
基于堆叠自编码器的出口NOx浓度预测研究
2024-12-19 00:00:00饶永华
中国新技术新产品 2024年23期





摘 要:本文旨在利用堆叠自编码器(SAE)预测工业排放中的NOx浓度,探索其在环境监测与控制中的应用潜力。研究人员通过筛选关键影响参数,确定对出口NOx浓度影响显著的因素,使用SAE建立了一个有效的出口NOx浓度预测模型,具备较高的预测精度。此外,本文还提出了基于在线学习的模型参数自更新方法,实现了模型的动态调整以及适应性优化。对模型自适应更新效果进行分析,验证了其在不断变化的环境条件下的有效性。本文不仅为环境管理决策提供了科学依据,还在工业生产过程中提供了一种新的智能化预测方法,具有重要的理论及实际价值。
关键词:堆叠自编码器;NOx浓度预测;SAE网络结构
中图分类号:X 734 " 文献标志码:A
在环境保护需求下,准确预测并有效控制工业排放中的NOx浓度显得尤为重要。传统的监测方法通常依赖物理化学分析以及经验模型,但这些方法往往受限于实时性以及数据处理复杂性,难以满足复杂工业环境下的实时监测需求。而机器学习以及深度学习技术的发展为环境监测与预测提供了新的解决方案。堆叠自编码器在特征学习以及非线性建模方面表现出色,被广泛应用于各种数据预测以及处理任务中。其能够通过无监督学习自动从数据中学习特征表示,具备较强的数据抽象能力与泛化能力,适用于复杂的工业过程数据分析。
1 出口NOx浓度关键影响参数筛选
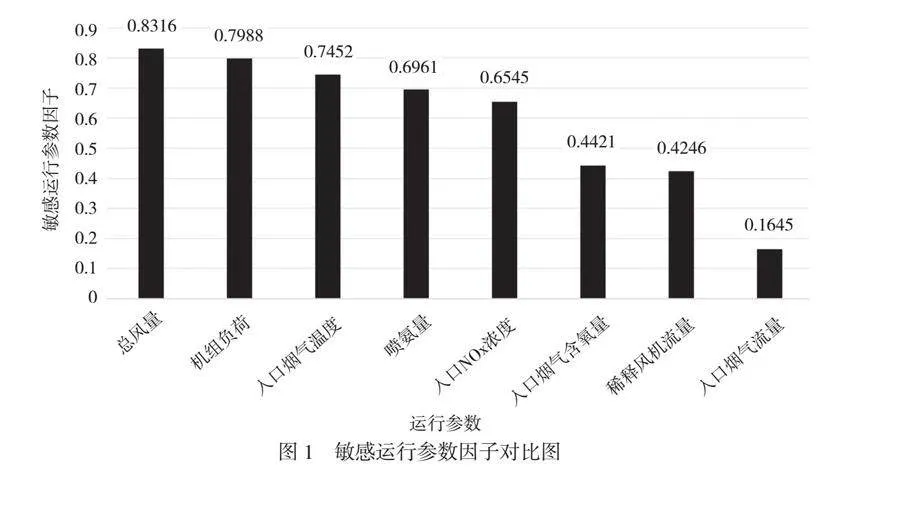
在燃煤机组的SCR系统中,运行参数数据量巨大,涵盖了进料氨水流量、烟气温度、催化剂层厚度等多个方面。由于参数众多,如果不加筛选地全部纳入模型,不仅会导致模型复杂化,还会大幅提升计算成本以及操作难度。因此,本文采用敏感变量优选法,旨在筛选与SCR系统出口NOx浓度关联性最强的关键影响参数。在筛选过程中,研究人员利用Spearman相关系数来量化每个运行参数与出口NOx浓度的相关性。Spearman相关系数的优势在于,它不依赖变量的线性关系,能够更好地捕捉变量间的非线性关系,这对SCR系统这类复杂系统的参数分析尤为重要。通过计算各运行参数的Spearman相关系数,研究人员得出了每个参数与出口NOx浓度的敏感运行参数因子[1]。通过这种敏感运行参数因子的对比分析,研究人员能够更精确地识别对NOx浓度影响最显著的参数,从而构建出一个更高效、简洁的SCR系统预测模型(如图1所示)。
2 基于堆叠自编码器的出口NOx浓度预测建模
2.1 堆叠自编码器介绍
