓存,结合LRU算法有效管理热点数据。
五、性能评估与优化
(一)渲染性能分析
性能分析采用Chrome DevTools和WebGL Profiler工具,测试场景包含10万三角面片和50个动态光源。初始测试显示58FPS的帧率和65%的CPU使用率。分析发现顶点和片元着色器占用大部分GPU时间。通过着色器优化,如顶点属性压缩和光照预计算,GPU渲染时间减少23%。绘制调用优化,包括实例化渲染和静态批处理,将每帧调用从3000次降至800次,提升帧率15%。大规模场景引入空间数据结构进行剔除,减少过度绘制。综合优化后,复杂场景(50万面片、100光源)的帧率从25FPS提升至42FPS,大幅改善用户体验。具体优化效果见表1。
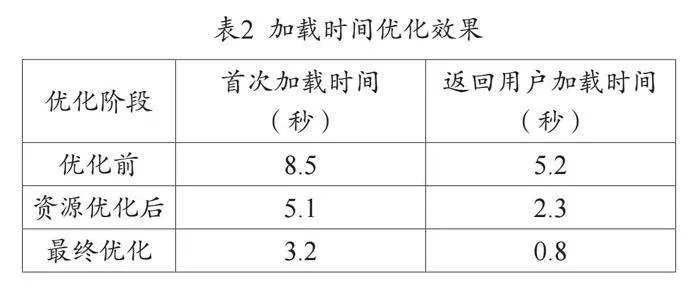
(二)加载时间优化
使用Navigation Timing API和Resource Timing API分析资源加载。初始加载时间为8.5秒,主要由3D模型和纹理占用。优化策略包括:
第一,3D资源流式加载,优先加载关键部分,减少40%加载时间。
第二,资源预加载,基于用户行为预测。
第三,纹理自适应压缩,根据设备和网络条件调整。
第四,优化JavaScript和CSS加载顺序,内联关键CSS。
第五,实施HTTP/2服务器推送,减少延迟。
第六,使用Service Worker实现离线缓存。
优化后,首次加载时间降至3.2秒,返回用户加载时间仅0.8秒,大幅提升用户体验,见表2。
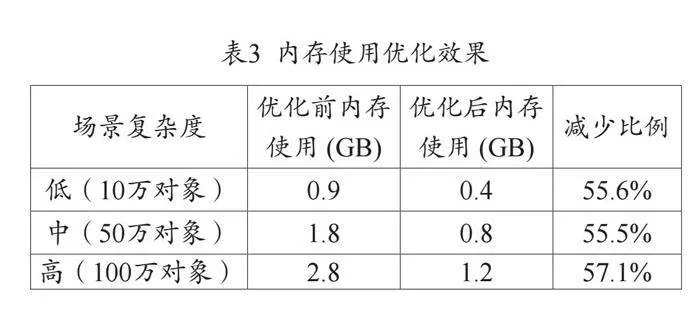
(三)内存使用优化
通过Chrome Memory面板分析,初始版本加载100万对象场景时内存峰值达2.8GB,存在明显内存泄漏。优化措施包括:
第一,引入对象池技术,重用频繁创建销毁的对象。
第二,实现基于四叉树的LOD系统,动态加载不同精度模型。
第三,优化纹理管理,使用纹理图集合并小纹理。
第四,实现纹理流式加载和卸载机制。
第五,引入自动内存监控和清理机制。
优化后,同场景内存峰值降至1.2GB,减少57%。长时间运行(8小时)后内存增长控制在5%以内,显著提高了应用稳定性,见表3。
(四)可扩展性评估
设计了一系列测试用例,模拟不同规模的用户负载和场景复杂度,评估系统的可扩展能力。在用户并发方面,使用Apache JMeter模拟了从100到10000个并发用户的场景。测试结果见表4。
六、结语
基于WebGL与微前端的虚拟仿真平台技术方案,通过WebGL高效渲染与微前端模块化设计相结合,有效解决了传统虚拟仿真系统面临的性能与扩展性问题。实验结果表明,该方案在渲染效率、加载时间和系统扩展性等方面均取得显著改善。未来工作将进一步优化WebGL着色器性能,探索更高效的微前端通信机制,以及研究大规模场景下的动态加载策略。
参考文献
[1]董志成,陈恭洋,印森林,等.基于WebGL的数字露头可视化表征与识别系统:以无人机倾斜摄影依奇克里克剖面为例[J].科学技术与工程,2024,24(11):4633-4642.
[2]刘天财,杨宇青,马继承,等.基于WebGL的智慧社区三维可视化应用研究[J].科技资讯,2023,21(24):233-238.
[3]吴蓉,刘彬.基于VUE微前端无刷新换肤方案设计[J].软件,2024,45(01):177-179+183.
[4]杨晨辉.基于微前端架构的产业链数据可视化系统的设计与实现[D].北京:北京邮电大学,2022.
[5]葛峰,高中扩,闫倩倩.一种自动驾驶整车在环虚拟仿真测试平台设计[J].汽车维修技师,2024(16):24.
[6]田淋瑕,罗威.虚拟ECU仿真测试平台搭建及应用[J].内燃机与配件,2024(15):137-139.
[7]李亚南,李聪聪,马丽,等.沉浸式3D虚拟仿真实验平台构建[J].实验室研究与探索,2024,43(06):201-208.
基金项目:2022年度浙江省职业教育与成人教育科研课题“微仿真平台的设计与实施方案研究——以机械设计课程为例 ”(项目编号:2022-27)
作者单位:杭州科技职业技术学院
责任编辑:王颖振、郑凯津
猜你喜欢
智能计算机与应用(2020年6期)2020-11-11 08:02:18
计算机技术与发展(2020年7期)2020-07-15 05:04:26
中国新通信(2020年2期)2020-06-24 03:06:44
软件(2020年3期)2020-04-20 01:45:18
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
家庭百事通(2016年3期)2016-03-14 08:07:17
