
基于索引布隆过滤器的DDS自动发现算法
2024-12-18 00:00:00刘黄彪杨凡宋歌王峰俊张琦张小贝
现代电子技术 2024年24期






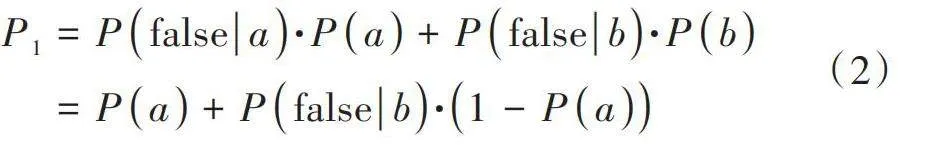




摘" 要: 数据分发服务(DDS)被广泛用于分布式系统的网络搭建,其中自动发现机制是DDS的关键部分。现有的DDS自动发现机制大都采用简单发现协议(SDP),但这种协议在大规模分布式系统的网络环境中会产生网络负载过高、匹配效率低下等问题。针对这些问题,提出一种基于索引布隆过滤器的轻量级DDS自动发现算法。该算法基于多维向量结构和索引值间的位操作设计一种索引布隆过滤器,用于压缩分布式系统网络节点间的传输信息,同时提供比标准布隆过滤器更低的误判率。结合索引布隆过滤器与SDP,能够减少DDS自动发现过程中的资源消耗并提高匹配效率。实验结果表明,在节点匹配率为10%的情况下,所提出的DDS自动发现算法相比基于标准布隆过滤器的SDPBloom算法,发现过程的数据包数量减少了46.39%,匹配时间缩短了73.30%。
关键词: 数据分发服务; 自动发现算法; 布隆过滤器; 分布式系统; 简单发现协议; 多维向量; 误判率
中图分类号: TN713⁃34" " " " " " " " " " " " " " 文献标识码: A" " " " " " " " " " " "文章编号: 1004⁃373X(2024)24⁃0047⁃08
DDS automatic discovery algorithm based on index BF
LIU Huangbiao1, 2, YANG Fan2, SONG Ge2, WANG Fengjun2, ZHANG Qi1, ZHANG Xiaobei1
(1. School of Communication amp; Information Engineering, Shanghai University, Shanghai 200444, China;
2. COMAC Shanghai Aircraft Design amp; Research Institute, Shanghai 201210, China)
Abstract: Data distribution server (DDS) is extensively utilized in the network construction of distributed systems, and the automatic discovery mechanism is a key part of DDS. The simple discovery protocol (SDP) is used in most of the existing DDS automatic discovery mechanisms, which can cause problems such as high network load and low matching efficiency in large⁃scale distributed system network environment. On this basis, a lightweight DDS automatic discovery algorithm based on index bloom filter (BF) is proposed. Based on the multi⁃dimensional vector structure and the bit operation between index values, an