自编码器是一种神经网络模型,将输入数据压缩到潜在空间(编码),然后再重建原始输入(解码)来学习数据。其主要由2个部分组成。1)编码器。将输入数据映射到潜在空间中的表示。编码器网络层的输出被称为编码(或隐藏)层。2)解码器。将编码后的表示映射回重建的输入空间,尽可能还原原始输入,自编码器的训练目标是最小化输入与重建输出之间的重建误差。堆叠自编码器通过堆叠多个自编码器层来增加模型的深度。每个自编码器层都被训练,以学习数据的不同层次的表示,每一层的编码器输出成为下一层的输入。本次研究中,研究人员为了预测出口NOx浓度,使用堆叠自编码器。每一层都负责学习数据的不同抽象层次的特征表示,与编码器对应的解码器层,负责将编码的数据逐层解码还原为原始输入,如公式(1)所示。
=fNN(g2(g1(x;θ1);θ2)) (1)
式中:为预测的出口NOx浓度;x为输入的运行参数向量,包括上述8种用于预测的特征;g1(;θ1)为第一层堆叠自编码器的编码器部分,用于将输入向量x映射到第一层特征空间;g2(;θ2)为第二层堆叠自编码器的编码器部分,接收第一层特征空间的输出作为输入,并将其映射到第二层特征空间;fNN(∙)为神经网络模型,用于预测最终编码后的特征[2]。
具体实践中,工作人员输入x的具体参数,此时第一层自编码器开始运行,将x映射到第一层的特征空间。第二层自编码器接收第一层的编码特征作为输入,将其进一步映射到第二层的特征空间,通过这种方式获得最终编码特征(见表1)。
2.2 基于SAE的出口NOx浓度预测模型建立
当研究人员建立基于SAE的出口NOx浓度预测模型时,全面考虑每个步骤的细节,以确保最终模型的准确性与可靠性。研究人员尝试构建一个能够精确预测火电机组出口NOx浓度的模型。此模型旨在通过应用先进算法,为燃煤火电机组的环保与高效运行提供有力支持。研究人员从多个运行中的火电机组中收集了足够的数据,确保模型能够广泛适用于不同条件下的燃煤火电机组。数据包括800组实际运行数据,涵盖了各种运行参数以及环境条件,主要的输入变量包括总风量、机组负荷、入口烟气温度、喷氨量、入口NOx浓度。当构建SAE模型时,研究人员设计一整套完整的网络结构,包括输入层、多个隐层以及输出层的层次结构[3]。每个自编码器层都经过精心设计,以最大化模型对数据复杂关系的捕捉能力。
本文中,为了评估SAE模型的预测能力,研究人员引入了2个主要的评估指标,即均方根误差(RMSE)以及确定系数R2。基于这2项指标帮助研究人员量化模型预测值与实际观测值之间的差异,并评估模型的拟合程度以及泛化能力(见表2)。
3 基于在线学习的模型参数自更新
具体实践中,SCR系统的运行条件容易在外部环境的影响下发生改变,影响其工作状态。针对这一问题,研究人员尝试搭建基于在线学习模型的参数自适应更新框架,通过分析历史数据与实时反馈数据,使模型能够持续改进优化,从而更好地应对复杂的数据环境。研究人员先进行离线训练,从数据库、数据仓库或实时数据流等多个来源收集数据,并对数据进行清洗、归一化处理,以确保数据质量。根据任务需求,选择合适的模型架构与算法。在离线训练的初始阶段,模型参数通常会使用初始值进行初始化。在此基础上,通过优化损失函数,模型调整其参数,以最大程度地拟合历史数据集,利用反向传播算法等优化技术来更新模型的权重与偏差,过程如公式(2)所示。
