
基于一维卷积和LSTM网络的端到端水声目标识别
2024-12-18 00:00:00杨康
无线互联科技 2024年23期
关键词:深度学习





摘要:水声目标识别在国防和海洋环境监测等领域具有重要应用。然而,传统的时频域特征提取方法由于信息损失和环境适应性不足,限制了识别性能的提升。为克服这些局限性,文章提出了一种基于一维卷积神经网络(One-dimensional Convolutional Neural Network,1D CNN)与长短时记忆网络(Long Short-term Memory Network,LSTM)相结合的端到端水声目标识别模型(One-dimensional Long Short-term Memory,1DLSTM)。该模型直接以原始时域信号为输入,利用1D CNN提取局部特征,通过LSTM捕捉长程依赖关系,有效保留了信号的全局信息。在ShipsEar数据集上的实验结果表明,该模型的识别准确率高达93.91%,为水声目标端到端识别领域提供了一种新思路。
关键词:深度学习;水声目标识别;端到端
中图分类号:TB566;TP183""文献标志码:A
0"引言
水声目标识别作为水下探测技术的核心,在国防、海洋环境监测、水下资源勘探和导航等领域具有重要应用价值。然而,水下环境的复杂性给水声目标识别带来了巨大挑战。多径效应、海洋环境噪声、水温变化引起的声速剖面变化等因素都会严重影响声波传播,导致接收信号的失真和干扰。
传统的水声目标识别方法通过先提取可区分的特征,然后通过分类器或模板匹配来进行目标识别。这些方法包括基于频谱分析的方法(如短时傅里叶变换、小波变换)、基于统计特征的方法(如梅尔频率倒谱系数MFCC)等[1-2]。然而,这些方法往往依赖于人工设计的特征,难以适应复杂多变的水下环境,导致识别性能不稳定。
近年来,深度学习技术在水声目标识别领域取得了显著进展。基于卷积神经网络(Convolutional Neural Network,CNN)的方法,如Cao等[3]提出的多尺度CNN模型,通过学习声呐信号的频谱特征提高了识别性能。张旺等[4]提出的结合注意力机制的残差网络(Residual Network,ResNet)进一步增强了模型对关键特征的感知能力。然而,这些方法大多依赖于时频域表征,如频谱图或梅尔频谱图等[5-6],这些表征受限于固定的分辨率参数,可能导致原始波形中细微信息的丢失,从而限制了识别率的进一步提升。
相比之下,直接利用时域信号进行端到端识别能够保留全面的信息,减少人为偏差,简化处理流程。因此,该研究提出了一种新型的端到端水声目标识别模型(1DLSTM),该模型直接使用原始波形作为输入,结合了一维卷积神经网络的局部特征提取能力与长短时记忆网络的长程依赖建模能力,以全面捕捉水声信号的特征和全局结构。
1"相关原理和所提方法
1.1"一维卷积神经网络