index BF is designed to compress the information transmitted between nodes in the distributed system network and provide a lower misjudgment rate than the standard BF. The combination of index BF and SDP can reduce the resource consumption in DDS automatic discovery process and improve the matching efficiency. The experimental results demonstrate that when the node matching rate is 10%, the proposed DDS automatic discovery algorithm significantly can reduce the number of data packets by 46.39% and shorten the matching time by 73.30% compared with the SDPBloom algorithm based on the standard BF.
Keywords: data distribution services; automatic discovery algorithm; bloom filter; distributed system; simple discovery protocol; multidimensional vector; misjudgment rate
0" 引" 言
当今飞机、汽车和火车系统设计的规模日益增大,系统复杂性大大增加,分布式系统的应用[1⁃2]变得越来越重要。数据分发服务(Data Distribution Server, DDS)中间件[3]作为一种可靠的数据通信技术,在分布式环境中能够实现高性能、实时的数据传输[4],提供通信、消息传递和协议适配等功能[5],以及协调和管理分布式系统的各个部分[6]。在DDS的通信过程中,节点发现机制[7]帮助分布式系统中的节点相互发现和建立通信关系,它允许 DDS系统中的节点自动地发现其他节点,并获取这些节点的有关信息,如可用性、QoS(Quality of Service)要求等。通过节点发现机制,节点能够动态地加入或离开DDS系统,而无需手动配置或静态预定义节点的信息。
为了在不同的DDS实现之间提供互操作性和透明度,OMG标准化了DDS互操作性有线协议(DDS Interoperability Wire Protocol)[8],其规定任何兼容的DDS⁃RTPS的实现必须至少支持SDP(Simple Discovery Protocol)。然而该协议仅能够满足中小型系统的通信需求[9],对于民用飞机等大规模分布式系统设计来说,网络节点数量庞多、发现协议数据包成倍增加、交换频率大大上升[10],这会导致SDP的匹配效率低下,匹配时间过长和高带宽消耗问题凸显,无法较好地满足大规模的数据传输需求。