(2)
式中:θ为模型参数集合;α为学习率;J(θ)为损失函数,用于衡量模型预测值与真实值之间的差异;L(y,hθ(x))为单个样本的损失函数;m为训练样本的数量;δ(i)为第i个样本的误差项;z(i) 为第i个样本的线性组合;x(i) 为第i个样本的特征向量;y(i) 为第i个样本的真实标签;hθ(x)为模型的预测函数。
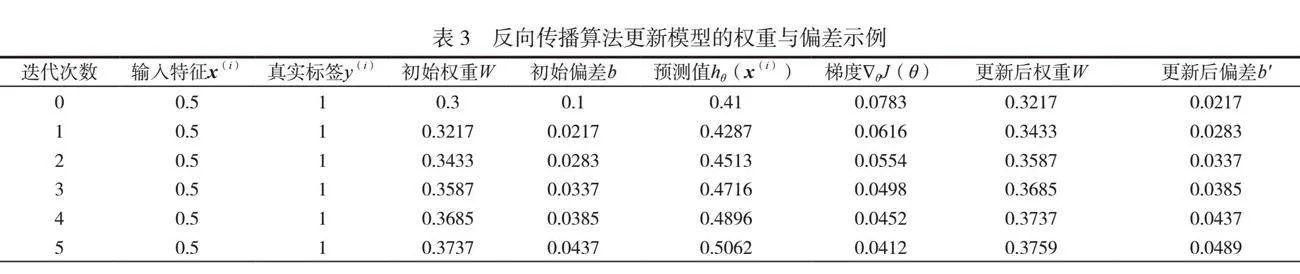
在训练开始之前,需要初始化模型参数θ,包括权重W与偏差b,在前向传播阶段,输入数据通过神经网络各层进行计算,得到输出预测值。针对每个训练样本i,计算线性组合z(i)=θTx(i)+b ,应用激活函数hθ(x(i))得到预测值。在此基础上,利用反向传播算法计算损失函数关于模型参数的梯度(见表3)。
4 模型自适应更新效果分析
本次研究中,为了验证自适应更新策略对模型性能的改善程度,确保模型能够持续适应新的数据特征以及环境变化,提高预测的准确性与鲁棒性。研究人员进行模型自适应更新效果分析。研究人员采用了2种不同的预测模型。第一种是传统的基于栈式自编码器的出口NOx预测模型,该模型依赖固定的网络结构与参数。第二种是采用自适应更新策略的SAE模型,该模型能够在运行过程中动态调整网络结构与参数,以适应数据变化。在训练阶段,为了保证对比的公平性,自适应更新SAE模型的离线版本在训练集大小、数据分布以及网络超参数等方面与原始SAE模型保持一致[4]。通过这种方式确保2种模型在相同条件下进行训练,从而更准确地评估自适应更新策略的效果。实际测试后,研究人员采用了1组未参与训练的数据集对2种模型进行效果评估。通过比较预测结果与实际测量值,分析2种模型的优缺点,见表4。
分析表4可以发现,原始SAE模型预测值与实际值之间的平均误差为0.0678,而自适应更新SAE模型的RMSE为0.0455,这说明自适应更新后的模型预测值与实际值之间的平均误差缩小了。通过比较2个RMSE值可以发现,自适应更新SAE模型的RMSE比原始SAE模型降低了约33.1%((0.0678-0.0455)/0.0678≈0.331),即自适应更新策略显著降低了预测误差。
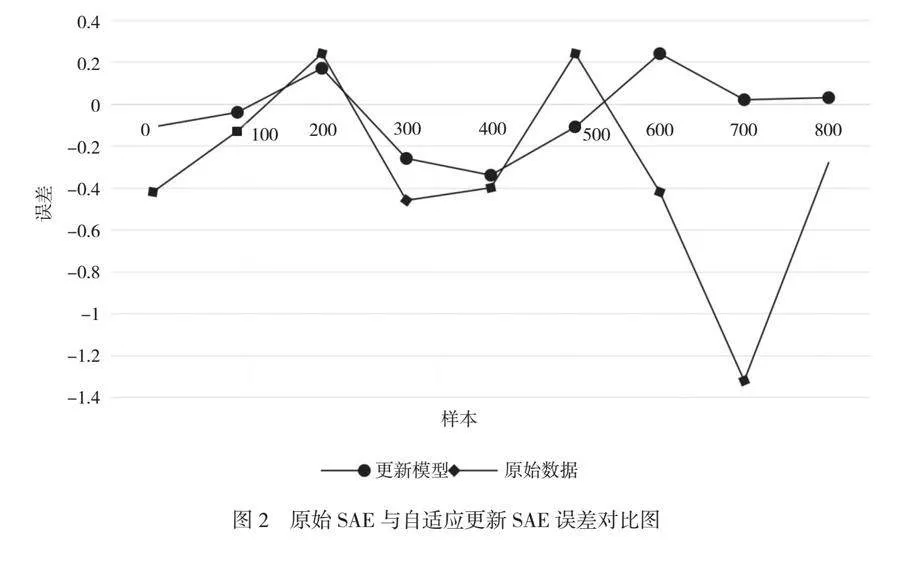