经典的卷积神经网络通常使用二维卷积来处理图像数据,通过二维卷积能够有效地捕捉图像的空间特征。然而,当处理时序数据时,一维卷积更为合适。一维卷积操作能够有效地从时序数据中提取局部特征,这对于识别序列中的短期和长期依赖特征至关重要。此外,与二维卷积的矩阵卷积运算相比,一维卷积具有较低的计算复杂度和较少的模型参数。
一维卷积本质是通过一个或多个一维卷积核沿着时间轴滑动,对输入信号进行局部特征提取。一维卷积操作可以表示为:
X(l)j=f(∑Mi=1ω(l)ij*X(l-1)i+b(l)j)(1)
其中,Xl-1i表示第l-1层输入特征图,*表示一维卷积运算,f(·)为激活函数,ω(l)ij和b(l)j分别表示一维卷积核中的权值和参数偏置。
1.2"长短时记忆网络
长短时记忆网络是一种专门为解决传统循环神经网络(Recurrent Neural Network,RNN)在处理长序列数据时遇到的梯度消失和梯度爆炸问题而设计的特殊网络结构。LSTM的核心在于其独特的记忆单元结构。每个LSTM单元包含3个关键的门控机制:输入门、遗忘门和输出门。这些门控机制通过控制信息的流动,选择性地保留或丢弃信息,从而解决了传统RNN在处理长时间依赖时无法有效记忆的重要信息的问题。
遗忘门通过一个sigmoid函数计算输入值的权重,将其压缩至0到1之间的范围,从而通过权重控制哪些信息需要被遗忘。其计算公式如下:
ft=σ(Wf·[ht-1,xt]+bf)(2)
其中,ft是遗忘门的输出,Wf是权重矩阵,ht-1是前一个时间步的隐状态,xt是当前时间步的输入,bf是偏置,σ是sigmoid激活函数。
输入门决定哪些新的信息将被加入记忆单元中。输入门包含2个步骤:首先,使用一个sigmoid函数选择哪些值将被更新。其次,使用tanh函数生成新的候选值,决定哪些信息将更新到记忆单元中。计算公式如下:
it=σ(Wi·[ht-1,xt]+bi)(3)
Ct=tanh(WC·[ht-1,xt]+bC)(4)
其中,it是输入门输入,Ct是新的候选记忆单元状态。
输出门决定记忆单元的哪些部分将输出,影响下一个时间步的隐状态。输出门同样通过sigmoid函数控制信息流动,通过tanh函数将记忆单元状态转化为输出隐状态。公式如下:
ot=σ(Wo·[ht-1,xt]+bo)(5)
ht=ot·tanh(Ct)(6)
其中,ot是输出门的输出,ht是当前时间步的隐状态。
LSTM单元的最终更新公式如下:
Ct=ft·Ct-1+it·Ct(7)
其中,Ct是当前时间步的记忆单元状态,Ct-1是前一个时间步的记忆单元状态。
1.3"提出的1DLSTM模型
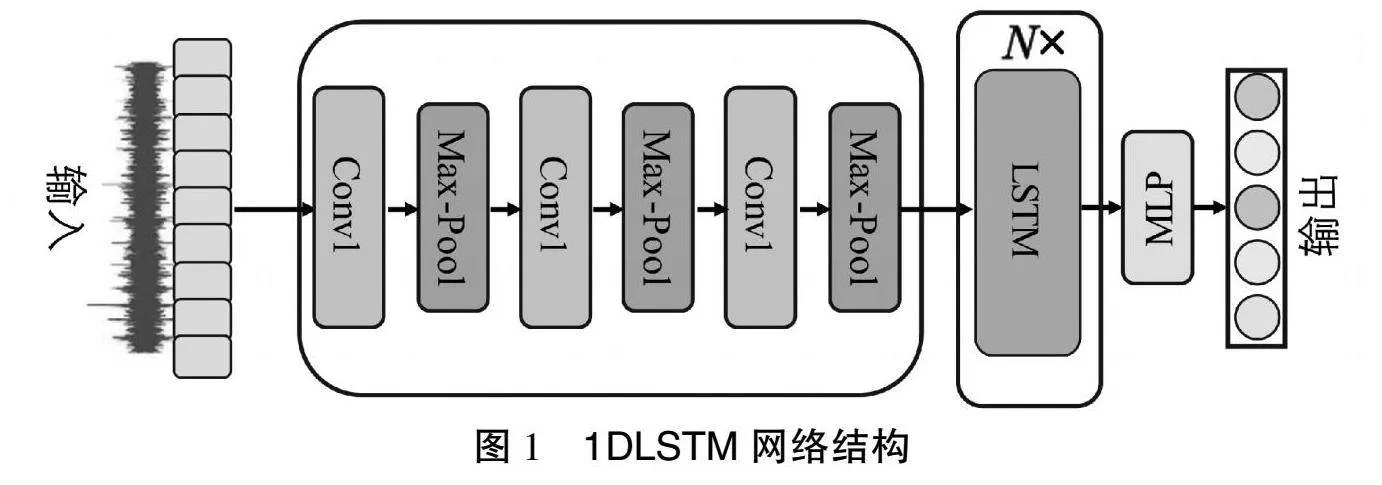