布隆过滤器(Bloom Filter, BF)是一种经典的数据结构[11],主要作用是快速判断一个元素是否属于某个集合,而无需实际存储这个集合中的所有元素,具有高效的查询速度和低内存消耗的特点,在分布式系统中应用广泛[12]。在DDS中,BF可以应用于节点发现过程中的信息压缩和快速匹配[13]。通过使用BF,DDS系统可以在节点之间交换和存储经过哈希计算后的信息,而无需传输和存储原始的大量数据,这样可以大大减少网络负载和节点资源消耗,提高节点发现的效率和性能。需要注意的是,BF在判断一个元素是否存在于集合中时,可能会存在误判[14] 。一般而言,BF的误判率和它的大小以及所使用的哈希函数数量相关,BF的误判率和哈希函数数量都直接影响节点发现过程的效率和带宽,因此基于BF的DDS自动发现算法研究也大都建立在BF的改良之上[15⁃18],例如符号布隆过滤器(Symbol Bloom Filter, SBF)[19]和单哈希多维布隆过滤器(Onehash Manydimensions Bloom Filter, OMBF)[20],前者通过增加符号向量来降低误判率,但增加了查询和插入操作的复杂性;后者使用单个哈希函数,通过多维不同分区位向量的映射操作保证哈希函数的均匀性和随机性,用一定的误判率换取更快的查询时间。然而这种单一性能的改善对于DDS自动发现算法的提升有限,随着网络规模的增大,另一性能的短板也会影响到发现算法的匹配效率,需要提出一种更加全面的BF来进行DDS自动发现算法的改进。
本文详细分析了SBF和OMBF的特点和不足之处,提出了一种用于大规模分布式系统的索引布隆过滤器(Index Bloom Filter, IBF),并结合SDP实现了基于该过滤器的DDS自动发现算法。在多维位图的基础上,将标准BF中存储信息的位向量替换成根据端点信息生成的索引向量,并通过索引间的异或操作来进行元素的插入和查找,这种方式仅需要2个哈希函数就可以保证可接受的误判率,同时还能保证快速的查找时间,从而提高自动发现的匹配效率和速度,满足类似机载信息系统这种大规模分布式系统的通信需求。
1" 相关工作
1.1" DDS简单发现协议
OMG DDS标准[21]定义了分布式系统的发布/订阅通信模型,其中描述了DDS中的实体概念,包括域、域参与者、主题、发布者、订阅者、数据写入器、数据读取器[22]等,分布式系统之间的通信正是由这些实体之间的行为所实现的。DDS实体通信模型如图1所示。其中域代表一个单独的通信网络,属于相同域的不同参与者通过发布者和订阅者进行通信,写入器和读取器作为发布者或订阅者实际发送和接收消息的端点,主题定义了不同端点之间通信的数据类型和数据名称,多个主题构成不同参与者之间通信的逻辑通道。
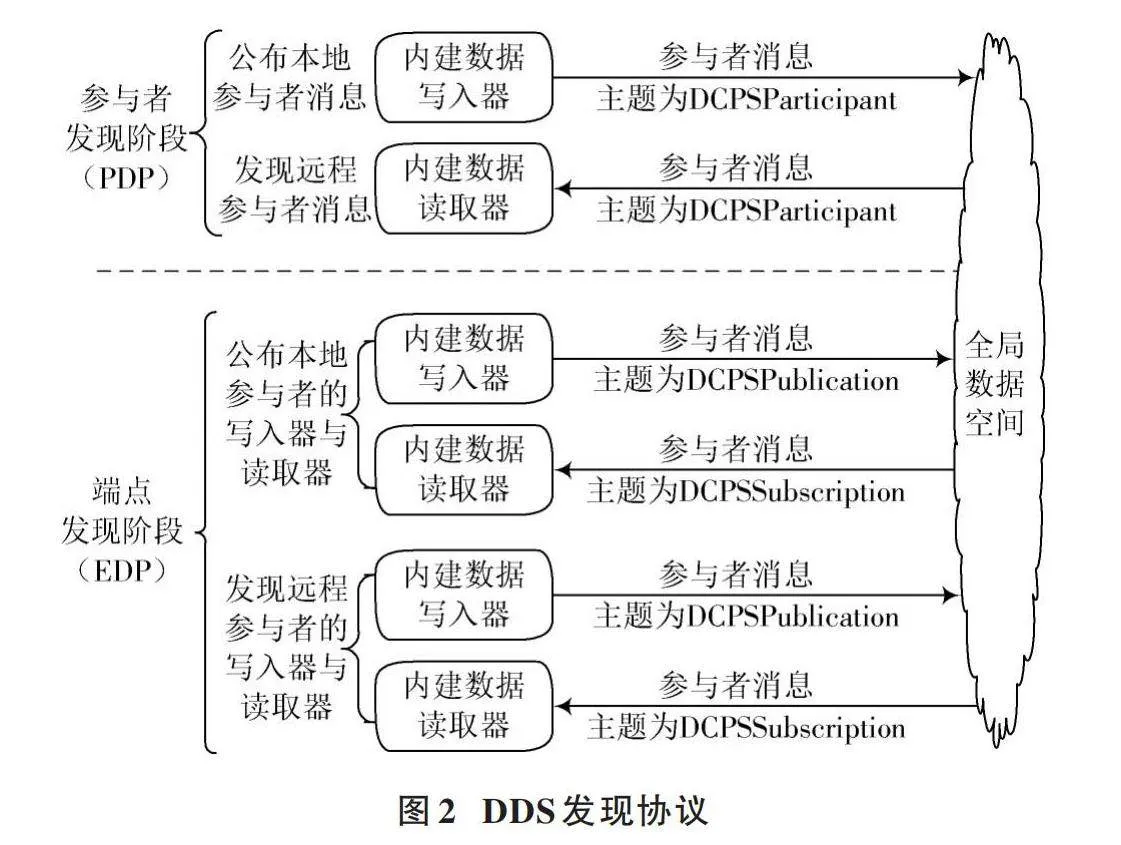
DDS可以描述为一种覆盖式点对点结构,其中给定主题的发布者通过全局数据空间(Global Data Space, GDS)链接到同一主题的所有订阅者。DDS通过节点发现机制为发布者和订阅者之间建立通信,节点发现机制实现了发布者和订阅者之间所有信息的透明和可互操作的即插即用传播。根据DDS互操作性协议,任何发现协议都必须分为两个连续的阶段:参与者发现阶段(Participant Discovery Phase, PDP)和端点发现阶段(Endpoint Discovery Phase, EDP)。DDS发现协议如图2所示。其中PDP为参与者之间的发现阶段,本地域参与者通过内建数据写入器向其他域参与者发送数据包,同时也会通过数据读取器读取其他域参与者发送的数据包。每当有新的参与者互相匹配时,就会触发EDP阶段,两个域参与者之间交换本地和远程端点信息,包括主题名称、主题类型、QoS策略信息等。
1.2" 基于布隆过滤器的DDS自动发现协议
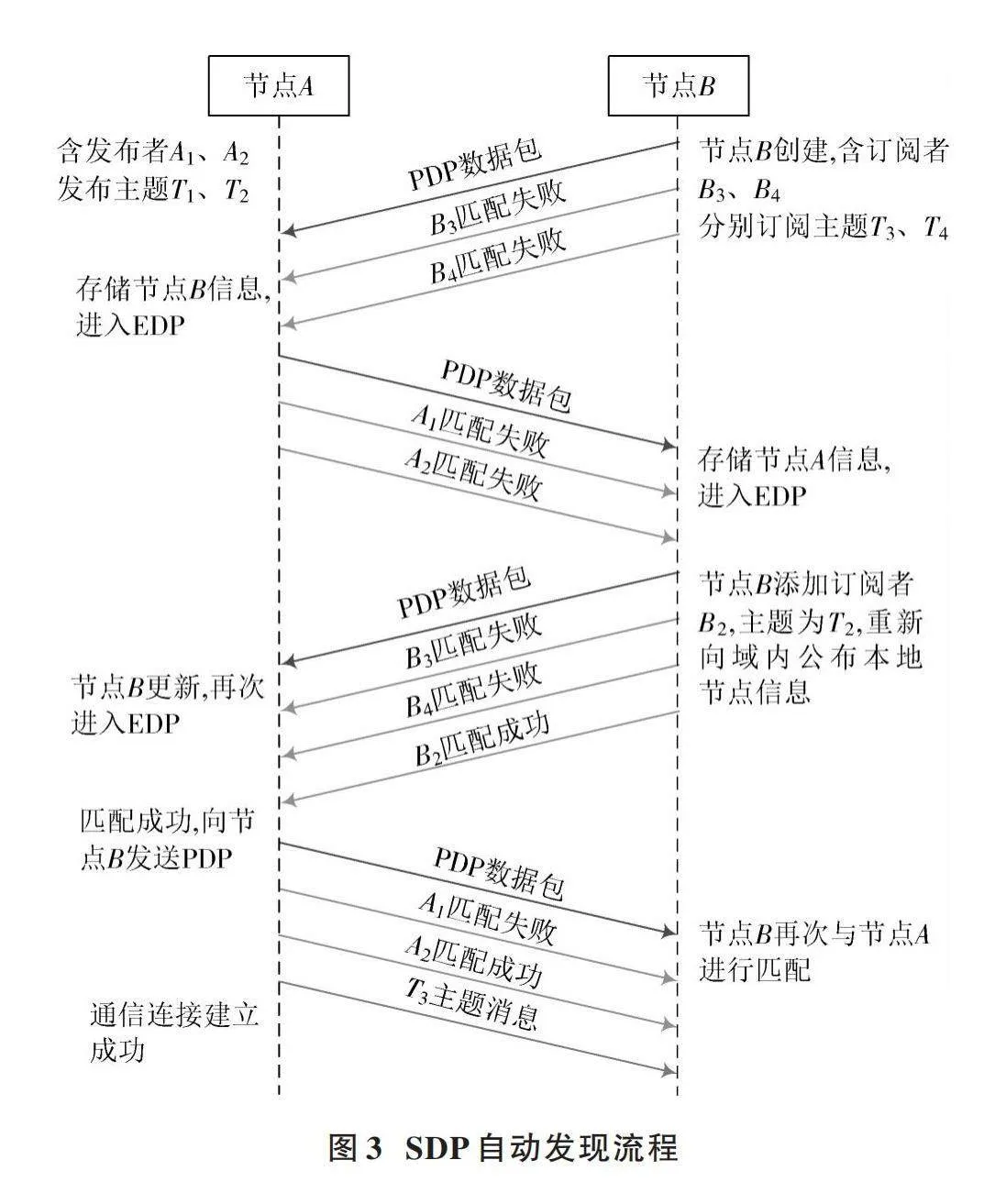