在预测精度分析方面,原始SAE模型的R2值为0.8672,说明模型能够解释大约86.72%的变量间相关性。自适应更新SAE模型的R2值为0.9403,即自适应更新后的模型能够解释大约94.03%的变量间相关性。通过比较2个R2值可以得出,自适应更新SAE模型的R2值比原始SAE模型提高了约7.81%((0.9403-0.8672)/0.8672≈0.081),说明自适应更新策略提高了模型在解释变量间相关性方面的表现,从而提升了预测精度。因此,研究人员得出结论,自适应更新策略在降低预测误差方面具有显著优势,因为自适应更新SAE模型的RMSE值比原始SAE模型小。而R2值的提高说明自适应更新模型在解释变量间的相关性方面表现更优,预测精度得到了提升[5]。自适应更新策略有效地改善了模型的预测性能。此外,研究人员还对测试集上的原始SAE与自适应更新SAE之间的误差进行对比,如图2所示。
分析图2可以发现,自适应更新能够根据模型的实际表现动态调整更新频率与更新量。当应用于自编码器模型时,这种策略能够使AE模型的误差曲线具有更平稳的特性,同时波动幅度也相应减小。这种变化说明了预测误差得到了有效控制,模型的预测效果因此变得更稳定。具体来说,自适应更新通过实时监测模型的预测性能,只在必要时进行更新,从而减少了不必要的模型调整,使模型能够在较长时间内保持良好的预测性能,不易受到随机噪声的影响。
5 结语
本文成功地构建并优化了预测模型,验证了其在实际应用中的有效性与可行性。通过深入探讨关键影响参数筛选、模型建立及自适应更新策略,不仅为出口NOx浓度预测提供了新的技术方法,也为环境保护以及工业生产优化提供了有力支持。通过本次研究,研究人员得出以下结论。1)堆叠自编码器(SAE)作为一种深度学习模型,具有强大的特征提取能力。在本文中,SAE的应用为出口NOx浓度预测提供了新的技术途径。此外,研究人员还构建了一个基于SAE的预测模型,该模型能够有效地从输入数据中学习复杂的特征,并用于预测出口NOx浓度。2)为了适应不断变化的数据环境,研究人员采用了在线学习策略对模型参数进行自更新。这种策略使模型能够实时调整,以保持最佳的预测性能。3)通过试验分析,研究人员发现自适应更新策略有效地改善了模型的预测性能,使其在出口NOx浓度预测方面具有更高的可靠性。
参考文献
[1]李影,卓建坤,吴逸凡,等.可解释的变负荷下燃煤机组SCR反应器入口NOx质量浓度预测模型[J].热力发电,2024,53(7):119-128.
[2]张瑞方,张扬,张海.氨燃料在燃烧设备中的应用及展望[J].洁净煤技术,2024,30(5):46-55.
[3]金秀章,畅晗,赵大勇,等.基于蜣螂优化-集成加权融合的NO_x浓度动态预测[J].计量学报,2024,45(4):600-608.
[4]何德峰,刘明裕,孙芷菲,等.基于LSTM-SAFCN模型的生物质锅炉NOx排放浓度预测[J].高技术通讯,2024,34(1):92-100.
[5]刘树成,张晓,刘加昂,等.重型柴油车NOx排放因子与其浓度相关性研究[J].环境科学研究,2024,37(3):545-553.