1DLSTM模型的核心思想是在深度学习的架构下,构建一个端到端的模型,直接以原始波形作为输入,通过多层次的特征提取和序列建模,最终实现高精度的水声目标识别。为了达到这一目标,网络结构如图1所示,具体参数如表1所列。首先,输入层直接接收原始的时域信号,保留了所有的原始信息,避免了在传统预处理过程中可能导致的信息损失。在一维卷积层部分,网络采用了3层1D CNN结构,每层卷积层后都紧接着一个最大池化层。这种设计允许网络逐层提取更高级的特征,其中第一层使用32个滤波器捕捉基本的时域特征,第二层使用64个滤波器以提取更复杂的模式,而第三层则使用128个滤波器进一步提取抽象特征。整个卷积过程中卷积核的大小设置为5。
卷积层输出的结果在进入LSTM层之前,首先经过重塑层的处理,将其重塑为适合LSTM处理的序列形式,从而保持特征的时间顺序。接着,模型采用双层LSTM结构,每层包含128个隐藏单元。这种设计能够有效建模信号中的长期时间依赖关系,捕捉水声信号的全局结构特征。此外,还通过引入dropout机制来防止过拟合的发生。最后,模型通过全连接层(Multilayer Perceptron,MLP)作为分类器,将LSTM的输出映射到目标类别的概率分布上,从而实现高精度的分类结果。
2"实验
2.1"实验数据和评估指标
实验采用ShipsEar数据集作为水声目标信号源。根据原始数据集的标注,目标类别划分为A、B、C、D和E 5个类别(4类船舶和1类背景噪声)。为了扩充原始数据,实验将信号按1 s长度进行等间隔分割,最终获得9600个独立样本。为确保模型的鲁棒性和泛化能力,采用分层随机抽样方法,按8∶1∶1的比例将数据集划分为训练集、验证集和测试集。
分类结果的评估中,采用识别准确率、召回率、精确率和F1-score来全面衡量网络的识别性能。每个指标的计算公式如下:
Accuracy=TP+TNTP+TN+FP+FN(8)
Precision=TPTP+FP(9)
Recall=TPTP+FN(10)
F1-score=2×Precision×RecallPrecision+Recall(11)
其中,TP、TN、FP、FN分别为真阳性、真阴性、假阳性和假阴性。
2.2"实验结果
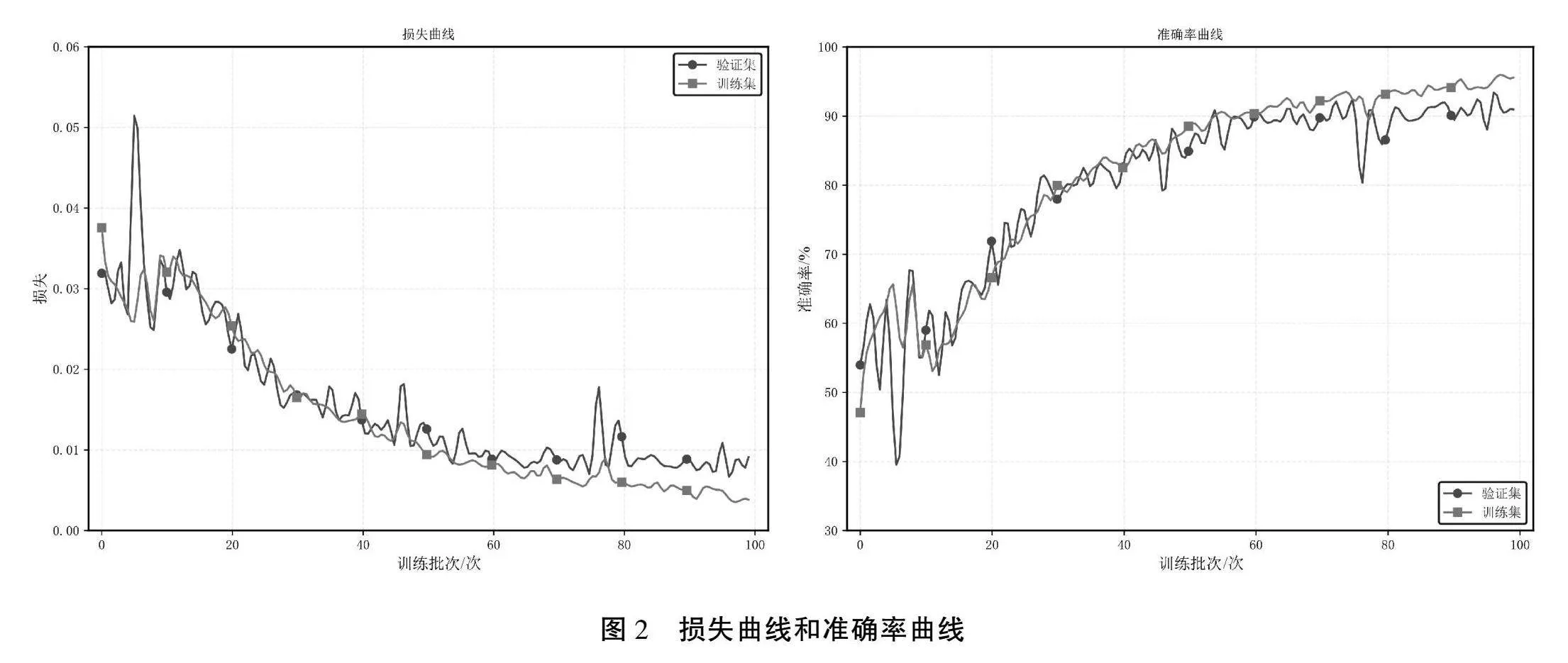
图2展示了1DLSTM模型在训练过程中训练集和验证集的损失曲线和准确率变化曲线。从图6中可以观察到,模型的学习过程呈现出典型的收敛特征。在完成训练后,实验中使用独立的测试集对模型进行了最终评估。1DLSTM模型在测试集上达到了93.91%的总体准确率,这一结果验证了模型的优秀泛化能力。
为了更深入地分析模型的识别性能,实验中进一步计算了测试集上模型的精确率、召回率和F1-score,其值分别为93.88%,93.93%和93.89%。结果表明,1DLSTM模型在评价指标上均表现出较高的识别准确率。
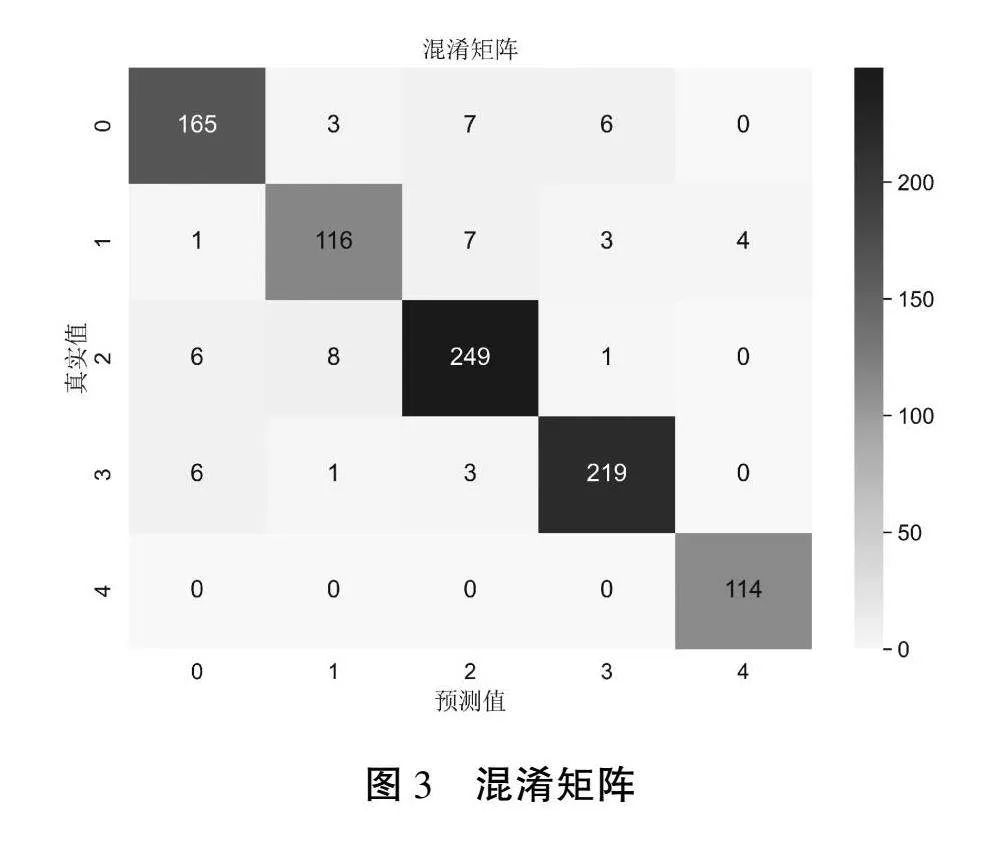