由1.1小节可知,EDP数据包包含了节点建立通信所需要的主要信息,而PDP数据包主要用于公布节点的存在情况。SDP自动发现流程如图3所示,由图可知,在SDP中本地节点通过PDP阶段获取网络中所有节点的存在信息,之后便直接进入EDP阶段,不论是否与该节点建立通信。为了尽量减少SDP中冗余EDP数据包对于带宽资源的浪费,引入了布隆过滤器算法来改进DDS简单发现协议。其主要原理是:在进入EDP阶段之前,通过BF进行一次筛选,检查远程节点是否存在本地节点所感兴趣的端点信息,从而减少不必要的EDP阶段。加入BF后的SDP自动发现流程如图4所示,通过BF的过滤作用挑选出有必要进一步匹配的参与者节点,从而减少不必要的EDP匹配过程,这种方式能够有效降低节点在发现过程中的网络资源消耗。
尽管SDPBloom算法在一定程度上减少了SDP在大规模分布式系统中的发现流量,但标准BF存在的误判率问题和哈希运算量仍然影响DDS自动发现算法的匹配效率和时间。为此,本文在标准BF基础上进行改进,构建了一种多维分区的索引向量位图,代替标准BF中的单维位图,用于保存过滤器中元素的存在信息,通过不同索引之间的差异性降低标准BF的误判率。这种过滤器仅需使用2个哈希函数(一个用于生成索引值,另一个用于锁定映射位置)就可以拥有比标准BF更低的误判率,能够更好地适应大规模分布式系统的通信需求。
2" 基于索引布隆过滤器的DDS自动发现算法
2.1" 索引布隆过滤器结构和原理
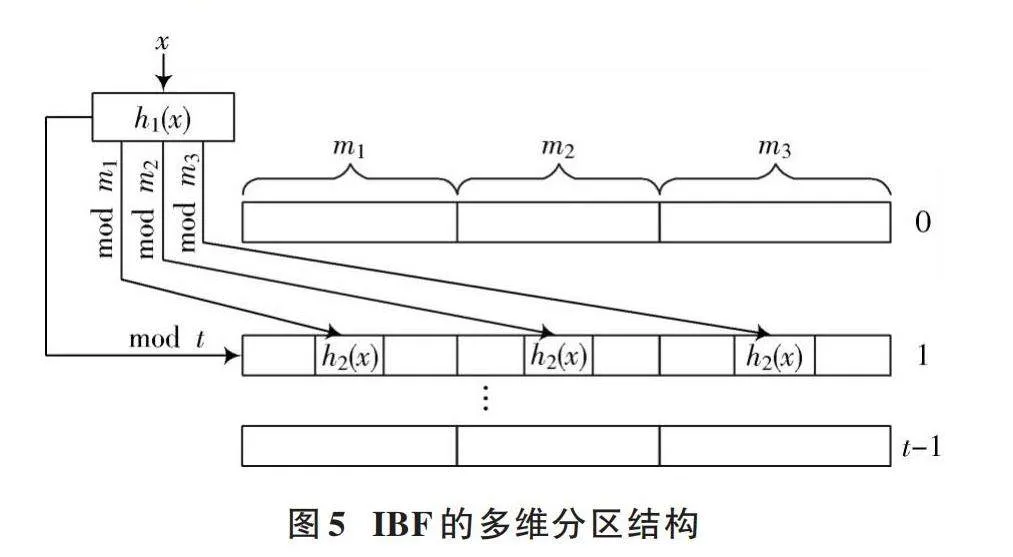
索引布隆过滤器是一种改进型的布隆过滤器。为了降低误判率,标准BF往往通过增加所使用的哈希函数数量来减少哈希冲突[23],故所选择的哈希函数往往比较复杂[24],且计算量较大,如混沌哈希函数、MD5、SHA⁃2等。为了降低哈希函数计算量,索引布隆过滤器将标准布隆过滤器中存储元素存在信息的位向量拓展为多维向量,并对每个维度进行分区。IBF的多维分区结构如图5所示,为一个[t]维位向量,其中每一维有3个分区,大小分别为[m1]、[m2]、[m3]。为了保证元素映射位置的相互独立性,分区大小一般设置为互不相同的质数。元素插入时,主要经过两次哈希运算与多次取模运算,其中两次哈希运算分别产生一个映射值和一个索引值,再对映射值进行第一次取模运算,选取元素映射的向量维度,最后与每个分区大小进行多次取模,以确定元素在每个分区中的映射位置。
IBF的算法处理流程如下。
1) 分区阶段:通过计算的方式将给定的[m]大小的位向量尽可能地分成[t]个大小不一的区域,即[{m1,m2,…,mk}]。为尽可能保证映射的随机性和均匀性,不同分区大小应设置为质数,分区中的每个位置是一个[z]位的索引,用于记录元素的存在信息。
2) 哈希阶段:将待插入元素[x]通过第1个哈希函数[h1(x)]映射为机器字,用于后续的取模操作,从而确定元素在各个分区中的映射位置。
3) 取模阶段:利用之前定义的[t]个不同分区的大小对哈希阶段生成的机器字进行取模运算,所得到的结果用于指示元素[x]在每个分区中的具体映射位置。由于分区大小都是质数,能够在一定程度上保持哈希映射的随机性和均匀性。
4) 索引映射:通过第2个哈希函数[h2(x)]计算元素[x]的索引值,并利用[z]对其取模,从而得到该元素对应的索引值;再将步骤3)中所有位置的值与该值进行或操作,更新每个位置的索引值。
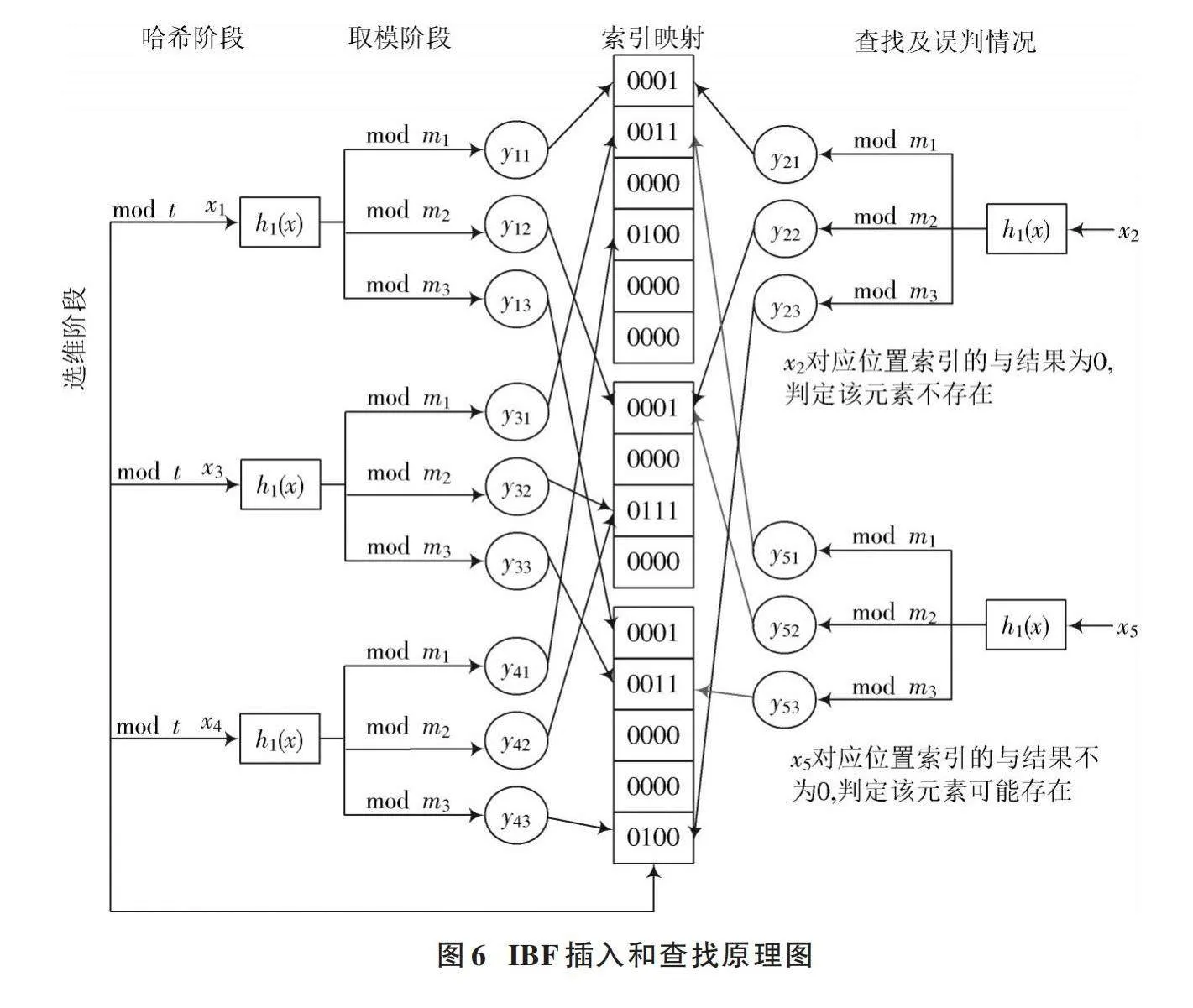
通过将单维位向量扩展到多维,能够减少相当一部分的哈希计算量,但对于标准BF来说,这种位图结构所得到的哈希映射结果并没有表现出更好的均匀性和随机性。为了解决这个问题,IBF添加了索引映射操作来剔除部分哈希冲突所造成的误判情况,从而在多维位向量中获得更好的误判率表现。在元素存储信息的表示中,标准BF基于位向量每个比特位的取值来表示元素的存在与否;而在索引布隆过滤器中,每个表示位被替换成一个多比特位组合表示的索引,用于区分来自不同元素的映射。初始情况下,多维位向量中所有的位都置为0。当多个索引被映射到同一位置时,通过对每个位置分别进行或操作来保存多个元素的存在信息。IBF插入和查找原理图如图6所示。
查询元素时,将对所有映射位置的索引值进行与操作,若与结果不为0,则表示多个映射位置可能存在同一索引,判定元素存在,否则不存在。在图6中,标准BF位向量中[x2]对应的映射位置都会被置为1,导致最终在元素查询时发生误判。而在IBF中,不同映射位置对应的索引值与结果为0,说明这几个位置的索引来自不同元素,因此判定该元素不存在,这种方式剔除了标准BF中由于哈希冲突导致误判的部分情形,从而降低了误判率。
2.2" 索引布隆过滤器性能分析
本文将索引布隆过滤器的误判率与标准布隆过滤器进行对比。IBF产生误判的原因有两个:多维分区映射阶段产生的映射位置冲突和映射位置对应的索引冲突,这两种情况同时发生时就会产生误判。两种冲突概率分别用[P1]和[P2]表示,则索引布隆过滤器的误判率可表示为:
[PFPR=P1·P2] (1)
映射位置冲突的产生原因也分两种:一种是哈希阶段所获取的映射值机器字冲突,用[a]表示;另一种则是映射值机器字不冲突的情况下,在取模阶段发生的余数冲突,用[b]表示。则映射位置冲突概率可表示为:
[P1=P1a·Pa+P1b·Pb=Pa+P1b·1-Pa] (2)
假设机器字为[L]位,IBF中有[t]维位向量,每一维向量的分区数为[k],[n]个元素均匀插入[t]维位向量中,则映射值机器字冲突概率为:
[Pa=1-1-12Ln] (3)
同理,余数冲突的误报率为:
[P1b=i=1k1-1-1mint≈i=1k1-e-nt·mi] (4)
通常情况下[2L≫mi],即[Pa≈0]。故有:
[PFPR≈P1b·P2≈i=1k1-1-1mint·P2≤1-i=1k1-1mintkk·P2≈1-i=1ke-nt·mikk·P2] (5)
标准布隆过滤器误判率[25]公式如下:
[PFPRBF=1-1-1mknk≈1-e-knmk] (6)
由式(5)、式(6)可知,每个分区的大小[mi]越接近[mt·k]时,[P1]越接近[PFPRBF];对于不同的索引集合,[P2]的值也不同,例如索引集合[{1,2,4,8}]对应的[P2]为0.25,即误判率降低为原来的[14]。
通过以上分析可知:索引布隆过滤器的误判率提升主要依靠索引集合的设置,对于任何索引集合,都有[P2≤1];当分区的均匀性越好、索引集合的位冲突概率越小时,IBF性能越好。
2.3" 基于索引布隆过滤器的DDS自动发现算法实现
索引布隆过滤器的插入和查询算法伪代码分别如算法1和算法2所示,插入时,首先通过一个哈希运算和多次取模运算得到索引的全部映射位置,并依次对每个位置的索引值做或操作;查询时,只需判断查询元素映射位置对应的索引值与结果是否为0,即可判断元素是否存在。
算法1:索引布隆过滤器插入算法
输入:key为待插入的字符串密钥
Function:insert(key)
[dim←h1(key)%t];" " " " " " " " " " " " " " " " //计算映射维度
for [i]:[1 2 … k" "]do
/*计算索引在每个分区中的映射位置*/
[position←dim×mi+j=1imj-mi+h1(key)%mi];
/*计算元素索引并与对应位置索引做或操作*/
[mposition=mposition | h2(key)];
end for
算法2:索引布隆过滤器查询算法
输入:key为待查询的字符串密钥
输出:表示待查询元素存在情况的布尔值
Function:query(key)