此外,图3所示的混淆矩阵进一步验证了模型在不同类别上的识别效果。混淆矩阵显示,1DLSTM模型在各类别的识别中均具有较高的准确性,只有极少数的混淆错误发生在船舶类之间。这表明,1DLSTM模型不仅能够有效区分不同种类的船舶,还能够较好地分辨背景噪声,展现了其在多类别水声目标识别任务中的广泛适用性。
3"结语
文章提出了一种新型的端到端水声目标识别模型(1DLSTM),成功融合了一维卷积神经网络与长短时记忆网络的优势,实现了对原始时域信号的高效处理与识别。与传统基于时频域特征提取的方法相比,该模型具有明显优势,能够直接利用原始信号,避免了特征工程中的信息损失风险。通过1D CNN与LSTM的协同作用,模型不仅能够提取局部时间特征,还能有效捕捉信号的全局结构特征。实验结果表明,1DLSTM模型在ShipsEar数据集上达到了93.91%的识别准确率,表现出优异的泛化能力与鲁棒性。在多个评估指标(包括精确率、召回率和F1-score)上,该模型均表现出卓越的性能,尤其在复杂的水声环境中,1DLSTM能够有效区分目标类别。
未来的研究可以进一步优化1DLSTM模型的结构和参数,以适应更为复杂的水下环境,同时探索该模型在其他领域如水下通信和海洋资源探测中的应""用潜力。
参考文献
[1]李昊鑫,肖长诗,元海文,等.特征降维与融合的水声目标识别方法[J].哈尔滨工程大学学报,2025(1):1-9.
[2]葛轶洲,姚泽,张歆,等.水声目标的MFCC特征提取与分类识别[J].计算机仿真,2024(2):13-16.
[3]CAO X,ZHANG X M,YU Y,et al.Proceedings of the IEEE International Conference on Digital Signal Processing,October 16-18,2016[C].Beijing:Piscataway,2016.
[4]张旺,杨乘,罗娅娅.融合注意力机制的ResNeXt语音欺骗检测模型[J].计算机应用与软件,2024(8):298-302.
[5]雷禹,冷祥光,周晓艳,等.基于改进ResNet网络的复数SAR图像舰船目标识别方法[J].系统工程与电子技术,2022(12):3652-3660.
[6]任晨曦.基于联合神经网络的水声目标识别技术研究[D].太原:中北大学,2022.
(编辑"王永超)
End-to-end acoustic target recognition based on 1D convolutional and LSTM networks
YANG "Kang1,2
(1.Zhenjiang College of Technology, Zhenjiang 212003, China;
2.Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract: "Acoustic target recognition plays a crucial role in defense and marine environment monitoring. However, traditional time-frequency domain feature extraction methods often suffer from information loss and inadequate adaptability to varying environments, limiting their recognition performance. To address these limitations, this paper presents an end-to-end acoustic target recognition model (1DLSTM) that combines a one-dimensional convolutional neural network (1D CNN) with a long short-term memory network (LSTM).This model directly processes raw time-domain signals, using the 1D CNN to extract local features and the LSTM to capture long-term dependencies, thereby effectively preserving the global information of the signal. Experimental results on the ShipsEar dataset demonstrate that this model achieves a recognition accuracy of 93.91%, offering a novel approach to end-to-end acoustic target recognition.
Key words: deep learning; acoustic target recognition; end-to-end
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27 19:23:52
中国远程教育(2016年11期)2016-12-27 18:07:31
现代商贸工业(2016年25期)2016-12-26 09:58:02
江苏教育·中学教学版(2016年11期)2016-12-21 11:45:08
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
考试周刊(2016年94期)2016-12-12 12:15:04
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