[dim←h1(key)%t];" " " " " " " " " " " " " " nbsp; " //计算映射维度
[res←0xFF];
for [i]:[1 2 … k" "]do
/*计算索引在每个分区中的映射位置*/
[position←dim×mi+j=1imj-mi+h1(key)%mi];
/*计算所有位置索引与结果*/
[res=mpositionres];
end for
return res==0
基于索引布隆过滤器的DDS自动发现算法伪代码如算法3所示,本地参与者在使能时构建对应的IBF和感兴趣的端点密钥集,将存储端点存在信息的位向量打包到PDP数据包中并发送;当接收到远程参与者的 PDP数据包时,提取出里面的位向量信息,构建对应 IBF并对感兴趣的端点密钥集合进行查询,若查询到感兴趣的端点存在信息,则进入EDP阶段,向该远程参与者节点发送PDP数据包,从而提高不同参与者节点间的匹配效率。
算法3:基于索引布隆过滤器的DDS自动发现算法
Function:local_endpoint_enabled(EP)
/*将端点信息转换成字符串密钥*/
[key←getEndpointKey(EP)];
[IBF.insert(key)];
Add IBF to PDP_packet;
Send PDP_packet to all remote Participant;
Function:remote_pdp_received(PDP_packet)
/*提取PDP数据包中IBF信息进行查询*/
[IBF←get_IBF(PDP_packet)];
for all local_matched_Ek do
if IBF.query(Ek)gt; 0 then
Send PDP_packet to this remote Participant;
Enter EDP phase;
break
end if
end for
3" 对比实验及结果分析
本节将IBF与SBF、OMBF和BF进行对比,通过两部分实验验证SDP_IBF自动发现算法的性能,第一部分比较4种布隆过滤器的误判率和查找时间,第二部分将4种过滤器算法整合到自动发现协议中,对比SDPBloom、SDP_SBF、SDP_OMBF、SDP_IBF四种DDS自动发现协议在实际网络中的性能表现。实验平台为Intel[Ⓡ] CoreTM i5⁃12500H 2.50 GHz、机带RAM 16.0 GB,软件环境为DDS分布式互连架构平台。
实验共设计不同的主题数200 000个,布隆过滤器的参数m=5 000,哈希函数采用自定义的混合哈希函数,4种过滤器k值均为4,在OMBF和IBF中,k值表示每一维度向量的分区数,设置维度t为4,每一维度分为k个分区,大小分别为239、241、257、263。
3.1" 主题误报率和查询时间验证
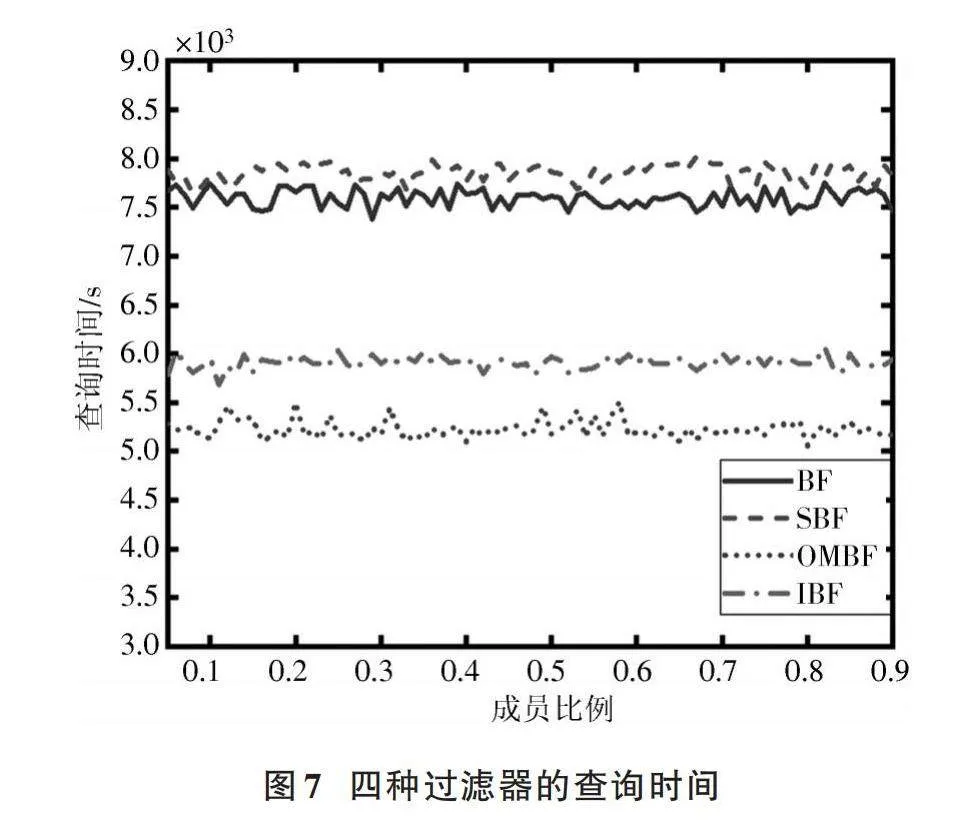
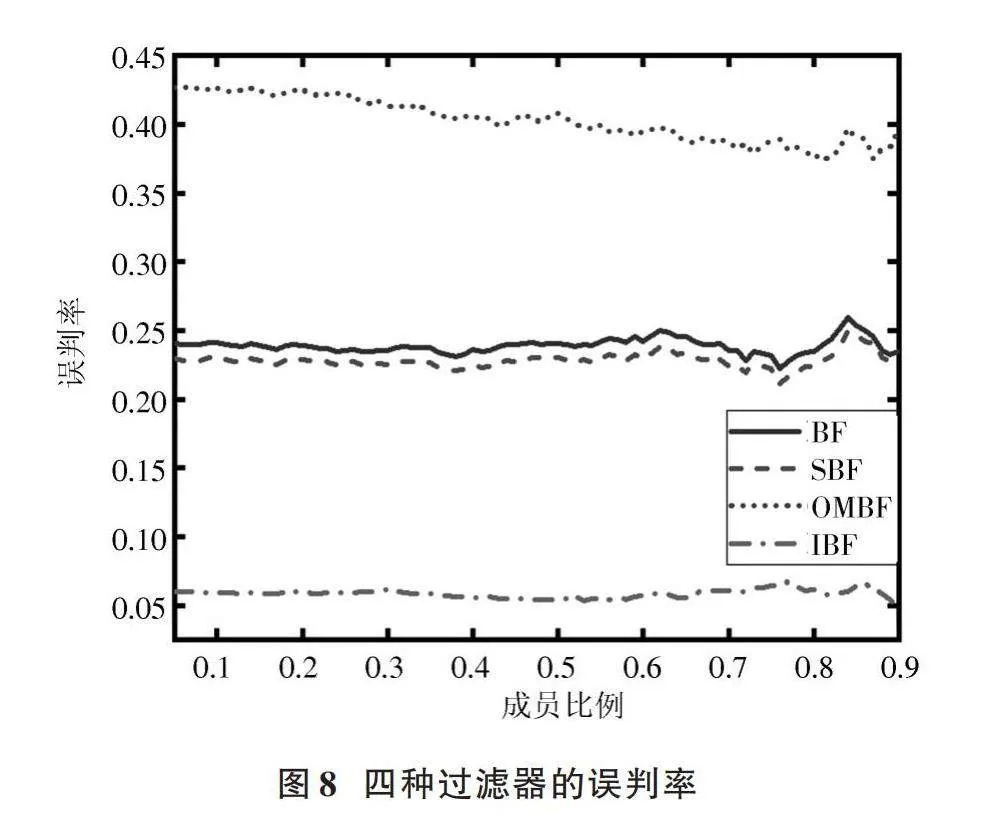
向每个布隆过滤器插入非重复主题1 500个,并设计了一组函数,对插入主题字符串进行重复、反转、大小写转换等操作,生成具体的错误集合;再将错误集合和插入主题集合按照不同的比例组合成测试集合,使得存在成员比例从5%~90%变化,测试不同成员比例下4种过滤器所消耗的查询时间以及误判率表现,结果分别如图7、图8所示。
从图7和图8可以看出:4种过滤器中,SBF的误判率相比标准布隆过滤器略有提升,但牺牲了一定的查询时间,这是由于SBF每次查询都要同时查询数据向量和符号向量所造成的;OMBF在查询时间方面提升较大,但单个哈希函数无法保证散列的均匀性和随机性,从而造成误判率上升。本文提出的IBF在查询时间上相较标准BF提升了近20%,降低了18%左右的误判率,具有良好的查询性能。
3.2" 网络传输量及匹配消耗时间验证
将4种布隆过滤器结合到自动发现算法中,设计不同的网络节点50个,每个网络节点上配置500个具有不同主题的发布和接收端点,在网络稳定后加入一个新节点,新节点在网络中的节点匹配率从10%~50%变化,监测在此过程中的数据包数量以及节点匹配所消耗的时间。4种自动发现算法的发现阶段数据包数量和节点匹配时间分别如图9、图10所示。
从图9和图10可以看出:当节点的匹配率逐渐增大时,发现阶段的数据包和节点匹配消耗时间都在逐步增大;SDPBloom和SDP_SBF在实际发现过程中区别不大,而SDP_OMBF在同等过滤器参数下产生了大量的数据包,同时也消耗了更长的节点匹配时间,这是因为在自动发现协议中,具体的发现性能与过滤器的误判率和查找时间有关,OMBF中较高的误判率意味着多余EDP阶段的增加。在机载信息系统中,节点匹配率大都在10%上下浮动,此时SDPBloom的发现阶段数据包数量为5 450个,匹配时间为191 s;而SDP_IBF的发现阶段数据包数量为2 922个,匹配时间为51 s。相较于SDPBloom,SDP_IBF的发现阶段数据包数量减少了 46.39%,匹配时间缩短了73.30%。在其余匹配率下,SDP_IBF也表现出较好的性能。
4" 结" 论
本文提出了一种用于大规模分布式系统网络节点发现机制的轻量级DDS自动发现算法。在标准布隆过滤器的基础上,提出了一种新的索引布隆过滤器,用于压缩分布式计算节点之间的信息;然后将它与SDP结合,组成一个新的DDS自动发现算法——SDP_IBF。此外,还讨论了4种基于不同过滤器的DDS自动发现算法的性能,实验结果表明,SDP_IBF可以通过降低误判率和查询时间来显著减少DDS自动发现算法的发现阶段数据包冗余,加快新参与者网络节点的匹配速度,能够更好地满足大规模分布式系统的通信需求。
注:本文通讯作者为宋歌。
参考文献
[1] SCHNEIDER S. The future of iiot software in manufacturing: a guide to understanding and using data distribution service (DDS), time⁃sensitive networking (TSN), and OPC unified architecture (OPCUA) for advanced manufacturing applications [J]. Control engineering, 2019, 66(1): 16⁃19.
[2] SADJINA S, KYLLINGSTAD L T, RINDARY M, et al. Distributed co⁃simulation of maritime systems and operations [J]. Journal of offshore mechanics and arctic engineering, 2019, 141(1): 011302.
[3] LIU Z, ZHAO Z. Distributed co⁃simulation computing based on DDS for large⁃scale aircraft mechatronic system [C]// Proceedings of the Fifth International Conference on Mechatronics and Computer Technology Engineering. Rome, Italy: ACM, 2022: 167⁃176.
[4] AGARWAL T, NIKNEJAD P, BARZEGARAN M, et al. Multi⁃level time⁃sensitive networking (TSN) using the data distribution services (DDS) for synchronized three⁃phase measurement data transfer [J]. IEEE access, 2019, 7: 13407⁃13417.
[5] 赵斌,郝红旗.网络中间件在分布式仿真系统中的应用[J].计算机仿真,2009,26(12):100⁃102.
[6] 王鹏,杨妹,彭勇,等.DDS在分布式仿真系统中的应用研究[C]//中国计算机用户协会仿真应用分会全国仿真技术学术会议论文集.北京:《计算机仿真》杂志社,2021:254⁃259.
[7] KAUSHIK S, POONIA R C, KHATRI S K. Comparative study of various protocols of DDS [J]. Journal of statistics and management systems, 2017, 20(4): 647⁃658.
[8] Object Management Group. The real⁃time publish⁃subscribe protocol DDS interoperability wire protocol (DDSI⁃RTPS) specification version 2.5 [EB/OL]. [2022⁃04⁃01]. https://www.omg.org/spec/DDSI⁃RTPS/2.5.
[9] 朱晓攀,陈实.基于DDS的像质处理提升仿真系统设计与实现[J].系统工程与电子技术,2018,40(8):1881⁃1888.
[10] AHMED R, LIMAM N, XIAO J, et al. Resource and service discovery in large⁃scale multi⁃domain networks [J]. IEEE communications surveys amp; tutorials, 2007, 9(4): 2⁃30.
[11] LUO L, GUO D, MA R T, et al. Optimizing bloom filter: challenges, solutions, and comparisons [J]. IEEE communications surveys amp; tutorials, 2018, 21(2): 1912⁃1949.
[12] TARKOMA S, ROTHENBERG C E, LAGERSPETZ E. Theory and practice of bloom filters for distributed systems [J]. IEEE communications surveys amp; tutorials, 2011, 14(1): 131⁃155.
[13] SANCHEZ⁃MONEDERO J, POVEDANO⁃MOLINA J, LOPEZ⁃VEGA J M, et al. Bloom filter⁃based discovery protocol for DDS middleware [J]. Journal of parallel and distributed computing, 2011, 71(10): 1305⁃1317.
[14] 李卓宇,夏必胜,马乐荣.布隆过滤器算法误判率的分析与应用[J].延安大学学报(自然科学版),2021,40(1):68⁃71.
[15] MITZENMACHER M. Compressed bloom filters [J]. Networ⁃king IEEE/ACM transactions on, 2001, 10(5): 604⁃612.
[16] LIU P, JIANG C, ZHANG X, et al. Compressed bloom filter method of DDS middleware based on FPGA [C]// Proceedings of the 2021 7th International Conference on Computer and Communications. Tianjin: IEEE, 2021: 27⁃34.
[17] JANG S, BYUN H, LIM H. Dynamically allocated bloom filter⁃based PIT architectures [J]. IEEE access, 2022, 10: 28165⁃28179.
[18] NWADIUGWU W P, CHA J H, KIM D S. Enhanced SDP⁃dynamic bloom filters for a DDS node discovery in real⁃time distributed systems [C]// Emerging Technologies and Factory Automation. [S.l.]: IEEE, 2017: 767.
[19] LIU Z, ZHAO Z. Data distribution service based on symbol bloom filter for large⁃scale distributed computing [C]// 2022 7th International Conference on Cloud Computing and Big Data Analytics. [S.l.]: IEEE, 2022: 112⁃116.
[20] 樊智勇,腾达,刘哲旭.基于单哈希多维布隆过滤器的DDS自动发现算法[J].计算机应用与软件,2021,38(10):273⁃277.
[21] Object Management Group. OMG data distribution service (DDS) version 1.4 [EB/OL]. [2015⁃04⁃10]. https://www.omg.org/spec/DDS/1.4.
[22] TEKINERDOGAN B, ÇELIK T, KöKSAL Ö. Generation of feasible deployment configuration alternatives for data distribution Service based systems [J]. Computer standards amp; interfaces, 2018, 58: 126⁃145.
[23] BLOOM B H. Space/time trade⁃offs in hash coding with allowable errors [J]. Communications of the ACM, 1970, 13(7): 422⁃426.
[24] CHRISTENSEN K, ROGINSKY A, JIMENO M. A new analysis of the 1 positive rate of a bloom filter [J]. Information processing letters, 2010, 110(21): 944⁃949.
[25] 华文镝,高原,吕萌,等.布隆过滤器研究综述[J].计算机应用,2022,42(6):1729⁃1747.
[26] 张晓敏.基于布隆过滤器属性基的多关键词可搜索方案[J]. 计算机与现代化,2021(8):104⁃111.
作者简介:刘黄彪(1998—),男,湖北黄石人,硕士研究生,主要研究方向为民用飞机航电系统设计。
杨" 凡(1996—),男,安徽和县人,硕士研究生,主要研究方向为民用飞机航电系统设计。
宋" 歌(1986—),男,河南洛阳人,硕士研究生,研究员,主要研究方向为民用飞机航电系统设计。
王峰俊(1968—),男,江西南昌人,研究员,主要研究方向为民机机载软件、IMA、航电数据网络。
张" 琦(1993—),男,河南漯河人,博士研究生,讲师,主要研究方向为光电信息技术。
张小贝(1982—),男,湖北宜城人,博士研究生,教授,主要研究方向为光电信息技术。
猜你喜欢
软件工程(2024年7期)2024-12-31 00:00:00
电子测试(2018年9期)2018-06-26 06:45:56
趣味(语文)(2018年2期)2018-05-26 09:17:55
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
自动化博览(2014年6期)2014-02-28 22:32:20
计算机工程(2014年6期)2014-02-28 01:25:40
中国氯碱(2014年11期)2014-02-28 01:05:07
电子设计工程(2014年12期)2014-02-27 11:58:03
